一种基于神经压缩与渐进式精细化的点云视频处理方法
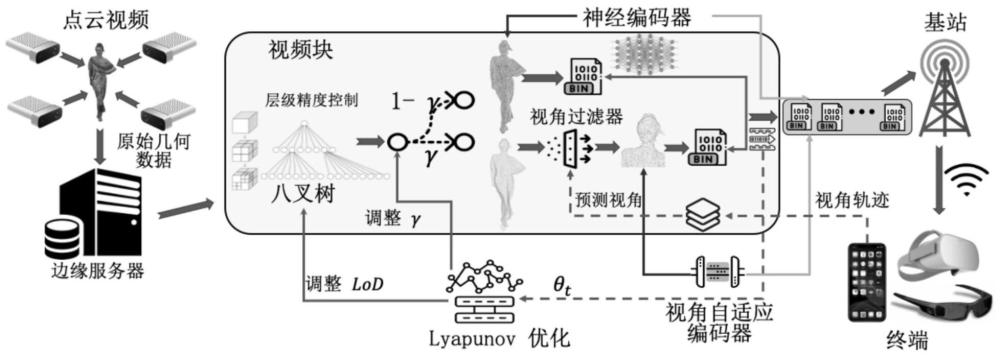
本发明涉及点云视频处理,特别是涉及一种基于神经压缩与渐进式精细化的点云视频处理方法。
背景技术:
1、pcv为用户提供了六自由度(6-dof)的逼真3d场景观看体验,使人们能够全身心沉浸在3d视频场景中,并自由变换位置和角度观看视频内容。然而,由于其高维度和稀疏性质,pcv的处理相比2d视频更为复杂。例如,每帧包含约76万点的视频,其带宽需求高达2.9gbps,远超过普通设备的带宽能力。因此,优化pcv传输的带宽需求成为当务之急。
2、与传统的视频流媒体服务相比,点云视频(pcv)流媒体系统面临几个关键挑战:1)高带宽需求:pcv需要处理大量数据,导致其带宽需求远超过普通设备的能力。特别是在带宽受限的环境下,如何有效传输高质量的3d内容成为一个重要问题。2)实时交互的复杂性:pcv提供六自由度(6-dof)的观看体验,用户可以自由移动和旋转头部观看视频内容。这种高度的交互性要求系统能实时响应用户的动作和视角变化,而在实际应用中,这往往受到网络波动和压缩效率低下的影响。3)有效的压缩和播放连续性:为了处理大量的点云数据,有效的压缩技术至关重要。现有的压缩方法无法满足实时处理和高压缩率的双重需求。此外,保持播放的连续性,避免因为网络波动或压缩解压缩引起的播放中断,对于提供高质量的用户体验来说非常重要。
3、当前的研究已经提出了几种策略来缓解带宽消耗,主要分为压缩和视野(fieldof view,fov)自适应流媒体两大类。然而,这些方法在实际使用中仍然存在重大限制,包括用户动态和异质性交互的影响,以及当前压缩方案的低效率。fov自适应方案虽然在360度视频流中有效减少带宽消耗,但在pcv中,由于6-dof的特性,预测用户fov的准确性大大降低,导致播放频繁中断。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于神经压缩与渐进式精细化的点云视频处理方法,采用帧间编码的神经点云压缩技术,以消除帧间冗余;渐进式精细化流媒体策略,确保连续播放无中断;并且通过lyapunov优化适应不同网络和计算条件,优化长期用户qoe。
2、本发明的目的是通过以下技术方案来实现的:一种基于神经压缩与渐进式精细化的点云视频处理方法,包括以下步骤:
3、s1.在服务端构建并训练深度神经编码器;
4、所述步骤s1所述深度神经编码器包括:多尺度特征提取器、运动估计模块、运动补偿模块、残差计算模块和熵编码压缩模块,所述步骤s1包括:
5、s101.构建多尺度特征提取器,对前一帧和当前帧的pcv进行多尺度编码,以捕获多尺度的拓扑信息;所述使用多尺度特征提取器采用两个编码器和一个稀疏卷积网络块,其中特征编码器由多个降采样模块构成;
6、所述降采样模块由步长为2的稀疏卷积网络、密度特征学习模块、残差网络及步长为1的稀疏卷积网络构成,通过稀疏卷积网络作为降采样器来减少pcv的空间冗余,并通过学习层次化特征及密度信息,捕获3d空间中的复杂结构和模式;
7、所述密度学习模块的数据处理过程如下:
8、s1011.密度特征学习模块采用(k3,c,23)-spconv作为降采样器,以减少点云的空间冗余并学习层次化特征,捕获3d空间中的复杂结构和模式;
9、s1012密度感知单元引入:引入密度感知单元来提取密度特征;对于点云p的预降采样和后降采样版本pi和pi+1,这两组数据在(k3,c,23)-spconv降采样操作后由密度感知单元进行处理;
10、s1013.构建分组点集:在确定降采样点集时,每个被丢弃的点被唯一分配给其最近的降采样点,因此,与特定降采样点pn分组的所有点共同构成分组点集g(pn);
11、s1014.计算密度特征:定义点pn的密度特征dn,通过对分组点集g(pn)中的点与pn之间的距离求平均来计算;
12、s1015.采用k最近邻方法,选择pn在g(pn)中的k个最近邻居然后,根据这些邻居点计算密度dn:
13、
14、s1016.密度特征嵌入:将计算出的密度信息嵌入到潜在空间中,生成密度特征嵌入,通过多层感知器将dn映射到一个d维嵌入空间中,捕获g(pn)的密度。
15、s102.构建运动估计模块,分析前一帧和当前帧的潜在表达之间的时空相关性,并预测运动向量vt:首先前一帧特征与当前帧点云经过s101中的特征提取器分别得到特征和yt,随后将和yt拼接并通过稀疏卷积模块得到动量向量预估vt;
16、s103.构建运动补偿模块:利用运动向量vt和前一帧的潜在表达来预测当前帧的潜在表达使用加权插值算法对运动进行补偿:首先vt与进行相加,随后通过权重k加权插值补全点云达到上采样效果,得到
17、s104.构建深度熵压缩模块,采用稀疏卷积模块和多层感知机的结合来估计待压缩数据的熵,作为数据数字编码压缩的基础;前一帧的潜在表达运动向量vt和残差rt经过量化后,利用上述深度熵模型进行压缩成比特流;
18、s105.点云重建,即视频解码:基于s104中所描述的深度熵模型计算待解压数据的熵,指导数字编码器解压比特流还原出前一帧的潜在表达运动向量vt和残差rt;
19、通过由多个转置稀疏卷积模块构成的编码器进行上采样,随后通过补偿vt和rt以重建原始的点云张量yt;其中解码器与编码器的结构对称,以确保输入和输出的一致性;
20、s106.优化损失函数来更新网络权重;损失函数l由两部分构成:(1)压缩并解压重建后的与真实的y的失真程度d;(2)压缩后比特大小r;
21、l=d+λr
22、s107.对于连续的pcv数据,重复s101-s106,并基于损失函数优化深度神经编码器权重参数,直至损失值收敛,完成训练;深度神经编码器的权重参数将固定,供后续使用。
23、s2.在服务端构建并训练视角自适应编码器;
24、所述视角自适应编码器包括区域粗预测模块、内容特征编码器和内容感知轨迹估计器,所述步骤s2包括:
25、s201.构建区域粗预测模块:给定视频传输过程中m个连续的fov区域以及每个fov区域对应的内容特征;使用lstm网络,从m个连续的n个的fov中,选择n个连续历史fov轨迹中捕获特征,粗略预测下一个fov区域,记为st,其中n小于m,且选择的n个fov不包含m个连续的fov的最后一个,其中n为自定义的正整数;
26、s202.构建内容特征编码器:由多个spconv层构成的内容特征编码器,将选择的n个fov区域的内容特征{st-n-1,st-n,…,st-1}送入内容特征编码器进行提取和融合,形成ft-1;
27、s203.构建内容感知轨迹估计器:提取从预测区域st对应的内容特征ft,将ft-1和ft拼接,送入由(13,c,13)-spconv和irn网络组成的内容感知轨迹估计器,分析帧间内容特征,将粗略预测的fov区域细化为精细的预测区域st;
28、其中,fov区域是指视角区域;
29、s204.优化损失函数来更新网络权重。使用交叉熵损失函数计算预测区域st和真实区域st的差值作为损失函数l;其中,真实区域st是指n个连续历史fov的下一个真实的fov;
30、s205.不断重复s201-s204,基于损失函数优化视角自适应编码器的权重参数,直至损失值收敛,完成训练;视角自适应编码器的权重参数将会固定,用于后续处理。
31、s3.在服务端对pcv数据进行八叉树空间编码得到编码后的pcv数据,所述pcv数据是指点云视频数据;
32、八叉树空间编码过程中,八叉树空间编码的精细程度由最大深度lod决定;给定初始的lod值;
33、八叉树是用于划分三维空间的树状结构,通过递归分割三维空间,将点云数据划分为多个小区域,有效提高了大规模数据处理的效率。通过设定lod(level of depths)控制对pcv进行八叉树空间编码的精细程度,lod越大,越精细,反之,lod越小则越粗糙。lod初始化为10。
34、s4.在服务端给定初始的权重γ,将编码后的pcv数据按权重γ分配给深度神经编码器或视角自适应编码器压缩的权重,分配(1-γ)的点云由深度神经编码器压缩,剩余的γ点云由视角自适应编码器压缩;γ初始值设定为0.3;
35、s5.服务端中,深度神经编码器对自身分配到的pcv数据进行压缩;
36、s6.服务端中,利用视角自适应编码器确定当前fov区域,并过滤fov区域外的点云,随后对当前fov区域内的点云进行压缩;
37、所述步骤s6中包括:
38、s601.视角自适应编码器确定当前的fov区域:
39、如果当前客户端发送的fov区域数目小于n,则确定fov区域采用初始化的全局区域;
40、如果当前客户端发送的fov区域数目不小于n,则视角自适应编码器利用客户端发送的最新的连续n个fov区域进行预测,将预测结果作为当前的fov区域;
41、s602.在获得当前的fov区域后,部署fov过滤器进行降采样,剪除fov外的点;给定观察者在3d坐标空间中的位置p(x,y,z),表示注视方向的3d单位向量表示点云的一组3d点s={p1,p2,...,pn},以及fov角度θ,
42、通过计算观察者位置到s中每个点pi的归一化向量并比较注视方向向量与每个归一化向量之间的角度αi的余弦值和fov角度一半的余弦值来确定fov内的点集
43、然后对当前fov区域内的点云进行压缩。
44、s7.服务端将压缩后的视频数据实时传输到客户端,客户端将步骤s5中压缩后的比特流传输到客户端侧解压时得到pcv的基础层;将步骤s6的比特流解压后与基础层融合得到画质增强,客户端记录用户的fov区域,并发送至服务端;
45、所述步骤s7包括:
46、s701.服务端将步骤s5中压缩得到的比特流标记为stream1,并传输客户端,客户端解压stream1,即进行视频解码,重建点云视频,得到pcv基础层;
47、服务端将步骤s6中压缩得到的比特流记为stream2,并传输至客户端;客户端解压stream2得到fov区域内的增强层;
48、s702.将s701中pcv基础层与fov区域内的增强层进行融合,最终得到精细化的pcv;
49、s703.客户端实时记录用户的fov并传输至服务端,供视角自适应编码器不断更新预测的未来fov。
50、s8.监测网络状况和计算资源使用情况以及当前qoe,使用lyapunov优化算法动态调整视频流的编解码策略,以针对长期qoe进行优化。
51、所述步骤s8聚焦于利用lyapunov优化算法来优化视频流媒体的qoe,具体流程如下:
52、s801.qoe最大化问题的形式化:定义qoe主要由视频的感知质量和延迟决定;使用mpeg评估工具计算原始和重建点云之间的失真误差,从而评估感知质量;
53、监测当前时间t的网络可用带宽和系统的计算资源占用状态;衡量计算资源占用指标为ucpu、ugpu和umem,并根据权重向量λ1,λ2,λ3计算资源消耗分数:
54、rcs=λ1×ucpu+λ2×ugpu+λ3×umem
55、资源占用量计算方式:
56、s802.资源约束条件:鉴于网络条件的动态性和计算资源的限制计算带宽约束和资源约束:
57、带宽约束:用函数h(lodt,γt)表示当前带宽消耗,并确保其不超过t时刻的可用带宽bt;计算资源约束:当前计算资源总量c(lodt,γt)不超过系统的总计算资源
58、s803.lyapunov优化:将长期优化问题转化为单一时间槽t问题,然后使用进化算法来解决,其优化目标是优化总时长t的qoe:
59、
60、s.t.0≤γ≤1
61、
62、h(lodt,γt)≤bt
63、
64、s804.进化算法求解器:由于问题的混合整数非线性特性,采用进化算法求解器来迭代优化潜在参数集合{lodt,γt},利用得到的lodt,γt作为新的八叉树最大深度和分配权重,然后返回步骤s1进行下一次的点云数据处理。
65、本发明的有益效果是:本发明采用帧间编码的神经点云压缩技术,以消除帧间冗余;渐进式精细化流媒体策略,确保连续播放无中断;并且通过lyapunov优化适应不同网络和计算条件,优化长期用户qoe。
- 还没有人留言评论。精彩留言会获得点赞!