大语言模型内部知识定位探测方法、系统、设备及介质
本发明涉及知识定位,特别是涉及一种大语言模型内部知识定位探测方法、系统、设备及介质。
背景技术:
1、大语言模型以神经网络参数的形式学习存储知识,这种隐式知识表示方式可解释性差,难以被人类理解。同时,随着知识的过时或错误,想修正大语言模型内部的知识是很困难的。所以对大语言模型内部知识进行知识定位探测,了解内部知识存储的位置与方式,对于大语言模型的可解释性和修正错误知识具有重要的作用。
2、目前针对大语言模型内部的知识定位检测方法主要有知识归因(knowledgeattribution)和因果中介分析(causal mediation analysis)两种,但上述两种知识定位方法对于每条知识的定位均需要多次的前向计算或多次的反向梯度计算,由于大语言模型参数规模巨大,前向计算与反向梯度计算均需要耗费大量的时间与计算资源,造成知识定位的时间成本和计算成本太高。
3、基于此,本发明提出一种大语言模型内部探测知识定位探测方法以解决上述问题。
技术实现思路
1、本发明提供一种大语言模型内部知识定位探测方法、系统、设备及介质,以解决现有对大语言模型内部知识定位方法探测成本和计算成本太高的问题。
2、在本发明实施例第一方面提出一种大语言模型内部知识定位探测方法,所述方法包括:
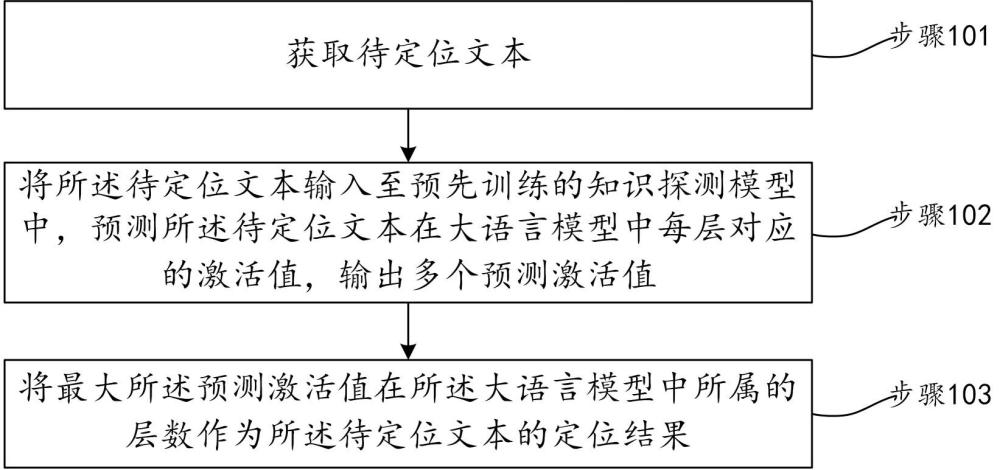
3、获取待定位文本;
4、将所述待定位文本输入至预先训练的知识探测模型中,预测所述待定位文本在大语言模型中每层对应的激活值,输出多个预测激活值,其中,所述知识探测模型通过训练文本和所述训练文本对应的训练标签训练得到,所述训练标签是所述大语言模型针对所述训练文本经过一轮前向过程计算生成的,所述训练标签用于表征所述大语言模型对所述训练文本的响应程度,所述训练标签对应的值越高表明所述训练文本存储在大语言模型中对应层的概率越高;
5、将最大所述预测激活值在所述大语言模型中所属的层数作为所述待定位文本的定位结果。
6、在本发明可选地一实施例中,所述知识探测模型的训练样本是由大语言模型生成的,所述大语言模型包括嵌入层和多层堆叠的transformer块,所述多层堆叠的transformer块中每个块的结构相同,每个所述transformer块包含多头自注意力层和全连接映射层两个子层,对每个所述子层进行层归一化操作,并对两个所述子层中间进行残差连接,对每个所述transformer块之间进行残差连接;
7、所述知识探测模型的训练样本通过以下步骤获取:
8、所述训练文本经过所述嵌入层得到文本词嵌入向量表示序列,并在所述文本词嵌入向量表示序列中增加位置编码信息,建模所述文本词嵌入向量表示序列的时间先后顺序,记录第一激活向量;
9、记录所述训练文本经过每个所述transformer块的所述多头自注意力层与所述全连接映射层的第二激活向量;
10、对记录的所有所述第一激活向量和所述第二激活向量求均值,得到每一层激活向量均值,每个所述激活向量均值表示所述大语言模型对所述训练文本的响应程度,所述激活向量均值越高表明所述训练文本存储在大语言模型中对应层的概率越高;
11、将所有所述激活向量均值按照在所述大语言模型所属的层数从前往后组成一个向量,将所述向量作为训练所述知识探测模型的训练标签;
12、将所述训练文本和所述训练标签组合作为一条所述训练样本。
13、在本发明可选地一实施例中,所述知识探测模型的训练样本的获取步骤具体包括:
14、采用词嵌入矩阵将所述训练文本转化为连续特征向量;
15、对所述连续特征向量增加位置编码信息,并建模所述连续特征向量的时间先后顺序信息,记录所述第一激活向量;
16、记录每个所述transformer块的所述多头自注意力层与所述全连接映射层的所述第二激活向量,对每一层的所述第一激活向量和所述第二激活向量求均值,得到n个所述激活向量均值,其中,所述嵌入层产生一个所述第一激活向量,每个所述transformer块产生两个所述第二激活向量,其中,n为大于3的整数;
17、将n个所述激活向量均值按照在所述大语言模型所属的层数依次组合形成n维的向量,将所述向量作为训练所述知识探测模型的训练标签;
18、将所述训练文本和所述训练标签组合作为一条所述训练样本。
19、在本发明可选地一实施例中,所述知识探测模型为对任意神经网络模型进行训练得到的,所述知识探测模型的训练步骤包括:
20、将所述训练文本输入至待训练神经网络模型,并对所述训练文本进行编码,得到编码文本;
21、采用softmax函数将所述编码文本转换为概率值;
22、采用交叉熵损失函数计算所述概率值和所述训练标签之间的损失;
23、对所述损失进行反向传播计算梯度,以及对所述待训练神经网络模型的参数进行更新,完成所述知识探测模型的训练。
24、在本发明可选地一实施例中,所述神经网络模型的网络结构为基于transformer的网络结构,所述网络结构包含一个嵌入层、m层自注意力模块和一个线性层,所述知识探测模型的训练步骤具体包括:
25、采用所述嵌入层将所述训练文本转化为多维的向量序列;
26、将多维的所述向量序列输入至所述m层自注意力模块中,输出所述编码文本,其中,m为大于2的整数;
27、采用所述线性层将所述编码文本的维度转换为与所述训练标签的维度相同;
28、采用所述softmax函数对所述编码文本进行归一化处理,得到所述概率值;
29、对所述概率值采用交叉熵损失函数进行梯度下降训练,直至完成所述知识探测模型的训练。
30、在本发明可选地一实施例中,所述方法还包括:
31、在获取所述待定位文本的定位结果后,对所述大语言模型所在层数的存储文本和待定位文本进行对比,得到对比结果;
32、当所述对比结果为所述存储文本和所述待定位文本不相同的情况下,将所述存储文本更改为所述待定位文本,以修正所述大语言模型中的存储文本为正确的文本。
33、在本发明实施例第二方面提出一种大语言模型内部知识定位探测系统,所述系统包括:
34、获取模块,用于获取待定位文本;
35、预测模块,用于将所述待定位文本输入至预先训练的知识探测模型中,预测所述待定位文本在大语言模型中每层对应的激活值,输出多个预测激活值,其中,所述知识探测模型通过训练文本和所述训练文本对应的训练标签训练得到,所述训练标签是所述大语言模型针对所述训练文本经过一轮前向过程计算生成的,所述训练标签用于表征所述大语言模型对所述训练文本的响应程度,所述训练标签对应的值越高表明所述训练文本存储在大语言模型中对应层的概率越高;
36、定位结果获取模块,用于将最大所述预测激活值在所述大语言模型中所属的层数作为所述待定位文本的定位结果。
37、可选地,所述知识探测模型的训练样本是由大语言模型生成的,所述大语言模型包括嵌入层和多层堆叠的transformer块,所述多层堆叠的transformer块中每个块的结构相同,每个所述transformer块包含多头自注意力层和全连接映射层两个子层,对每个所述子层进行层归一化操作,并对两个所述子层中间进行残差连接,对每个所述transformer块之间进行残差连接;所述系统还包括样本生成模块,所述样本生成模块包括:
38、第一记录子模块,用于所述训练文本经过所述嵌入层得到文本词嵌入向量表示序列,并在所述文本词嵌入向量表示序列中增加位置编码信息,建模所述文本词嵌入向量表示序列的时间先后顺序,记录第一激活向量;
39、第二记录子模块,用于记录所述训练文本经过每个所述transformer块的所述多头自注意力层与所述全连接映射层的第二激活向量;
40、激活向量均值生成子模块,用于对记录的所有所述第一激活向量和所述第二激活向量求均值,得到每一层激活向量均值,每个所述激活向量均值表示所述大语言模型对所述训练文本的响应程度,所述激活向量均值越高表明所述训练文本存储在大语言模型中对应层的概率越高;
41、第一训练标签生成子模块,用于将所有所述激活向量均值按照在所述大语言模型所属的层数从前往后组成一个向量,将所述向量作为训练所述知识探测模型的训练标签;
42、第一训练样本生成子模块,用于将所述训练文本和所述训练标签组合作为一条所述训练样本。
43、可选地,所述样本生成模块还包括:
44、训练样本转化子模块,用于采用词嵌入矩阵将所述训练文本转化为连续特征向量;
45、记录子模块,用于对所述连续特征向量增加位置编码信息,并建模所述连续特征向量的时间先后顺序信息,记录所述第一激活向量;
46、向量均值生成子模块,用于记录每个所述transformer块的所述多头自注意力层与所述全连接映射层的所述第二激活向量,对每一层的所述第一激活向量和所述第二激活向量求均值,得到n个所述激活向量均值,其中,所述嵌入层产生一个所述第一激活向量,每个所述transformer块产生两个所述第二激活向量,其中,n为大于3的整数;
47、第二训练标签生成子模块,用于将n个所述激活向量均值按照在所述大语言模型所属的层数依次组合形成n维的向量,将所述向量作为训练所述知识探测模型的训练标签;
48、第二训练样本生成子模块,用于将所述训练文本和所述训练标签组合作为一条所述训练样本。
49、可选地,所述知识探测模型为对任意神经网络模型进行训练得到的,所述系统还包括训练模块,所述训练模块包括:
50、第一编码子模块,用于将所述训练文本输入至待训练神经网络模型,并对所述训练文本进行编码,得到编码文本;
51、转换子模块,用于采用softmax函数将所述编码文本转换为概率值;
52、损失计算子模块,用于采用交叉熵损失函数计算所述概率值和所述训练标签之间的损失;
53、参数更新子模块,用于对所述损失进行反向传播计算梯度,以及对所述待训练神经网络模型的参数进行更新,完成所述知识探测模型的训练。
54、其中,所述神经网络模型的网络结构为基于transformer的网络结构,所述网络结构包含一个嵌入层、m层自注意力模块和一个线性层,所述训练模块还包括:
55、转化子模块,用于采用所述嵌入层将所述训练文本转化为多维的向量序列;
56、第二编码子模块,用于将多维的所述向量序列输入至所述m层自注意力模块中,输出所述编码文本,其中,m为大于2的整数;
57、维度转换子模块,用于采用所述线性层将所述编码文本的维度转换为与所述训练标签的维度相同;
58、归一化子模块,用于采用所述softmax函数对所述编码文本进行归一化处理,得到所述概率值;
59、梯度下降训练子模块,用于对所述概率值采用交叉熵损失函数进行梯度下降训练,直至完成所述知识探测模型的训练。
60、可选地,所述系统还包括:
61、对比模块,用于在获取所述待定位文本的定位结果后,对所述大语言模型所在层数的存储文本和待定位文本进行对比,得到对比结果;
62、修正模块,用于当所述对比结果为所述存储文本和所述待定位文本不相同的情况下,将所述存储文本更改为所述待定位文本,以修正所述大语言模型中的存储文本为正确的文本。
63、在本发明实施例第三方面提出一种电子设备,包括:存储器,用于存储一个或多个程序;处理器;当所述一个或多个程序被所述处理器执行时,实现如上述第一方面中任一项所述的大语言模型内部知识定位探测方法。
64、在本发明实施例第四方面提出一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述第一方面中任一项所述的大语言模型内部知识定位探测方法。
65、本发明包括以下优点:本发明提出一种大语言模型内部知识定位探测方法、系统、设备及介质,通过获取待定位文本;将所述待定位文本输入至预先训练的知识探测模型中,预测所述待定位文本在大语言模型中每层对应的激活值,输出多个预测激活值,其中,所述知识探测模型通过训练文本和所述训练文本对应的训练标签训练得到,所述训练标签是所述大语言模型针对所述训练文本经过一轮前向过程计算生成的,所述训练标签用于表征所述大语言模型对所述训练文本的响应程度,所述训练标签对应的值越高表明所述训练文本存储在大语言模型中对应层的概率越高;将最大所述预测激活值在所述大语言模型中所属的层数作为所述待定位文本的定位结果。上述大语言模型内部知识定位探测方法在进行知识定位探测时无需对原始大语言模型进行多次的前向计算或反向梯度计算,仅需通过预先训练好的知识探测模型生成待定位文本的预测激活值,根据该预测激活值可直接获取待定位文本在大语言模型中的层数,以低成本计算的方式快速实现大语言模型内部知识的定位探测。
- 还没有人留言评论。精彩留言会获得点赞!