基于增量深度子空间网络的实时微表情识别方法及装置与流程
本发明属于计算机科学与,尤其是涉及基于增量深度子空间网络的实时微表情识别方法及装置。
背景技术:
1、微表情在理解非语言交际和识破欺骗方面扮演着重要角色。它指的是个体在试图掩饰某些事实时,不自觉地展现出的短暂面部运动。由于微表情的振幅较小,且持续时间短暂(通常在1/15到1/25秒之间),因此对其进行自动分析具有一定挑战性。微表情发现与分析技术的研究在国家安全、司法审讯、医学临床等多个领域的发展具有深远的学术价值。其能够提升谎言检测的准确性,更精准地揭示隐藏在人们面部微小的肌肉变化中的真实情感,从而在判断陈述的真实性上提供更可靠的依据。
2、近些年来,随着计算机视觉和机器学习技术的发展,微表情识别得到了广泛的关注和研究,许多研究人员开始使用计算机视觉技术进行自动表情识别,大大提高了微表情应用的可行性。卷积神经网络作为深度学习的经典技术之一,开始被广泛应用于提取具有判别性的微表情特征。虽然实现了较高的识别准确率,但都需要大量的可训练参数,样本量极大地限制了深度学习模型在微表情识别任务上的性能,暴露出过拟合、参数量大、计算成本高等问题。同时,在训练模型的时候,还需要考虑正则化参数和选择数值优化器,根据数据不断调整参数,这也是一个繁琐的过程。
3、综上所述,现有技术存在的问题及不足有:
4、1.微表情识别任务中,现有的基于深度卷积神经网络的方法存在训练收敛速度慢、计算资源占用高等问题,并且,由于微表情识别的数据集规模相对较小,缺乏多样性,这限制了cnn在真实世界中的泛化能力,使得模型可能过拟合于特定的数据集,难以适应不同的环境和情境。
5、2.在有效提取微表情特征中,现有的采用传统特征算子方法与卷积神经网络相结合的微表情识别方法在训练速度及识别精度上仍然效果不佳。
6、3.微表情通常是短暂而快速的,传统的卷积神经网络在处理长时序信息上存在一定的困难。这可能导致模型难以捕捉到微表情的时序变化,影响识别的准确性。
技术实现思路
1、有鉴于此,本发明旨在克服现有技术中上述问题的不足之处,提出基于增量深度子空间网络的实时微表情识别方法及装置,通过光流捕获面部运动特征,然后将光流特征输入到增量行列二维核主成分分析网络(irc2dkpcanet)中进一步学习更深层次的时空特征,最后用线性支持向量机(svm)进行情感分类。
2、为达到上述目的,本发明的技术方案是这样实现的:
3、本发明第一方面提供了基于增量深度子空间网络的实时微表情识别方法,包括如下步骤:
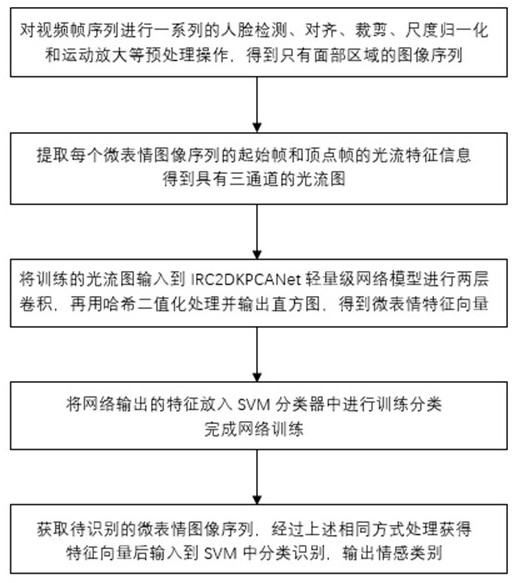
4、步骤1:获取微表情视频训练数据集,对微表情视频训练数据集中的视频帧序列进行预处理操作,得到只有面部区域的图像序列;
5、步骤2:对于步骤1得到的图像序列,提取每个微表情图像序列的起始帧和顶点帧的光流特征信息,得到具有三通道的微表情光流特征图像;
6、步骤3:构建irc2dkpcanet轻量级网络模型,irc2dkpcanet轻量级网络模型包括依次连接的第一层特征提取模块、第二层特征提取模块以及输出层,所述第一层特征提取模块使用卷积核提取光流特征的纹理信息,所述第二层特征提取模块使用卷积核提取光流特征的边缘特征,所述输出层采用哈希二值化和直方图输出得到面部微表情特征的向量表示,将步骤2得到的所有微表情视频训练数据集中的微表情光流特征图像输入至irc2dkpcanet轻量级网络模型得到微表情的特征向量,将得到的微表情的特征向量及对应的情感类别标签输入svm分类器中进行训练,完成irc2dkpcanet轻量级网络模型的训练,得到训练好的irc2dkpcanet轻量级网络模型;
7、步骤4:获取待识别的微表情图像序列,进行预处理得到具有三通道的微表情光流特征图像,并输入至irc2dkpcanet轻量级网络模型中得到微表情的特征向量后,输入至svm中进行分类识别,输出情感类别。
8、进一步的,所述步骤1中,预处理操作包括面部关键点检测、面部对齐和裁剪、尺度归一化、以及面部运动放大处理。
9、进一步的,所述irc2dkpcanet轻量级网络模型中,将步骤2得到的所有微表情视频训练数据集中的n幅微表情光流特征图像输入至第一层特征提取模块进行初始核主成分分析,分别提取出样本行方向与列方向的特征向量后,同阶特征向量相乘,生成l1个滤波器,利用滤波器与原始训练图像分别进行卷积,原始训练图像中的每一幅图像生成l1幅图像,共生成nl1幅图像,作为第二层特征提取模块的输入,将这些输入按照第一层特征提取模块的方式进行重排,分别迭代提取行、列方向特征向量后,得到第二层特征提取模块的滤波器,生成新的滤波器共l2个,并利用新生成的滤波器对nl1幅图像进行卷积,共生成nl1l2幅图像,第一层特征提取模块生成的所有l1幅图像中,对其中每一幅图像生成的l2幅图像进行二进制哈希处理,然后合并成一幅图像,对哈希处理后的所有nl1幅图像进行取块处理,并统计每个块的直方图,将同一幅图像中所有块的直方图进行串联,得到最终的矩阵特征向量作为微表情图像最终的特征向量。
10、进一步的,还包括对于新输入的待识别的面部光流特征图像,在输入至irc2dkpcanet轻量级网络模型中时,根据下面的计算公式逐步更新中心化核矩阵,生成新的滤波器,得到更新后的样本的特征值和特征向量;
11、;
12、其中,是更新后的核矩阵,1是全1列向量,为更新后的样本均值,计算方法如下:,
13、其中,表示更新前的样本均值,xn表示第n个原有样本,n表示原始样本数,k(xnew,xn)计算新样本与第n个原始样本的核函数值。
14、本发明第二方面提供了基于增量深度子空间网络的实时微表情识别装置,包括:
15、预处理模块,用于获取微表情视频训练数据集,对微表情视频训练数据集中的视频帧序列进行预处理操作,得到只有面部区域的图像序列;
16、光流特征图像获取模块,用于对于预处理模块得到的图像序列,提取每个微表情图像序列的起始帧和顶点帧的光流特征信息,得到具有三通道的微表情光流特征图像;
17、模型构建模块,用于构建irc2dkpcanet轻量级网络模型,irc2dkpcanet轻量级网络模型包括依次连接的第一层特征提取模块、第二层特征提取模块以及输出层,所述第一层特征提取模块使用卷积核提取光流特征的纹理信息,所述第二层特征提取模块使用卷积核提取光流特征的边缘特征,所述输出层采用哈希二值化和直方图输出得到面部微表情特征的向量表示,将光流特征图像获取模块得到的所有微表情视频训练数据集中的微表情光流特征图像输入至irc2dkpcanet轻量级网络模型得到微表情的特征向量,将得到的微表情的特征向量及对应的情感类别标签输入svm分类器中进行训练,完成irc2dkpcanet轻量级网络模型的训练,得到训练好的irc2dkpcanet轻量级网络模型;
18、识别模块,用于获取待识别的微表情图像序列,进行预处理得到具有三通道的微表情光流特征图像,并输入至irc2dkpcanet轻量级网络模型中得到微表情的特征向量后,输入至svm中进行分类识别,输出情感类别。
19、本发明第三方面提供了一种电子设备,包括处理器以及与处理器通信连接,且用于存储所述处理器可执行指令的存储器,所述处理器用于执行上述基于增量深度子空间网络的实时微表情识别方法。
20、本发明第四方面提供了一种计算机可读取存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述的基于增量深度子空间网络的实时微表情识别方法。
21、相对于现有技术,本发明所述的基于增量深度子空间网络的实时微表情识别方法及装置具有以下优势:
22、1、本发明的irc2dkpca网络可以从高维数据中提取出有效的特征,用于微表情的识别,通过核技巧,将非线性数据映射到高维特征空间,从而更好地捕捉微表情中的信息,实现了高效的特征提取。
23、2、本发明的irc2dkpca网络采用增量的处理方式,具有适应性强的特点,可以自动适应新的样本和数据。这意味着在实际应用中,可以根据不断变化的数据进行在线学习和更新,而不需要重新训练整个模型,具有更好的实时性和响应性。
24、3、本发明的增量处理方式只需要对新的样本进行计算和更新,而不需要重新计算整个数据集。这可以大大减少计算资源的消耗,提高了系统的效率。
- 还没有人留言评论。精彩留言会获得点赞!