一种基于语义学习的档案密级鉴定方法及系统与流程
本发明属于档案密级鉴定,具体涉及一种基于语义学习的档案密级鉴定方法及系统。
背景技术:
1、随着社会的发展与进步,社会对档案资源的利用需求日益增长。推动档案密级鉴定是档案事业高质量发展的重要一环。档案密级鉴定工作是档案开放的前提。提升档案密级鉴定工作水平对提高档案工作的知名度、优化档案服务质量、维护社会主体使用档案的权力具有重要价值与意义。
2、现有技术中,大多借助人工方式,对档案进行密级鉴定,这种方式人力成本投入大,工作量大,并且效率低下;随着计算机技术的发展,一些智能关键词识别技术被运用至档案密级鉴定领域中,但是,现有的档案密级鉴定智能技术,通过识别涉密关键词,进而进行档案密级鉴定,这种方式容易将带有涉密关键词而档案本身不涉密的文档误判为涉密内容,准确率低下。
技术实现思路
1、为了解决现有技术存在的人力成本投入大,工作量大以及准确性低的问题,本发明目的在于提供一种基于语义学习的档案密级鉴定方法及系统。
2、本发明所采用的技术方案为:
3、一种基于语义学习的档案密级鉴定方法,包括如下步骤:
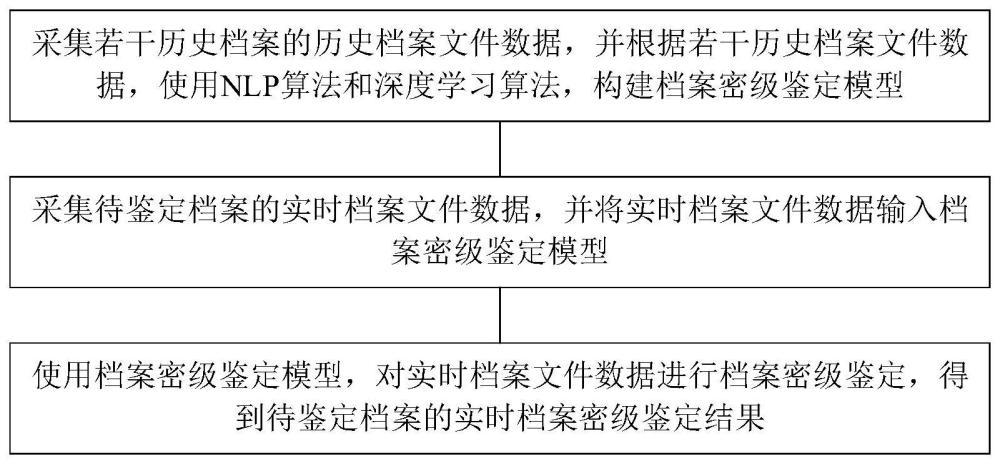
4、采集若干历史档案的历史档案文件数据,并根据若干历史档案文件数据,使用nlp算法和深度学习算法,构建档案密级鉴定模型;
5、采集待鉴定档案的实时档案文件数据,并将实时档案文件数据输入档案密级鉴定模型;
6、使用档案密级鉴定模型,对实时档案文件数据进行档案密级鉴定,得到待鉴定档案的实时档案密级鉴定结果。
7、进一步地,采集若干历史档案的历史档案文件数据,并根据若干历史档案文件数据,使用nlp算法和深度学习算法,构建档案密级鉴定模型,包括如下步骤:
8、采集若干历史档案的历史档案文件数据,并对若干历史档案文件数据进行数据预处理,得到若干数据预处理后历史档案文件数据;数据预处理后历史档案文件数据包括历史档案的历史元数据和对应的历史扫描图像数据;
9、根据若干数据预处理后历史档案文件数据的历史元数据,使用元数据解析工具,构建元数据解析模块,并生成对应的若干历史著录项列表数据;历史著录项列表数据包括若干历史著录项数据;
10、根据若干数据预处理后历史档案文件数据的历史扫描图像数据,使用orc算法,构建文本识别子模型,并生成对应的若干历史正文文本识别数据和若干历史涉密标识识别结果;
11、整合元数据解析工具和文本识别子模型,构建数据处理层;
12、筛选历史著录项列表数据中关键的历史著录项数据,并对关键的历史著录项数据和对应的历史正文文本识别数据进行特征融合,得到若干历史特征融合字符序列;
13、根据若干历史特征融合字符序列,使用nlp算法,构建词嵌入层,并生成对应的若干历史词向量序列;
14、根据预设的涉密关键词语料库,对若干历史词向量序列进行标签添加,得到数据预处理后历史档案文件数据对应的涉密关键词预设标签;
15、根据若干历史词向量序列,使用深度学习算法,构建特征提取层,并生成对应的若干历史语义图特征;
16、根据若干历史语义图特征,使用集成学习算法,构建输出层,并生成对应的若干历史涉密关键词预测标签;
17、依次连接数据处理层、词嵌入层、特征提取层以及输出层,构建初始的档案密级鉴定模型;
18、根据若干历史涉密关键词预测标签和对应的若干涉密关键词预设标签,获取模型预测准确率;
19、若模型预测准确率大于准确率阈值,则输出最终的档案密级鉴定模型,否则,重新训练档案密级鉴定模型。
20、进一步地,使用orc算法,构建文本识别子模型,包括,根据若干数据预处理后历史档案文件数据的历史扫描图像数据,使用ctpn-ncrnn算法,构建文本识别子模型,并生成对应的若干历史正文文本识别数据和若干历史涉密标识识别结果。
21、进一步地,关键的历史著录项数据包括历史档案对应的历史题名数据、历史形成机构数据以及历史形成时间数据。
22、进一步地,使用nlp算法,构建词嵌入层,包括,根据若干历史特征融合字符序列,使用bert算法,构建词嵌入层,并生成对应的若干历史词向量序列。
23、进一步地,使用深度学习算法,构建特征提取层,包括,根据若干历史词向量序列,使用bilstm-attention-gat-crf算法,构建特征提取层,并生成对应的若干历史语义图特征。
24、进一步地,使用iwoa优化算法,对特征提取层的bilstm网络和gat网络进行优化。
25、进一步地,使用集成学习算法,构建输出层,包括,根据若干历史语义图特征,使用rf算法,构建输出层,并生成对应的若干历史涉密关键词预测标签。
26、进一步地,使用档案密级鉴定模型,对实时档案文件数据进行档案密级鉴定,得到待鉴定档案的实时档案密级鉴定结果,包括如下步骤:
27、使用数据处理层,获取实时档案文件数据的实时关键著录项数据、实时正文文本识别数据以及实时涉密标识识别结果;
28、对实时关键著录项数据和实时正文文本识别数据进行特征融合,得到实时特征融合字符序列;
29、使用词嵌入层,将实时特征融合字符序列转换为对应的实时词向量序列;
30、使用特征提取层,提取实时词向量序列对应的实时语义图特征;
31、使用输出层,对实时语义图特征进行分类,得到对应的实时涉密关键词预测结果;
32、根据实时涉密标识识别结果和对应的实时涉密关键词预测结果,生成待鉴定档案的实时档案密级鉴定结果。
33、一种基于语义学习的档案密级鉴定系统,用于实现档案密级鉴定方法,系统包括依次连接的档案密级鉴定模型构建单元、档案文件数据采集单元以及档案密级鉴定单元;
34、档案密级鉴定模型构建单元,用于采集若干历史档案的历史档案文件数据,并根据若干历史档案文件数据,使用nlp算法和深度学习算法,构建档案密级鉴定模型;
35、档案文件数据采集单元,用于采集待鉴定档案的实时档案文件数据,并将实时档案文件数据输入档案密级鉴定模型;
36、档案密级鉴定单元,用于使用档案密级鉴定模型,对实时档案文件数据进行档案密级鉴定,得到待鉴定档案的实时档案密级鉴定结果。
37、本发明的有益效果为:
38、本发明公开了一种基于语义学习的档案密级鉴定方法及系统,通过使用nlp算法和深度学习算法,构建档案密级鉴定模型,实现了对待鉴定档案的自动、高效档案密级鉴定,避免了依靠人工方式,降低了人力成本投入,减轻了工作量;档案密级鉴定模型进行ocr目标检测涉密标识,进行ocr文本识别多种字体的文本数据,进行语义学习重复提取档案文本中的涉密关键词信息,根据语义图特征进行密级鉴定预测,提高了档案密级鉴定的准确率,避免将带有涉密关键词而档案本身不涉密的文档误判为涉密内容。
39、本发明的其他有益效果将在具体实施方式中进一步进行说明。
- 还没有人留言评论。精彩留言会获得点赞!