一种基于多尺度扩散模型的遮挡行人重识别方法
本发明涉及图像处理,具体是一种基于多尺度扩散模型的遮挡行人重识别方法。
背景技术:
1、行人重识别技术利用计算机视觉技术判断监控网络中非重叠多摄像头拍摄的视频序列或图像库中是否存在特定行人,可以有效实现跨摄像头寻找同一个人的目的,但在密集场景中,被遮挡者的外观会随着遮挡物体的不同而发生显著变化,遮挡位置和遮挡区域的大小会干扰行人重识别模型对鲁棒和细粒度行人特征的理解和推断。此外,如果遮挡区域包含与身份相关的信息,而非遮挡区域包含与其他行人相似的外观特征,则往往导致匹配错误。
2、行人重识别技术通常包含三个环节:特征提取、相似度量和特征匹配。首先利用行人特征表示方法提取行人图像的视觉特征;然后采用相似性度量方法对提取到的行人图像视觉特征进行训练;最后将待检索的行人图像视觉特征与其他行人图像视觉特征进行相似度排序,找到与其相似度高的行人图像。
3、目前,基于深度学习的行人重识别方法能够自动学习很好的视觉特征和最优的相似性度量,但是,由于行人在不同的角度和距离拍摄,其图像通常存在非对齐、遮挡、姿态变化等问题,现有基于深度学习的行人重识别主要有三类方法解决上述问题:基于手工拆分的遮挡行人重识别,基于语义学习的遮挡行人重识别和基于注意力机制的遮挡行人重识别,均存在着一定的问题。
4、基于手工拆分的遮挡行人重识别方法将行人图像或全局特征图手动分割为若干个块或条状。由于该类方法对手动拆分过程有严格要求,而人类对裁剪样本的偏见会导致行人局部特征对齐困难,因此在现实情况下手动裁剪所有遮挡图像是不现实的。
5、基于语义学习的遮挡行人重识别方法匹配具有相同语义的行人局部身体区域(如头部、手臂和腿部),从而缓解空间错位问题。基于语义学习的遮挡行人重识别方法不使用手动裁剪,因此能够有效地避免识别效率低下和偏差问题,同时有助于通过外部线索(如人类解析或姿态估计器的辅助)以较高的置信度进行区分性特征提取,但遮挡行人重识别模型在训练样本的过程中受到巨大的偏向性线索误差,使得识别精度急剧下降。
6、受注意力机制启发的基于注意力机制的遮挡行人重识别解决方案直接关注于不受遮挡的行人身体部件,放弃语义划分得到的身体部件线索,从而降低了模型的复杂度。基于注意力机制的遮挡行人重识别方法预测得到的注意力图包含可见和具有判别性的区域,同时能够减少遮挡信息的不利影响。但对于网络模型学习的视觉注意力,需要设计一种有效的机制来分析和增强其有效性,从而能够学习更有用的注意力图用于细粒度识别。
7、此外,在实际的视频监控环境中,由于复杂背景和异物遮挡等应用环境的复杂性,由于遮挡图像不仅丢失部分目标信息,还引入了额外的干扰因素,导致现有方法难以准确学到特征表示和识别目标。
技术实现思路
1、本发明的目的在于解决现有技术中存在的问题,提供一种基于多尺度扩散模型的遮挡行人重识别方法,可以有效解决复杂环境下遮挡行人重识别的瓶颈问题,即遮挡样本少且基于数据增强的随机遮挡方式用于模拟真实场景下遮挡能力有限的问题,上述问题不利于模型学习高效、鲁棒的特征表示和度量准则,且对于遮挡场景下识别行人能力差。
2、本发明为实现上述目的,通过以下技术方案实现:
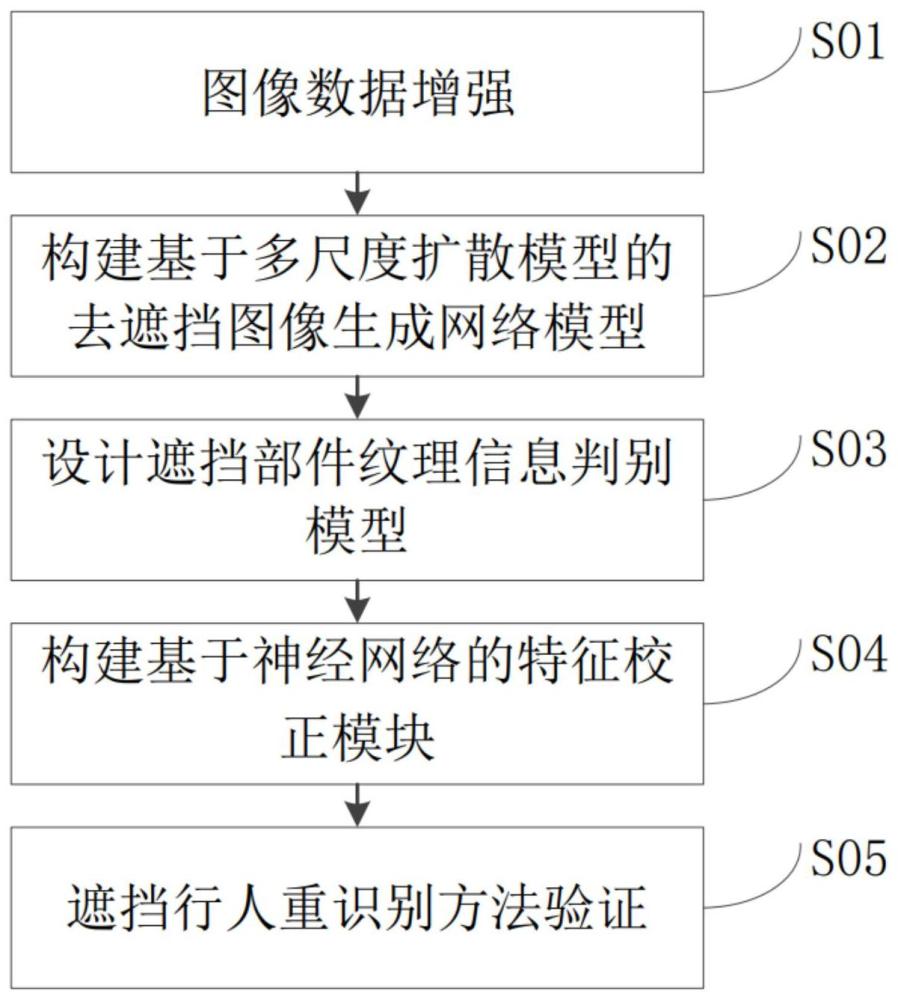
3、一种基于多尺度扩散模型的遮挡行人重识别方法,包括步骤:
4、s01、对训练行人图像进行图像数据增强,得到训练样本;
5、s02、构建基于多尺度扩散模型的去遮挡图像生成网络模型,通过去遮挡图像生成网络模型对输入的遮挡图像进行遮挡区域信息恢复,并能够生成高质量的无遮挡图像;
6、s03、构建遮挡部件纹理信息判别模型,遮挡部件纹理信息判别模型包括局部判别网络、全局判别网络,局部判别网络用于遮挡区域的纹理信息判别,全局判别网络用于判断全局一致性;
7、s04、构建基于神经网络的特征校正模块,通过使用神经网络来学习特征空间偏移量以调整卷积核中每个采样位置,将特征映射与一组参考特征映射对齐;
8、s05、验证提出的遮挡行人重识别方法的有效性,对生成遮挡行人图像构成的数据集进行遮挡行人重识别方法验证。
9、优选的,所述步骤s01具体包括:对原始训练集中的每一张原始图像进行随机遮挡区域生成和遮挡颜色生成;把原始图像和添加遮挡的图像设置成深度神经网络设定的输入尺寸,作为对原始训练集数据增强后的训练集。
10、优选的,所述步骤s01中,对于未遮挡的图像i随机添加遮挡,获得含有随机遮挡的训练图像i′,对原始图像i进行归一化为256×128像素,添加遮挡的图像分别归一化为大尺度遮挡图像i′l,大尺度遮挡图像的像素为256×128,小尺度遮挡图像t′s,小尺度遮挡图像的像素为128×64。
11、优选的,所述步骤s02中,构建基于多尺度扩散模型的去遮挡图像生成网络模型包括步骤:
12、s21、采用小尺度编码器对小尺度的遮挡图像进行特征编码;
13、s22、采用大尺度编码器对大尺度的遮挡图像进行特征编码;
14、s23、图像解码器将融合的特征生成大尺度无遮挡图像。
15、优选的,步骤s21-s23中,所述小尺度编码器es、大尺度编码器el和图像解码器d构成多尺度扩散模型dm,小尺度编码器es将小尺度遮挡图像i′s编码为小尺度特征,大尺度编码器el将大尺度遮挡图像i′l编码的特征与小尺度特征进行融合编码成具有n个尺度的隐变量z=el(es(i′s),i′l)={z1:n},其中,es(·)表示小尺度编码器es的编码映射函数,el(·)表示大尺度编码器el的编码映射函数;
16、在扩散过程中,从低层隐变量z1到高层隐变量zn分别顺序地添加噪声,且每个尺度的隐变量执行t次;
17、在去噪过程中,通过图像解码器还原出原图i的分布,其中,d(·)表示图像解码器d的重构映射变化函数,是生成的无遮挡行人图像;
18、为了有效保留生成样本的细节信息,按照下面的损失函数训练基于多尺度扩散模型的去遮挡图像生成网络模型:
19、
20、其中,表示生成的无遮挡行人图像;i表示原始未遮挡行人图像;
21、定义原未遮挡行人图像i与生成无遮挡行人图像之间的像素级重构损失函数;
22、||·||2表示二范数。
23、优选的,所述步骤s03中,遮挡部件纹理信息判别模型包括一个局部判别网络dl和一个全局判别网络dg,满足:
24、
25、
26、其中,m是对应于被丢弃区域的二进制掩码,在像素被丢弃的位置值设为1,否则设为0;表示数学期望;⊙表示两个矩阵对应元素相乘符号;ll表示的是局部对抗损失;lg反映整张图像真实性的全局对抗性损失;m⊙i是未遮挡行人图像i添加随机遮挡区域m后的遮挡图像i′;dl(m⊙i)表示局部判别器dl对遮挡图像i′的判别结果;表示局部判别器dl对生成无遮挡行人图像添加随机遮挡区域m后的判别结果;dg(i)表示全局判别器dg对未遮挡行人图像i的判别结果;dg(i)表示全局判别器dg对生成无遮挡行人图像的判别结果。
27、优选的,所述步骤s04中,基于神经网络的特征校正模块是一个特征对齐网络,该网络学习一个空间位置信息由二维特征图oi∈r2×h×w表示,其中每一个偏移值被视为第i层输出特征图fi+1∈rc×h×w中每个像素点(xi+1,yi+1)与输入特征图fi中每个像素点(xi,yi)之间的偏移距离,特征对齐操作可以表示为:
28、δoi=foffset([fi,fi+1])
29、
30、其中,是fi+1对齐fi后的特征;falign表示要学习空间偏移量δoi的卷积层;foffset表示使用δoi对齐特征的可变性卷积层;[·,·]表示拼接两个特征图的操作。
31、优选的,所述步骤s05中,采用传统和公开数据集对生成的未遮挡行人图像构成的数据集进行遮挡行人重识别验证。
32、对比现有技术,本发明的有益效果在于:
33、本发明利用成对的遮挡图像和非遮挡图像训练一个多尺度扩散模型、局部判别网络和全局判别网络,多尺度扩散模型对随机遮挡区域进行去遮挡操作,生成高质量的重构图,判别网络能够区分输入图像是真实图像还是生成图像。解决了已有的行人重识别方法在识别过程中忽略了特征不对齐问题,通过构建基于神经网络的特征校正模块来提升遮挡行人重识别方法的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!