一种大坝裂缝检测模型
本发明属于混凝土裂缝检测,具体涉及一种基于像素级深度学习的混凝土坝表面裂缝检测技术,本发明是发明名称为一种基于像素级深度学习的混凝土坝表面裂缝检测方法(申请号为2023102234065)的发明专利的分案申请。
背景技术:
1、混凝土坝长期暴露于大气与水环境中,承受水流冲刷、温度变化以及干湿、冻融等外界作用,其表面不可避免会出现缺陷,其中裂缝是威胁坝体安全稳定的最主要因素。裂缝不仅存在于大坝表面,若不及时处理还将延伸至坝体内部,影响大坝的强度和使用寿命,甚至引发渗漏、坍塌等安全事故。因此,及时识别和检测混凝土坝表面裂缝对预示工程险情和保障大坝安全具有重要意义。
2、在现有技术中,基于计算机视觉的裂缝图像检测方法已经得到了相关研究,且可分为传统图像分割方法和深度学习语义分割方法。传统图像分割方法主要是利用图像中裂缝自身像素的灰度值比背景低、图像二值化、图像滤波器和数值图像等低阶视觉信息实现对裂缝的识别分割。与人工直接检测相比,传统图像分割方法具备一定安全性和可行性,但当背景存在大量噪声时精度低,易受外界因素干扰,分割结果不准确。而且该类方法对裂缝进行检测时步骤较多,需要人为不断进行调整参数以适应分割场景,检测效率低,在精度和效率上满足不了实际工程场景应用需要,需要进一步建立精确、高效的裂缝智能分割方法。
3、相较基于低阶视觉信息的传统图像分割方法,深度学习语义分割方法采用的高阶视觉信息具有更高的精度和鲁棒性。经过对现有研究分析,深度学习语义分割算法对裂缝检测具备了可行性,但大部分研究主要是基于公开数据集下的房屋建筑物、路面、桥梁裂缝实验研究,而对混凝土坝裂缝安全检测的研究较少。公开号为cn115731172a的专利公开了一种基于图像增强和纹理提取的裂缝检测方法,通过添加注意力的方式改进unet网络检测裂缝,但没有建立残差网络,不能通过增加网络深度来强化模型的特征提取能,导致特征信息提取有限,检测能力弱。公开号为cn115131664a的专利公开了一种混凝土细小裂缝识别方法,提高混凝土细小裂缝的检测精度,但该方法数据集需要采集大量数据集,且人工标注费时费力。
4、因此,若直接将上述现有技术应用于混凝土坝表面裂缝检测还存在以下问题:
5、1)坝面裂缝图像的采集和数据标注人工成本高,导致坝面裂缝数据集稀缺,数据集不足会严重影响裂缝特征提取和图像分割。由于公开数据集中的裂缝与坝面裂缝特征和分别差异较大,不能直接将公开裂缝数据集扩充到坝面裂缝图像中,混凝土坝裂缝数据集样本量少会导致模型训练不充分,易出现漏检;
6、2)混凝土坝图像中裂缝所占的像素点少,而背景却占了图像绝大部分,导致模型对坝面裂缝特征信息提取不充分,细小裂缝分割能力弱;
7、3)实际工程中的裂缝更具复杂性,现有算法对光照不均、裂缝与周边环境对比度低等情况下的混凝土坝裂缝检测鲁棒性低、像素准确率低,使边缘分割平滑。
技术实现思路
1、本发明的目的是为了解决现有技术存在的坝面数据图像采集困难、数据标注人工成本高,使大坝裂缝数据集缺乏导致模型训练欠拟合、不充分、检测精度低以及现有方法对微小裂缝所占的像素点少、裂缝与周边环境对比度低,导致模型对坝面裂缝特征信息提取能力弱、细小裂缝分割能力弱、像素准确率低的技术问题,而提供的一种基于像素级深度学习的混凝土坝表面裂缝检测方法及大坝裂缝检测模型。
2、为解决上述技术问题,本发明采用的技术方案为:
3、一种基于像素级深度学习的混凝土坝表面裂缝检测方法,包括以下步骤:
4、步骤1:获取混凝土坝表面裂缝图像和两阶段迁移学习训练方式;
5、步骤2:构建大坝裂缝检测模型;
6、步骤3:采用大坝裂缝检测模型对混凝土坝表面裂缝图像中的每个像素点进行识别,并获取混凝土坝的裂缝形状检测结果。
7、在步骤1中,具体包括以下子步骤:
8、步骤1-1:进行训练模型数据集的采集:
9、(1)本发明用来训练模型的数据集有3部分,分别为pascal voc 2012数据集、第一阶段跨域训练裂缝数据集dataseta和第二阶段目标域混凝土坝表面裂缝图像数据集datasetb;
10、(2)pascal voc 2012为计算机视觉挑战赛数据集,由1464张训练集图像、1449张验证集图像组成,包含20类别和1个背景。
11、(3)第一阶段跨域训练裂缝数据集dataseta通过收集网上公开裂缝数据集crackforest,sdnet2018,aft original crack dataset second组成。
12、(4)第二阶段目标域混凝土坝表面裂缝图像数据集datasetb通过无人机对混凝土坝表面进行采集,无人机依次经过大坝裂缝易形成的关键点位拍摄图像,最后将采集的巡检数据的图片或视频储存在机身内置的ssd卡中并返回到起航点。
13、步骤1-2:进行训练模型数据集的制作:
14、(1)人工采用labelme标注工具手动对第二阶段目标域datasetb进行像素级标注。
15、(2)为保障该数据集能适应不同复杂环境,使得模型具备更强的泛化能力和鲁棒性,对第二阶段目标域datasetb进行了扩充。
16、(3)图像标注后经过图像增强算法retinex、调整图像光度、对比度和空间变化(随机旋转、翻转)对图像进行了扩充。
17、(4)第二阶段目标域datasetb按比例8:2随机划分为训练集和验证集。
18、步骤1-3:进行两阶段迁移学习训练:
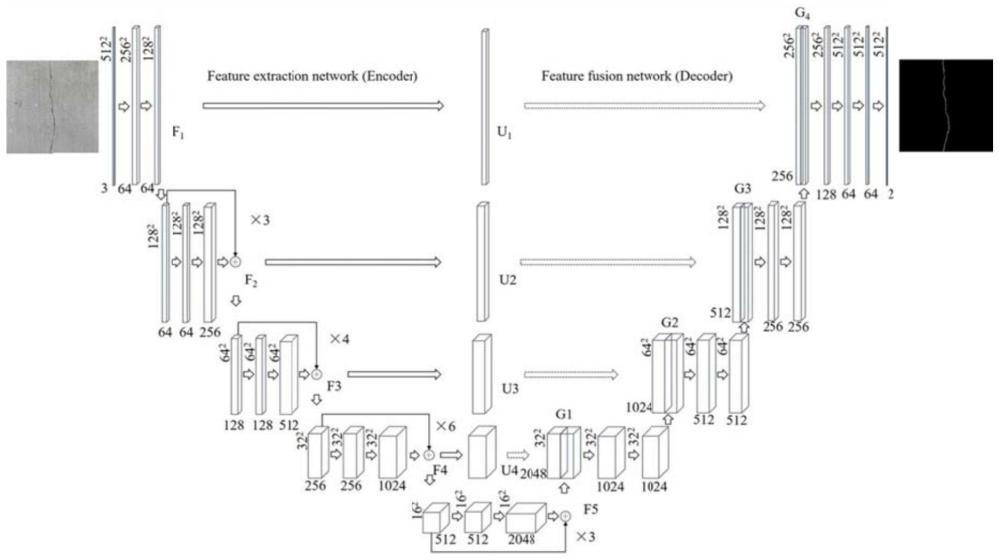
19、(1)训练初始,在输入端设置将所有数据集图像重塑其尺寸为512×512像素大小;
20、(2)模型训练batch_size为8、epoch为300、优化器为adam、momentum为0.9、初始学习率为0.0001、学习率下降方式为cosineannealinglr、损失函数为cross entropy loss;
21、
22、y为真实值分布;为网络输出分布;n为总类别数;
23、(3)第一阶段是基于跨域的模型知识迁移,即利用源域对目标域共享模型参数。利用源域pascal voc 2012数据集模型得到的训练结果作为第一阶段目标域dataseta的预训练模型,在源域和目标域中找到两者之间共享的参数信息,使第一阶段目标域dataseta在训练过程中从算法和模型的角度进行参数更新,避免网络从零学习,使第二阶段能获得一个更好的导师模型;
24、(4)第二阶段是基于域内的特征知识迁移,即将源域和目标域的特征从原始特征空间映射到新特征空间中。将第一阶段迁移学习后的dataseta预训练模型作为第二阶段的源域,从相关领域中学习相同信息和知识结构,通过迁移学习方法将源域中存在与目标域相同的特征表示迁移到第二阶段目标域datasetb中,从而在新空间中更好地利用源域中已有的标记数据样本进行分类训练,解决坝面裂缝标注图像稀缺导致精度差的问题;
25、(5)由于第一阶段和第二阶段在图像特征上是相同领域,为加快训练效率和防止权值被破坏,在第二阶段迁移训练中加入了冻结训练步骤。即在训练的前150代冻结了主干网络,仅对解码分类器进行训练,后150代解冻对整个网络进行训练学习。
26、在步骤2中,具体包括以下子步骤:
27、步骤2-1:搭建resnet50网络作为unet模型编码器的特征提取网络,通过residual模块加深网络层数和提取能力充分获取裂缝特征信息,使模型可以有效地学习坝面裂缝的深层特征,提高模型对裂缝分割精度;
28、步骤2-2:将多层并行残差注意力添加到跳跃连接层中,通过获取更多语义信息以增强模型的特征表达能力,以抑制无关区域中的特征响应,提高有效特征信息通道的重要性,使网络专注于裂缝特征信息,补充细节损失,使模型更精确对坝面裂缝图像进行分割。
29、在步骤2中,所建立的大坝裂缝检测模型的结构为:
30、检测图像视频通过一次7×7卷积,bn,rulu→maxpool→1282×64大小的第一编码特征图f1;
31、第一编码特征图f1→残差模块×3,得到1282×256大小的第二编码特征图f2;第一编码特征图f1→mprattention,得到第一增强特征图u1;
32、第二编码特征图f2→残差模块×4,得到642×512大小的第三编码特征图f3;第二编码特征图f2→mprattention,得到第二增强特征图u2;
33、第三编码特征图f3→残差模块×6,得到322×1024大小的第四编码特征图f4;第三编码特征图f3→mprattention,得到第三增强特征图u3;
34、第四编码特征图f4→残差模块×3,得到162×2048大小的第五编码特征图f5;第四编码特征图f4→mprattention,得到第四增强特征图u4;
35、第五编码特征图f5→up-conv层上采样→与第四增强特征图u4融合补充细节损失,得到322×2048大小的第一解码特征图g1。
36、第一解码特征图g1→conv 3×3层卷积,rulu→conv 3×3层卷积,rulu→up-conv层上采样→与第三增强特征图u3融合补充细节损失,得到642×1024大小的第二解码特征图g2。
37、第二解码特征图g2→conv 3×3层卷积,rulu→conv 3×3层卷积,rulu→up-conv层上采样→与第二增强特征图u2融合补充细节损失,得到1282×512大小的第三解码特征图g3。
38、第三解码特征图g3→conv 3×3层卷积,rulu→conv 3×3层卷积,rulu→up-conv层上采样→与第一增强特征图u1融合补充细节损失,得到2562×256大小的第四解码特征图g4。
39、第四解码特征图g4→conv 3×3层卷积,rulu→up-conv层上采样→conv 3×3层卷积,rulu→conv 1×1,sigmoid→裂缝图像。
40、残差模块的结构根据输入的特征图通道数与输出通道数是否一致而变化;
41、情况一:
42、若输入的特征图通道数与输出通道数一致时,大坝裂缝检测模型中残差模块的结构为:
43、输入的特征图为x→conv 1×1层卷积,bn,rulu→conv 3×3层卷积,bn,rulu→conv 1×1层卷积,bn→得到f(x);
44、f(x)→与x残差结构融合防止梯度爆炸→深层次的特征图h(x)。
45、情况二:
46、若输入特征图通道数与输出通道数不一致,大坝裂缝检测模型中残差模块的结构为:
47、输入的特征图为x→conv 1×1层卷积,bn,rulu→conv 3×3层卷积,bn,rulu→conv 1×1层卷积,bn→得到f(x);
48、输入的特征图为x→conv 1×1层卷积,bn→得到k(x);
49、f(x)→与k(x)残差结构融合防止梯度爆炸→深层次的特征图h(x)。
50、大坝裂缝检测模型中多层并行残差注意力模块的结构为:
51、输入特征图x→残差结构融合防止梯度爆炸→skip层特征图;
52、输入特征图x→conv 1×1层卷积增加模型的非线性能力→f1(x)特征图;
53、输入特征图x→conv 3×3层卷积,bn,rulu多尺度卷积下进行特征学习→f2(x)特征图;
54、输入特征图x→atrous conv3×3层卷积,dilation rate 3增加模型感受野→f3(x)特征图;
55、多层并行残差注意力模块输出y=skip+f1(x)+f2(x)+f3(x),通过add的方式进行融合。
56、与现有技术相比,本发明具有如下技术效果:
57、本发明采用无人机和rm-unet对混凝土坝表面裂缝进行检测。首先,通过对unet进行了改进增强对细微裂缝的提取效果,从而提升了模型对裂缝边缘形状的分割精度和准确度。其次两阶段迁移学习通过跨域学习和域内学习的方式,将相关领域知识转移到目标领域,使模型在小规模数据集下得到充分训练,使得rm-unet的检测能力和优于目前先进语义分割模型;最后使用无人机对大坝进行巡检,将航拍结果使用rm-unet模型进行处理,可以及时、高效对大坝健康进行诊断,解决人工判别和目前图像识别效率低、识别能力差的情况。综上,本发明方法在混凝土坝面裂缝检测具有更高的效率和精度,具备更强的鲁棒性,可以为大坝安全检测提供更好的替代或补充办法。
- 还没有人留言评论。精彩留言会获得点赞!