一种基于NLP的数据收集合规识别方法与流程
本发明涉及数据分析,尤其涉及一种基于nlp的数据收集合规识别方法。
背景技术:
1、数据合规是数据管理的基本保障,对数据资产的全生命周期管理起到基础性支持作用。然而,在数据合规的判断过程中,如果依靠人工检查给定的收集数据是否符合相关法律法规,需要花费大量的时间和精力。而且目前的数据合规体系还未建立完善,对于数据管理没有健全风险识别和预警机制,难以准确掌握生产经营中的合规风险。最后,实际业务中因行业、数据应用场景的不同,而且数据合规实务的合规依据更新较快,数据合规理论研究远远滞后于数据合规实务的发展。因此,如何提供一种基于nlp的数据收集合规识别方法是本领域技术人员亟需解决的问题。
技术实现思路
1、本发明的一个目的在于提出一种基于nlp的数据收集合规识别方法,本发明解决了现有技术存在的数据合规识别准确率低、效率低以及实用性低的问题。
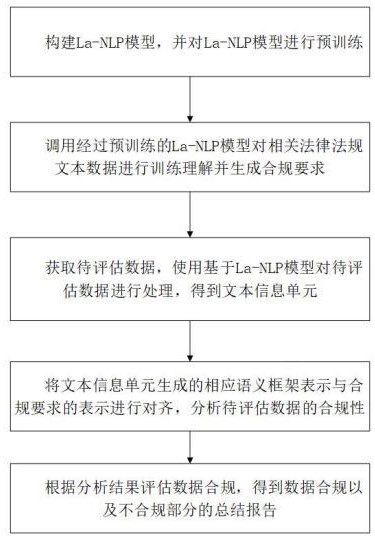
2、根据本发明实施例的一种基于nlp的数据收集合规识别方法,包括如下方法步骤:
3、s1、构建la-nlp模型,并对la-nlp模型进行预训练;
4、s2、调用经过预训练的la-nlp模型对相关法律法规文本数据进行训练理解并生成合规要求;
5、s3、获取待评估数据,使用基于la-nlp模型对待评估数据进行处理,得到文本信息单元;
6、s4、将文本信息单元生成的相应语义框架表示与合规要求的表示进行对齐,分析待评估数据的合规性;
7、s5、根据分析结果评估数据合规,得到数据合规以及不合规部分的总结报告。
8、可选的,所述la-nlp模型构建具体包括:
9、调用经过预训练的la-nlp模型对相关法律法规文本数据进行训练理解并生成规则库。在la-nlp模型中,为了解决在编码过程中的范围偏离问题,使用层次注意力机制替代传统注意力机制。具体实现是通过设计了一个注意力掩码应用到传统注意力操作上,层次注意力机制可以表示如下:
10、;
11、其中,c代表注意力掩码,代表哈达玛乘积,q代表查询,k代表键,v代表值,表示特征维度;
12、所述注意力掩码c通过计算相邻注意力分数确定,相邻注意力分数代表相邻la-nlp模型输入基本单元的范围趋势,对于任何相邻la-nlp模型输入基本单元,相邻注意力分数计算如下:
13、;
14、其中,表示查询矩阵,表示键矩阵,表示两个相邻模型输入基本单元,表示超参数作为缩放因子;
15、和重复更新,将相邻亲和分数通过计算和的归一化结果的平均值得到:
16、;
17、其中,softmax表示softmax归一化函数;
18、设定添加一个约束,约束随着网络深入,相邻亲和分数为增加趋势,第层中的亲和分数计算如下:
19、;
20、其中,表示网络的第i-1层,表示相邻亲和分数;
21、对给定输入基本单元对,注意力掩码矩阵c的元素计算如下:
22、。
23、计算得到的注意力掩码矩阵c由所有注意头共享,并逐步更新。许多在语义和空间上相似的输入基本单元逐渐合并形成不同的聚类,这些不同的聚类被视为不同条文内容的范围。
24、可选的,所述la-nlp模型使用层次注意力机制划分文本中的每个法律条文的范围,将法律条文范围和规则库之间的对齐,视为最优传输问题,利用最优传输模块进行对法律条文范围和规则库之间的相互引导。
25、可选的,所述s2具体包括:
26、最优传输问题在传输之前给定初始状态,传输后的最终状态以及单位成本函数,表示从中第 i位置到中第 j位置的单位传输成本,制定一个传输计划使总传输成本最小化,每个元素表示从传输到的量,总传输成本计算如下:
27、;
28、;
29、;
30、其中,表示初始状态 i位置,表示传输位置 j位置,表示从传输到的量,对于编码器获得的法律条文范围预测和规则库预测,利用最优传输模块度量法律条文范围预测和规则库预测之间的距离,法律条文范围预测和规则库预测的传输成本计算如下:
31、;
32、;
33、;
34、其中,表示单位成本函数,第i个法律条文范围预测,表示第j个规则预测;
35、利用余弦相似度定义单位成本函数,随着和之间的余弦相似度增加,对应的单位成本变低:
36、;
37、其中,表示和之间的余弦相似度值;
38、通过la-nlp模型对法律法规进行解析,提取出规则和要素,将规则和要素编码成一种被计算机理解的形式,并总结出规则库;
39、与法律专家合作从相关法律法规要求中提取n个合规要求,n个合规要求分为四个类别包括个元数据要求、个关于数据处理者义务的要求、个关于数据控制者权利的要求以及个关于数据控制者义务的要求,根据法律专家的反馈,四个类别有个是强制性要求,个是可选要求,根据合规要求建立人工库;
40、将规则库和人工库的合规要求进行人工合并得到完整合规要求。
41、可选的,所述规则库中包括对于法律法规中的条款,将复合语句分解为简单要求,定义为第一规则库,对于行业报告中的合规要求,定义为第二规则库。
42、可选的,所述强制性要求为有关数据控制者和处理者的身份隐私信息的关键信息,基于关键信息进行合规性检查,所述可选要求为根据法律专家的意见以及行业报告、专家学者实践中推导出的,当数据违反强制性要求时判定为不合规,在数据违反可选要求时会产生警告。
43、可选的,所述s3具体包括:
44、s31、获取待评估数据,使用la-nlp模型对输入的待评估数据进行解析和预处理;
45、s32、创建基于合规要求的语义框架为基础语义框架,用于表征合规要求中每个要求的信息内容,在待评估数据的文本部分上生成nlp注释,基础语义框架包括人物、权限和动作;
46、s33、基于基础语义框架的表示方法,自动生成输入的待评估数据生成基于语义框架的表示:
47、确定语句中的语义角色;
48、使用语义角色动作生成谓词,并使用剩余的语义角色生成论证;
49、使用la-nlp模型进行语义角色标注的结果,la-nlp模型处理语义角色标记工具为输入数据中文本内容的每个语句分解为使用与要求中相似的语义角色标记的有意义的短语。
50、s34、根据生成的语义框架的表示得到文本信息单元。
51、可选的,所述s33具体包括:
52、s331、给定语句中的语义角色,利用训练过的la-nlp模型进行注释,所述注释包括同义词理解适应文本中应用的不同措辞;
53、s332、当识别出一个语义角色,对标记分配给的文本范围进行界定,使用文本块分块产生的自然语言处理注释找到其所在的完整短语;
54、s333、输入的数据文本中的每个语句都被分割成一组短语,每组短语都有一个语义角色标签;
55、s334、短语构成对语句的基于语义框架的表示。
56、可选的,所述s4具体包括:
57、s41、使用基于合规要求和基于输入数据文本中创建的文本信息单元检查输入数据的合规性:
58、将基于合规要求的语义框架表示与输入数据文本中每个语句的语义框架表示进行对奇比较,并计算匹配程度的分数,通过将规则库的表示和文本信息单元的语义框架表示进行对比,验证数据的合规性;
59、s42、解析对齐分析结果,得到待评估数据对应的每个文本信息单元的合规属性。
60、可选的,所述s5具体包括根据分析结果来评估数据合规,生成一个数据合规以及不合规部分的详细总结报告,在输入数据文本级别上做出合规决策,在待评估数据中,如果至少有一条语句满足要求,在输入数据文本中将该要求标记为满足,否则,要求将被标记为违反,当至少一个强制要求被违反时,将视为不合规,当违反可选要求时,会有一个警告,所有的待评估数据内容都会被标记,生成总结报告。
61、本发明的有益效果是:
62、本发明考虑了在数据合规的判断过程中,人工检查给定的收集数据是否合规需要耗时费力的问题,一方面理解和识别相关法律法规的合规性要求,并在收集数据中验证这些要求。而且法律文本由于术语多、句式复杂增加了额外的复杂性,可能导致误解,因此,提出了一种自动化的解决方案来检查给定的数据是否符合相关法律法规,解决了现有技术存在的数据合规识别准确率低、效率低以及实用性低的问题。
- 还没有人留言评论。精彩留言会获得点赞!