基于高斯分布参数调节的人工智能数据处理方法及系统
本发明涉及人工智能,特别是基于高斯分布参数调节的人工智能数据处理方法及系统。
背景技术:
1、随着人工智能技术的发展,大数据的分析与处理成为解决各种技术问题的重要工具,在轨道交通方面,由于实际数据采集困难和个别故障信息类型样本较少等原因,投入到人工智能算法的训练集样本往往存在数据分类不平衡的问题,严重影响人工智能算法训练所得的训练模型的处理性能。
2、在分类模型处理不平衡数据集的过程中会过多关注多数类样本,无法保证更具有价值的少数类样本的分类性能,使用采样的方法可以增加少数类数据样本数量,改变数据集的平衡率。
3、本发明为了克服随机采样过程中新增加的少数类样本导致的过拟合,合成的新样本有可能成为噪声样本,不具备少数类样本的特征,干扰分类算法的准确性,无法有效处理好少数类样本与多数类样本之间的边界问题,对分类效果造成一定程度的影响,本发明采用基于高斯分布参数调节的人工智能数据处理方法,通过自适应算法调整生成的合成数据集中的少数类危险样本数量,实现对不平衡数据集的有效处理,并在迭代过程中动态优化分类性能,最终输出性能稳定和适应性强的优等合成数据集。
技术实现思路
1、鉴于现有的基于高斯分布参数调节的人工智能数据处理方法及系统中存在的问题,提出了本发明。
2、因此,本发明的目的是提供基于高斯分布参数调节的人工智能数据处理方法及系统,针对处理不平衡数据集时缺乏自适应性和性能不稳定的问题,本发明通过基于高斯分布参数调节的方法,结合knn算法和自适应算法,实现了有效调整生成的合成数据集中少数类危险样本数量,达到稳定性能和适应性强的优等合成数据集。
3、为解决上述技术问题,本发明提供如下技术方案:
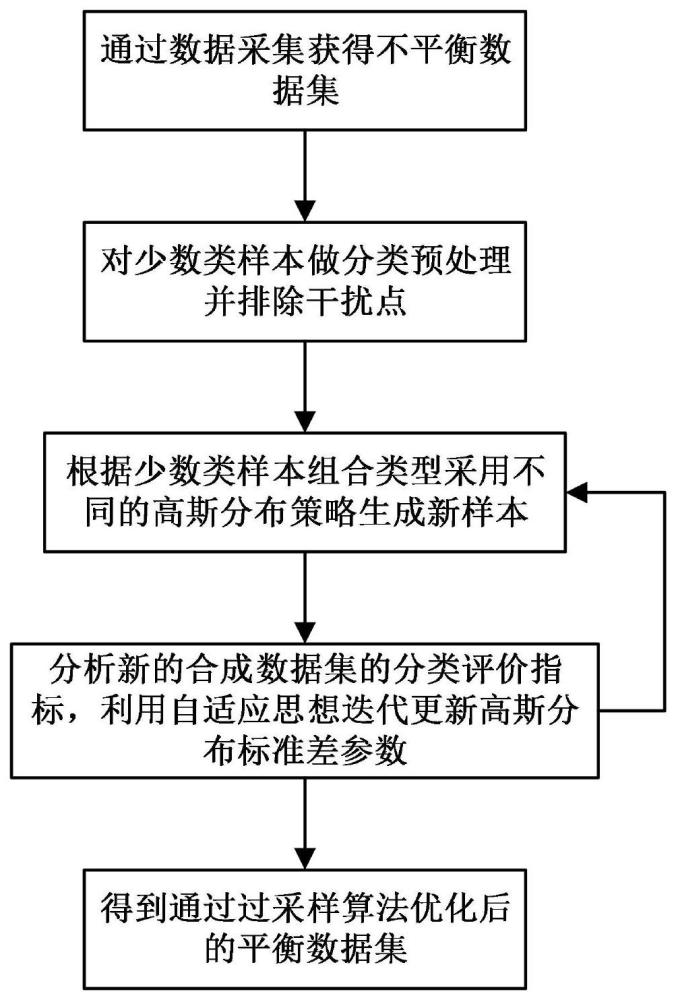
4、第一方面,本发明实施例提供了基于高斯分布参数调节的人工智能数据处理方法,其包括,通过数据采集获得自适应高斯分布参数的不平衡数据集,对数据集进行预处理获取少数类样本数量,利用knn算法计算少数类样本的邻近点;根据邻近点中少数类样本和多数类样本的比例对少数类样本进行分类,设置生成的少数类样本数量,选取危险样本数量,计算少数类危险样本数量,将新生成的少数类危险样本数量和原始数据集结合得到合成数据集;对合成数据集进行分类得到分类性能指标,对分类性能指标进行分析,通过自适应算法调节插值过程高斯分布参数,生成优等合成数据集并输出,基于输出结果对人工智能数据进行处理。
5、作为本发明所述基于高斯分布参数调节的人工智能数据处理方法的一种优选方案,其中:所述预处理包括利用knn算法计算少数类样本的k1个邻近点,根据邻近点中少数类样本与多数类样本的比例,将少数类样本分别分类为干扰样本、危险样本和安全样本,并排除干扰样本;
6、所述knn算法包括计算少数类样本的测试样本与训练样本之间的距离,具体计算公式为:
7、
8、其中,d表示测试样本xi与其中一个训练样本xj的欧氏距离,n表示该数据样本的特征数;
9、所述邻近点包括通过对欧式距离的大小进行比较,选择测试样本距离近的k个训练样本。
10、作为本发明所述基于高斯分布参数调节的人工智能数据处理方法的一种优选方案,其中:所述设置生成的少数类样本数量包括选取邻近点的安全样本和危险样本,具体步骤如下:
11、当选取的邻近点为安全样本时,则插值操作公式为:
12、
13、其中,gauss1表示安全样本期望值,表示标准差的高斯分布在σ1标准差条件下生成的随机数;
14、当选取的邻近点为危险样本时,则插值操作公式为:
15、
16、其中,gauss2表示危险样本期望值,表示标准差的高斯分布在σ2标准差条件下生成的随机数。
17、作为本发明所述基于高斯分布参数调节的人工智能数据处理方法的一种优选方案,其中:所述合成数据集包括基于安全样本和危险样本按照8:2的比例进行分类,分为训练数据集和测试数据集,利用训练数据集训练分类模型,利用测试数据集训练分类性能指标,所述分类性能指标包括g-mean、f-measure和auc,对高斯分布的标准差参数σ1和σ2进行循环迭代调节,寻找最优的分类性能指标,所述分类性能指标的具体计算步骤如下:
18、分类性能指标g-mean的计算公式为:
19、
20、其中,tp表示分类器实际正类的预测正类值,tn表示分类器实际负类的预测负类值;
21、分类性能指标f-measure的计算公式为:
22、
23、其中,tp表示分类器实际正类的预测正类值,tn表示分类器实际负类的预测负类值;
24、所述分类性能指标包括根据受试者工作特征曲线roc的下面积进行计算,所述工作特征曲线roc的纵坐标为正类样本分类正确的概率tpr,所述工作特征曲线roc的横坐标为负类样本分类错误的概率fpr,具体计算公式为:
25、
26、
27、其中,tp表示分类器实际正类的预测正类值,tn表示分类器实际负类的预测负类值,tpr表示正类样本分类正确的概率,fpr表示负类样本分类错误的概率。
28、作为本发明所述基于高斯分布参数调节的人工智能数据处理方法的一种优选方案,其中:所述对分类性能指标进行分析包括设定分类性能指标的绝对变化阈值δt和分类性能指标相对变化阈值δp,判断分类性能指标是否在设定的范围内变化;
29、当分类性能指标的绝对变化阈值δt小于相对变化阈值δp时,则判定为收敛状态,此时,系统达到稳定的分类性能,无需进一步迭代;
30、当分类性能指标的绝对变化阈值δt大于或等于相对变化阈值δp时,则判定为继续迭代状态,此时,系统处在提升状态,需继续调节参数进行迭代。
31、作为本发明所述基于高斯分布参数调节的人工智能数据处理方法的一种优选方案,其中:所述模型训练包括在最后一次迭代完成后的周围随机生成新解,利用metropolis准则对新解进行计算,具体计算公式为:
32、
33、其中,et+1为新解的分类性能指标,et为当前最优解的分类性能指标,t为模拟退火初始温度。
34、作为本发明所述基于高斯分布参数调节的人工智能数据处理方法的一种优选方案,其中:所述迭代包括内循环和外循环,所述内循环包括将新解进行实验得到的分类性能指标,与当前最优解进行比较判断;使用随机生成或者混沌算子的方法在当前最优解周围随机生成新解;
35、当内循环次数结束时,记作完成一次外循环,每次外循环新解t值会改变为t=kt,k为退火系数;
36、当多次外循环后,温度达到阈值,得到σ1和σ2的模拟退火法最优解并输出结果,对人工智能数据进行调节。
37、第二方面,本发明实施例提供了基于高斯分布参数调节的人工智能数据处理系统,其包括:计算模块,其通过数据采集获得自适应高斯分布参数的不平衡数据集,利用knn算法计算少数类样本的邻近点;结合模块,其根据邻近点中少数类样本和多数类样本的比例对少数类样本进行分类,设置生成的少数类样本数量,计算少数类危险样本数量,将新生成的少数类危险样本数量和原始数据集结合得到合成数据集;分析模块,通过对合成数据集进行分类得到分类性能指标,对分类性能指标进行分析,生成优等合成数据集并输出,基于输出结果对人工智能数据进行处理。
38、第三方面,本发明实施例提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其中:所述处理器执行所述计算机程序时实现上述的基于高斯分布参数调节的人工智能数据处理方法的任一步骤。
39、第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,其中:所述计算机程序被处理器执行时实现上述的基于高斯分布参数调节的人工智能数据处理方法的任一步骤。
40、本发明有益效果为:本发明通过数据采集获得自适应高斯分布参数,利用knn算法计算少数类样本的邻近点,进而对少数类样本进行分类,生成合成数据集,通过自适应算法调节少数类危险样本数量,动态优化合成数据集,实现对不平衡数据的有效处理,通过细致的性能评估和分析,根据分类性能指标的变化情况,判断是否继续迭代,以达到生成性能稳定和适应性强的优等合成数据集目的,本发明使人工智能数据处理更具自适应性和鲁棒性,为应对实际复杂场景提供了有效的解决方案。
- 还没有人留言评论。精彩留言会获得点赞!