一种基于多源标注的事件抽取方法、装置及系统
本发明属于自然语言处理和人工智能,尤其涉及一种基于多源标注的事件抽取方法、装置及系统。
背景技术:
1、事件抽取是自然语言处理(nlp)中的一项关键任务,旨在从文本中识别并提取特定类型的事件。事件抽取对于许多应用有着重要的价值,包括信息检索、知识图谱构建、新闻摘要和监控等。
2、事件抽取的核心问题在于理解语义,这是一个具有挑战性的任务。最近,深度学习已经被广泛应用于事件抽取。然而,深度学习模型的成功往往依赖于大量的高质量标注数据来训练。然而,获取这样的数据是昂贵的,因为它需要人工专家进行细致的标注,这既耗时又费力。在保证质量与成本的平衡上,通常可以组织多个非专业的标注者对同一数据进行重复的标注。对于同一数据,不同标注者中出现最多的标签被认为具有高质量,并被视为真实的标签。然而,对于事件数据的标注,一个数据集中可能有数十个类别。区分如此多的类别已经是一项耗费精力的任务,存在的相似类别进一步增加了标注的困难。当标注难以区分的数据类别时,标注者可能会很容易犯错误。这可能导致错误的重复标签比正确的标签更多,因此打破了现有方法选择准确标签的标准,即众数投票方法。
3、现有技术中,申请号为cn202111624377.0的中国发明申请设计了一套基于众包技术的面向多层次标注者的事件标注系统,完成了数据集构建、语料库构建、标注机制、众包分配与聚合机制和结果数据库导出机制,具有相对完整的流程。然而,该发明申请仅以简单的众数投票作为众包聚合机制,没有考虑到每个标注个体水平之间的差异性,更没有考虑到混淆类的存在对标注结果分布情况的影响,因此该发明申请的标签聚合模块准确性不高,且难以在复杂标注场景下适用。
4、如上所述,众包标注也面临着诸多挑战。首先,不同标注方对不同类别的数据的标注水平不平衡。其次,标注方的标注质量可能会有很大的不同。因此,如何从众包标注中有效地提取有价值的信息,以及如何设计算法来适当地聚合这些标注,以获得高质量的标注结果,是当前面临的一项关键问题。本发明即是针对这一问题,提出了一种基于多源标注的事件抽取方法、装置及系统。
技术实现思路
1、有鉴于此,本发明创造提出了一种基于多源标注的事件抽取方法、装置及系统,对众包标签选择进行了基础研究,设计了一个质量评估过程,该过程将能力强的标注者权重高于能力弱的标注者。通过多轮质量评估算法,正确的标签能够在数量上占优势,超越错误的标签,大大提高聚合后标注的准确度,从而得到更加健壮的事件抽取模型。
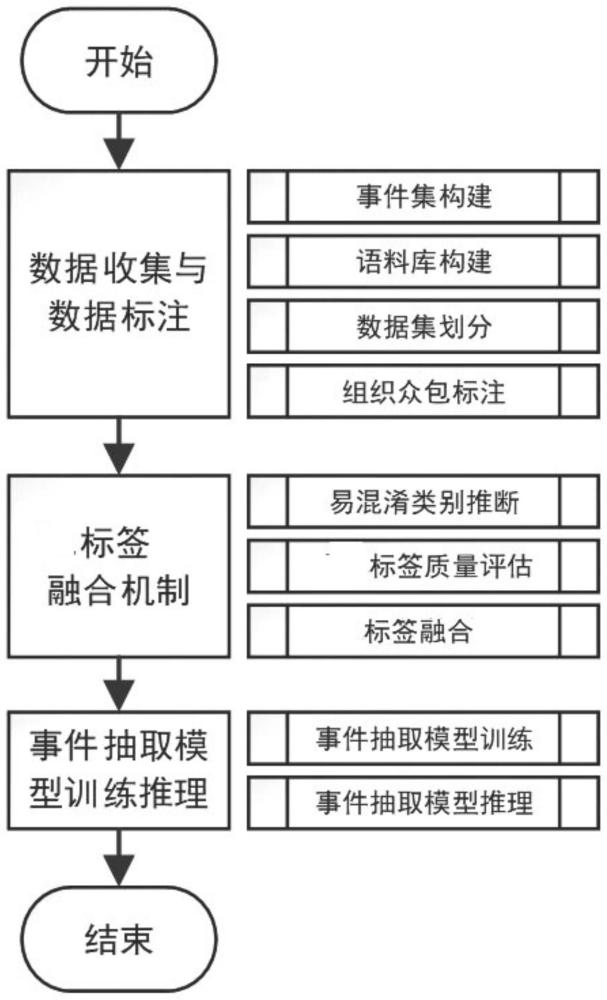
2、为实现上述发明目标,本发明公开了一种基于多源标注的事件抽取方法,包括以下步骤:
3、创建一个包含多个不同事件类型的事件集,每个事件由一个或多个角色组成;
4、从多种数据源收集文本,文本包含要抽取的事件;基于文本构建语料库,语料库的数据包括多个领域、主题和文本类型;
5、将构建的语料库数据集d划分为两个子集:训练集dtr和推理集dte;所述训练集dtr用于模型学习和训练的部分,所述推理集dte用于模型进行事件抽取推理的部分;
6、对训练集进行标注,得到标签;
7、对标签进行融合,包括推断易混淆类别,对标签质量进行评估,并融合标签;
8、将通过标签聚合得到的最终标签作为训练标签,将训练集中的文本作为输入,对一个深度神经网络进行训练;
9、训练好的神经网络模型f*用于对新的文本进行事件抽取:给定一个推理集用模型f*对每一个文本ti进行预测,得到预测的事件标签i∈{1,2,...,m},其中m是推理文本的总数,i为文本标号;
10、利用训练好的模型,对新的文本进行事件类型的预测,从而完成事件抽取的任务。
11、进一步地,创建一个包含多个不同事件类型的事件集,每个事件由一个或多个角色组成,包括:
12、首先,根据需要抽取的事件类型,定义每种事件的角色;然后,从领域专家的知识库中获取相关的事件和角色信息,以丰富事件集;最后,对事件集进行反复的审查和修订,确保其完整性和准确性;
13、构建完成的事件集e表示为包含n类事件的集合e={e1,e2,…,en},其中每个事件e是由m个角色构成的集合ei={r1,r2,…,rm},i∈[1,n],rm为第m个角色。
14、进一步地,所述数据集划分,包括:
15、训练集dtr占据整个数据集的小部分,但保证有足够数量的样本;剩余的样本则构成推理集dte;进一步地,将训练集dtr划分为已知集dk和未知集du,已知集dk中的样本是已经精确标注的部分,在未知集du中,样本的正确标签是未知的,这样,整个数据集d被划分为已知集dk,未知集du和推理集dte。
16、进一步地,推断易混淆类别包括:
17、构建各种常见的易混淆类别集合,记为gk,k=1,2,…,m,m为易混淆类别总数;对每一个标注者,预先对其进行测试,判断其在标注类上的准确率;如果准确率过低,那么将该组所对应的易混淆类加入到该标注者的易混淆类别集中,即
18、ll={class(gk)|accl(gk)≤λ},k∈{1,2,...,m};
19、λ为accl(gk)表示易混淆类别测试集合gk上第l个标注者的标注结果的标签准确率,m为易混淆类别总数,l是易混淆类的编号。
20、进一步地,标签的质量是一个高斯分布,其分布函数由数学期望e和方差v决定,即:
21、qi=(ei,vi),ei∈[0,1],vi∈[0,∞)
22、标注质量的数学期望通过不断迭代来达到最终的估计,某个标注质量迭代的依据是根据它与其他标注的一致性程度来决定的;迭代起始时,初始化所有标注的质量为:
23、ei=pi,vi=0,i=1,2,
24、pi为标注者i在预先的随机抽取得到的验证集ri上的标注精度,表示为:
25、pi=acci(ri)
26、其中acci(ri)是第i个标注者标注ri的结果的标签准确率;
27、共有m个标注,其中第i个标注的标注结果是yi,其混淆类是li,那么其标注的质量表示如下:
28、
29、i,k∈{1,2,…,m},i≠k,y={y1,y2,…,ym}
30、其中,y是标注结果的集合,lk,ek分别是第k个标注的混淆类和数学期望,是更新后的标签yi的质量,s(·)是s形函数,用以平滑输出,s-1(·)是s(·)的反函数,它们的解析式如下:
31、
32、f(ei,li;y,{lk},{ek})项通过下面的方程计算:
33、
34、
35、
36、
37、其中yi是第i个标注者的标注结果,ci,k表示标注者i和k之间的一致性,表示标注类别为混淆类的标注结果,g(ei,ek;lk)是置信度的更新量;
38、标签质量的方差由下面的方程计算:
39、
40、
41、
42、经过t轮迭代,最终确认得到每个标注者最终的标签质量及其方差vi,i=1,2,...,m;v是标签质量的方差,最终的标签质量是具有容错边界的标签质量。
43、进一步地,将得到的标签质量作为众数投票的权重,对最终聚合的标签结果进行投票,得到最终具有高可靠性的标签,即:
44、
45、δ(class,si)是一个指示函数,当class=si时,δ(class,si)=1,否则δ(class,si)=0,si是第i个标注者的标注结果标签。
46、进一步地,对一个深度神经网络进行训练,包括:
47、训练集为其中ti表示第i个样本的文本,ei表示第i个样本的事件标签,n是训练样本的总数,目标是训练一个深度神经网络模型f,使得模型f能够在训练集dtrain上最小化某一损失函数l,即:
48、
49、其中,f(ti)代表模型f对输入文本ti的预测输出,l(f(ti),ei)表示预测输出f(ti)和真实事件标签ei之间的损失,argminf表示找到使得后面的表达式最小的模型f。
50、本发明第二方面公开的基于多源标注的事件抽取装置,包括
51、创建单元:创建一个包含多个不同事件类型的事件集,每个事件由一个或多个角色组成;
52、收集单元:将从各种数据源收集文本,文本包含要抽取的事件,基于文本构建语料库,语料库的数据包括多个领域、主题和文本类型;
53、划分单元:将构建的语料库数据集d划分为两个子集:训练集dtr和推理集dte,训练集dtr是用于模型学习和训练的部分,而推理集dte是用于模型进行事件抽取推理的部分;
54、标注单元:对训练集进行标注;
55、融合单元:对标签进行融合,包括推断易混淆类别,对标签质量进行评估,并融合标签;
56、训练单元:将通过标签聚合得到的最终标签作为训练标签,将训练集中的文本作为输入,对一个深度神经网络进行训练;
57、抽取单元:训练好的神经网络模型f*被用来对新的文本进行事件抽取:给定一个推理集用模型f*对每一个文本ti进行预测,得到预测的事件标签i∈{1,2,...,m},其中m是推理文本的总数;
58、预测单元:利用训练好的模型,对新的文本进行事件类型的预测,从而完成事件抽取的任务。
59、本发明第三方面公开的一种基于多源标注的事件抽取系统,包括:数据采集终端,事件抽取服务器。
- 还没有人留言评论。精彩留言会获得点赞!