一种中医证候归属分类方法及其数据库系统
本发明属于数字化医药技术,具体涉及一种中医证候归属分类方法及其数据库系统。
背景技术:
1、个性化诊断和治疗在医学领域日益受到关注。而中医基于“证”的辨证论治代表着最古老的个性化医疗体系,侧重于根据个体因素进行诊断和治疗。中医的“证”是指在疾病不同阶段的病理生理差异的总结性理解,考虑了病性、病位等因素。根据每一患者所表现出的“证”来开具特定的中药处方。例如,根据中医理论,抑郁症可以根据患者症状/体征被分类为多个亚型(“证”),包括肝气郁结型、肝郁脾虚型、气虚血瘀型等。然后根据患者的具体“证”提供不同的治疗策略,例如,肝气郁结亚型使用调理气的处方,气虚血瘀亚型使用益气活血处方。多项现代研究已证明中医辩证论治在疗效方面体现出优越性,然而,“证”的确定在很大程度上依赖于中医医师在提取和分析症状/体征中隐含信息方面的经验,这种主观方法可能缺乏足够的客观性和准确性最终导致人类在正确诊断和治疗方面的有限经验及认识的深度上限制了中医理论的个性化治疗的发展。因此,有必要找到一种能够促进中医“证”客观化和准确性的方法和范式。人工智能(ai)的迅速发展使得大数据集的训练和分析成为可能,从而推动了个性化医学的进展。目前ai已经应用于探索中药草性能与其作用之间的具体关系。但尚缺乏将ai应用于中医证候分类判断方面的研究。这种应用ai对中医临床的疾病个性化诊疗积累的大量经验和数据进行推算而得的方法和范式可以对疾病的不同证型进行诊断,并且确定相应最佳治疗方案,此方法的应用将推动中医临床应用的传承和发展。
技术实现思路
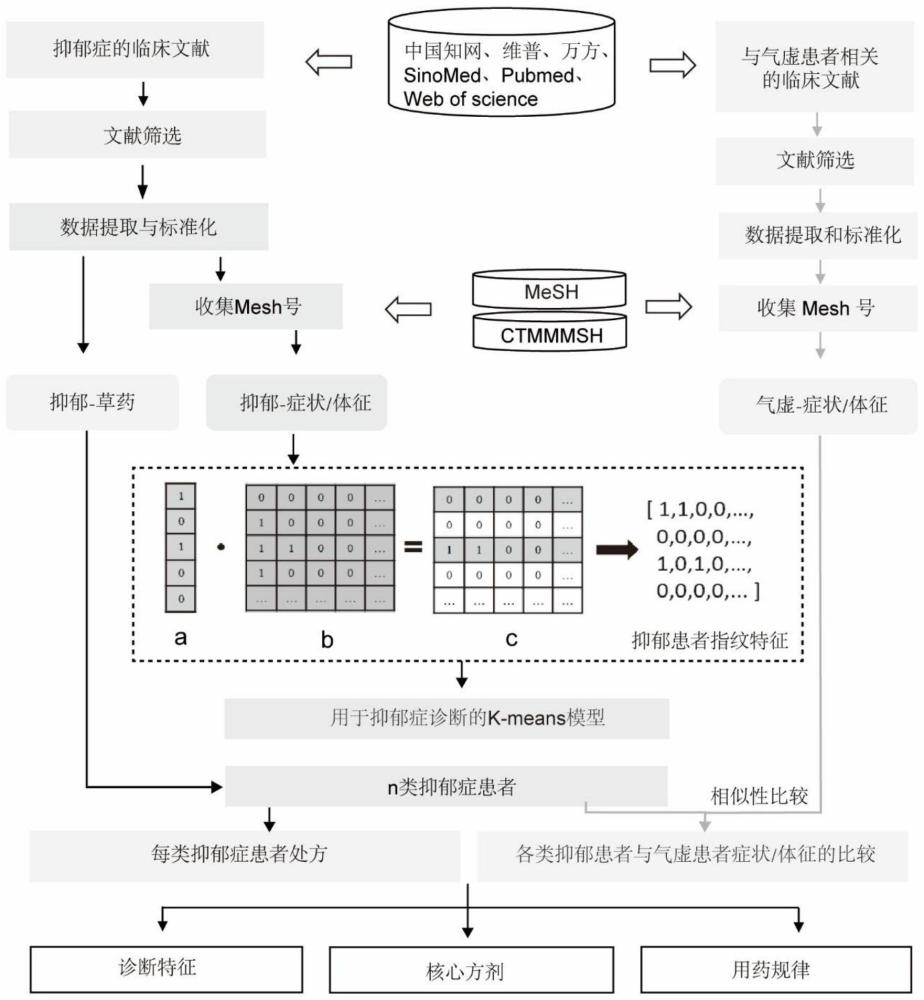
1、为克服以上技术缺陷,本发明提供了一种中医证候归属分类方法,该方法的主要构思:收集和筛选某种疾病的症状/体征数据集及其对应的治疗中药数据集,建立抑郁症病人症状/体征及所用方药的mysql数据库,将症状/体征信息向量化表示,基于医学主题词(mesh)和《中国中医药学主题词表》(ctmmmsh)的层次规则所隐含的关联,通过无监督聚类算法,对疾病进行了不同亚型的重新分类,从而科学分析该疾病的证候分类及挖掘目前尚未认知的证候类型。
2、具体技术方案包括以下步骤:
3、1.文献的收集和筛选:收集和筛选与疾病有关,具有明确治疗效果,并记载病例症状和体征信息的中药治疗临床文献;
4、2.文献信息的提取与标准化:将上述文献记载的每个病例的症状、体征和对应的用药信息进行提取和标准化;并对上述信息进行频率分析,创建疾病症状、体征数据集和用药信息数据集,导入mysql数据库储存;
5、3.疾病患者聚类:根据上述疾病症状、体征数据集,采用无监督的k-means计算模型,将疾病患者分为不同的组别;
6、4.对患者组别用药规律分析,推导对应组别的证候类别:根据上述用药信息数据集,组别中使用频率高的中药,推导出各个组别的用药核心配方及功效,由此推导对应组别的证候类别;
7、5.证候类别的验证:比较不同组别与传统中医同一证候的症状/体征相似性,对上述推导的证候类别进行验证。
8、其中,所述文献的来源包括中国知网、维普网、中国医学信息网、万方网、pubmed、web of science数据库。
9、所述文献的筛选优选方法:使用knime 5.4处理收集到的文献,并以统一的列对数据表进行连接;按文献纳入标准,通过比较标题栏和摘要栏,剔除了冗余文献;将改进后的文献列表导入zotero 6.0,并下载文章全文,以创建一个本地文献数据库,用于数据提取;
10、所述文献信息的优选标准化方法为:对于症状和体征的标准化,,icd-11《国际疾病分类》第11次修订版、《中国中医药学主题词表》(ctmmmsh)和symmap数据库中提供的分类标准,然后根据mesh、ctmmmsh获取每个症状/体征的树形结构号;对于用药信息的标准化,以《中华人民共和国药典》和《中华本草》为依据,对用药信息的中药的名称进行标准化处理。
11、所述无监督的k-means计算模型的优选建立方法,包括以下步骤:
12、1.症状或体征层次关系矩阵的建立:将树形结构号的从属关系转换为布尔从属关系,对于每种关系,根据以下公式进行计算,将其表示为"0"或"1",
13、
14、其中x和y是疾病症状或体征的树形结构号;其布尔值构成一个二维矩阵,代表疾病症状或体征的树形结构号的层次关系;通过该矩阵可以确定给定的x是否属于层次结构中的y;
15、2.患者指纹向量的构建:将每个疾病患者的症状/体征转化为表型向量,其中载体中的值表示为0或1,值1表示患者表现出特定的症状/体征,而值0表示没有该症状/体征;通过在表型向量和症状/体征分级关系矩阵之间进行点乘,捕获了单个疾病患者的所有分级信息,将得到的点积矩阵进行扁平化处理,并用值0修剪维度以创建指纹向量;
16、3.无监督机器学习:使用python 3.9脚本中的sklearn.cluster.kmeans包实现了k-means聚类算法,将指纹向量用作聚类算法的输入信息,在k-means聚类过程中,计算余弦距离来测量指纹向量之间的相似性;无监督聚类的结果被可视化为3d散点图,选择轮廓系数作为聚类算法的评价指标,使用以下公式计算:
17、
18、式中s:所有样本的平均轮廓系数;a:每个样本的平均簇内距离;b:样本和最近的不属于该样本的聚类之间的距离。
19、所述的患者组别用药规律分析的优选方法为:从用药信息数据集中检索与疾病患者相对应的处方,使用knime 5.4分析每个患者组别中每种中药的类别和贡献;选择每个患者组别中使用频率最高的前20种中药,并参考《中医药学高级丛书:方剂学》确定核心方剂及中药的功效类别,由此推导对应组别的证候类别;
20、所述的证候类别的验证优选方法为:使用knime 5.4计算步骤1.4所推导的对应组别的证候类别中症状/体征的贡献,其中,症状/体征的贡献被定义为该症状/体征发生的频率除以在某一组别中观察到的症状/体征总数;并计算传统中医同一证候与每个组别之间的症状/体征的值平方偏差vsd,平方偏差vsd根据以下方程式计算:
21、
22、其中,ai表示:传统中医同一证候的贡献,bi表示:推导的对应组别的证候类别中症状/体征的贡献,最后依据平方偏差vsd验证步骤1.4所推导的对应组别的证候类别的正确性。
23、在上述分类方法的基础上,本发明进一步公开其数据库系统。
24、该数据库系统包括以下模块:
25、1.文献的收集和筛选模块:该模块与文献数据库或本地数据库关联,收
26、集和筛选其中与疾病有关,具有明确治疗效果,并记载病例症状/体征信息的中药治疗临床文献;
27、2.文献信息的提取与标准化处理模块:该模块将上述文献记载的每个病例的症状/体征和对应的用药信息进行提取并参考现行的标准分类指南给每个症状/体征分配树形结构号进行标准化;再对上述信息进行频率分析,分析后的数据以独立数据集的形式存储在mysql数据库中,创建疾病症状/体征数据集和用药信息数据集;
28、3.疾病患者聚类分析处理模块:该处理模块根据上述疾病症状/体征数据集,将症状/体征分配树形结构号进行矢量化,构建疾病患者指纹向量,以指纹向量用作聚类算法的输入信息,采用上述分类方法所述的无监督k-means计算模型,计算余弦距离来测量指纹向量之间的相似性,将疾病患者分为不同的组别;
29、4.患者组别用药规律分析模块:该模块从用药信息数据集中检索与疾病患者相对应的处方,使用knime 5.4分析每个患者组别中每种中药的类别和贡献,根据贡献大小确定组别中使用频率高的中药,推导出各个组别的用药核心方剂及功效,由此推导对应组别的证候类别;
30、5.证候类别验证模块:该模块收集与上述推导对应组别的证候类别一致的传统中医证候的中医文献,进一步提取和标准化所述文献中的症状/体征名称,并对症状/体征进行频率分析,建立该传统中医证候的症状/体征数据集,与上述推导对应组别的证候类别的症状/体征的相似性,对上述推导的证候类别进行验证,并输出结果。
31、在现有技术中,ai诊断和治疗模型往往忽视了症状/体征之间的关系,导致数据来源不准确,限制了机器学习的深度。无监督聚类算法是一种经典的ai方法,不依赖预定义的标签,有潜力根据人体固有原则对症状/体征进行分类。通过消除分类过程中的人为偏见,这些算法能够更准确地建立疾病的客观亚型。在mesh库和《中国中医药学主题词表》中,每个主题词都可以由一个或多个树形结构号来描述,从而标示它在层次树结构中的位置以及与其他主题词之间的相互关系。结合本发明,利用树形结构号可揭示症状/体征之间的潜在的深层关联关系,可满足将中医辨证理念应用于现代医学中疾病不同类型的要求。本发明建立特殊的ai计算模型,挖掘临床文献研究中病人全部的症状/体征,对患者进行客观分型,挖掘目前尚未认知的证候类型及中药治疗的用药规律,为中医药领域的研究和数据化提供新的途径和方法。进一步地,本发明还可为建立新型的数字化中医诊疗模式提供辅助作用,促进中医学的传承与发展。
- 还没有人留言评论。精彩留言会获得点赞!