针对大语言模型融合算子的图编译方法、装置及存储介质
本公开涉及人工智能,尤其涉及一种针对大语言模型融合算子的图编译方法、装置及存储介质。
背景技术:
1、大语言模型(large language model,llm)是一种人工智能模型,专门设计用于理解和生成人类语言。大语言模型是深度学习的一个分支,通常包含数十亿甚至数百亿个参数,这些参数通过在大量文本数据上的训练来学习语言的复杂模式和结构。这种大规模的训练使得大语言模型能够执行广泛的自然语言处理任务,包括但不限于文本总结、翻译、情感分析和对话系统等。
2、和传统视觉模型相比,大语言模型在网络结构上有着算子相对单一,网络重复性高,网络模型巨大的特点。传统的人工智能(artificial intelligence,ai)编译器设计一般是为了适用于含有复杂算子的模型网络,网络中算子类别较多,且对应图连接关系也比较复杂。为了支持通用的模型,在设计上会为将算子粒度划分的非常细粒度,然而对于大语言模型来说,传统的编译器已经无法较好的完成模型编译和运行工作,且会导致网络碎片化,从而导致模型运行效率降低。相关技术中尚未提供一种针对大语言模型的高效的图编译流程。
技术实现思路
1、有鉴于此,本公开提出了一种针对大语言模型融合算子的图编译方法、装置及存储介质。
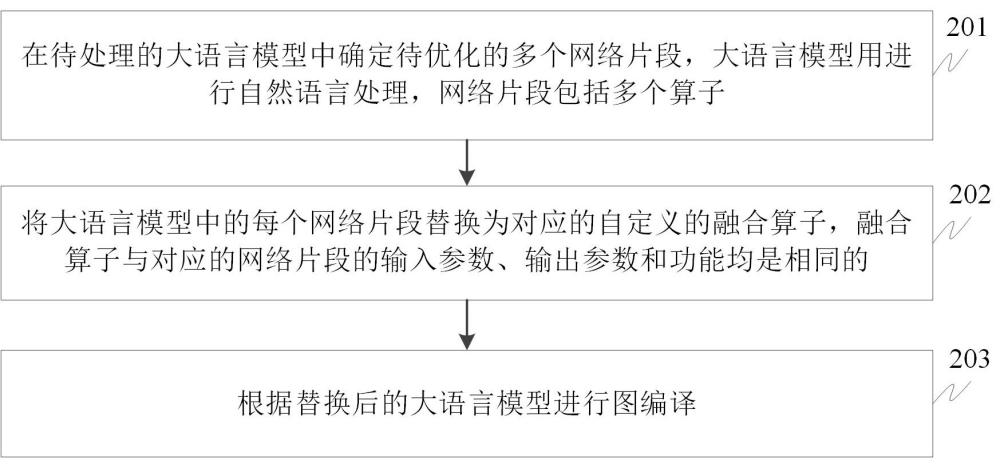
2、根据本公开的一方面,提供了一种针对大语言模型融合算子的图编译方法,所述方法包括:
3、在待处理的大语言模型中确定待优化的多个网络片段,所述大语言模型用于进行自然语言处理,所述网络片段包括多个算子;
4、将所述大语言模型中的每个所述网络片段替换为对应的自定义的融合算子,所述融合算子与对应的所述网络片段的输入参数、输出参数和功能均是相同的;
5、根据替换后的所述大语言模型进行图编译。
6、在一种可能的实现方式中,所述方法还包括:
7、获取所述大语言模型对应的自定义算子库,所述自定义算子库包括自定义的多个所述融合算子;
8、所述在待处理的大语言模型中确定待优化的多个网络片段,包括:
9、根据多个所述融合算子,在待处理的所述大语言模型中确定各自对应的所述网络片段。
10、在另一种可能的实现方式中,所述融合算子是根据不同的深度学习框架自定义的算子,所述融合算子的算子粒度大于预设阈值。
11、在另一种可能的实现方式中,所述根据替换后的所述大语言模型进行图编译,包括:
12、根据替换后的所述大语言模型生成对应的目标计算图,所述目标计算图用于指示替换后的所述大语言模型中的数据计算逻辑;
13、将所述目标计算图转化为目标中间表示,所述目标中间表示包括所述目标计算图的图结构信息,所述目标中间表示用于进行所述大语言模型的推理。
14、在另一种可能的实现方式中,所述大语言模型的推理过程包括预填充(英文:prefill)阶段和解码(英文:decode)阶段,所述预填充阶段和所述解码阶段复用所述目标中间表示;
15、其中,所述预填充阶段用于将输入的数据通过所述大语言模型处理后生成词块,所述解码阶段用于基于已生成的所述词块逐步生成词块序列。
16、在另一种可能的实现方式中,所述方法还包括:
17、根据所述目标中间表示进行所述预填充阶段的推理;
18、对所述目标中间表示的所述图结构信息进行部分修改得到修改后的所述目标中间表示;
19、根据修改后的所述目标中间表示进行所述解码阶段的推理。
20、在另一种可能的实现方式中,所述图结构信息包括多个节点的节点信息和多条边的边信息,所述节点信息包括算子表达、张量和常量属性中的至少一种,所述边信息用于指示相邻的两个所述节点之间的连接关系。
21、根据本公开的另一方面,提供了一种针对大语言模型融合算子的图编译装置,所述装置包括:
22、确定模块,用于在待处理的大语言模型中确定待优化的多个网络片段,所述大语言模型用于进行自然语言处理,所述网络片段包括多个算子;
23、替换模块,用于将所述大语言模型中的每个所述网络片段替换为对应的自定义的融合算子,所述融合算子与对应的所述网络片段的输入参数、输出参数和功能均是相同的;
24、图编译模块,用于根据替换后的所述大语言模型进行图编译。
25、在一种可能的实现方式中,所述装置还包括:
26、获取模块,用于获取所述大语言模型对应的自定义算子库,所述自定义算子库包括自定义的多个所述融合算子;
27、所述确定模块,还用于根据多个所述融合算子,在待处理的所述大语言模型中确定各自对应的所述网络片段。
28、在另一种可能的实现方式中,所述融合算子是根据不同的深度学习框架自定义的算子,所述融合算子的算子粒度大于预设阈值。
29、在另一种可能的实现方式中,所述图编译模块,还用于:
30、根据替换后的所述大语言模型生成对应的目标计算图,所述目标计算图用于指示替换后的所述大语言模型中的数据计算逻辑;
31、将所述目标计算图转化为目标中间表示,所述目标中间表示包括所述目标计算图的图结构信息,所述目标中间表示用于进行所述大语言模型的推理。
32、在另一种可能的实现方式中,所述大语言模型的推理过程包括预填充阶段和解码阶段,所述预填充阶段和所述解码阶段复用所述目标中间表示;
33、其中,所述预填充阶段用于将输入的数据通过所述大语言模型处理后生成词块,所述解码阶段用于基于已生成的所述词块逐步生成词块序列。
34、在另一种可能的实现方式中,所述装置还包括:推理模块,用于:
35、根据所述目标中间表示进行所述预填充阶段的推理;
36、对所述目标中间表示的所述图结构信息进行部分修改得到修改后的所述目标中间表示;
37、根据修改后的所述目标中间表示进行所述解码阶段的推理。
38、在另一种可能的实现方式中,所述图结构信息包括多个节点的节点信息和多条边的边信息,所述节点信息包括算子表达、张量和常量属性中的至少一种,所述边信息用于指示相邻的两个所述节点之间的连接关系。
39、根据本公开的另一方面,提供了一种计算设备,所述计算设备包括:
40、处理器;
41、用于存储处理器可执行指令的存储器;
42、其中,所述处理器被配置为在执行所述存储器存储的指令时,实现第一方面或第一方面的任意一种可能的实现方式所提供的方法。
43、根据本公开的另一方面,提供了一种非易失性计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述第一方面或第一方面的任意一种可能的实现方式所提供的方法。
44、根据本公开的另一方面,提供了一种计算机程序产品,包括计算机可读代码,或者承载有计算机可读代码的非易失性计算机可读存储介质,当所述计算机可读代码在计算设备的处理器中运行时,所述计算设备中的处理器执行上述方法。
45、本公开实施例提供了一套基于融合算子替换的大语言模型的图编译流程,通过融合算子替换来优化大型语言模型,使其在保持功能不变的同时,提高运行效率,减少计算资源的消耗,避免了采用传统的编译器无法较好的完成模型编译和运行工作的情况, 降低了不同大语言模型的差异化带来的图编译的复杂度,同时可以适用于不同的深度学习框架和底层硬件系统。
46、根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
- 还没有人留言评论。精彩留言会获得点赞!