保持数据和语义一致性的跨模态哈希检索方法及系统
本发明主要涉及计算机信息检索,具体涉及一种保持数据和语义一致性的跨模态哈希检索方法及系统。
背景技术:
1、随着计算机技术的不断发展,多媒体数据呈爆炸式增长,数据表现形式越来越多样。为了从大规模多模态数据中快速有效的检索相应信息,跨模态检索成为一个重要的研究课题。面对不断增长的数据量,传统的跨模态检索方法由于计算成本太高变得不切实际。哈希方法将数据点映射到汉明空间中获取紧凑的低维表示,并在原始特征空间中保留它们的相似性,在汉明空间中使用异或运算可以加快搜索速度。同时,由于使用二进制编码,大大降低了计算成本和存储开销。因此,哈希技术被广泛用于跨模态检索,许多跨模态哈希方法被提出并广泛应用于信息检索、推荐系统和其他领域。
2、跨模态哈希方法将不同模态的数据映射到同一特征空间中以实现跨模态的数据匹配和检索,根据其学习方式可以分为无监督方法和有监督方法。无监督方法不需要利用监督信息,仅利用数据本身的特征进行学习,然而由于数据的多样性和复杂性,无监督方法学习到的哈希码判别性较差。有监督方法使用有标签的数据进行训练,有助于学习更具辨别力的特征,因此有监督方法通常可以获得更好的检索性能(如scratch方法利用集体矩阵分解和标签的语义嵌入来探索潜在的语义空间,以保持哈希码的模态内和模态间相似性;alech方法自适应地利用高阶语义标签相关性引导潜在特征学习,提高了跨模态检索效果)。然而现有的大多数方法主要集中在共享子空间中保持异构模态之间的语义相似性,通常忽略了一定的数据底层特征和语义潜在相关性,从而不能充分保持跨模态数据的数据和语义一致性。为了避免使用成对相似性矩阵造成的高计算复杂度和内存开销,srlch等方法仅使用语义标签信息来监督哈希码的学习,由于没有充分利用监督信息,部分忽略了标签的语义相关性,从而降低了检索结果。此外,大多数算法通过放松二进制限制来解决实值空间中的二进制优化问题,对获得的实值解进行阈值处理,产生二进制哈希码。这种两阶段过程有可能造成大的量化误差并生成不理想的哈希码。这些方法在数据匹配和检索的准确性还不够理想,尚需进一步改进和优化。因此,亟需提供一种能充分保持多模态数据和语义一致性且能学习和生成更优哈希码的跨模态哈希检索方法及系统。
技术实现思路
1、本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种。
2、为解决上述技术问题,本发明提出的技术方案为:
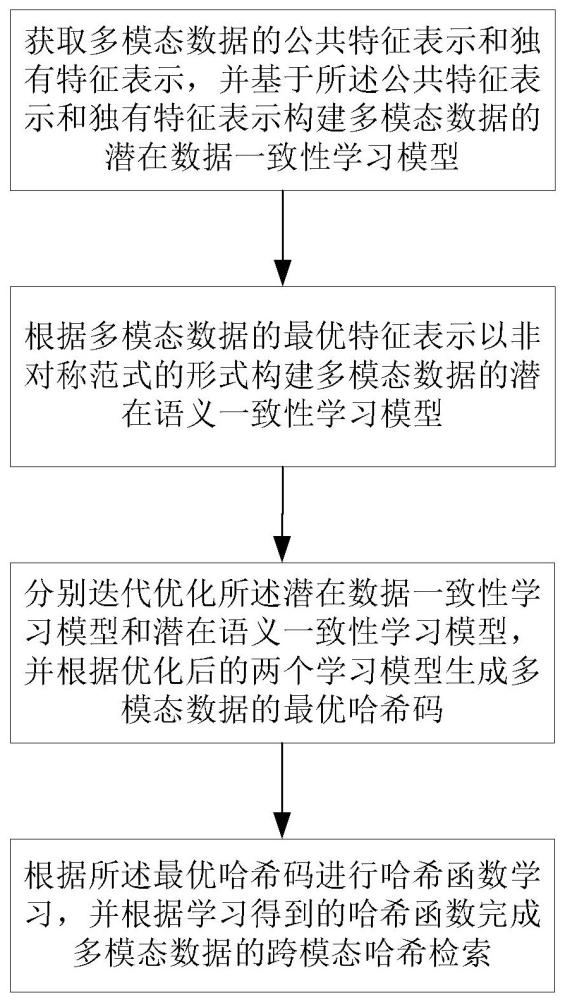
3、一种保持数据和语义一致性的跨模态哈希检索方法,包括步骤:
4、s101,获取多模态数据的公共特征表示和独有特征表示,并基于所述公共特征表示和独有特征表示构建多模态数据的潜在数据一致性学习模型;
5、s102,根据多模态数据的最优特征表示以非对称范式的形式构建多模态数据的潜在语义一致性学习模型;
6、s103,分别迭代优化所述潜在数据一致性学习模型和潜在语义一致性学习模型,并根据优化后的两个学习模型生成多模态数据的最优哈希码;
7、s104,根据所述最优哈希码进行哈希函数学习,并根据学习得到的哈希函数完成多模态数据的跨模态哈希检索。
8、作为上述技术方案的进一步改进:
9、步骤s101包括步骤:
10、对多模态数据进行核化,以获得多模态数据的非线性结构;
11、通过协同语义标签矩阵分解将多模态数据映射到一个公共的潜在语义空间,以获得多模态数据的公共特征表示;
12、通过独有语义标签矩阵分解将多模态数据中的每个模态数据投影到该模态独有的潜在语义空间,以获得每个模态数据的独有特征表示;
13、根据所述公共特征表示和独有特征表示构建多模态数据的潜在数据一致性学习模型,以获得多模态数据的最优特征表示。
14、对多模态数据进行核化的函数表达式为:
15、,
16、上式中,k∈{1,2},分别表示图像和文本模态,为第k种模态的数据特征,为随机选择的个锚点的样本,为设定的锚点个数,为高斯核函数;
17、所述协同语义标签矩阵分解的函数表达式为:
18、,
19、上式中,为矩阵分解的基本矩阵,为矩阵分解的投影辅助矩阵,为标签矩阵,为图像和文本模态的特征矩阵,为第k种模态的平衡参数;
20、所述独有语义标签矩阵分解的函数表达式为:
21、,
22、上式中,为第k种模态的矩阵分解的基本矩阵,为第k种模态的矩阵分解的投影辅助矩阵,为相关矩阵,为非负权衡参数,为图像模态的矩阵分解的投影辅助矩阵,为文本模态的矩阵分解的投影辅助矩阵;
23、所述潜在数据一致性学习模型的函数表达式为:
24、,
25、上式中,表示避免过拟合的正则化项,和为非负权衡参数;
26、所述最优特征表示的函数表达式为:
27、。
28、步骤s102包括步骤:
29、通过最小化正交变换后哈希码和投影矩阵之间的量化损失学习哈希码以得到第一哈希码学习表示,并以汉明亲和力保持为目标学习哈希码以得到第二哈希码学习表示;
30、通过非对称相似性矩阵优化第二哈希码学习表示,根据优化后的第二哈希码学习表示及最优特征表示构建多模态数据的潜在语义一致性学习模型。
31、所述第一哈希码学习表示的函数表达式为:
32、s.t.,
33、上式中,为训练集的统一哈希码矩阵,为正交旋转矩阵,为单位矩阵,为最优特征表示;
34、所述第二哈希码学习表示的函数表达式为:
35、s.t.,
36、上式中,为统一哈希码的长度,为训练集的数据量,为成对语义相似矩阵;
37、所述潜在语义一致性学习模型的函数表达式为:
38、,
39、上式中,为辅助实值矩阵,为非负权衡参数。
40、步骤s103中,分别迭代优化所述潜在数据一致性学习模型和潜在语义一致性学习模型,包括步骤:
41、依次更新所述潜在数据一致性学习模型中的每个变量,在更新其中一个变量时固定其他变量,并在判断到所述潜在数据一致性学习模型的目标函数收敛时停止更新,以得到所述潜在数据一致性学习模型的目标函数收敛时的最优特征表示;
42、根据所述最优特征表示更新潜在语义一致性学习模型,依次更新所述潜在语义一致性学习模型中的每个变量,在更新其中一个变量时固定其他变量,并在判断到所述潜在语义一致性学习模型的目标函数收敛时停止更新,以得到优化后的潜在语义一致性学习模型。
43、所述依次更新所述潜在数据一致性学习模型中的每个变量,包括步骤:
44、更新,固定和,得到的闭式解为:
45、,
46、上式中,为非负权衡参数;
47、更新,固定和,得到的闭式解为:
48、;
49、更新,固定和,得到的闭式解为:
50、;
51、更新,固定和,得到的闭式解为:
52、,
53、上式中,为第一模态的平衡参数;
54、更新,固定和,得到的闭式解为:
55、,
56、上式中,为第二模态的平衡参数;
57、更新,固定和,得到的闭式解为:
58、;
59、所述依次更新所述潜在语义一致性学习模型中的每个变量,包括步骤:
60、更新,固定,采用奇异值分解得到的解为:
61、,
62、上式中,为酉矩阵;
63、更新,固定,通过辅助实值矩阵替代,得到的闭式解为:
64、,
65、上式中,是符号函数,为全为1的列向量,为非负权衡参数,为辅助矩阵变量;
66、更新,固定,得到的闭式解为:
67、。
68、步骤s104包括步骤:
69、使用图像和文本模态的特征矩阵和学习的哈希码来训练个二进制分类器,学习过程的目标函数表达式为:
70、,
71、上式中,为第k种模态的最优投影矩阵,表示从核特征到哈希码的线性映射矩阵,为非负权衡参数;
72、得到的最优解为:
73、;
74、在根据学习得到的哈希函数完成多模态数据的跨模态哈希检索过程中,通过使用映射矩阵得到哈希码,其中哈希函数的表达式为:
75、,
76、上式中,表示第k种模态的检索项,表示核化特征提取。
77、本发明还提供一种保持数据和语义一致性的跨模态哈希检索系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行上述保持数据和语义一致性的跨模态哈希检索方法。
78、本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行上述保持数据和语义一致性的跨模态哈希检索方法。
79、与现有技术相比,本发明的优点在于:
80、本发明通过潜在数据一致性学习和潜在语义一致性学习的两步学习法来学习多模态数据的哈希码,可以最大化地保持多模态数据的数据和语义一致性,从而提高跨模态检索效果;通过同时保留多模态数据的公共特征和独有特征,并构建潜在数据一致性学习模型,可以同时兼顾不同模态数据间的公共特征及每种模态数据的独有特征,避免由于忽略某些数据底层特征和语义潜在相关性,对潜在语义空间学习产生不利影响;通过非对称范式的形式构建多模态数据的潜在语义一致性学习模型,可以降低量化误差,从而减小量化误差对哈希码的学习和生成产生的不利影响。
- 还没有人留言评论。精彩留言会获得点赞!