基于图的模型划分的边端协同推理方法及系统
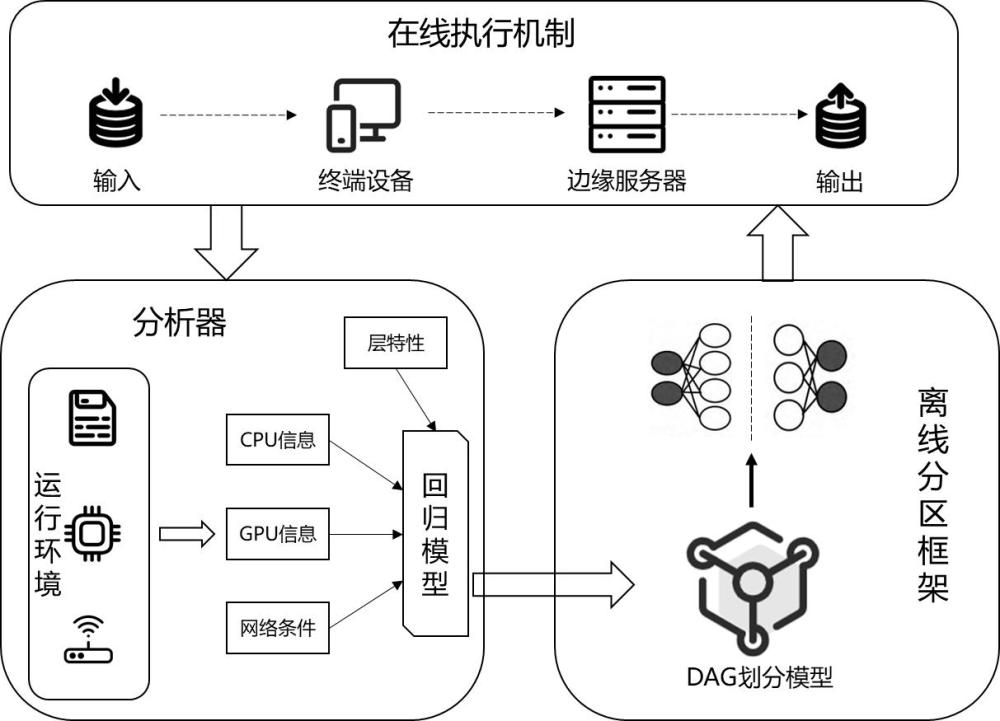
本发明属于移动边缘计算场景下多设备协作计算领域,具体涉及基于图的模型划分的边端协同推理方法及系统。
背景技术:
1、在现代计算机应用中,卷积神经网络(convolutional neural networks,简称为cnn)被广泛应用于计算机视觉、自然语言处理、图像识别和大数据分析多个领域。此外,现代创新技术产生了大量的数据,如自动驾驶汽车、人工智能医疗设备、智能手机和智能监控,它们是具有实时性和隐私敏感的应用,需要更低的延迟和更高的隐私保护。传统架构中cnn模型部署在具有强大计算资源的远程云中,终端设备产生的原始数据被传输到云端进行处理并返回结果,这面临着广域网络的不可靠和延迟严重的问题。为了应对这一挑战,许多研究人员提出了不同的解决办法,通过灵活分配计算、存储、带宽资源来实现低延迟和低能耗。
2、随着人工智能技术和边缘计算的发展,边缘智能正得到越来越多的关注,在靠近数据源的设备上部署ai应用,可以提供更加灵活和安全的服务,因此,可以将推理任务下放到边缘服务器上进行处理,以减少数据传输和云端计算的压力。虽然cnn具有较高的推理精度和可重构的灵活性,但执行cnn需要较大的计算资源,特别是对于具有大量相乘累加操作的深层cnn。考虑到边缘服务器的计算能力是有限的,所以,不能把所有的计算任务都卸载到边缘服务器上,部分任务应该在终端设备执行。如何在具有资源约束的边缘服务器和终端设备组成的实际系统中实现快速、高精度的cnn协同推理是基于cnn应用最具挑战性的问题之一。
3、为解决上述问题,充分利用终端设备和边缘服务器的计算资源,需要找到一种在边缘计算环境中加速cnn推理任务的新颖方法。
技术实现思路
1、本发明的目的在于克服现有技术中的不足,提供一种基于图的模型划分的边端协同推理方法及系统,用以解决现有的cnn推理任务的推理时间没有得到最大限度的减少的问题。
2、为达到上述目的,本发明是采用下述技术方案实现的:
3、第一方面,本发明提供了一种基于图的模型划分的边端协同推理方法,基于边缘网络系统,所述边缘网络系统至少包括相连接的端设备和边缘服务器;
4、所述方法包括以下步骤:
5、步骤1,获取cnn模型以及边缘网络系统的工作负载信息和网络质量信息;
6、步骤2,将cnn模型转换为有向无环图;
7、步骤3,采用等价节点合并的方法对所述有向无环图进行压缩;
8、步骤4,对时延优化问题进行建模,cnn协同推理时延由计算时延和数据传输时延组成。
9、步骤5,基于图神经网络和dqn算法,根据所述边缘网络系统的工作负载信息和网络质量信息进行dag划分模型的训练,以最小化时延为目标求解所述时延优化问题,得到最优的划分策略。根据划分策略,将cnn模型划分为2个cnn模型分段,分别分配给端设备和边缘服务器进行计算。
10、进一步的,所述边缘网络系统的工作负载信息包括端设备和边缘服务器的浮点计算能力、cpu占用率、gpu显存使用率;
11、所述网络质量信息包括端设备和边缘服务器之间的网络带宽 b w。
12、进一步的,步骤2中,将cnn模型转换为有向无环图,包括:
13、步骤21,理解cnn模型的结构:cnn模型包括卷积层、池化层、全连接层。卷积层和池化层用于提取图像特征,全连接层用于进行分类或回归任务。
14、步骤22,确定cnn模型的输入和输出:确定cnn模型的输入和输出,对于图像分类任务,输入是图像数据,输出是类别标签。
15、步骤23,创建节点:基于cnn模型的结构,为每个层级创建一个节点。
16、步骤24,建立节点之间的关系:根据cnn模型的连接关系,建立节点之间的有向边。每个有向边表示各个层级之间的数据流动。
17、步骤25,构建有向无环图:根据节点和有向边的关系,构建有向无环图。节点表示层级,有向边表示数据流动,并使用图论库进行有向无环图的构建。
18、步骤26,验证图的结构:验证所构建的有向无环图是否符合cnn模型的结构和连接关系,使图能够准确地描述cnn模型的运算过程。检查节点和有向边的数量是否正确,以及节点之间的连接关系是否符合cnn模型的结构,得到验证后的有向无环图。
19、进一步的,步骤3中,采用等价节点合并的方法对所述有向无环图进行压缩,包括:
20、步骤31,使用深度优先搜索dfs算法对原始图进行拓扑排序,选择一个起始节点进行搜索,在深度优先搜索过程中,将当前节点标记为已访问。
21、步骤32,对于当前节点的每个未访问的邻居节点,递归地进行深度优先搜索。
22、步骤33,当前节点的所有邻居节点都被访问完毕后,将当前节点加入到拓扑排序结果的头部。
23、步骤34,返回上一层继续搜索,继续从未访问的节点中选择一个作为当前节点,重复步骤32和步骤33,直到所有节点都被访问过。在每次访问节点时,需要判断节点是否已经被访问过,以避免重复访问和形成环路。
24、步骤35,最终得到的拓扑排序结果即为有向无环图的拓扑排序序列。
25、步骤36,初始化一个等价节点的映射表,用于记录每个节点的等价节点。从拓扑序列中的第一个节点开始,遍历每个节点,从中找出具有相同入度和相同出度的节点,并在这些节点中找出具有相同输入和输出的节点,具有相同输入和输出的节点是等价的,由此来更新等价节点的映射表,通过映射表进行等价节点的合并,并进行有向无环图的更新。
26、进一步的,在每次访问节点时,判断节点是否已经被访问过,如果未被访问过则继续访问,否则跳过。
27、进一步的,步骤4中,对时延优化问题进行建模的方法包括:
28、cnn协同推理时延由计算时延和数据传输时延组成。
29、假设节点间的传输延迟是无穷小的。数据传输时延包括上传数据的时延 t up和返回结果的时延 t down,设 t tr为总传输时延, d s为端设备输出数据的大小, d m为结果数据的大小,则,
30、cnn模型的层类型具有不同的计算复杂度,对于卷积层,
31、,
32、其中 h和 w分别表示输入特征图的高度和宽度, c in和 c out分别表示输入和输出通道数, k表示卷积核的大小。
33、对于全连接层,
34、,
35、 i和 o分别代表输入和输出特征图的维数。在终端设备或边缘服务器上,单个卷积层和单个全连接层的推理时间可表示为:,
36、表示回归模型,上式表示通过回归模型进行各个层级的推理时延预测,以端设备或边缘服务器的浮点计算能力 fs e、cpu占用率、gpu显存使用率以及层级的计算复杂度为输入,以单个层级在端设备或边缘服务器的推理时延为输出;
37、用和分别表示节点 v i对应层在终端设备和边缘服务器上的处理延迟,表示在终端设备上处理节点对应层的集合,表示在边缘服务器上处理节点对应层的集合。设和分别表示终端设备和边缘服务器上的执行延迟,则
38、
39、总推断延迟 为:
40、。
41、进一步的,dag划分模型的输入包括边缘网络系统的工作负载信息和网络质量信息,通过迭代,输出为最优的dag划分策略。
42、进一步的,基于图神经网络和dqn算法,根据所述边缘网络系统的工作负载信息和网络质量信息进行dag划分模型的训练,求解所述时延优化问题,得到最优的划分策略,包括:
43、步骤51,建立图神经网络的架构,用于处理和编码有向无环图的信息。用图神经网络代替dqn算法中的其他神经网络。
44、通过图神经网络来表示节点的状态,对于节点 v i,使用一个向量 g( v i)来表示它的状态,其中 g( v i)是节点 v i的特征向量,包含节点的度以及节点的计算复杂度。
45、所述dqn算法中:
46、状态空间:,其中 b w表示端设备和边缘服务器之间的网络带宽, g( v i)是节点 v i的特征向量,用来表示节点的状态, c end表示端设备的计算资源, c edge表示边缘服务器的计算资源,计算资源主要包括浮点计算能力、cpu占用率、gpu显存使用率,表示原始输入数据以及各个节点的输出数据大小,表示原始输入数据大小,表示节点 v 1的输出数据大小,表示节点 v 2的输出数据大小,表示节点 v m的输出数据大小;
47、动作空间:由所有可选的划分策略组成。对于cnn模型的协同推理计算,其动作就是在端设备和边缘服务器之间选择合适的划分点,基于当前状态,dag有m-1个划分点。动作空间,其中表示有向无环图划分点的集合,、、分别表示第1、2、个节点与节点之间的划分点;
48、奖励函数:根据执行的动作反馈相应的奖励值。以任务推理时延为优化目标,与此同时,dqn神经网络的目标是找到使奖励函数r最大的动作a所对应的最大q值。将奖励函数r定义为任务推理最小时延的负相关,即:
49、;
50、步骤52,初始化dqn图神经网络模型:定义一个图神经网络,用于估计q值函数;定义神经网络的结构、学习率 φ、折扣因子 y、探索率 ε初值;
51、初始化经验池:创建一个经验回放缓冲区,用于存储智能体与环境交互获得的经验,包括状态、动作、奖励、下一个状态;
52、步骤53,与环境交互,获取网络环境状态信息;
53、根据网络环境状态信息和探索率 ε选择动作。其中,探索率 ε为一个取值的超参数,表示选择随机动作的概率,用于探索性地选择非最优动作。如果随机数小于探索率,选择随机动作;反之,根据当前 q值选择最优动作。
54、步骤54,执行动作,即选择一个划分点对有向无环图进行划分。执行动作后获得相应的奖励,即推理时延的反馈,同时观察到网络状态更新为;
55、步骤55,将与环境交互获得的经验值存入dqn经验池,当经验池中的元组数目达到一定值n时,随机选择经验样本组成小批量数据子集来训练dqn。当经验池容量大于 n时,则会删除最老的经验样本,仅保留最新的 n个经验样本,保持样本的新鲜度;
56、步骤56,神经网络计算出该批次样本对应的 q值,进而找出当前状态下 q值对应的动作以及执行动作后智能体所获得的奖励:,最后计算出目标 q值。
57、该批次样本对应的q值为:
58、,
59、其中表示主网络的输出函数,它是由一个图神经网络确定的函数,表示主网络参数。
60、 q值对应的动作为:
61、,
62、执行动作后智能体获得环境的奖励值为:
63、,
64、进而可求得目标网络q值:
65、,
66、其中, y为折扣因子,用于平衡当前奖励和未来奖励的重要性程度;
67、步骤57,通过损失函数计算使得当前q值无限接近于目标q值,最终达到收敛状态。损失函数定义为:
68、,
69、损失函数衡量了神经网络的预测误差,即当前状态下的 q值与目标 q值之间的差异;
70、步骤58,更新主网络参数:通过反向传播算法更新主网络的参数即图神经网络参数,以最小化损失函数;
71、更新目标网络参数:定期将主网络的参数复制到目标网络中;
72、步骤59,将当前状态更新为下一个状态,以便在下一步训练中使用更新后的状态进行决策。
73、步骤510,重复上述步骤53-59,直到观察到的网络状态是终止状态,即已经找到最小推理延迟的划分策略,此时停止迭代过程。
74、第二方面,本发明提供一种基于图的模型划分和边端协同推理系统,包括:
75、信息采集模块:用于获取cnn模型以及边缘网络系统的工作负载信息和网络质量信息;
76、转换模块:用于将cnn模型转换为有向无环图;
77、dag压缩模块:用于采用等价节点合并的方法对所述有向无环图进行压缩;
78、建模模块:用于对时延优化问题进行建模,cnn协同推理时延由计算时延和数据传输时延组成;
79、dag划分模块:用于基于图神经网络和dqn算法,根据所述边缘网络系统的工作负载信息和网络质量信息进行dag划分模型的训练,以最小化时延为目标求解所述时延优化问题,得到最优的划分策略。根据划分策略,将cnn模型划分为2个cnn模型分段,分别分配给端设备和边缘服务器进行计算。
80、第三方面,本发明提供一种基于图的模型划分和边端协同推理系统,包括处理器及存储介质;
81、所述存储介质用于存储指令;
82、所述处理器用于根据所述指令进行操作以执行根据第一方面所述方法的步骤。
83、与现有技术相比,本发明所达到的有益效果:
84、1、本发明构建了一种三层边缘网络系统架构,采用边端协作的方式进行cnn任务推理,并考虑将cnn模型转换为有向无环图,其拓扑结构可以方便的划分成多个子图,使得模型更加高效和灵活,有助于提高模型的性能和效率。
85、2、本发明提出一种等价节点合并的模型压缩方法,为提高模型的性能和效率,提出等价节点合并的方法对模型进行高效的压缩,并将图神经网络和dqn算法相结合,找到最优的模型划分策略,以最小化推理时延。通过在有向无环图中找出等价节点,进行融合合并,减小有向无环图的节点数量,可以显著减小cnn模型的大小,节省存储资源并加快任务的推理速度。并且合并后的有向无环图拓扑顺序不发生改变,由此造成的推理精度损失较小,可以忽略不计。
86、3、本发明采用改良的dqn算法对模型进行划分,将图神经网络技术和dqn算法相结合,用图神经网络代替dqn算法中的神经网络,根据边缘服务器和终端设备可用的计算和通信资源,动态划分有向无环图进行任务的协同推理,以最小化任务推理时延,当网络环境发生变化时,可以通过训练好的dag划分模型快速找到最优划分策略。
87、4、本发明通过将边端协同推理工作中涉及到的推理时延和传输时延转换为与计算任务复杂度、设备负载和网络带宽相关联的最优化问题并求解,以实现任务的边端协同加速推理。
88、5、本发明提出基于图的模型划分的边端协同推理方法及系统,将cnn模型转换为有向无环图进行模型的高效压缩,并采用改良的dqn算法对cnn模型进行合理划分,利用终端设备和边缘服务器的计算和通信资源进行边端协同任务推理,以最小化推理时延。
- 还没有人留言评论。精彩留言会获得点赞!