一种基于FPGA的物品自动看护方法及系统与流程
本发明涉及防盗领域,具体涉及一种基于fpga的物品自动看护方法及系统。
背景技术:
现代快节奏的工作和生活中,人们或是沉浸在各种各样的信息中,或是奔波于各地,难免会遗忘或丢失某些物品,而常见物品的遗失往往令人烦恼不已,不仅意味着时间和资金上的巨大重复和浪费,某些重要物品的丢失甚至是无法挽回的,严重者甚至会触及到法律责任,此时一套智能的物品看护系统就显得格外重要。
现有的物品及行李看管系统,多使用射频电子标签,往往安装,使用和维护都比较复杂,并且还有供电不足,通信距离有限等问题亟待解决;电子标签脱落或被拆除后,报警作用失效,即使报警信号响起来,仍然无法确认物品的丢失位置;此外,无法实时确认及存储丢失物体和疑似拿取人的信息,无法完成智能提醒及类似扩展功能实现。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术的不足,提供一种基于fpga的物品自动看护方法及系统,
本发明解决其技术问题所采取的技术方案是:
本发明供一种基于fpga的物品自动看护方法,具体步骤包括:
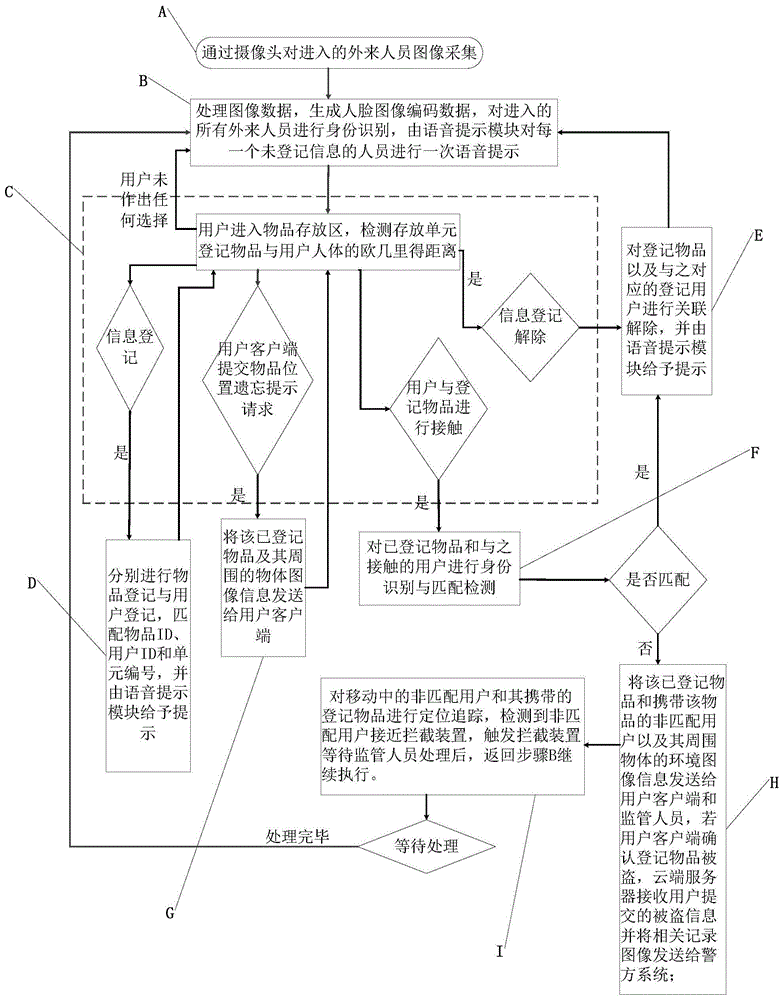
步骤a:通过摄像头对进入的外来人员图像采集;
步骤b:对进入的所有外来人员进行身份识别,由语音提示模块对每一个未登记信息的人员进行一次语音提示;
步骤c:用户进入物品存放区,检测登记物品与用户人体的距离,
若用户进行物品信息登记,则执行步骤d;
若用户进行物品信息登记解除,则执行步骤e;
若用户与登记物品进行接触时,执行步骤f;
若用户客户端提交物品位置遗忘提示请求,则执行步骤g;
若以上均未发生,则返回步骤b;
步骤d:分别进行物品登记与用户登记;
步骤e:对登记物品以及与之对应的登记用户进行关联解除;
步骤f:对已登记物品和与之接触的用户进行身份识别与匹配检测,
若信息匹配成功,执行步骤e;
若信息匹配失败,执行步骤h;
步骤g:
将该已登记物品及其周围的物体图像信息发送给用户客户端;
步骤h:
将该已登记物品及其周围物体的环境图像信息发送给用户客户端和监管人员,若用户客户端确认登记物品被盗,云端服务器接收用户提交的被盗信息并将相关记录图像发送给警方系统;
步骤i:对移动中的非匹配用户和其携带的登记物品进行定位追踪,检测到非匹配用户接近拦截装置,触发拦截装置等待监管人员处理后,返回步骤b继续执行。
进一步地,所述步骤b具体包括:
b1:将采集的图像数据的rgb三通道数据分别进行减均值归一化处理,从而移除图像的平均亮度值;
b2:处理过的用户图像生成人脸图像编码数据,该人脸图像编码数据为人脸图像编码成的128维向量;
b3:将得到的128维向量数据与预先记录在数据库内的人脸图像编码数据对比,当二者的欧几里得距离小于设定阈值时,说明是同一个人,
如果是同一个人,则以该登记用户的用户id标识该用户;
如果不是同一个人,则标识为未登记用户。
进一步地,所述步骤c中用户进入物品存放区,对用户定位追踪具体包括:
c1:当人员进入存放单元监控探头范围,对包含人体头、手、脚、颈、肘、膝盖各个部位进行检测与坐标定位;
c2:连接上述人体头、手、脚、颈、肘、膝盖各部分定位坐标并生成人体骨骼框架;
c3:检测存放单元中的物品预先记录的坐标与该人员人体手、脚、头部任一敏感部位坐标的距离。
进一步地,所述步骤d具体包括:
d1:用户选择任一空闲的物品存放单元,选择信息登记,同时语音模块提示用户登记操作,监控探头分别对登记的物品和用户进行图像信息采集;
d2:将处理过的用户图像生成人脸图像编码数据,若该用户为未登记用户,生成新的用户id;
d3:并将新用户人脸图像编码数据与用户id存储在数据库;
d4:生成物品在图像中的坐标数据,对比该物品在数据库中的坐标记录,若该物品没有记录,则生成新的物品id,并由坐标数据进行实时定位;
d5:将新物品坐标数据与生成的物品id存放到数据库,数据库将物品id、用户id与存放单元编号关联匹配,完成新物品登记,然后返回步骤c。
进一步地,所述步骤e具体包括:
选择信息解除,检测该物品id是否与该人员的用户id匹配,若匹配,对该物品id和用户id解除关联;
同时,该用户变为未登记用户,并由语音提示模块给予提示,然后返回步骤b;
若不匹配,执行步骤f。
进一步地,所述步骤f具体包括:
当检测存放单元中的物品预先记录的坐标与该人员人体手、脚、头部任一敏感部位坐标的距离小于设定阈值时,判断物体与该人员发生碰撞匹配;
同时,检测碰触人员是否为登记用户,
若是,测该用户id是否与物品id关联匹配,若匹配,语音模块进行提示,并执行步骤e;
若不匹配或者该人员不是登记用户,语音提示装置进行提示,同时触发报警装置给予警示;
计算碰触人员人脸坐标位置与其骨骼框架头部坐标的欧几里得距离,当距离小于设定阈值时,确定该碰撞人员与其生成的骨骼框架相对应,从而锁定该该碰撞人员,执行步骤h。
进一步地,所述步骤g具体包括:
g1:用户客户端提交物品位置遗忘提示请求,获取用户id、单元编号;
g2:根据单元编号,获取数据库中的物品id,查找该物品周围其他物体的坐标信息及名称;
g3:计算物体在采集图像中显示的面积,选取被登记物品附近最大的物体图像及名称;
g4:获取图像hsv色彩信息,并对比其中的饱和度的值,其越大表示越鲜艳,选取物品附近颜色最鲜艳的物体图像及名称;
g5:除了g3、g4获取的物体图像及名称外,通过计算与比较登记物品与附近物体坐标的欧几里得距离,从最小距离开始依次选取与被登记物品距离较接近的四个物体图像及名称,当数量不满足时,不再继续选取,并将以上g3、g4、g5获得的数据与单元编号推送给用户客户端;
g6:返回步骤c。
进一步地,所述步骤h具体包括:
依次按照步骤g2、g3、g4、g5执行,同时执行后得到的数据发送给用户客户端和监管人员,并触发存放单元的报警模块,然后执行步骤i。
本发明还提供了一种基于fpga的物品自动看护系统,包括:图像采集单元、fpga图像处理单元、云端服务器、路由器、入口检测区、物品存放区、出口检测区、客户端;
所述入口检测区包括语音提示模块、入口单向门闸,所述语音提示模块紧邻入口单向门闸并通过网络连接云端服务器,入口检测区用于获取外来人员人脸图像,并识别其身份信息,同时给予语音提示;
所述出口检测区包括出口出口单向门闸,所述出口单向门闸通过网络连接云端服务器,所述出口单向门闸前还设置警戒线,出口检测区用于用户出行,同时检测是否有非法人员携带未解除登记的物品外逃,当监控定位的非法人员通过警戒线时,同时电控出口单向门闸关闭,防止其逃逸;
所述客户端包括用户客户端、物品看护场地监管人员客户端;所述路由器通过线路连接云端服务器;
所述图像采集单元与fpga图像处理单元电性连接,图像采集单元包括若干覆盖整个物品自动看护系统场地的摄像头,用于对物品自动看护系统所有区域的图像信息实时采集;
所述fpga图像处理单元通过网络连接云端服务器,包括intelarria10fpga模块,用于接收并处理图像采集单元采集的图像数据,并将处理结果发送到云端服务器,同时接收云端服务器发送的数据,用于控制无线监控探头获取图像数据;
所述物品存放区包括若干物品存放单元,每个物品存放单元上都设置一个单元编号、物品处理终端和报警装置,每个物品存放单元都处在图像采集单元监控之下;所述单元编号用于标识物品存放单元,单元编号紧邻物品处理终端和报警装置;所述报警装置与云端服务器通过网络连接,服务器在检测到与登记物品碰触的人员并非匹配用户时给予报警提示;所述物品处理终端与fpga图像处理单元电性连接,同时与云端服务器通过网络连接,物品处理终端包括微控制器模块、语音模块、按键模块、无线模块、显示模块,处理终端用于物品与用户的信息登记与匹配,以及登记物品与匹配用户的信息解除,登记与匹配以及信息解除过程通过图像采集单元、fpga图像处理单元、云端服务器、物品处理终端、报警装置的配合完成;
所述云端服务器还通过网络连接客户端、警方系统,用于接收与处理fpga图像处理单元传递的处理数据,完成物品与人体图像信息的检测和记录,并将信息推送给客户端和警方系统。
进一步地,intelarria10fpga模块还包括:
预先训练好的facenet模型,用于生成人脸图像编码数据,识别人员身份信息;
预先训练好的squeezedet模型,用于生成物体的boundingbox四个顶点的坐标,通过实时获得的物体boundingbox四个顶点的坐标,对物体进行定位;
预先训练好的opencv模型和xml分类器,用于检测人体头、手、脚,颈、肘、膝盖部位,并通过连接上述各部分boundingbox中心点生成人体骨骼框架;
squeezedet模型处理得到的人脸boundingbox坐标数据与人体骨骼框架的头部位置boundingbox坐标数据相比对,用于确认该人体骨骼框架的身份,以及通过卷积网络对物品和人体在移动过程中进行定位;
经过图像预处理模块处理后,facenet模型、opencv模型、xml分类器、squeezedet模型相互配合,对物品和人体进行定位和追踪。
本发明的有益效果是:
(1)对所属财物进行实时看护;
(2)可将非法人员及其携带的登记物品的图像信息及时推送给客户端或者警方系统,提供财物丢失的线索;
(3)对特定环境特定物品的携带进行提醒及位置提示;
(4)对非法人员定位和追踪,通过关闭看护系统场地的出口,防止非法人员逃逸。
附图说明
图1为本发明基于fpga的物品自动看护方法流程图
图2为本发明基于fpga的物品自动看护系统的示意图
附图标记:
1、云端服务器,2、fpga图像处理单元,3、物品存放区,4、图像采集单元,5、入口检测区,51、语音提示模块,52、入口单向门闸,6、出口检测区,7、客户端,8、路由器
具体实施方式
为能清楚说明本方案的技术特点,下面通过具体实施方式,并结合其附图,对本发明进行详细阐述。下文的公开提供了许多不同的实施例或例子用来实现本发明的不同结构。为了简化本发明的公开,下文中对特定例子的部件和设置进行描述。此外,本发明可以在不同例子中重复参考数字和/或字母。这种重复是为了简化和清楚的目的,其本身不指示所讨论各种实施例和/或设置之间的关系。应当注意,在附图中所图示的部件不一定按比例绘制。本发明省略了对公知组件和处理技术及工艺的描述以避免不必要地限制本发明。
如图1所示,本发明一实施例提供的基于fpga的物品自动看护方法,具体步骤包括:
步骤a:通过摄像头对进入的外来人员图像采集;
步骤b:对进入的所有外来人员进行身份识别,由语音提示模块对每一个未登记信息的人员进行一次语音提示;具体包括:
b1:将采集的图像数据的rgb三通道数据分别进行减均值归一化处理,从而移除图像的平均亮度值;
b2:处理过的用户图像生成人脸图像编码数据,该人脸图像编码数据为人脸图像编码成的128维向量;
具体的,通过预先训练过的facenet模型进行人脸识别检测,处理后得到人脸图像编码数据;
b3:将得到的128维向量数据与预先记录在数据库内的人脸图像编码数据对比,当二者的欧几里得距离小于设定阈值时,说明是同一个人,
如果是同一个人,则以该登记用户的用户id标识该用户;
如果不是同一个人,则标识为未登记用户。
步骤c:用户进入物品存放区,检测登记物品与用户人体的距离,具体包括:
c1:当人员进入存放单元监控探头范围,对包含人体头、手、脚、颈、肘、膝盖各个部位进行检测与坐标定位;
具体的,为实现该方法,设置图像数据处理模型,通过预先训练过的opencv模型对包含人体头、手、脚、颈、肘、膝盖各个部位的xml分类器进行训练,运用adaboost以及haar目标检测技术,对人体头、手、脚、颈、肘、膝盖各个部位进行检测;通过预先训练过的squeezedet模型生成该人员的人脸、头、手、脚,颈、肘、膝盖部位的boundingbox四个顶点与中心点坐标;facenet模型生成该人员的人脸图像编码数据;
c2:连接上述人体头、手、脚、颈、肘、膝盖各部分定位坐标并生成人体骨骼框架;
具体的,opencv模型连接人体头、手、脚、颈、肘、膝盖各部分boundingbox中心点并生成人体骨骼框架;
c3:检测存放单元中的物品预先记录的坐标与该人员人体手、脚、头部任一敏感部位坐标的距离;
具体的,squeezedet模型检测存放单元中的物品boundingbox中心点坐标与该人员人体手、脚、头部任一敏感部位boundingbox中心点坐标的距离。
等待用户接下来的执行动作,
若用户进行物品信息登记,则执行步骤d;
若用户进行物品信息登记解除,则执行步骤e;
若用户与登记物品进行接触时,执行步骤f;
若用户客户端提交物品位置遗忘提示请求,则执行步骤g;
若以上均未发生,则返回步骤b;
步骤d:分别进行物品登记与用户登记,具体包括:
d1:用户选择任一空闲的物品存放单元,选择信息登记,同时语音模块提示用户登记操作,监控探头分别对登记的物品和用户进行图像信息采集;
d2:将处理过的用户图像生成人脸图像编码数据,若该用户为未登记用户,生成新的用户id;
d3:并将新用户人脸图像编码数据与用户id存储在数据库;
d4:生成物品在图像中的坐标数据,对比该物品在数据库中的坐标记录,若该物品没有记录,则生成新的物品id,并由坐标数据进行实时定位;
具体的,由squeezedet模型对该登记物品boundingbox四个顶点和中心点坐标数据进行实时更新,squeezedet模型读取图像信息经过一个卷积网络获得featuremap,经过一个convdet层处理得到若干矩形框,即若干个boundingbox,每个矩形框有坐标数据以及类别概率,经过非极大值抑制过滤,得到最终筛选下来的矩形框,完成物体识别;
根据检测到的连续帧图像目标boundingbox中心点距离、iou进行关联,iou即为目标boundingbox区域重合面积越大,连续帧图像目标boundingbox中心点距离越小、iou越大,则认为是同一个目标,完成物体追踪;
d5:将新物品坐标数据与生成的物品id存放到数据库,数据库将物品id、用户id与存放单元编号关联匹配,完成新物品登记;
然后返回步骤c;
步骤e:对登记物品以及与之对应的登记用户进行关联解除,具体包括:
选择信息解除,检测该物品id是否与该人员的用户id匹配,若匹配,对该物品id和用户id解除关联;
同时,该用户变为未登记用户,并由语音提示模块给予提示,然后返回步骤b;
若不匹配,执行步骤f。
步骤f:
对已登记物品和与之接触的用户进行身份识别与匹配检测,具体包括:
当检测存放单元中的物品预先记录的坐标与该人员人体手、脚、头部任一敏感部位坐标的距离小于设定阈值时,判断物体与该人员发生碰撞匹配;
具体的,当squeezedet模型检测存放单元中的物品boundingbox中心点坐标与该人员人体手、脚、头部任一敏感部位boundingbox中心点的距离小于设定阈值时,判断物体与该人员发生碰撞匹配;
同时,检测碰触人员是否为登记用户,
若是,测该用户id是否与物品id关联匹配,若匹配,语音模块进行提示,并执行步骤e;
若不匹配或者该人员不是登记用户,语音提示装置进行提示,同时触发报警装置给予警示;
计算碰触人员人脸坐标位置与其骨骼框架头部坐标的欧几里得距离,
具体的,计算人脸boundingbox中心点坐标位置与头部boundingbox的中心点的坐标欧几里得距离,当当距离小于设定阈值时,确定该碰撞人员与其生成的骨骼框架相对应,从而锁定该该碰撞人员,
然后执行步骤h。
步骤g:
将该已登记物品及其周围的物体图像信息发送给用户客户端,具体包括:
g1:用户客户端提交物品位置遗忘提示请求,获取用户id、单元编号;
g2:根据单元编号,获取数据库中的物品id,查找该物品周围其他物体的坐标信息及名称;
g3:计算物体在采集图像中显示的面积,选取被登记物品附近最大的物体图像及名称;
具体的,通过squeezedet模型生成该物品周围其他物体的boundingbox的坐标信息及标记名称,
g4:获取图像hsv色彩信息,并对比其中的饱和度的值,其越大表示越鲜艳,选取物品附近颜色最鲜艳的物体图像及名称;
具体的,opencv模型利用物体boundingbox的四个顶点坐标信息计算得到物体在采集图像中显示的面积,选取被登记物品附近最大的物体图像及标记名称;
g5:除了g3、g4获取的物体图像及名称外,通过计算与比较登记物品与附近物体坐标的欧几里得距离,
具体的,通过计算与比较登记物品与附近物体boundingbox中心点坐标的欧几里得距离,从最小距离开始依次选取与被登记物品距离较接近的四个物体图像及名称,当数量不满足时,不再继续选取,并将以上g3、g4、g5获得的图像数据与单元编号推送给用户客户端;
g6:返回步骤c。
步骤h:
依次按照步骤g2、g3、g4、g5执行,同时执行后得到的数据发送给用户客户端和监管人员,并触发存放单元的报警模块,若用户客户端确认登记物品被盗,云端服务器接收用户提交的被盗信息并将相关记录图像发送给警方系统,然后执行步骤i。
步骤i:对移动中的非匹配用户和其携带的登记物品进行定位追踪,检测到非匹配用户接近拦截装置,触发拦截装置等待监管人员处理后,返回步骤b继续执行。
如图2所示,本发明该实施例提供的基于fpga的物品自动看护系统,包括:图像采集单元4、fpga图像处理单元2、云端服务器1、入口检测区5、物品存放区3、出口检测区6、客户端7、路由器8。
入口检测区5包括语音提示模块51、入口单向门闸52,语音提示模块紧邻入口单向门闸并通过网络连接云端服务器1,入口检测区5用于获取外来人员人脸图像,并识别其身份信息,同时给予语音提示。
具体的,语音提示模块采用wt588d语音芯片;
出口检测区6包括出口出口单向门闸,出口单向门闸通过网络连接云端服务器1,出口单向门闸前还设置警戒线,出口检测区6用于用户出行,同时检测是否有非法人员携带未解除登记的物品外逃,当监控定位的非法人员通过警戒线时,同时电控出口单向门闸关闭,防止其逃逸。
路由器通过线路连接云端服务器,客户端包括用户客户端、物品看护场地监管人员客户端,
具体的,用户客户端通过app连接该物品自动看护系统,物品看护场地监管人员客户端通过电脑终端获取云端服务器1发来的图像信息。
图像采集单元4与fpga图像处理单元2电性连接,图像采集单元4包括若干覆盖整个物品自动看护系统场地的摄像头,用于对物品自动看护系统所有区域的图像信息实时采集。
fpga图像处理单元2通过网络连接云端服务器1,包括intelarria10fpga模块,用于接收并处理图像采集单元4采集的图像数据,并将处理结果发送到云端服务器1,同时接收云端服务器1发送的数据,用于控制无线监控探头获取图像数据;
具体的,intelarria10fpga还包括:
预先训练好的facenet模型,用于生成人脸图像编码数据,识别人员身份信息;
预先训练好的squeezedet模型,用于生成物体的boundingbox四个顶点的坐标,通过实时获得的物体boundingbox四个顶点的坐标,对物体进行定位;
预先训练好的opencv模型和xml分类器,用于检测人体头、手、脚,颈、肘、膝盖部位,并通过连接上述各部分boundingbox中心点生成人体骨骼框架;
squeezedet模型处理得到的人脸boundingbox坐标数据与人体骨骼框架的头部位置boundingbox坐标数据相比对,用于确认该人体骨骼框架的身份,以及通过卷积网络对物品和人体在移动过程中进行定位;
经过图像预处理模块处理后,facenet模型、opencv模型、xml分类器、squeezedet模型相互配合,对物品和人体进行定位和追踪。
物品存放区3包括若干物品存放单元,每个物品存放单元上都设置一个单元编号、物品处理终端和报警装置,每个物品存放单元都处在图像采集单元4监控之下;单元编号用于标识物品存放单元,单元编号紧邻物品处理终端和报警装置;报警装置与云端服务器1通过网络连接,服务器在检测到与登记物品碰触的人员并非匹配用户时给予报警提示;处理终端与fpga图像处理单元2电性连接,同时与云端服务器1通过网络连接,处理终端包括电性连接的微控制器模块、语音模块、按键模块、无线模块与显示模块,处理终端用于物品与用户的信息登记与匹配,以及登记物品与匹配用户的信息解除,登记与匹配以及信息解除过程通过图像采集单元4、fpga图像处理单元2、云端服务器1、物品处理终端、报警装置的配合完成。
具体的,微控制器模块采用型号为stc12c5a60s的单片机,无线模块型号为cc2500patr2.4sn的收发模块,该模块通过串口与单片机连接,语音模块采用wt588d语音芯片,显示模块为液晶显示屏。
云端服务器1还通过网络连接客户端、警方系统,用于接收与处理fpga图像处理单元2传递的处理数据,完成物品与人体图像信息的检测和记录,并将信息推送给客户端和警方系统。
最后应说明的是:以上只是本发明的优选实施方式,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也被视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!