一种体育赛事数据统计方法及系统
本发明涉及数据统计,具体涉及一种体育赛事数据统计方法及系统。
背景技术:
1、体育(physical education,缩写pe或p.e.),是一种复杂的社会文化现象,它是一种以身体与智力活动为基本手段,根据人体生长发育、技能形成和机能提高等规律,达到促进全面发育、提高身体素质与全面教育水平、增强体质与提高运动能力、改善生活方式与提高生活质量的一种有意识、有目的、有组织的社会活动。
2、体育赛事是指比较有规模有级别的正规比赛。以篮球比赛为例,需要统计的数据种类较多,比如得分、助攻和篮板球等,而赛场上的形势是不可预测的,可能会导致需要统计的数据量较大,但是现有的体育赛事数据统计通常采用人工记录方式,人力资源成本大,且数据统计的方式较为单一。
3、在专利公告号为cn109360589a的一篇中国专利中,公开了一种体育赛事数据统计方法及系统,在其方案中主要包括有数据的输入、数据的分类和存储,以及数据的调取和输出。在数据的输入过程中,包含音频输入模块。在实际情况中,体育赛事场地往往人员密集,因此会产生大量的噪音,而音频输入模块并不能区分这些噪音,可能会在使用音频输入模块进行体育赛事数据统计时,受到外界的干扰,导致数据输入错误。而且在音频输入模块中包含错音识别单元和错音提示单元,可能会导致错音提示单元一直提示输入错误的情况,影响数据统计的效率。
技术实现思路
1、本发明的目的在于提供一种体育赛事数据统计方法及系统,解决上述技术问题。
2、本发明的目的可以通过以下技术方案实现:
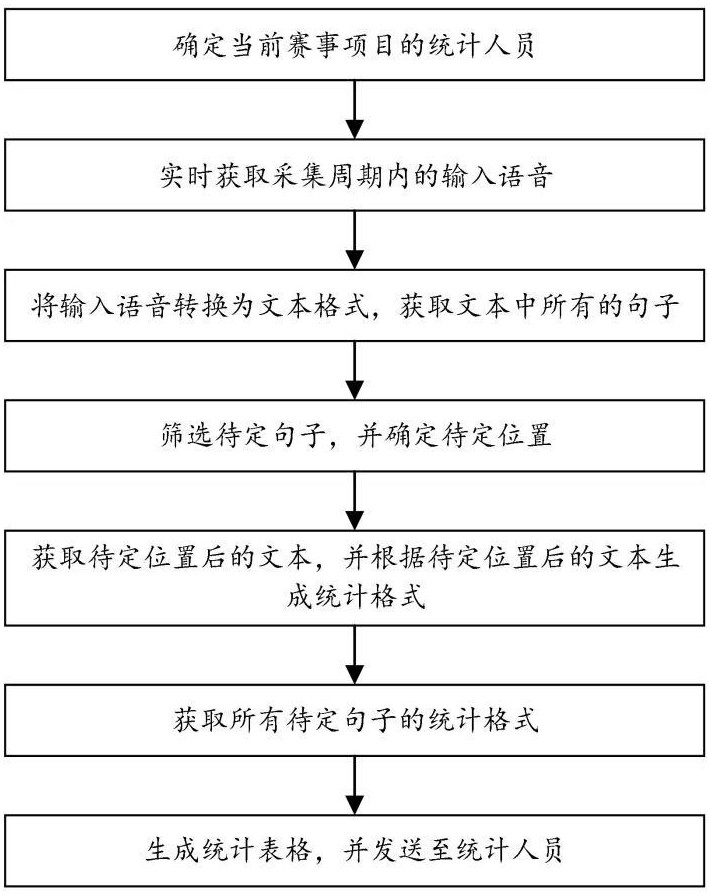
3、一种体育赛事数据统计方法,包括以下步骤:
4、s1:确定当前赛事项目的统计人员,所述的统计人员为负责统计体育赛事数据的工作人员,所述的体育赛事数据包括运动员姓名、得分、助攻次数、犯规次数和失误次数;
5、s2:设定采集周期,在所述的采集周期内,实时获取输入语音,所述的输入语音为该统计人员发出的语音信号,获取所述的输入语音的过程具体包括:
6、建立数据库,所述的数据库中存储有统计人员的声纹,通过深度学习模型建立声纹识别模型,并使用所述的数据库对其进行训练和验证;
7、实时获取所述的采集周期内的语音信号,并将其输入至声纹识别模型,获取输入语音;
8、s3:将所述的输入语音转换为文本格式,获取文本中所有的句子,并执行得分步骤:
9、s31:通过正则表达式筛选出包含有运动员姓名的句子,定义为待定句子,并在所述的待定句子中标记出运动员姓名中最后一个字符的位置,定义为待定位置;
10、s32:在所述的待定句子中,获取待定位置后的文本,并通过正则表达式查找其中是否包括体育赛事数据,并生成当前待定句子的统计格式,所述的统计格式为当前待定句子对应的运动员姓名-体育赛事数据;
11、s33:重复步骤s31~s32,获取所有待定句子的统计格式;
12、s4:生成统计表格,所述的统计表格中包括每个运动员的得分总和、助攻总次数、犯规总次数和失误总次数,并在所述的采集周期结束后,将所述的统计表格发送至统计人员。
13、作为本发明进一步的方案:所述的步骤s31中,执行以下步骤:
14、步骤一:获取当前赛事项目运动员的姓名,并获取姓名中每个汉字的声调赋分m;
15、步骤二:计算运动员的赋分总和,其中mi表示运动员姓名中第i个汉字的声调赋分;
16、步骤三:将运动员按照赋分总和进行排序,赋分总和越大,排名越靠后;
17、步骤四:从排序中的首位开始,通过正则表达式筛选出包含有对应运动员姓名的待定句子;
18、步骤五:重复步骤一~步骤四,筛选出所有的待定句子。
19、作为本发明进一步的方案:所述的步骤一中,具体的赋分过程包括:阴平、阳平、上声和去声分别赋分为1、2、3、4。
20、作为本发明进一步的方案:所述的步骤三中,当存在两个及两个以上的赋分总和相同时,将其按照运动员姓名的首拼音进行排序。
21、作为本发明进一步的方案:所述的步骤s31中,当存在某一句子中存在两个及两个以上运动员的姓名时,执行以下步骤:
22、通过正则表达式查找该句子中是否包括体赛事数据;
23、当该句子中不包括体赛事数据时,不进行后续处理;
24、当该句子中包括体赛事数据时,在未识别出输入语音时,提醒统计人员,重新输入该句子,并提醒统计人员调整语音输入的格式为统计格式。
25、作为本发明进一步的方案:所述的步骤s32中,当某一待定句子中不包括体育赛事数据时,该待定句子不执行后续步骤。
26、作为本发明进一步的方案:所述的步骤s32中,当某一待定句子中包括两个及两个以上的体育赛事数据时,执行以下步骤:
27、获取该句子中体育赛事数据的数量a,并根据该句子中的体育赛事数据生成a个该句子的统计格式。
28、一种体育赛事数据统计系统,包括:
29、初始模块:确定当前赛事项目的统计人员,所述的统计人员为负责统计体育赛事数据的工作人员,所述的体育赛事数据包括运动员姓名、得分、助攻次数、犯规次数和失误次数;
30、输入确定模块:设定采集周期,在所述的采集周期内,实时获取输入语音,所述的输入语音为该统计人员发出的语音信号,获取所述的输入语音的过程具体包括:
31、建立数据库,所述的数据库中存储有统计人员的声纹,通过深度学习模型建立声纹识别模型,并使用所述的数据库对其进行训练和验证;
32、实时获取所述的采集周期内的语音信号,并将其输入至声纹识别模型,获取输入语音;
33、记录模块:将所述的输入语音转换为文本格式,获取文本中所有的句子,并执行得分步骤:
34、s31:通过正则表达式筛选出包含有运动员姓名的句子,定义为待定句子,并在所述的待定句子中标记出运动员姓名中最后一个字符的位置,定义为待定位置;
35、s32:在所述的待定句子中,获取待定位置后的文本,并通过正则表达式查找其中是否包括体育赛事数据,并生成当前待定句子的统计格式,所述的统计格式为当前待定句子对应的运动员姓名-体育赛事数据;
36、s33:重复步骤s31~s32,获取所有待定句子的统计格式;
37、发送模块:生成统计表格,所述的统计表格中包括每个运动员的得分总和、助攻总次数、犯规总次数和失误总次数,并在所述的采集周期结束后,将所述的统计表格发送至统计人员。
38、本发明的有益效果:本发明适用于篮球比赛,在本发明中,首先确定需要统计的体育赛事数据种类,这是后续处理的基础;之后,获取采集周期内获取的语音信号,并从中识别出输入语音,采集周期为篮球比赛开始的时间到结束的时间,识别输入语音是通过声纹进行的,声纹不仅具有特定性,而且有相对稳定性的特点。实验证明,无论讲话者是故意模仿他人声音和语气,还是耳语轻声讲话,即使模仿得惟妙惟肖,其声纹却始终不变;其次,通过正则表达式筛选待定句子,这是为了减少后续的处理量;因为可以理解的是,统计人员在工作过程中,也可能进行统计体育赛事数据不相关的交流,如日常交流等;所以基于此,在本发明中通过正则表达式进行初步的筛选,减少后续的数据处理量,节约计算资源;之后通过正则表达式查找句子中是否包括体育赛事数据,进而生成统计格式;因为可以理解的是,在实际情况中,统计人员可能因为球员的精彩表现而喝彩,或如“a的传球好帅”,此时虽然提到了球员的名字,但是可能并不是统计体育赛事数据;最终,生成统计表格并发送至统计人员,对收集的数据进行可视化展示。本发明可以在通过语音统计体育赛事数据的过程中,降低由于周围噪音过多导致的语音输入错误的情况,提高统计体育赛事数据的效率。
- 还没有人留言评论。精彩留言会获得点赞!