一种数据聚类集成融合方法及装置
本发明属于数据处理,具体涉及一种数据聚类集成融合方法及装置。
背景技术:
1、随着城市的不断发展和扩张,工业化、城市化进程加快,人们对环境质量的要求也日益提高。为了全面、准确地评估环境质量,通常会对环境进行多维度的检测,如空气质量监测、水质检测、噪声污染测量等。
2、这些检测方法会生成大量的数据,每组数据都反映了环境在特定方面的状态。为了更好地理解和分析这些数据,挖掘它们背后的环境模式和趋势,就需要对这些数据进行聚类集成融合处理。
3、聚类集成融合处理是一种高级的数据分析技术,它能够将来自不同检测方法、不同时间段的数据进行整合,通过聚类算法识别出数据中的相似性和差异性,进而形成有意义的数据群组。这些群组可以帮助我们更加清晰地认识环境的整体状况,发现潜在的环境问题,为环境管理和政策制定提供科学依据。
4、然而,现有的数据聚类集成融合处理方法通常是平等地对待所有聚类和基本聚类算法,因此存在低质量的基本聚类成员,这些低质量的基本聚类成员可能会对最终的集成融合结果产生负面影响,降低整体的分析准确性和可靠性。
技术实现思路
1、本发明的目的就在于解决低质量的基本聚类成员可能会对最终的集成融合结果产生负面影响,降低整体的分析准确性和可靠性的问题,而提出一种数据聚类集成融合方法及装置。
2、在本发明实施的第一方面,首先提出一种数据聚类集成融合方法,所述方法包括:
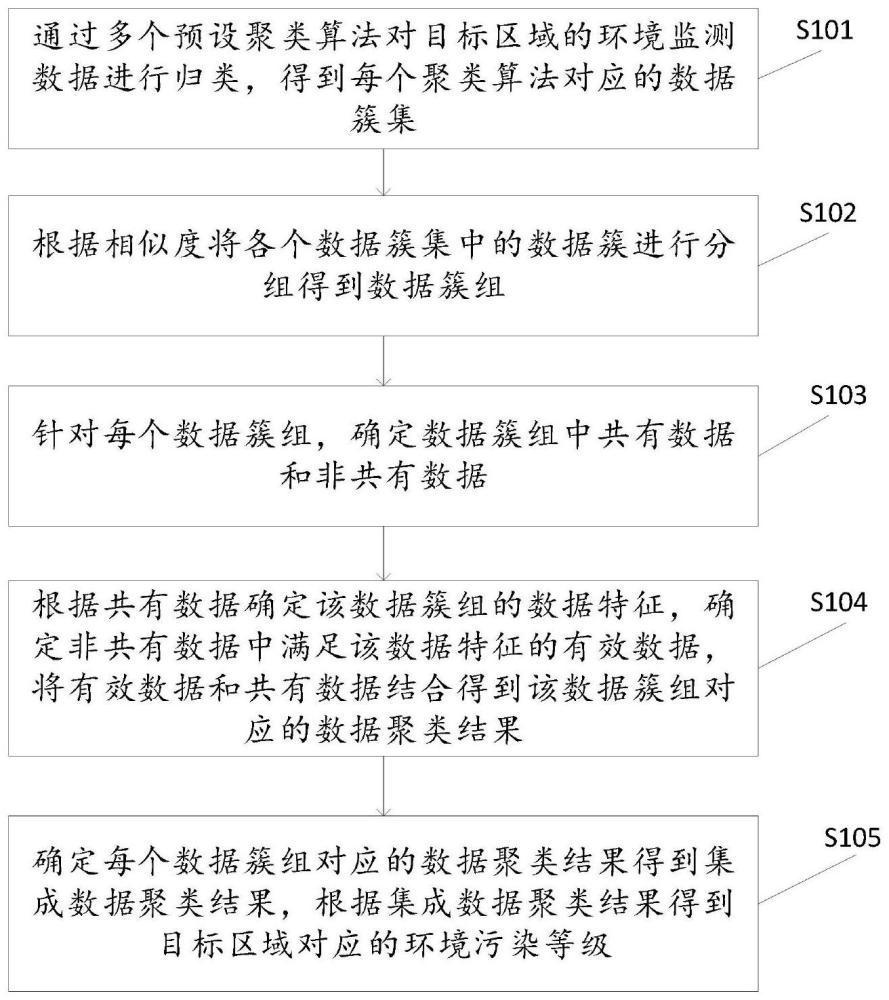
3、通过多个预设聚类算法对目标区域的环境监测数据进行归类得到每个聚类算法对应的数据簇集;每个聚类算法设置的数据簇个数相同;
4、根据相似度将各个数据簇集中的数据簇进行分组得到数据簇组;数据簇组的个数与数据簇个数相同;每一数据簇组包含各个数据簇集中的一个数据簇;
5、针对每个数据簇组,确定数据簇组中共有数据和非共有数据;共有数据为数据簇组中各个数据簇均包含的数据;非共有数据为数据簇组中除共有数据以外的数据;
6、根据共有数据确定该数据簇组的数据特征,确定非共有数据中满足该数据特征的有效数据,将有效数据和共有数据结合得到该数据簇组对应的数据聚类结果;
7、确定每个数据簇组对应的数据聚类结果得到集成数据聚类结果,根据集成数据聚类结果得到所述目标区域对应的环境污染等级。
8、可选的,根据相似度将各个数据簇集中的数据簇进行分组得到数据簇组包括:
9、针对各个数据簇集中的数据簇,计算数据簇中各个数据对应坐标的平均值得到第一目标坐标;
10、将该数据簇对应的质心坐标与第一目标坐标进行求平均得到第二目标坐标;该质心坐标为聚类算法对环境监测数据进行归类时产生的;
11、获取任意一个数据簇集,根据该数据簇集内的数据簇进行分组得到目标数据组;各目标数据组都对应一个第二目标坐标;
12、针对每一剩余的数据簇集,依次判断该数据簇集内各个数据簇对应的第二目标坐标与目标数据组对应的第二目标坐标的目标距离,以目标距离最小值为条件,对该数据簇集内各个数据簇进行分组,得到数据簇组。
13、可选的,根据共有数据确定该数据簇组的数据特征,确定非共有数据中满足该数据特征的有效数据,将该有效数据和共有数据结合得到该数据簇组对应的数据聚类结果包括:
14、根据该共有数据,拟合一个标准的多元正态分布函数;
15、计算非共有数据中各个数据落在多元正态分布函数上的期望;
16、将期望大于预设值的数据记为有效数据;
17、将该有效数据和共有数据结合得到该数据簇组对应的数据聚类结果。
18、可选的,计算非共有数据中各个数据落在多元正态分布函数上的期望之后还包括:
19、将期望小于预设值的数据记为无效数据;
20、将该无效数据对应的数据簇记为原始数据簇,针对该原始数据簇,通过该原始数据簇对应的第二目标坐标,获取与该数据簇最近距离的替换数据簇;所述替换数据簇为与该原始数据簇相邻的数据簇;
21、将该无效数据划分到替换数据簇中,计算该无效数据落在替换数据簇对应的多元正态分布函数上的目标期望;
22、若该目标期望大于预设目标期望值,则将该无效数据归类到所述替换数据簇中。
23、可选的,将该无效数据划分到替换数据簇中,计算该无效数据落在替换数据簇对应的多元正态分布函数上的目标期望还包括:
24、步骤一:若该目标期望小于预设目标期望值,则将该无效数据划分至下一最近距离的替换数据簇;
25、步骤二:重新计算该无效数据落在替换数据簇对应的多元正态分布函数上的目标期望;
26、步骤三:若该目标期望依然小于预设目标期望值,则重复上述步骤一和步骤二,直到该无效数据对所有替换数据簇对应的目标期望都小于预设目标期望值,则将该无效数据记为特别数据后进行单独归类。
27、在本发明实施的第二方面,提出一种数据聚类集成融合装置,包括:所述装置包括数据簇集模块、数据簇组模块、共有数据模块、数据聚类结果模块和环境污染等级确定模块:
28、所述数据簇集模块,用于通过多个预设聚类算法对目标区域的环境监测数据进行归类得到每个聚类算法对应的数据簇集;每个聚类算法设置的数据簇个数相同;
29、所述数据簇组模块,用于根据相似度将各个数据簇集中的数据簇进行分组得到数据簇组;数据簇组的个数与数据簇个数相同;每一数据簇组包含各个数据簇集中的一个数据簇;
30、所述共有数据模块,用于针对每个数据簇组,确定数据簇组中共有数据和非共有数据;共有数据为数据簇组中各个数据簇均包含的数据;非共有数据为数据簇组中除共有数据以外的数据;
31、所述数据聚类结果模块,用于根据共有数据确定该数据簇组的数据特征,确定非共有数据中满足该数据特征的有效数据,将有效数据和共有数据结合得到该数据簇组对应的数据聚类结果;
32、所述环境污染等级确定模块,用于确定每个数据簇组对应的数据聚类结果得到集成数据聚类结果,根据集成数据聚类结果得到所述目标区域对应的环境污染等级。
33、可选的,所述数据簇组模块包括第一目标坐标模块、第二目标坐标模块、目标数据组模块和数据簇分组模块:
34、所述第一目标坐标模块,用于针对各个数据簇集中的数据簇,计算数据簇中各个数据对应坐标的平均值得到第一目标坐标;
35、所述第二目标坐标模块,用于将该数据簇对应的质心坐标与第一目标坐标进行求平均得到第二目标坐标;该质心坐标为聚类算法对环境监测数据进行归类时产生的;
36、所述目标数据组模块,用于获取任意一个数据簇集,根据该数据簇集内的数据簇进行分组得到目标数据组;各目标数据组都对应一个第二目标坐标;
37、所述数据簇分组模块,用于针对每一剩余的数据簇集,依次判断该数据簇集内各个数据簇对应的第二目标坐标与目标数据组对应的第二目标坐标的目标距离,以目标距离最小值为条件,对该数据簇集内各个数据簇进行分组,得到数据簇组。
38、可选的,所述数据聚类结果模块包括多元正态分布函数模块、期望分布模块、有效数据模块和数据结合模块:
39、所述多元正态分布函数模块,用于根据该共有数据,拟合一个标准的多元正态分布函数;
40、所述期望分布模块,用于计算非共有数据中各个数据落在多元正态分布函数上的期望;
41、所述有效数据模块,用于将期望大于预设值的数据记为有效数据;
42、所述数据结合模块,用于将该有效数据和共有数据结合得到该数据簇组对应的数据聚类结果。
43、可选的,所述期望分布模块包括无效数据模块、替换数据簇模块、目标期望模块和数据归类模块:
44、所述无效数据模块,用于将期望小于预设值的数据记为无效数据;
45、所述替换数据簇模块,用于将该无效数据对应的数据簇记为原始数据簇,针对该原始数据簇,通过该原始数据簇对应的第二目标坐标,获取与该数据簇最近距离的替换数据簇;所述替换数据簇为与该原始数据簇相邻的数据簇;
46、所述目标期望模块,用于将该无效数据划分到替换数据簇中,计算该无效数据落在替换数据簇对应的多元正态分布函数上的目标期望;
47、所述数据归类模块,用于若该目标期望大于预设目标期望值,则将该无效数据归类到所述替换数据簇中。
48、可选的,所述目标期望模块包括无效数据划分模块、重新计算模块和单独归类模块:
49、所述无效数据划分模块,用于若该目标期望小于预设目标期望值,则将该无效数据划分至下一最近距离的替换数据簇;
50、所述重新计算模块,用于重新计算该无效数据落在替换数据簇对应的多元正态分布函数上的目标期望;
51、所述单独归类模块,用于若该目标期望依然小于预设目标期望值,则重复上述所述替换数据簇模块和所述重新计算模块,直到该无效数据对所有替换数据簇对应的目标期望都小于预设目标期望值,则将该无效数据记为特别数据后进行单独归类。
52、本发明的有益效果:
53、本发明提出了一种数据聚类集成融合方法,通过多个预设聚类算法对目标区域的环境监测数据进行归类,得到每个聚类算法对应的数据簇集;根据相似度将各个数据簇集中的数据簇进行分组得到数据簇组;针对每个数据簇组,确定数据簇组中共有数据和非共有数据;根据共有数据确定该数据簇组的数据特征,确定非共有数据中满足该数据特征的有效数据,将有效数据和共有数据结合得到该数据簇组对应的数据聚类结果;确定每个数据簇组对应的数据聚类结果得到集成数据聚类结果,根据集成数据聚类结果得到目标区域对应的环境污染等级;根据数据簇之间的相似度,将这些数据簇进行分组从而确定数据簇组中共有数据和非共有数据,根据共有数据确定该数据簇组的数据特征,再根据该数据特征确定非共有数据中满足该数据特征的有效数据,从而降低了每个数据簇中的低质量聚类成员,避免了这些低质量的基本聚类成员对最终的集成融合结果产生负面影响,提高了整体的分析准确性和可靠性。
- 还没有人留言评论。精彩留言会获得点赞!