一种摄像头监控图像用的实时目标检测方法与流程
本发明涉及目标检测领域,具体来说,涉及一种摄像头监控图像用的实时目标检测方法。
背景技术:
1、在摄像头监控目标检测领域,高分辨率图像的小目标检测一直是摄像头监控目标检测中的一个难点。由于高清摄像头的普及,监控摄像头图像分辨率远大于主流目标检测输入分辨率。如常见监控摄像头像素和图像常见宽高为:200万像素(图像宽1920像素、高1080像素),400万像素(图像宽2560像素、高1440像素),800万像素(图像宽3840像素、高2160像素)。常见的主流目标检测模型及输入尺寸为:ssd默认输入宽300像素高300像素,9万像素;faster r-cnn默认输入图像宽600像素高600像素,36万像素;yolo默认输入图像宽640像素高640像素,约41万像素。这些主流目标检测模型输入尺寸均小于200万像素的监控摄像头图像尺寸,直接拿目标检测模型对原始尺寸的监控图像进行训练或推理,模型会按照长宽比例自动压缩图像至默认输入尺寸,由于小目标通常具有较小的尺寸和较低的分辨率,这使得小目标的特征表示不够充分,压缩图像会导致小目标丢失高比例像素,使得模型无法获取小目标的有效特征进行训练或推理。
2、为解决上述问题,传统处理方法通常采用滑动窗口裁剪方法将原图分割成多个与目标检测算法标准输入相同大小的子图,对子图逐一检测并返回原图,以达到目标检测预期效果。但带来的问题的是检测速度大幅度降低,无法够满足实时性要求,实际应用效果差。
3、yolov8是一个先进的yolov8目标检测模型,通用的yolov8目标检测模型由backbone(主干网络)、neck(颈部层)、head(头部层)组成,其中,主干网络有9层,颈部层有2层,头部层有p3、p4、p5三个输出层。通用的yolov8目标检测模型识别小目标特别是高分辨率图像中的小目标效果不佳。
4、不同的监控场景可能具有不同的光照条件、背景环境和目标特征,现有的目标检测算法往往难以适应这些变化,导致检测结果的不准确性和不稳定性。因此模型的现场适配也是一个重要的问题,现阶段模型的现场适配,主要是通过采集现场监控视频人工抽帧标注,对模型进行迭代训练,但是这种方法成本高昂,耗费时间长。
5、故现在市场上急需能够解决现有目标检测算法在监控领域小目标检测难、模型现场适配成本高时间长的问题,并用于摄像头监控图像的实时目标检测方法。
技术实现思路
1、针对相关技术中的上述技术问题,本发明提出基于深度学习和迁移学习的一种摄像头监控图像用的实时目标检测方法,能够克服现有技术存在的上述不足。
2、为实现上述技术目的,本发明的技术方案是这样实现的:
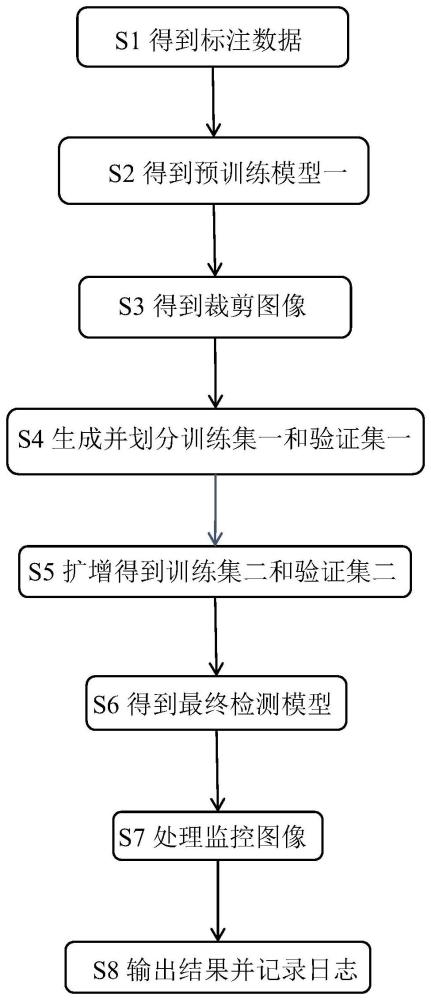
3、本发明提供一种摄像头监控图像用的实时目标检测方法,包括以下步骤:
4、s1得到标注数据:收集与现场环境相近的参照图片,使用现有的yolov8预训练模型进行推理,置信度设置为0.7~0.9,利用图像缩放技术对所述参照图片的数据集进行扩增,同步转换标签坐标,得到标注数据;
5、s2得到预训练模型一:首先修改所述yolov8模型的网络结构,然后通过s1得到的所述标注数据对所述yolov8模型进行训练,进而得到预训练模型一;
6、s3得到裁剪图像:获取现场监控视频,对所述视频抽帧,采用滑动窗口裁剪方法对所述视频的图像进行裁剪,得到裁剪图像;
7、s4生成并划分训练集一和验证集一:通过s2得到的所述预训练模型一,对s3得到的所述裁剪图像进行推理,置信度设置为0.6~0.9,得到标签化后的图像数据,将标签化处理后的所述图像数据划分为训练集一和验证集一;
8、s5扩增得到训练集二和验证集二:对s4得到的所述训练集一和所述验证集一分别通过旋转缩放进行数据扩增,同时转换对应标签坐标,得到扩增后的训练集二和验证集二;
9、s6得到最终检测模型:将s1得到的所述标注数据、s4得到的所述训练集一和所述验证集一、s5得到的所述训练集二和所述验证集二合并成最终数据集,通过所述最终数据集对s2得到的所述预训练模型一进行训练,得到最终检测模型;
10、s7处理监控图像:对从监控摄像头获取到的监控图像进行抽帧,然后采用s3中的裁剪方法拆分所述监控图像,通过s6获取的最终检测模型对裁剪后的所述监控图像进行推理,将推理结果进行合并;
11、s8输出结果并记录日志:将s7合并后的所述推理结果输出,并在服务器系统显示监控设备回传的实时推理结果,并将检测值与位置信息以日志形式记录。
12、进一步地,所述s2的具体步骤为:
13、s201:修改所述yolov8模型的网络结构;
14、s202:通过s1得到的所述标注数据对所述yolov8模型进行训练,进而得到所述预训练模型一。
15、进一步地,所述s201中,对所述yolov8模型的网络结构修改的具体过程优选为:
16、s2011:将原主干网络第7层和第8层的通道数由1024改为768,在原主干网络第8层之后,插入conv层和c2f层,得到新网络的第9层、第10层;
17、s2012:在颈部层原网络第10层之前,插入unsample层、concat层、c2f层,得到新网络的第12、13、14层;
18、s2013:在颈部层原网络第15层之后,插入unsample层、concat层、c2f层,得到新网络的第21、22、23层;
19、s2014:在头部层曾原网络第16层之前,插入conv层、concat层、c2f层,得到新网络的第24、25、26层;
20、s2015:在头部层原网络第21层之后,插入conv层、concat层、c2f层,得到新网络的第33、34、35层;
21、s2016:最后一层检测层detect,输入通道改为[23,26,29,32,35]。
22、实施时,所述yolov8模型的网络结构修改的原理为:在yolov8的基础结构上,对主干网络进行扩展,新增一个下采样层,下采样至64倍,增加网络的深度和表现力;头部层分别插入最小层和最大层,一个卷积次数较少,特征图的尺寸较大,更适合用于小目标的检测,一个卷积次数最多,特征图的尺寸较小,更适合用于大目标的检测;颈部层新增的两层,作用是将新添加的头部层与新增下采样层后的主干网络的输出进行连接。
23、进一步地,所述s2中对所述yolov8模型的网络结构修改的过程中,各所述修改网络参数以及参数含义具体为:
24、第9层:conv层,将上层输出作为本层输入,通道数为1024,卷积核大小为3*3,卷积核的步长为2;
25、第10层:c2f层,将上层输出作为本层输入,重复3次,通道数为1024,shortcut=true;
26、第12层:unsample层,上层输出作为本层输入,上采样的输出大小为输入大小的2倍,采用最近邻插值方法;
27、第13层:concat层,将上层和第8层的输出作为本层的输入,拼接的维度为1;
28、第14层:c2f层,将上层输出作为本层输入,重复3次,通道数为768;
29、第21层:unsample层,上层输出作为本层输入,上采样的输出大小为输入大小的2倍,采用最近邻插值方法;
30、第22层:concat层,将上层和第2层的输出作为本层的输入,拼接的维度为1;
31、第23层:c2f层,将上层输出作为本层输入,重复3次,通道数为128;
32、第24层:conv层,将上层输出作为本层输入,通道数为128,卷积核大小为3*3,卷积核的步长为2;
33、第25层:concat层,将上层和第20层的输出作为本层的输入,拼接的维度为1;
34、第26层:c2f层,将上层输出作为本层输入,重复3次,通道数为256;
35、第33层:conv层,将上层输出作为本层输入,通道数为768,卷积核大小为3*3,卷积核的步长为2;
36、第34层:concat层,将上层和第11层的输出作为本层的输入,拼接的维度为1;
37、第35层:c2f层,将上层输出作为本层输入,重复3次,通道数为256。
38、进一步地,所述s3的具体步骤为:
39、s301:获取现场监控的所述视频,对所述视频进行抽帧;
40、s302:采用所述滑动窗口裁剪方法对所述视频的图像裁剪,得到所述裁剪图像。
41、进一步地,所述s302中,采用所述滑动窗口裁剪方法对所述图像进行裁剪的具体过程优选为:
42、s3021确定相关参数:针对所述图像采用像素坐标系,所述图像宽w、高h、短边为wmin,检测网络标准输入大小isize,裁剪图像尺寸系数为n,裁剪图像最大系数为n,裁剪起始坐标(左上角)(xnl,ynl),在x和y方向上的裁剪系数为knx,kny,滑动窗口裁剪步长为xstepsize,w为裁剪窗口尺寸;
43、s3022确定裁剪系数:在所述像素坐标系中,在x和y方向上的裁剪系数knx,kny的计算公式分别为
44、
45、
46、其中,符号表示向上取整;
47、表示宽为w的所述图像,裁剪成宽为n倍isize大小的图片在x方向上能裁多少个,采用向上取整;
48、表示高为h的所述图像,裁剪成高为n倍isize大小的图片在x方向上能裁多少个,采用向上取整;实施时,采用向上取整可以充分利用所述图像的数据;
49、s3023确定裁剪最大系数:所述图像的裁剪最大系数n的计算公式为:
50、
51、其中,符号表示向上取整,符号"min"表示取最小值,表示当裁剪成检测网络标准输入大小isize时,图像的宽度w可以裁几次;表示当裁剪成检测网络标准输入大小isize时,图像的高度度h可以裁几次;实施时,为充分利用图像数据,采用向上取整,由于检测网络标准输入大小为正方形,裁剪图像应以窄边为准,所以二者取最小值。
52、s3024计算图像短边:所述图像短边
53、wmin=min(w,h);
54、其中,符号"min"表示取最小值,表示获取输入图像的最短边;
55、s3025计算滑动窗口裁剪步长:
56、其中,裁剪图像尺寸系数为n=1时,裁剪步长采用检测网络标准输入大小isize,当1<n≤n时,裁剪步长为nisize/2,nisize/2表示裁剪尺寸nisize的一半;
57、s3026计算裁剪窗口尺寸w:
58、
59、其中,当1≤n<n时,裁剪窗口尺寸w取nisize;当n取裁剪图像最大系数n时,裁剪窗口尺寸w取图像短边wmin。
60、s3027确定最后一次裁剪的起始坐标(xnl-1、ynl-1):
61、xnl-1=max((w-w),0);
62、ynl-1=max((h-w),0);
63、其中,符号"max"表示取最大值;max((w-w),0)、max((h-w),0)表示当裁剪窗口尺寸w大于图像的宽w或高h时,裁剪的起始坐标x方向为0或y方向为0;实施时,裁剪起始坐标xnl-1、ynl-1意义为,宽高方向最后一次裁剪时,剩余图像尺寸不足一个裁剪窗口尺寸w时,常规做法为补边,本发明采用以图像宽高为终点,w-w,h-w倒推出裁剪起始位置,此裁剪操作优于常规方法,既免于补边操作,又能充分利用图像信息。
64、s3028在x方向上裁剪起始坐标xnl坐标的集合a:
65、a={xnl∈z|knx-1≥xnl≥0}×xstepsize∪{xnl-1}
66、其中,符号"z"表示整数集,"∈"表示属于,"|"表示满足,"×"表示乘法,"≥"表示大于等于,"∪"表示集合操作中的并集;{xnl∈z|knx-1≥xnl≥0}表示从0到knx-1的一个整数集合,knx-1表示x方向最后一次裁剪不补边,留出最后单独添加;×xstepsize表示给0到knx-1的整数集合每个元素乘以一个裁剪步长xstepsize,∪{xnl-1}表示添加x方向最后一次裁剪的起始坐标xnl-1到集合a中;
67、s3029在y方向上裁剪起始坐标ynl坐标的集合b:
68、b={ynl∈z|kny-1≥ynl≥0}×xstepsize∪{ynl-1};
69、其中,符号"z"表示整数集,"∈"表示属于,"|"表示满足,"×"表示乘法,"≥"表示大于等于,"∪"表示集合操作中的并集;{ynl∈z|kny-1≥ynl≥0}表示从0到kny-1的一个整数集合,kny-1表示y方向最后一次裁剪不补边,留出最后单独添加;×xstepsize表示给0到knx-1的整数集合每个元素乘以一个裁剪步长xstepsize,∪{ynl-1}表示添加y方向最后一次裁剪的起始坐标ynl-1到集合b中;
70、s3030裁剪起始坐标的集合sl:
71、sl=a×b;
72、其中,符号"×"表示笛卡尔乘积;sl=a×b表示将x方向上裁剪起始坐标xnl坐标的集合a和y方向上裁剪起始坐标ynl坐标的集合b做笛卡尔乘积,得到裁剪起始坐标的集合sl;
73、s3031起始坐标和结束坐标的集合sn:
74、sn={(xnl,ynl,xnl+w,ynl+w)|(xnl,ynl)∈sl};
75、其中,表示通过裁剪起始坐标的集合sl中的坐标,计算出结束坐标,并将结束坐标添加到起始坐标集合sn中,得到起始坐标和结束坐标的集合sn;
76、s3032最终裁剪所有坐标的集合s:
77、
78、其中,符号表示从s1到sn取并集,n的最大值为裁剪图像最大系数n,即求从1倍检测网络标准输入大小isize到从n倍检测网络标准输入大小nisize的所有裁剪坐标点集合的并集,最终得到裁剪所有坐标的集合s,所述集合s即所述图像的裁剪坐标集合。
79、进一步地,所述s4具体包括以下步骤:
80、s401:通过s2得到的所述预训练模型一,对s3得到的所述裁剪图像进行推理;
81、s402:置信度设置为0.6~0.9,得到标签化后的图像数据;
82、s403:将标签化处理后的所述图像数据划分为所述训练集一和所述验证集一。
83、进一步地,所述s6的具体步骤为:
84、s601:将s1得到的所述标注数据、s4得到的所述训练集一和所述验证集一、s5得到的所述训练集二和所述验证集二合并成最终数据集;
85、s602:通过所述最终数据集对s2得到的所述预训练模型一进行训练,得到最终检测模型。
86、进一步地,所述s7的具体步骤为:
87、s701:对从监控摄像头获取到的所述监控图像进行抽帧;
88、s702:然后采用s3中的裁剪方法拆分所述监控图像;
89、s703:通过s6获取的所述最终检测模型对裁剪后的所述监控图像进行推理,将推理结果进行合并。
90、进一步地,所述s8的具体步骤为:
91、s701:将s7合并后的所述推理结果输出;
92、s702:并在服务器系统显示监控设备回传的实时推理结果;
93、s703:并将检测值与位置信息以日志形式记录。
94、本公开的有益效果:(a).本公开通过综合使用深度学习、迁移学习、半监督学习、数据扩增技术,解决了目标检测模型的现场适配成本高时间长的问题。
95、(b).本公开另外提出了一种新的yolov8网络的优选修改方案,以优化yolov8对高分辨图像的小目标的识别。对主干网络进行扩展,新增一个下采样层,下采样至64倍,增加网络的深度和表现力;头部层分别插入最小层和最大层,一个卷积次数较少,特征图的尺寸较大,提高小目标的检测能力,一个卷积次数最多,特征图的尺寸较小,提高大目标的检测能力。
96、(c).本公开另外提出了一种滑动窗口裁剪方法的优选方案,用于增强高分辨图像和小目标的识别,相比于传统滑动窗口裁剪方法,减少了裁剪数量,避免了裁剪特定尺寸需要补边的操作,保留了中目标和大目标的特征。传统滑动窗口裁剪方法,使用检测网络标准输入尺寸裁剪,步长为输入尺寸的一半,这种方法能提高对小目标的识别,缺点是裁剪数量多,显著提高计算量,同时由于小窗口分割了中目标和大目标,使得模型识别中目标和大目标的能力明显降低。
97、举例来说,常见的分辨率为1080p摄像头图像尺寸为1920x1080,用于yolov8模型识别,yolov8准输入尺寸为640x640,传统滑动窗口裁剪方法,会将图像裁剪成15张640x640的图,其中有7张图需要补边,这种裁剪方法会切断中大型的目标导致识别率下降;而基于本发明提出的新的滑动窗口裁剪方法,会将1920x1080图像裁剪成6张640x640、2张1080x1080的图像,不需要补边,相比传统滑动窗口裁剪方法节约28%前处理、后处理、模型推理时间,同时保留了中大型目标的识别精度。
- 还没有人留言评论。精彩留言会获得点赞!