一种高精度无线语音识别门禁系统的制作方法
本发明涉及门禁技术领域,具体涉及一种高精度无线语音识别门禁系统。
背景技术:
相关技术中的门禁系统多为有线传输方式,新增布线极为繁琐,且目前主流的语音识别方法多采用模板匹配法,而采用模板匹配法最大的缺点是需要存储大量的语音模型,当存储的语音模型达到一定限度时,会发生语音模型之间可能互相混淆的情况,大大降低识别性能。我们知道音频是一类重要的多媒体形式,与人类生活息息相关,其主要表现形式主要有音频、音乐和声音。在2001年tonkalker第一次提出了“感知哈希”的概念,感知哈希是指将在数据量的多媒体数据映射为长度较小的比特串,并将感知相近的多媒体对象映射成数学相近的哈希值,因此感知哈希关注的是感知的相似性,在音频验证方面,将输入音频映射成二进制哈希序列,然后将预先存在的二进制哈希序列进行比较,可以准确验证。
在音频压缩方面,常常应用带改进的离散余弦变换,所谓改进的离散余弦变换(modifieddiscretecosinetransform,mdct)是一种与傅立叶变换相关的变换,以第四型离散余弦变换(dct-iv)为基础,重叠性质如下:它是应用于处理较大的资料集合,当连续的资料区块中,当前的资料区块跟后续的资料区块有重叠到的情形;即当前资料区块的后半段与下一个资料区块的前半段为重叠的状态。
在音频解码方面,开源解码器libmad(mpegaudiodecoder)是一个开源的高精度mpeg音频解码库,支持mpeg-1(layeri,layerii和layeriii-也就是mp3)。开源解码器libmad(mpegaudiodecoder)提供24-bit的pcm输出,完全是定点计算,非常适合没有浮点支持的平台上使用。使用libmad提供的一系列api,就可以非常简单地实现mp3数据解码工作。
非负矩阵分解是针对非负的矩阵进行分解降维的概念,最早由两位科学家d.d.lee和h.s.seung与1999年在《nature》杂志上提出。非负矩阵分解通过低秩,对那些都为非负值得矩阵进行分解。非负矩阵分解在感知哈希技术中有着广泛的应用。
技术实现要素:
针对上述问题,本发明旨在提供一种高精度无线语音识别门禁系统。
本发明的目的采用以下技术方案来实现:
一种高精度无线语音识别门禁系统,包括语音采集模块、无线传输模块、语音信号处理模块、验证识别模块、感知哈希序列数据库和门禁,所述语音采集模块用于采集目标语音信号;所述语音信号处理模块用于将目标语音信号进行二进制比特的感知哈希序列构造;所述感知哈希序列数据库中预存有标准的二进制比特方式的感知哈希序列;验证识别模块用于将目标语音信号的感知哈希序列与感知哈希序列数据库中标准的感知哈希序列进行对比验证识别,得到语音验证识别结果,语音验证识别结果发送至门禁。
工作时,需要进出目标人员向语音采集模块发出目标语音信号,无线传输模块将目标语音信号发送至语音信号处理模块,语音信号处理模块将目标语音信号进行二进制比特方式的感知哈希序列构造后发送到验证识别模块,该验证识别模块将目标语音信号的感知哈希序列与感知哈希序列数据库中标准的感知哈希序列进行对比验证,如果验证成功,则绿led灯亮,门禁打开,如果验证失败,则红led灯亮,门禁保持关闭。
本发明的有益效果为:本发明采用构造二进制比特方式的感知哈希序列对目标语音信号进行处理,验证识别时扩大不同感知哈希值之间的差距,大大提高语音识别的精确度,从而提高门禁安全性能,同时本发明对目标语音信号构造成二进制比特序列方式进行存储,降低单个目标的存储空间从而起到提高存储目标数量的良好效果。
附图说明
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
图1是本发明的框架结构图;
图2是本发明的语音信号处理模块的框架结构图。
附图标记:
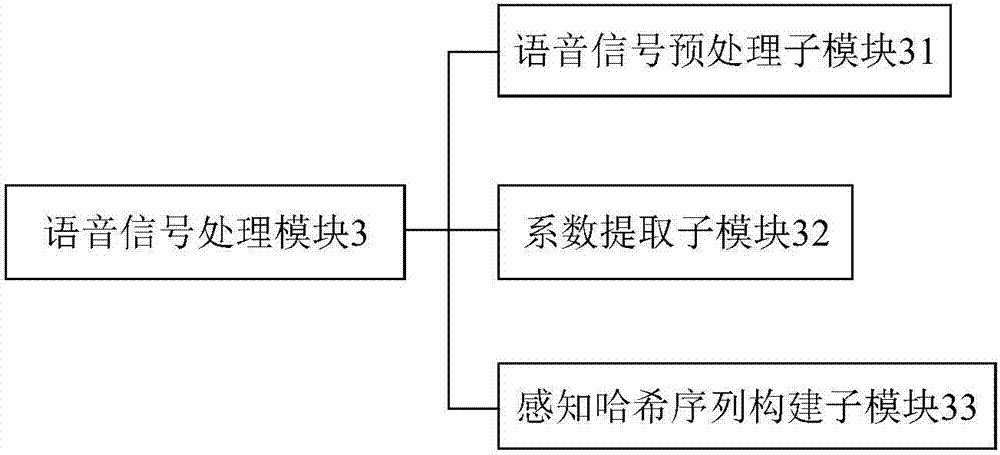
语音采集模块1、无线传输模块2、语音信号处理模块3、验证识别模块4、感知哈希序列数据库5、门禁6、语音信号预处理子模块31、系数提取子模块32、感知哈希序列构建子模块33。
具体实施方式
结合以下应用场景对本发明作进一步描述。
参见图1,本实施例的一种高精度无线语音识别门禁系统,包括语音采集模块1、无线传输模块2、语音信号处理模块3、验证识别模块4、感知哈希序列数据库5和门禁6,所述语音采集模块4用于采集目标语音信号;所述语音信号处理模块3用于将目标语音信号进行二进制比特方式的感知哈希序列构造;所述感知哈希序列数据库5中预存有标准的二进制比特方式的感知哈希序列;验证识别模块4用于将目标语音信号的感知哈希序列与感知哈希序列数据库5中预存的标准的感知哈希序列进行对比验证识别,得到语音验证识别结果,语音验证识别结果发送至门禁6。
优选地,所述无线传输模块2为4g无线网络或蓝牙。
优选地,如图2所示,所述语音信号处理模块3包括语音信号预处理子模块31、系数提取子模块32和感知哈希序列构建子模块33,所述语音信号预处理子模块31用于对目标语音信号进行加窗、分段和混叠处理;所述系数提取子模块32用于对目标语音信号进行压缩、解码及提取改进的离散余弦变换(mdct)系数;所述感知哈希序列构建子模块33用于将提取的mdct系数计算目标语音信号子带的能量,以构建目标语言的感知哈希序列。
工作时,需要进出目标人员向语音采集模块1发出目标语音信号,无线传输模块2将目标语音信号发生至语音信号处理模块3,语音信号处理模块3将目标语音信号进行二进制比特方式的感知哈希序列构造后发送到验证识别模块4,该验证识别模块4将目标语音信号的感知哈希序列与感知哈希序列数据库5中标准的感知哈希序列进行对比验证,如果验证成功,则绿led灯亮,门禁6打开,如果验证失败,则红led灯亮,门禁6保持关闭。
本发明上述实施例,采用构造二进制比特方式的感知哈希序列对目标语音信号进行处理,验证识别时扩大不同感知哈希值之间的差距,大大提高语音识别的精确度和鲁棒性,从而提高门禁安全性能,同时本发明对目标语音信号构造成二进制比特的感知哈希序列方式进行存储,降低单个目标的存储空间从而起到提高存储目标数量的良好效果。
优选地,所述门禁6包括红、绿led灯,所述红led灯用于在目标语音信号的感知哈希序列与标准的感知哈希序列匹配失败时发光;所述绿led灯用于在目标语音信号的感知哈希序列与标准的感知哈希序列匹配成功时发光。
本发明上述实施例,采用红、绿led灯进行验证结果显示,简明易懂,且材料成本低廉,节能环保。
优选地,所述语音信号预处理子模块用于对目标语音信号进行加窗、分段和混叠预处理,具体为:
(1)由于语音信号为非平稳信号,需要对采集得到的语音信号进行加窗处理,以得到短时平稳的语音信号,加窗卷积函数为:
y(a)=y(a)*w(a)
式中:y(a)为进行加窗处理后的第a帧时域语音信号,y(a)为输入的第a帧时域语音信号,w(a)为自定义窗函数,n为窗口长度;
(2)将时域语音信号y(a)分为j段,每段包括k节,每节包括p个子带,具体的j、k、p值根据实际情况设定,相邻段之间设定有(k-1)节的重复。
本发明上述实施例,将语音信号分段重叠,并设定相邻段之间设定有(k-1)节的重复,保证语音信号的鲁棒性同时确保算法精度。
优选地,所述系数提取子模块基于mdct的mp3音频压缩理论对输入的语音信号进行压缩,然后对压缩后的语音信号进行解码,提取mdct系数,包括:
(1)对预处理后的语音信号进行压缩,其中在对加窗处理后的时域语音信号进行频域变换时,采用下列公式进行频域变换:
式中,
(2)对输入的时域语音信号压缩完毕后,再对得到的压缩频域语音信号使用开源解码器libmad(mpegaudiodecoder)作为解码软件进行解码,提取mdct系数。
本发明上述实施例,通过自定义改进的离散余弦变换公式,引入修正因子,减少系统误差,能够更加准确地对时域语音信号进行频域变换,提高算法鲁棒性,有利于开源解码器libmad更加准确提取mdct系数,为接下来的能量计算奠定良好基础。
优选地,所述感知哈希序列构建子模块把通过开源解码器libmad提取得到的mdct系数来计算频域语音信号子带的能量,以构造感知哈希数序列,具体为:
(1)将频域语音信号每一个小节分为32个子带,分别计算每一个子带的能量,定义能量计算公式为:
式中,p(j,k,p)表示频域语音信号第j段第k节第p个子带的能量,q(j,k,p,q)表示频域语音信号第j段第k节第p个子带的第q个mdct系数;
(2)提取每段中1至k节1-32子带的能量,构成感知特征矩阵aj:
k值可表示矩阵长度,对特征矩阵aj通过非负矩阵分解降维,形成第j段的段内特征矩阵gj:
aj=cj×gj
其中,cj、gj分别为k×1、1×32的矩阵,将每段的段内特征矩阵转置合并得到段间联合特征矩阵d=[g1t,g2t,g3t,…,g32t],再用非负矩阵分解对段间联合特征矩阵d进行降维,得到段间特征矩阵g;
(3)构造感知哈希序列,采用二进制比特序列方式构造感知哈希序列,构造公式为:
式中,h(i)表示感知哈希序列计算函数,g(i)为段间特征矩阵g中第i个元素的数值,g(i)∈g,i=1,2,3……b,b为感知哈希序列的长度(单位:比特),
得到的感知哈希序列发送至验证识别模块。
本发明上述实施例,通过自定义能量计算公式,准确计算子带能量值,构成感知特征矩阵,最终提高二进制比特序列的精度,而且采用二进制比特序列进行存储的方式也使得存储数据量减小,同时提高运算速度。
优选地,所述验证识别模块将目标语音信号的感知哈希序列与感知哈希序列数据库中标准的感知哈希序列进行对比验证,对比得到的结果采用自定义误差值来衡量,自定义误差值公式如下:
式中,w表示自定义误差值计算函数,b为感知哈希序列的长度(单位:比特),βn为第n个权重系数,
定义比较判断函数:
式中,γ为设定的误差值的阈值。
本发明上述实施例,通过将目标语音信号的感知哈希序列与感知哈希序列数据库内标准的感知哈希序列比较,用自定义误差值来衡量两段感知哈希序列之间的差距,扩大相异的感知哈希值之间的差距值,更有利于突出差异,提高相同语音信号匹配识别时的准确度。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!