基于深度学习技术的跨模态哈希检索方法
本发明涉及跨模态检索,尤其涉及一种基于深度学习技术的跨模态哈希检索方法。
背景技术:
1、随着科技的快速发展,互联网中的图片、文本、音频和视频等多媒体数据呈爆发式增长。每类数据具有各自的分布和内在含义,也被称为多模态数据。在海量的多模态信息中,有效并高效地搜索感兴趣的信息愈发重要。对于一个事件或主题,可以用不同模态的数据来描述,从而获得更加全面的理解。随着跨模态数据量的不断增加,在存储空间和检索速度方面带来了新的挑战。跨模态检索即为使用一种模态数据查询另一种模态数据,跨模态检索在人们的日常生活中被普遍使用,如输入一张图片来检索得到关于图片的文字描述。
2、跨模态检索的最大挑战是两种模态的异构。为了把不同模态的数据映射到公共空间,跨模态检索对不同模态的数据进行语义向量化表示,在公共空间中实现对不同模态数据的相似性计算,从而得到和一种模态相似的另一种模态的数据。随着数据量的迅猛增长,需要存储的数据越来越多,进行跨模态检索所需要耗费的时间逐渐增加,超出了用户的预计等待时间。所以除了要考虑跨模态检索的效率,存储空间和检索速度也是需要权衡的方面。
3、根据数据在公共空间中的表示形式不同,跨模态检索在方法上可以分为实值表示学习和二值表示学习两大类。实值表示学习方法学习到的模态表征数据是实值的,二值表示学习方法即为哈希方法,把不同模态的数据映射到一个公共汉明空间,以二值哈希码形式存储特征向量,由于哈希码的长度较短,且在进行哈希码相似度计算时可以通过异或运算完成,所以在汉明空间进行相似度计算的效率更高,检索速度更快。因此跨模态哈希方法可以大幅缩减跨模态数据特征向量的存储空间和检索时间。
4、对于跨模态哈希检索方法,主要的技术可以大致分为两类:无监督方法和有监督方法。无监督方法的数据实例为成对的图片和文本数据,在学习时着重学习成对跨模态数据的关联,一组中的数据为相似的跨模态数据。由于无监督方法忽略了标志着语义信息的标签,获得的效果是次优的。有监督方法利用数据中包含的多标签监督信息,一组数据实例中包括图片、文本和对应的多标签,判断两条不同模态数据是否相似的依据为这两条数据对应的标签,如果两个标签中有相同的类别,则认为两条数据是相似的,如果两个标签中所有的类别都不相同,则认为两条数据是不相似的。
5、自监督对抗哈希(ssah)(li c,deng c,li n,et al.self-supervisedadversarial hashing networks for cross-modal retrieval[c]//proceedings of theieee conference on computer vision and pattern recognition.2018:4242-4251.)利用自监督的方式将对抗学习纳入模式间哈希方法中消除模态间差异,利用两个对抗网络最大化不同模态间的语义相关和一致性表示,利用自监督语义网络附加在多个标签上的形式发现高级语义信息,并使用这些信息引导特征学习,在公共语义空间和汉明空间中保持模态关系。
6、深度跨模态代理哈希(dcph)(tu r c,mao x l,tu r x,et al.deep cross-modalproxy hashing[j].ieee transactions on knowledge and data engineering,2022.)将类别信息转换为代理哈希码,使每个代理哈希码保存对应类别的语义信息,任意两个标签哈希码的距离应该尽可能的远,利用代理哈希码作为监督信息指导学习的过程。
7、以图片模态和文本模态作为主要研究的两种模态,有监督跨模态检索任务所使用的数据集中的数据实例为成对的图片和文本数据,每对数据都有标签进行标识。标签为由0、1组成的多标签注释,多标签注释中为1的类别即为数据所属的类别,每对数据可以属于多个类别。
8、跨模态数据集由网站上收集的同时出现的数据对组成,然后进行人工多标签标注,其中的文本中的部分单词存在不匹配的问题。词库中除了包含和图片内容相关的单词,还保留了其他类别的单词,如和地点相关的单词(证明图像集合包含在世界各地许多地方拍摄的图像)和与flickr摄影网站相关的单词等。因此,文本中的单词可以被分成两类,与内容相关的单词和与内容无关的单词,其中与内容无关的单词对于完成跨模态检索任务没有裨益,甚至会造成干扰,是跨模态检索任务中的噪声单词,应该被过滤掉。
9、大部分现有方法直接使用数据集中所提供的标签来衡量数据是否相似,通过标签构建由0、1组成的跨模态相似性矩阵。如果不同模态的两条数据对应的标签中有一个类别相同则认为两条数据相似,跨模态相似性矩阵对应位置1;如果不同模态的两条数据对应的标签中所有类别都不同则认为两条数据不相似,跨模态相似性矩阵对应位置0。把包含较多含义的标签信息压缩成仅包含二值的跨模态相似性矩阵,再通过跨模态相似性矩阵来引导不同模态数据特征的学习。跨模态相似性矩阵的构建过程是标签信息压缩后的结果,在压缩过程中产生了较多的信息损失。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于深度学习技术的跨模态哈希检索方法,采用深度学习技术,完成跨模态检索任务。
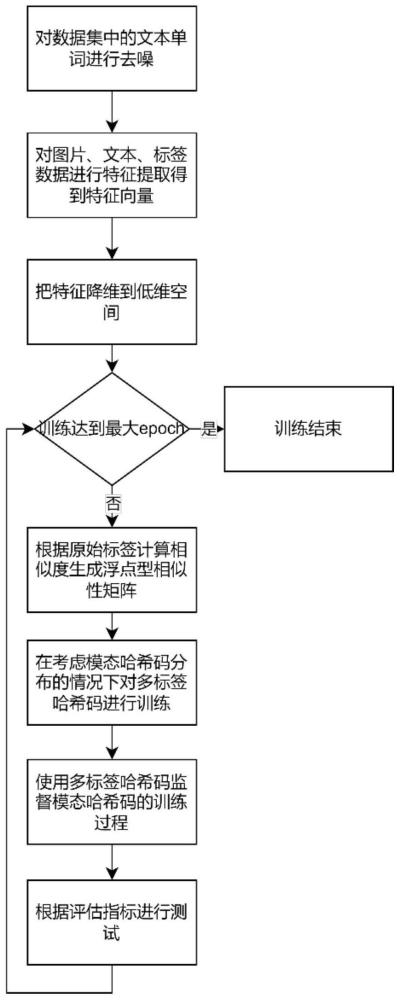
2、为解决上述技术问题,本发明所采取的技术方案是:基于深度学习技术的跨模态哈希检索方法,包括以下步骤:
3、步骤1、将多模态数据集中的数据划分为查询集和检索集两部分,在检索集中划分一部分数据作为训练集,在训练过程中只使用训练集数据进行训练;
4、多模态数据集中一个实例由图像、文本、多标签组成;数据集中的每个图片对应一个文本,每个文本由若干个不连续的单词组成,所有的单词构成词库;每对图像-文本对由包含多个类别的多标签进行标识,即一条模态数据有一个或者多个类别;
5、步骤2、利用clip对多模态数据集中的文本单词进行去噪;
6、首先对多模态数据集中存在的文本数据噪声进行过滤;将文本中的单词分成两类,与内容相关的单词和与内容无关的单词,并过滤掉与内容无关的单词;
7、使用视觉语言预训练模型vlp蕴含的图像文本对的多模态知识,对文本进行去噪,过滤掉与内容无关的单词;为每个单词生成一个特征;选择clip作为vlp模型,从vlp的图像和文本编码器中提取语义多模态知识;特征提取:首先,分别使用图片编码器和文本编码器对数据集中的图片和词库中的单词进行特征提取;计算相似性:将单词特征与图像特征进行比较,clip使用余弦相似度的度量方式来衡量输入图像与单词之间的相似度;选择最不相似的标签:clip根据输入图像和文本之间的相似度,推断出与图像最不相似的单词;
8、步骤3、分别使用图像模态网络、文本模态网络、标签网络对多模态数据集中的图片数据、文本数据、标签数据进行特征提取,得到图片特征向量、文本特征向量和标签特征向量;并将不同模态的特征向量分别通过各自的哈希层生成哈希码;
9、对于图片数据,采用基于深度学习的图像模态网络提取图像特征;所述图像模态网络共有八层,前七层与cnn-f卷积神经网络结构相同,第八层是作为哈希层的全连接层,输出是学习到的图像哈希码;图像模态网络包括五个卷积层和三个全连接层,每一层都使用修正线性单元relu作为激活函数;其中的最后一层将第七层提取到的图像特征向量经过可学习参数矩阵降维映射到k维向量空间,并通过tanh函数的约束生成图像哈希码
10、对于文本数据,采用bow词袋模型和多层感知机mlp构成文本模态网络来提取文本特征;bow词袋模型将文本转化为向量表示,多层感知机mlp包括三层全连接层,第三层全连接层作为哈希层将第二层全连接层输出的文本特征向量经过可学习参数矩阵降维映射到k维向量空间,并通过tanh函数的约束生成文本哈希码
11、通过标签网络,对原始多标签数据进行升维,映射到与模态数据哈希码相同的公共空间中;
12、标签网络包括三层全连接层,在标签网络的最后一层全连接层作为哈希层将第二层全连接层输出的标签特征向量经过可学习参数矩阵升维映射到k维向量空间中,并通过tanh函数的约束生成标签哈希码
13、步骤4、计算原始标签的相似度生成浮点型相似性矩阵;
14、采用余弦相似性的度量方式来计算原始的多标签信息l之间的相似程度,得到浮点相似性监督矩阵s,以表示成对实例的相似性程度信息,如下公式所示:
15、sij=cosine(li,lj)
16、其中,sij为标签信息li、lj之间的相似性,j表示跨模态数据集中第j个实例;
17、步骤5、在考虑模态哈希码分布的情况下对多标签哈希码进行训练;
18、为了保证标签特征在维度改变后语义特征保持不变,采用如下损失函数对多标签在原始空间与哈希码空间之间的余弦相似性差异进行约束,如下公式所示;
19、
20、其中,lmapping表示为了保证标签特征维度变化后语义特征保持不变所采用的损失函数,cosine表示计算余弦相似性,n表示多模态数据集中的实例个数,l表示原始标签向量,hl表示标签哈希码,n为跨模态数据集中实例总数;
21、在浮点型相似性监督矩阵s的监督下,采用成对相关性损失函数lcor来约束标签哈希码hl的分布,使得标签哈希码在生成过程中考虑模态数据的分布;采用浮点型相似性监督矩阵s对标签哈希码自身的语义相似性进行监督学习,提升哈希码的语义表达能力;
22、成对相关性损失函数lcor如下公式所示:
23、
24、其中,k为预先设定好的哈希码长度,分别表示跨模态数据集中第i个实例对应的图像哈希码、文本哈希码和标签哈希码;
25、步骤6、使用多标签哈希码监督模态哈希码的训练过程;
26、为了衡量图像模态数据的多分类预测概率和标签向量分布之间的差异,对分类预测向量和标签向量进行归一化操作;
27、将图像特征向量通过全连接层映射到与原始标签维度c相同的空间中,再经过softmax函数计算得到图像的分类预测向量
28、将原始标签数据进行归一化操作,将原始标签转换为概率分布p(li);利用k-l散度量化图像分类预测向量和原始标签向量的概率分布p(li)之间差异,损失函数如下公式所示:
29、
30、同理,将文本模态网络的第二层输出的文本特征向量映射到与原始标签维度c相同的空间中,经过softmax函数计算得到文本的多分类预测向量利用k-l散度量化文本的多分类预测向量和原始标签向量的概率分布p(li)之间差异,损失函数如下公式所示:
31、
32、其中,是文本的分类预测向量;
33、在浮点型相似性监督矩阵s和标签哈希码hl的监督下,采用成对相关性损失函数l′cor来约束成对相似实例的多模态哈希码hi,ht与对应语义的标签哈希码hl之间的相似性学习;采用浮点型相似性监督矩阵s对标签哈希码自身的语义相似性进行监督学习,提升哈希码的语义重心表达能力;
34、所述成对相关性损失函数l′cor,如下公式所示:
35、
36、采用上述技术方案所产生的有益效果在于:本发明提供的基于深度学习技术的跨模态哈希检索方法,针对数据集中文本单词是根据从网站上收集的同时出现的数据对搜集得到的,存在不匹配的问题,使用蕴含丰富多模态知识的视觉语言预训练模型vlp,对文本进行去噪。
37、为了更好的表示数据之间的语义相关性,根据数据间的关系可以分为三类相似性:不相似、完全相似和部分相似,基于此构建多重语义相似性矩阵,可以从整体上刻画数据之间的关系数据。
38、利用标签哈希码作为代理哈希码,在代理哈希码的学习过程中,考虑了图片和文本数据的分布。根据相似性矩阵,模态数据可以和多种代理哈希码相似。检索集中多标签相同的数据都以相同的方式存储。
- 还没有人留言评论。精彩留言会获得点赞!