一种项目推荐方法、系统与计算机设备
本发明涉及推荐方法,特别涉及一种项目推荐方法、系统与计算机设备。
背景技术:
1、近年来,各类web应用产生了海量的信息。比如,在线零售平台不断从用户获取大量的购买和评论信息,大量的信息很容易导致信息过载,这使得用户很难获取目标信息。推荐系统是一种利用用户行为、偏好和项目信息等数据,为用户提供个性化推荐的技术和工具。其目的是通过分析用户的兴趣和需求,预测用户可能感兴趣的项目,并将这些项目推荐给用户,以提升用户体验和满足他们的需求。推荐系统作为缓解信息过载的重要工具,它被广泛应用于各种基于web的应用,如在线零售平台的商品推荐,在线社交网络的帖子推荐,新闻网站的新闻推荐等。
2、具体来说,在线零售平台上,推荐系统可以根据用户的购买历史和偏好,预测其潜在的兴趣,并向其推荐相关的商品/这有助于用户快速找到自己感兴趣的商品,减少信息收缩成本,并提升购物体验。类似地,在线社交网络中推荐系统可以根据用户的社交关系、兴趣爱好和历史行为,项目推荐与关注领域相关的帖子用户。这样的推荐可以帮助用户发现更有价值的内容,扩大社交圈子,并促进用户互动。此外,新闻网站也可以利用推荐系统为用户提供个性化的新闻推荐。通过分析用户的浏览历史、点击行为以及对不同主题的兴趣程度,推荐系统可以向用户推送与其兴趣相关的新闻内容,使用户能够更加便捷地获取到感兴趣的信息。
3、传统推荐系统的方法主要包括基于内容的推荐、协同过滤和基于矩阵分解的方法。基于内容的推荐(content-based recommendation):该方法根据用户和项目的属性特征进行推荐。首先,针对用户和项目,从它们的属性中提取关键特征。然后,通过计算用户和项目之间的相似度,推荐与用户兴趣相关的项目。基于内容的推荐方法适用于情境较为简单的推荐场景,可以提供个性化的推荐结果。然而,该方法往往无法捕捉到用户和项目之间的复杂交互行为,且容易受到特征选择和表示的限制。协同过滤(collaborativefiltering,cf):cf方法是一种基于用户行为数据的推荐方法,它利用用户-项目交互数据来预测用户对未知项目的喜好程度。协同过滤可以分为基于用户(user-based)和基于项目(item-based)两种方法。基于用户的协同过滤:该方法通过计算相似用户之间的兴趣偏好,将相似用户的喜好扩展给目标用户,并向目标用户推荐相似用户喜欢的项目。基于用户的协同过滤简单直观,但在数据稀疏性和可扩展性方面存在问题。基于项目的协同过滤:该方法通过计算相似项目之间的关联度,将用户对一个项目的评分扩展给与其相似的其他项目,并向用户推荐相似项目。基于项目的协同过滤相对于基于用户的方法具有更好的可扩展性和抗噪能力。基于矩阵分解的方法(matrix factorization):这是一种常用的用于推荐系统的方法,它通过将用户-项目评分矩阵分解为两个低维矩阵,来获取用户和项目的隐含特征表示。常见的矩阵分解方法包括奇异值分解(singular value de composition,svd)和潜在因子模型(latent factor models,lfm)。基于矩阵分解的方法能够捕捉到用户和项目之间的潜在关系,有效地解决了数据稀疏性和冷启动问题。
4、传统推荐系统的方法适用于一些简单的推荐场景,具有一定的效果。然而,它们在处理数据稀疏性、冷启动和复杂交互关系等问题上存在一定的局限性。随着深度学习和图神经网络的发展,越来越多的推荐系统开始采用这些新的方法来提升推荐质量和个性化程度。图神经网络(gcns)在学习用于推荐的用户和项目表示方面表现出色,它可以通过堆叠多层消息传递层来捕获用户-项目网络上的高阶关系。例如,lightgcn采用简化的gnns嵌入层来学习用户-物品网络上的用户和物品嵌入,以提高效率。dccf学习全局解纠缠的用户表示,提取基于gnn协同过滤模型的细粒度潜在因素。dgsr使用动态gnn学习具有偏好的节点的交互行为以进行顺序推荐。然而,这些方法没有考虑推荐网络中用户-物品交互的不同重要性,即忽略了用户-物品网络上的注意机制。平均聚合来自所有用户-项目交互的特征信息很容易导致不准确的节点表示,从而对推荐性能产生负面影响。特别是gnn中的多跳消息传递层会严重恶化这一效果。
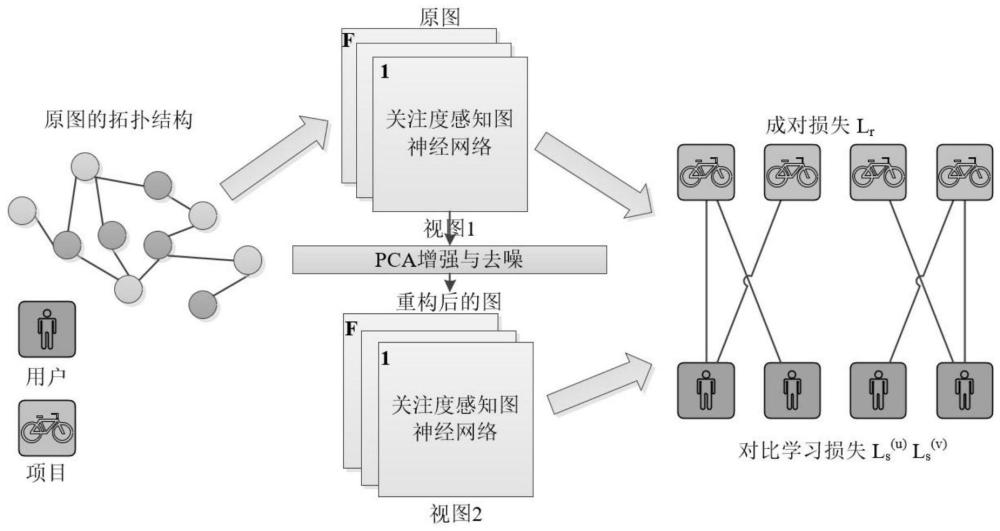
5、大多数基于gnns的推荐模型需要足够的高质量标记数据来进行监督模型训练。然而,当从非常有限的交互数据中学习节点表示时,许多现实世界的推荐场景都存在数据稀疏性问题。对比学习(cl)是一种自监督学习范式(ssl),它解决了数据增广的标签稀缺性问题。对比学习的目的是通过对比已定义的正面对和反面实例对,通过创建的对比视图之间的一致性来增广节点表示。例如,yu等人加入均匀噪声构建对比视图进行推荐。hccf使用本地和全局协作关系进行推荐,生成一种新的自监督视图增广交叉视图。最近,ccfcrec创建了内容协同过滤(cf)视图和共现cf视图来生成节点嵌入,用于冷启动项目推荐。然而,上述方法主要基于启发式对比视图生成器,限制了模型的通用性。ncl将具有图结构和语义空间的节点邻居组合成对比对。cvaes提出了一种带有对比学习损失函数的解纠缠条件变分自编码器,用于可解释的推荐。idcl使用意向对比学习构建了一个解纠缠图对比学习框架,用于意向感知推荐。然而,这些方法主要依赖于随机扰动的图增广,这可能会丢失有用的结构信息,从而影响学习到的表示的质量。此外,上述方法没有考虑重构视图的数据噪声。在现实场景中,由于对热门内容的过度推荐,用户经常会点击不相关的内容,从而导致通过数据增广从原始图中获得的重构视图存在噪声。这就限制了对比学习的适用性。最近,shi利用自监督超图转换器框架挖掘全局协作关系来增广用户表示,从而去噪用户-项目交互。adagcl利用两个可训练的视图生成器进行数据增广,以缓解推荐中的数据稀疏性和噪声。然而,这两种方法都忽略了直接利用原始图的拓扑关系来缓解重构图的噪声,这可能会增加额外的计算,并且无法准确地学习用户兴趣,导致推荐不准确。
技术实现思路
1、本发明的目的在于针对上述现有技术的不足,提供一种项目推荐方法、系统与计算机设备,以解决现有技术中忽略了直接利用原始图的拓扑关系来缓解重构图的噪声,这可能会增加额外的计算,并且无法准确地学习用户兴趣,导致推荐不准确的问题。
2、本发明具体提供如下技术方案:一种项目推荐方法,包括如下步骤:
3、获取用户-项目交互图g=(u,v,y);其中u、v、y分别为用户集合、项目集合以及用户和项目交互矩阵;
4、计算用户节点随机游走到一个项目节点的次数,将所述次数作为两个节点的相似度,并通过所述相似度构建关注度感知矩阵s;所述用户节点为用户集合中每个用户id,项目节点为项目集合中的每个项目id;
5、通过所述关注度感知矩阵s进行关注度感知节点特征聚合,构建关注度感知模型;
6、采用主成分分析法提取所述用户-项目交互图的全局协作上下文信息,并将所述全局协作上下文信息注入对比学习的表征对齐中,通过数据增广获得重构的用户-项目交互图;
7、通过所述关注度感知模型去除重构的用户-项目交互图中的噪声,并通过去除噪声的用户-项目交互图联合原始用户-物品交互图对用户进行相关项目的推荐。
8、优选的,在所述获取用户-项目交互图g=(u,v,y)后,构建一个具有关注度感知的局部图嵌入传播层对用户和节点进行嵌入,具体表达式为:
9、
10、其中,和为用户节点ui和项目节点vj在第l层的嵌入;σ(·)为leakyrel u的负斜率,具体为0.5,p(·)表示为缓解过拟合的边dropouts;l是一个具有关注度感知的拉普拉斯矩阵;e(u)∈ri×d和e(v)∈rj×d分别为用户和项目的嵌入向量矩阵;
11、其中拉普拉斯矩阵l的具体表达式为:
12、
13、其中,变量a表示用户-物品交互图的邻接矩阵,d(u)和d(v)表示用户与物品的对角度矩阵,⊙表示逐元素积,∈为控制关注度感知矩阵的贡献,s是定义用户-物品交互相似度的关注度感知矩阵;并通过去平均运算计算具有关注度感知的拉普拉斯矩阵l的协方差矩阵l。
14、优选的,所述计算用户节点随机游走到一个项目节点的次数,将所述次数作为两个节点的相似度,并通过所述相似度构建关注度感知矩阵s,具体表达式为:
15、s(u,v)=|wm,r(u→v)|+|wm,r(v→u)|
16、其中,s(u,v)表示使用带重启的随机游走节点u游走到节点v的次数,m表示采样路径的长度,r表示采样次数,|wm,r(u→v)表示通过mr步游走起始节点u经过节点v的次数,|wm,r(v→u)|表示通过mr步游走起始节点v经过节点u的次数,并采用残差连接保留原有的节点信息。
17、优选的,采用残差连接保留原有的节点信息,具体表达式为:
18、
19、对用户节点ui和项目节点vj的最终嵌入的内积来表示ui对vj的偏好,具体表达式为:
20、
21、其中,和分别表示通过残差连接后用户ui和项目vj在第l层的嵌入,表示用户节点ui的总嵌入,表示项目节点vj的总嵌入,yi,j表示ui对vj的偏好。
22、优选的,所述通过去平均运算计算具有关注度感知的拉普拉斯矩阵l的协方差矩阵l,包括如下步骤:
23、利用奇异值分解计算所述协方差矩阵l的特征值和特征向量,具体表达式为:
24、l=u∑vt
25、其中,u是一个i×i标准正交矩阵,v是一个j×j标准正交矩阵,∑存储l的奇异值,是一个维数为i×j的对角矩阵,矩阵∑的主成分对应于最大的奇异值;
26、通过截断奇异值列表来保留最大的k值来重建协方差矩阵l,具体表达式为:
27、
28、其中,uk为i×k标准正交矩阵,vk为j×k标准正交矩阵,∑存储了l的最大奇异值k,是一个维度为k×k的对角矩阵,uk,∑k和vk的近似版本和是矩阵l的低秩近似重构矩阵,表示图的主成分,并通过考虑用户-项目交互来保持全局协作信息。
29、优选的,所述通过所述关注度感知模型去除重构的用户-项目交互图中的噪声,包括如下步骤:
30、获取去噪的拉普拉斯矩阵,具体表达式为:
31、
32、其中,⊙表示元素积,为去噪后的拉普拉斯矩阵,用最少的假设缓解噪声边中的惩罚s中非零条目的数量;
33、使用random(·)从每一行s中随机选择一个零项来惩罚矩阵中相应的项,在重构的用户-物品交互图上构造一个图嵌入传播层来嵌入用户和项目,具体表达式为:
34、
35、其中,为图嵌入传播层进行用户节点的嵌入,为图嵌入传播层进行项目节点的嵌入。
36、优选的,所述构建关注度感知模型后,需对所述关注度感知模型的参数进行训练,包括如下步骤:
37、利用infonce loss对比pca增广视图嵌入与主视图嵌入,具体表达式为:
38、
39、其中,τ和s(·)分别代表温度参数和余弦相似度,为对比损失函数;
40、利用相同方式获取定义项目的infonce共同获取优化推荐的对比损失和主目标函数,具体表达式为:
41、
42、其中,θ1和θ2为控制贡献的超参数,θ为模型参数,为主目标函数;
43、对采用随机节点dropout缓解过拟合,具体表达式为:
44、
45、其中,为一对用户i的正样本的预测分数,为一对用户i的负样本的预测分数。
46、优选的,所述用户-项目交互图g=(u,v,y)中,u={u1,...,u2,...,ui},|u|=i定义了用户集合,v={v1,...,v2,...,vj},|v|=j定义了项目集合,i和j表示用户和项目的数量,y为用户和项目交互矩阵,并且y=[yi,j]i×j∈{0,1}表示用户ui和vj之间的交互,如果yi,j=1,则用户ui和vj之间存在交互,若yi,j=0,则无交互。
47、优选的,本发明还提供一种项目推荐系统,包括:
48、数据获取模块,用于获取用户-项目交互图g=(u,v,y);其中u、v、y分别为用户集合、项目集合以及用户和项目交互矩阵;
49、关注度感知矩阵获取模块,用于计算用户节点随机游走到一个项目节点的次数,将所述次数作为两个节点的相似度,并通过所述相似度构建关注度感知矩阵s;所述用户节点为用户集合中每个用户id,项目节点为项目集合中的每个项目id;
50、模型构建模块,用于通过所述关注度感知矩阵s进行关注度感知节点特征聚合,构建关注度感知模型;
51、重构模块,用于采用主成分分析法提取所述用户-项目交互图的全局协作上下文信息,并将所述全局协作上下文信息注入对比学习的表征对齐中,通过数据增广获得重构的用户-项目交互图;
52、去噪模块,用于通过所述关注度感知模型去除重构的用户-项目交互图中的噪声,并通过去除噪声的用户-项目交互图联合原始用户-项目交互图对用户进行相关项目的推荐。
53、优选的,本发明提供一种计算机设备,包括存储器及处理器,所述存储器中储存有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行所述的一种项目推荐方法的步骤。
54、与现有技术相比,本发明具有如下显著优点:
55、本发明通过两个节点的相似度构建关注度感知矩阵,通过关注度感知机制来学习节点间的重要性,从而提取局部图依赖关系。相较于其他基于自注意力机制的方法,本发明的方法时间复杂度更低,同时具有较强的可解释性。同时采用主成分分析提取图的全局协作上下文信息,并利用关注度感知矩阵来减小重构图中噪声,相较于使用随机扰动的图增广的方法,本发明的方法能够避免由于随机增广而造成的额外噪声,进而提升对比视图的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!