文件中单据的归档方法及装置、存储介质、计算机设备与流程
本发明涉及文件处理,适用于金融领域,特别是涉及一种文件中单据的归档方法及装置、存储介质、计算机设备。
背景技术:
1、金融机构和企业每天都需要处理大量的文件,其中包括多页pdf文件,一份pdf文件中可能会同时包含多种类型的单据(如合同、订单、发票、报关单等),对这些单据进行类型划分和归档是金融业务中的第一步也是关键一步。
2、目前,采用传统的文档分类和归档系统对这些单据进行划分处理。但是,传统的文档分类和归档系统通常依赖于ocr(光学字符识别)技术,这种技术可能受到文档质量、语言和格式的限制。此外,ocr处理需要大量计算资源和时间,而且可能引入识别错误,降低了对文件中各类型单据的划分和归档处理的处理效率和准确性。
技术实现思路
1、有鉴于此,本发明提供一种文件中单据的归档方法及装置、存储介质、计算机设备,主要目的在于解决现有技术依赖ocr对文档进行划分和归档导致的处理效率低和准确性不高的问题。
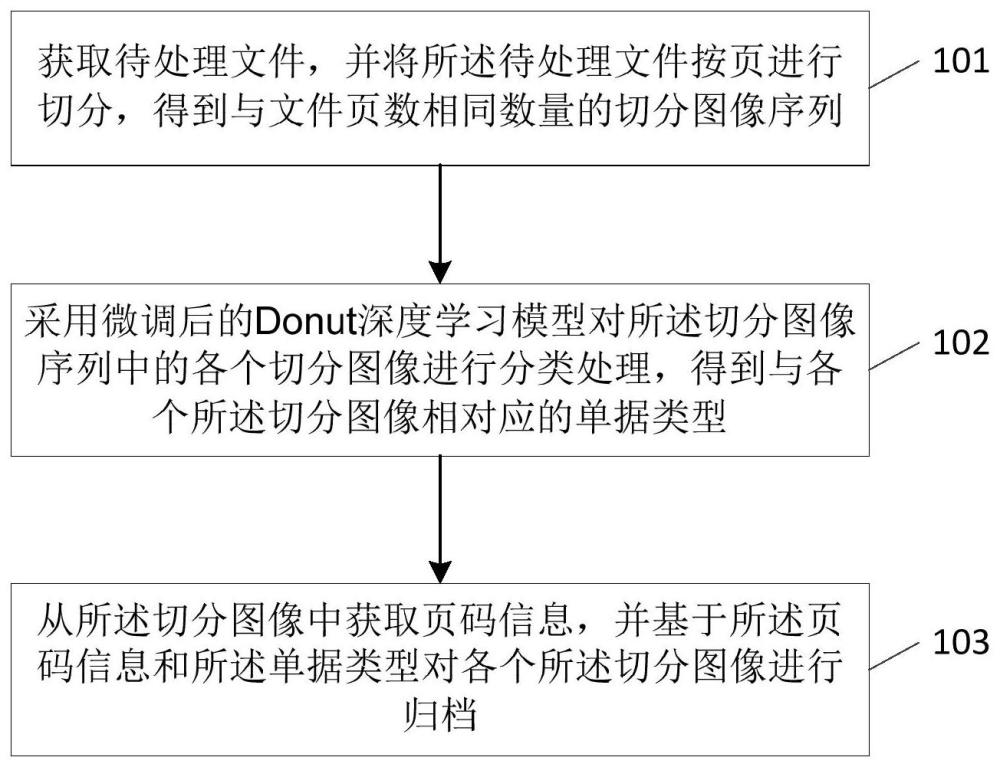
2、依据本发明一个方面,提供了一种文件中单据的归档方法,包括:
3、获取待处理文件,并将所述待处理文件按页进行切分,得到与文件页数相同数量的切分图像序列;
4、采用微调后的donut深度学习模型对所述切分图像序列中的各个切分图像进行分类处理,得到与各个所述切分图像相对应的单据类型;
5、从所述切分图像中获取页码信息,并基于所述页码信息和所述单据类型对各个所述切分图像进行归档。
6、进一步的,所述采用微调后的donut深度学习模型对所述切分图像进行分类处理之前,所述方法还包括:
7、采集各种单据类型的样本文件,并为所述样本文件添加类别标签,生成样本数据集;
8、将所述样本数据集中的样本按比例划分为训练集、测试集和验证集;
9、基于所述训练集、所述测试集和所述验证集分别对预训练donut深度学习模型进行训练、测试和验证操作,并基于训练、测试和验证的结果对所述预训练donut深度学习模型进行参数微调,得到微调后的所述donut深度学习模型。
10、进一步的,所述采用微调后的donut深度学习模型对所述切分图像序列中的各个切分图像进行分类处理,得到与各个所述切分图像相对应的单据类型之后,所述方法还包括:
11、将所述单据类型与预设的易分错类型集合进行匹配处理;
12、若匹配成功,则从所述切分图像中获取标题内容;
13、基于所述标题内容进行关键词匹配处理,得到关键词匹配结果,并基于所述关键词匹配结果对所述单据类型进行类别纠正。
14、进一步的,所述基于所述标题内容进行关键词匹配处理,得到关键词匹配结果,并基于所述关键词匹配结果对所述单据类型进行类别纠正包括:
15、获取预设的类别关键词列表,所述类别关键词列表包含与各个所述单据类型相对应的类别关键词;
16、对所述标题内容进行分词处理,并将得到的各个标题分词与所述类别关键词列表中的类别关键词一一进行关键词匹配处理,得到所述关键词匹配结果;
17、若所述关键词匹配结果中包含匹配成功的目标类别关键词,则基于所述类别关键词列表将所述单据类型纠正为与所述目标类别关键词所对应的目标单据类型。
18、进一步的,所述将所述单据类型与预设的易分错类型集合进行匹配处理之前,所述方法还包括:
19、获取各种单据类型的版式;
20、比较所述版式之间的相似性,并基于相似性比较结果确定易分错类型;
21、将所述易分错类型进行合并处理,生成所述易分错类型集合。
22、进一步的,所述基于所述页码信息和所述单据类型对各个所述切分图像进行归档包括:
23、获取属于同一单据类型的连续切分图像,并基于所述页码信息从所述连续切分图像中确定出首页图像;
24、按照所述首页图像在所述连续切分图像中的位置,确定属于同一份单据的所有待归档图像;
25、将属于同一份单据的所有待归档图像进行组合,得到组合单据;并按照对应的单据类型对所述组合单据进行归档。
26、进一步的,所述方法还包括:
27、从所述组合单据中获取标准化命名信息,包括标题内容、日期信息和版本号信息;
28、基于所述标准化命名信息对所述组合单据进行标准化命名处理。
29、依据本发明另一个方面,提供了一种文件中单据的归档装置,包括:
30、切分模块,用于获取待处理文件,并将所述待处理文件按页进行切分,得到与文件页数相同数量的切分图像序列;
31、分类模块,用于采用微调后的donut深度学习模型对所述切分图像序列中的各个切分图像进行分类处理,得到与各个所述切分图像相对应的单据类型;
32、归档模块,用于从所述切分图像中获取页码信息,并基于所述页码信息和所述单据类型对各个所述切分图像进行归档。
33、进一步的,所述装置还包括模型微调模块,用于:
34、采集各种单据类型的样本文件,并为所述样本文件添加类别标签,生成样本数据集;
35、将所述样本数据集中的样本按比例划分为训练集、测试集和验证集;
36、基于所述训练集、所述测试集和所述验证集分别对预训练donut深度学习模型进行训练、测试和验证操作,并基于训练、测试和验证的结果对所述预训练donut深度学习模型进行参数微调,得到微调后的所述donut深度学习模型。
37、进一步的,所述装置还包括纠正模块,用于:
38、将所述单据类型与预设的易分错类型集合进行匹配处理;
39、若匹配成功,则从所述切分图像中获取标题内容;
40、基于所述标题内容进行关键词匹配处理,得到关键词匹配结果,并基于所述关键词匹配结果对所述单据类型进行类别纠正。
41、进一步的,所述纠正模块还用于:
42、获取预设的类别关键词列表,所述类别关键词列表包含与各个所述单据类型相对应的类别关键词;
43、对所述标题内容进行分词处理,并将得到的各个标题分词与所述类别关键词列表中的类别关键词一一进行关键词匹配处理,得到所述关键词匹配结果;
44、若所述关键词匹配结果中包含匹配成功的目标类别关键词,则基于所述类别关键词列表将所述单据类型纠正为与所述目标类别关键词所对应的目标单据类型。
45、进一步的,所述纠正模块还用于:
46、获取各种单据类型的版式;
47、比较所述版式之间的相似性,并基于相似性比较结果确定易分错类型;
48、将所述易分错类型进行合并处理,生成所述易分错类型集合。
49、进一步的,所述归档模块还用于:
50、获取属于同一单据类型的连续切分图像,并基于所述页码信息从所述连续切分图像中确定出首页图像;
51、按照所述首页图像在所述连续切分图像中的位置,确定属于同一份单据的所有待归档图像;
52、将属于同一份单据的所有待归档图像进行组合,得到组合单据;并按照对应的单据类型对所述组合单据进行归档。
53、进一步的,所述归档模块还用于:
54、从所述组合单据中获取标准化命名信息,包括标题内容、日期信息和版本号信息;
55、基于所述标准化命名信息对所述组合单据进行标准化命名处理。
56、依据本发明的又一方面,提供了一种存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述文件中单据的归档方法对应的操作。
57、依据本发明另一个方面,提供了一种计算机设备,包括处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
58、所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行如上述文件中单据的归档方法对应的操作。
59、借由上述技术方案,本发明实施例提供的技术方案至少具有下列优点:
60、本发明提供了一种文件中单据的归档方法及装置、存储介质、计算机设备,与现有技术相比,本发明通过获取待处理文件,并将所述待处理文件按页进行切分,得到与文件页数相同数量的切分图像序列;采用微调后的donut深度学习模型对所述切分图像序列中的各个切分图像进行分类处理,得到与各个所述切分图像相对应的单据类型;从所述切分图像中获取页码信息,并基于所述页码信息和所述单据类型对各个所述切分图像进行归档,实现了对包含了多种类型单据的多页文件的单据分类和归档。本发明使用donut模型代替ocr技术,不仅减少了由ocr技术带来的分类误差,提高了文档分类的准确性;还减少了计算资源的需求,加速了文件处理过程,提高了处理效率。此外,donut模型能够处理不同语言的文档,降低了文件处理的语言限制。
61、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!