一种基于汽车OBD数据预测某次行程百公里油耗的方法与流程
本发明属于车联网
技术领域:
,具体涉及一种基于汽车OBD数据预测某次行程百公里油耗的方法。
背景技术:
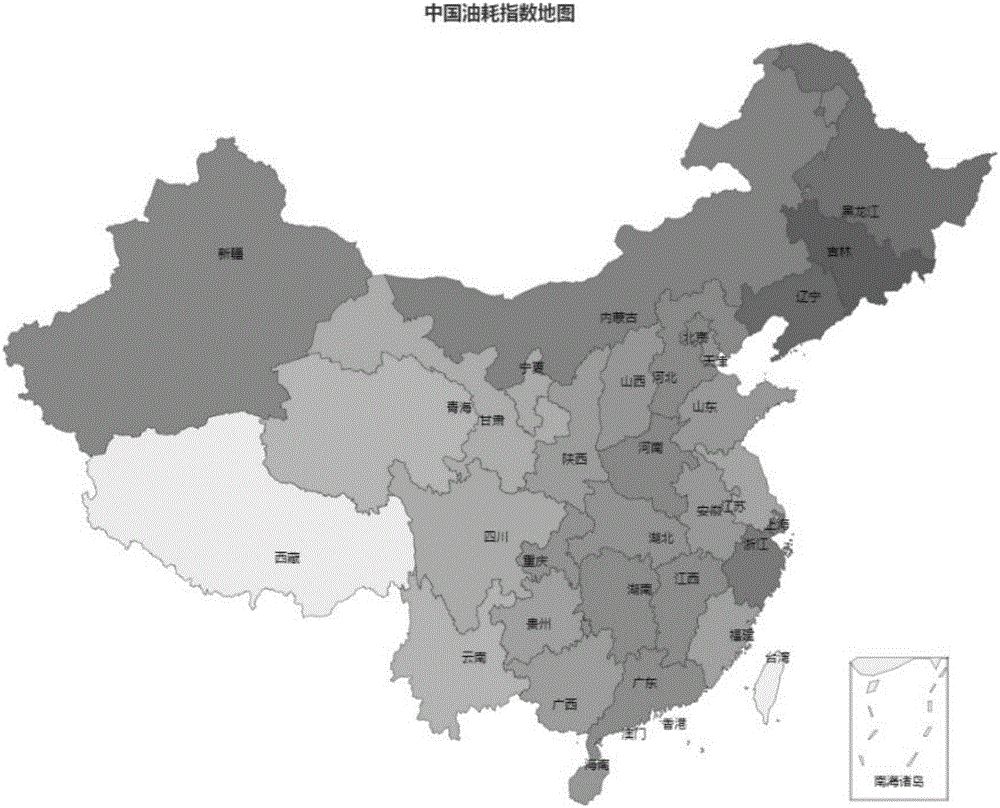
:影响百公里油耗的因素很多,例如:车型,车重,轮胎磨损情况,排量,路面拥堵情况,道路坡度,个人驾驶行为(急加速、急减速),气温环境(冬天开空调制热,夏天开空调制冷),由于周围环境的复杂多变,准确的单次行程的百公里油耗较难获得。通过汽车OBD盒子可以获得汽车在行驶中的车况数据,包括采集时间、剩余油量、里程、行程开始时间、行程结束时间,基于以上数据可以计算某段行程的百公里油耗=(行程开始剩余油量-行程结束剩余油量)*100/(行程结束里程–行程开始里程)。但这样在实际操作时,计算出来的百公里油耗存在较大误差。主要因为以下因素:1)通过OBD盒子采集上来的剩余油量本身存在偏差,且各车型传感器设计制式与精度不同,导致不同车型采集到的剩余油量偏差不一,并且车辆抖动,路面平整度也会造成较大干扰;2)假如行程较短,油量耗费少,油量变化很难测量;3)加满油时,部分车型出现超出油量量程而测不准的问题,这样就出现里程值增加,油量值未减少的现象,油量变化为零。4)采集到的里程是整数,精度不高。当行程较短时,会影响整体的计算精度。以上导致单次行程很难获得剩余油量数据变化趋势,计算出来的百公里油耗严重偏离实际值,有些甚至偏离数倍,所以仅通过OBD盒子采集到的油量与里程数据无法直接计算出真实的百公里油耗。技术实现要素:为了解决上述问题,本发明提供一种基于汽车OBD数据预测某次行程百公里油耗的方法,所述方法通过加油周期的百公里油耗数据来抽取特征建立模型,最后将此模型应用在单行程百公里油耗的预测上,最后计算出预测的单行程的百公里油耗;进一步地,所述方法包括:S1:特征数据选取与分析;S2:建立模型,使用加油周期数据训练模型;S3:使用加油周期数据验证模型;S4:使用单行程数据验证模型;进一步地,所述S1包括:S11:选取因变量,新建一个指标为油耗指数,加工油耗指数,存放基于车型归一化处理后的百公里油耗;S12:选取自变量,定义月份地域油耗指数、车辆历史油耗指数、加油周期内平均速度、急加速指数、急减速指数、急转向指数、怠速指数、速度区间占比、转速区间占比和排量,用相关系数筛选出影响大的因素,所述相关系数是用以反映变量之间相关关系密切程度的统计指标,相关系数按积差方法计算,以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度,所述相关系数是皮尔逊相关系数;进一步地,所述S11中油耗指数加工方法具体如下:1)按品牌、车型、排量、变速箱类型、发动机型号、最大马力将车辆分组,计算得到平均百公里油耗值,2)将每一车辆每一加油周期的百公里油耗除以对应分组车型的平均百公里油耗值;进一步地,所述S12中月份地域油耗指数为按月份、城市分组的平均油耗指数,所述车辆历史油耗指数为按车辆ID分组计算得到的平均油耗指数,所述加油周期内平均速度为加油周期内总行驶里程/加油周期总行驶时长,所述急加速指数为急加速次数/加油周期内总行驶里程,其中急加速定义为车辆正加速度达到某个阈值;进一步地,所述S12中急减速指数为急减速次数/加油周期内总行驶里程,其中急减速定义为车辆负加速度达到某个阈值;所述急转向指数为急转向次数/加油周期内总行驶里程,其中急转向定义为车辆转向角达到某个阈值;所述怠速指数为怠速时长/加油周期内总行驶里程;所述速度区间占比为将采集到的速度划分到不同速度区间内,各区间的占比;所述转速区间占比为将采集到的转速划分到不同转速区间内,各区间的占比;所述排量为不同车型的排量;进一步地,对S12中的每个自变量计算与S11因变量油耗指数的相关系数,分析各个自变量因素对油耗指数的影响大小。进一步地,所述S2包括:S21:将S1中特征数据组成数据集,在数据集中随机抽样数据,选择其中的70%作为测试集,剩余30%作为训练集;S22:设置XGBoost模型参数,设置油耗指数作为因变量,其他指标作为自变量,设置objective=“reg:linear”,另外设置其他训练参数如学习率,线程数,迭代次数,L1,L2正则惩罚系数,树深度与误差函数,所述误差函数默认为RMSE,通过调整这些参数来对模型进行调优,直至最后结果误差最小;进一步地,所述S3包括:S31:将测试集数据输入进训练好的模型,计算出预测的油耗指数;S32:查看油耗指数预测值的密度分布情况;S33:通过百分位数来查看油耗指数预测值与真实值的差异的分布情况;S34:计算测试集上油耗指数均方根误差和绝对误差,根据油耗指数反求百公里油耗,计算得百公里油耗的均方根误差和绝对误差;进一步地,所述S4包括:S41:将单次行程加工出的指标数据输入进训练好的XGBoost模型,计算得到单次行程的预测百公里油耗指数,并反求出预测百公里油耗;S42:对每个加油周期下的所有单行程,将预测出的单行程百公里油耗按该行程里程加权,与其所在的加油周期的百公里油耗进行比较,计算出均方根误差和平均绝对误差;本发明所述方法能较准确地预测出车辆单次行程的百公里油耗,均方根误差RMSE=1.08升,平均绝对误差MAE=0.85升。附图说明图1为本发明所述方法整体步骤图;图2为本发明所述方法中月份地域油耗指数地域图;图3为本发明所述方法中月份地域油耗指数折线图;图4为本发明所述方法中各特征与油耗指数相关系数图;图5为本发明所述方法中速度区间与油耗指数相关系数图;图6本发明所述方法中转速区间与油耗指数相关系数图;图7本发明所述方法中油耗指数预测值密度分布图;图8本发明所述方法中预测集上的预测值与实际值差异分布图;图9本发明所述方法中预测值与实际值差异的绝对值分布图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细描述。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。下面结合附图和具体实施例对本发明作进一步说明,但不作为对本发明的限定。下面为本发明的举出最佳实施例:如图1-图9所示,本发明提供一种基于汽车OBD数据预测某次行程百公里油耗的方法,所述方法使用加油周期的百公里油耗数据来抽取特征建立模型,最后将此模型应用在单行程百公里油耗的预测上,最后算出预测的单行程的百公里油耗,所述方法包括:S1:特征数据选取与分析;S2:建立模型,使用加油周期数据训练模型;S3:使用加油周期数据验证模型;S4:使用单行程数据验证模型。所述S1包括:S11:选取因变量,新建一个指标为油耗指数,加工油耗指数,存放基于车型归一化处理后的百公里油耗;S12:选取自变量,定义月份地域油耗指数、车辆历史油耗指数、加油周期内平均速度、急加速指数、急减速指数、急转向指数、怠速指数、速度区间占比、转速区间占比和排量,用相关系数筛选出影响大的因素,所述相关系数是用以反映变量之间相关关系密切程度的统计指标,相关系数按积差方法计算,以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度,所述相关系数是皮尔逊相关系数,所述油耗指数加工方法具体如下:1)按品牌、车型、排量、变速箱类型、发动机型号、最大马力将车辆分组,计算得到平均百公里油耗值,2)将每一车辆每一加油周期的百公里油耗除以对应分组车型的平均百公里油耗值;所述月份地域油耗指数为按月份、城市分组的平均油耗指数;所述车辆历史油耗指数为按车辆ID分组计算得到的平均油耗指数;所述加油周期内平均速度为加油周期内总行驶里程/加油周期总行驶时长;所述急加速指数为急加速次数/加油周期内总行驶里程,其中急加速定义为车辆正加速度达到某个阈值;所述急减速指数为急减速次数/加油周期内总行驶里程,其中急减速定义为车辆负加速度达到某个阈值;所述急转向指数为急转向次数/加油周期内总行驶里程,其中急转向定义为车辆转向角达到某个阈值;所述怠速指数为怠速时长/加油周期内总行驶里程;所述速度区间占比为将采集到的速度划分到不同速度区间内,各区间的占比;所述转速区间占比为将采集到的转速划分到不同转速区间内,各区间的占比;所述排量为不同车型的排量;对S12中的每个自变量计算与S11因变量油耗指数的相关系数,分析各个自变量因素对油耗指数的影响大小。所述S2包括:S21:将S1中特征数据组成数据集,在数据集中随机抽样数据,选择其中的70%作为测试集,剩余30%作为训练集;S22:设置XGBoost模型参数,设置油耗指数作为因变量,其他指标作为自变量,设置objective=“reg:linear”,另外设置其他训练参数如学习率,线程数,迭代次数,L1,L2正则惩罚系数,树深度与误差函数,所述误差函数默认为RMSE,通过调整这些参数来对模型进行调优,直至最后结果误差最小。所述S3包括:S31:将测试集数据输入进训练好的模型,计算出预测的油耗指数;S32:查看油耗指数预测值的密度分布情况;S33:通过百分位数来查看油耗指数预测值与真实值的差异的分布情况;S34:计算测试集上油耗指数均方根误差和绝对误差,根据油耗指数反求百公里油耗,计算得百公里油耗的均方根误差和绝对误差。所述S4包括:S41:将单次行程加工出的指标数据输入进训练好的XGBoost模型,计算得到单次行程的预测百公里油耗指数,并反求出预测百公里油耗;S42:对每个加油周期下的所有单行程,将预测出的单行程百公里油耗按该行程里程加权,与其所在的加油周期的百公里油耗进行比较,计算出均方根误差和平均绝对误差。本发明为了预测单行程的百公里油耗,需要对单行程的数据抽取特征来拟合模型。因为单行程的百公里油耗无法得知,所以使用加油周期的百公里油耗数据来抽取特征建立模型,进而将此模型应用在单行程百公里油耗的预测上。以上也就是本发明拟保护的创新点。整体步骤如图1。1、特征数据选取与分析本发明基于200多万个加油周期的百公里油耗数据,以及对应的车况数据,例如采集时间、速度、转速、所在地域、急加速次数、急减速次数、怠速时长等等。首先定义车辆加油周期,车辆两次加油中间的时间定义为一个加油周期,其由多个行程组成。获取汽车的车况数据,通过剩余油量变化情况识别加油时间点,再根据加油时间点切分数据,进行清洗后对每段数据拟合曲线,最后计算出每辆车每段加油周期的百公里油耗。1.1选取因变量:加油周期的百公里油耗数据基于不同的车型,而车型因素对油耗会有较大的影响,所以为了消除车型对百公里油耗的影响,新建一个指标为油耗指数,存放基于车型归一化处理后的百公里油耗。油耗指数加工方法具体如下:1)按品牌、车型、排量、变速箱类型、发动机型号、最大马力将车辆分组,计算得到平均百公里油耗值2)将每一车辆每一加油周期的百公里油耗除以对应以上分组车型的平均百公里油耗值例如:假设这一组中某辆车的某一段加油周期百公里油耗是Fi,那么这辆车这一段加油周期的油耗指数就等于Fi/AvgF。这样,这一组中的所有车的所有加油周期油耗指数平均为1,某一车某一段加油周期的油耗指数大于1表示这辆车这次加油周期的油耗高于这组车的平均油耗,小于1说明低于这组车的平均油耗。2、选取自变量:定义以下指标:2.1月份地域油耗指数:按月份、城市分组的平均油耗指数;如下表:城市月份平均油耗指数北京市1月1.08北京市2月0.98北京市3月1.02北京市4月1.00北京市5月1.01………广州市1月1.03广州市2月0.94………月份地域油耗指数属于环境因素,会对油耗产生较大影响。地域对油耗的影响主要体现在地理因素与路面拥堵状况上,见图2。颜色深表示油耗指数大,相对耗油量大,颜色浅表示油耗指数小,相对耗油量小。月份对油耗的影响主要体现在温度上,比如东三省因为冬天气温低,油耗高;西南地区气温适宜,油耗低。两者对油耗影响叠加,如图3:2.2车辆历史油耗指数:按车辆ID分组计算得到的平均油耗指数,由于每个人的驾驶习惯以及大概活动范围变化不大,该指标通过历史油耗数据来表征每个人所驾驶的车辆的油耗情况。2.3加油周期内平均速度:加油周期内总行驶里程/加油周期总行驶时长,从图4的相关系数中可见与油耗指数呈负相关,且作用非常显著2.4急加速指数:急加速次数/加油周期内总行驶里程,车辆正加速度达到某个阈值定义为急加速;2.5急减速指数:急减速次数/加油周期内总行驶里程,车辆负加速度达到某个阈值定义为急减速;2.6急转向指数:急转向次数/加油周期内总行驶里程,车辆转向角达到某个阈值定义为急转向;2.7怠速指数:怠速时长/加油周期内总行驶里程;发动机空转时称怠速,怠速时车辆不移动里程也不增加,但发动机转动需要耗油。所以假如怠速时间过多,车辆的百公里油耗会较高。2.8速度区间占比:仅使用平均速度粒度较粗,不能体现出不同速度对油耗的影响程度。将采集到的速度划分到不同速度区间内,计算各区间的占比,用以评估不同速度对油耗的影响。2.9转速区间占比:将采集到的转速划分到不同转速区间内,计算各区间的占比。用以评估不同转速对油耗的影响。2.10排量:对于不同排量的车型,油耗的波动程度可能不一样,这个特征可以辅助油耗指数更好的表现油耗波动程度。以上特征对油耗的影响各不相同,这里用相关系数来衡量各因素的重要性,以此筛选出影响力较大的因素。相关系数是用以反映变量之间相关关系密切程度的统计指标。相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。这里用的是皮尔逊相关系数相关系数的值介于–1与+1之间,即–1≤r≤+1。其性质如下:当r>0时,表示两变量正相关,r<0时,两变量为负相关。当|r|=1时,表示两变量为完全线性相关,即为函数关系。当r=0时,表示两变量间无线性相关关系。当0<|r|<1时,表示两变量存在一定程度的线性相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱。三级划分所述相关系数的值:|r|<0.4为低度线性相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关。本申请中因为样本数量大,达百万级,所以计算出来的相关系数绝对值容易偏小。以上特征相关系数如图4。从图4可以看出车辆历史油耗指数与油耗指数正相关最显著,历史油耗指数越大,油耗越高,历史油耗指数越小,油耗越低。其次是加油周期内平均速度与油耗指数显著负相关,平均速度越大,油耗越低,平均速度越小,油耗越高。接下来依次是急加速指数,怠速指数,急减速指数,月份地域油耗指数,急转向指数。关于加油周期内平均速度这个指标粒度较粗,这里将速度分解到不同区间,分析不同区间下的速度与油耗指数间的关系。从图5可见速度较低时耗油量最大,然后随着速度增大耗油量逐渐减少,直到速度在[70,90]达到最省油状态,之后油耗随着速度增加而增加。转速也对油耗存在影响,如图6:从图6可见,和速度一样,转速也有最佳转速区间,在2000-2500内油耗最低,离开这个区间后油耗逐渐增加。2、建立、训练模型对于预测问题,较适合的解决方法是采用回归模型。对比了多元线性回归,神经网络,XGBoost模型应用在测试集上的均方根误差RMSE,XGBoost模型的均方根误差RMSE最小,所以这里选择XGBoost模型。XGBoost的全称是ExtremeGradientBoosting。不同于传统的GBDT方法,XGBoost对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项整体求最优解,用以权衡目标函数的下降和模型的复杂程度,避免过拟合。并且它能够自动利用CPU的多线程进行并行计算以提高计算速度,可用来处理分类、回归问题。将以上特征数据组成数据集,在此数据集中随机抽样数据,选择其中的70%作为测试集,其他30%作为训练集。设置XGBoost模型参数,设置油耗指数作为因变量,其他指标作为自变量,设置objective=“reg:linear”,另外设置其他训练参数如学习率,线程数,迭代次数,L1,L2正则惩罚系数,树深度,误差函数(默认RMSE)等,可以通过调整这些参数来对模型进行调优,直至最后结果误差最小。在选取了适当的训练参数后,使用训练集数据开始训练:[0]train-rmse:0.395088[1]train-rmse:0.286086[2]train-rmse:0.212867[3]train-rmse:0.165185[4]train-rmse:0.135531[5]train-rmse:0.118038[6]train-rmse:0.108167[7]train-rmse:0.102724…[44]train-rmse:0.091511[45]train-rmse:0.091452[46]train-rmse:0.091403[47]train-rmse:0.091281[48]train-rmse:0.091157[49]train-rmse:0.091105训练迭代了50次,训练误差从0.395一直减小,逐渐稳定到0.091,这已经是较好的结果了。3、模型验证3.1将测试集数据输入进训练好的模型,计算出预测的油耗指数;3.2查看油耗指数预测值的密度分布情况,见图7,油耗指数预测值极大比例落在在[0.7,1.3]区间里,说明预测得到的油耗指数较为平滑并围绕1,在合理区间内。3.3通过百分位数来查看油耗指数预测值与真实值的差异的分布情况,76.1%的数据的绝对差异落在[0,0.1)区间,95.4%的数据的绝对差异落在[0,0.2)区间,说明预测得到的油耗指数非常接近实际油耗指数。如图8和图9所示。位于两端2%的数据属于异常值,经查询,绝大部分为福特福克斯车型,因该车型与OBD盒子未深度适配,采集到的各项数据指标偏差较大,从而导致了预测值的偏离。3.4计算出测试集上油耗指数均方根误差RMSE=0.097,绝对误差MAE=0.071;由油耗指数反求百公里油耗,计算得百公里油耗的均方根误差RMSE=0.915升,绝对误差MAE=0.658升,说明这样的结果已经具有实际使用意义。4、使用单行程数据验证模型4.1将单次行程加工出的指标数据输入进训练好的XGBoost模型,计算得到单次行程的预测百公里油耗指数,并反求出预测百公里油耗。4.2对于每个加油周期下的所有单行程,将预测出的单行程百公里油耗按该行程里程加权,与其所在的加油周期的百公里油耗比较,计算出均方根误差RMSE=1.08,平均绝对误差MAE=0.85。单行程油耗测试误差RMSE比加油周期油耗测试误差大了0.165,主要原因在于单行程数据中转速的获取频率为每五分钟取一个值,单个行程的转速样本数据过少,不能获得足够完整的的转速总体分布情况。假如增加转速的采集频率,则可以减小单行程的百公里油耗预测误差。本发明所述方法能较准确地预测出车辆单次行程的百公里油耗,均方根误差RMSE=1.08升,平均绝对误差MAE=0.85升以上所述的实施例,只是本发明较优选的具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1