基于城市道路卡口数据的全路网路段行程时间估计方法与流程
本发明涉及城市道路行程时间计算方法,具体涉及一种基于城市道路卡口数据的全路网路段行程时间估计方法。
背景技术:
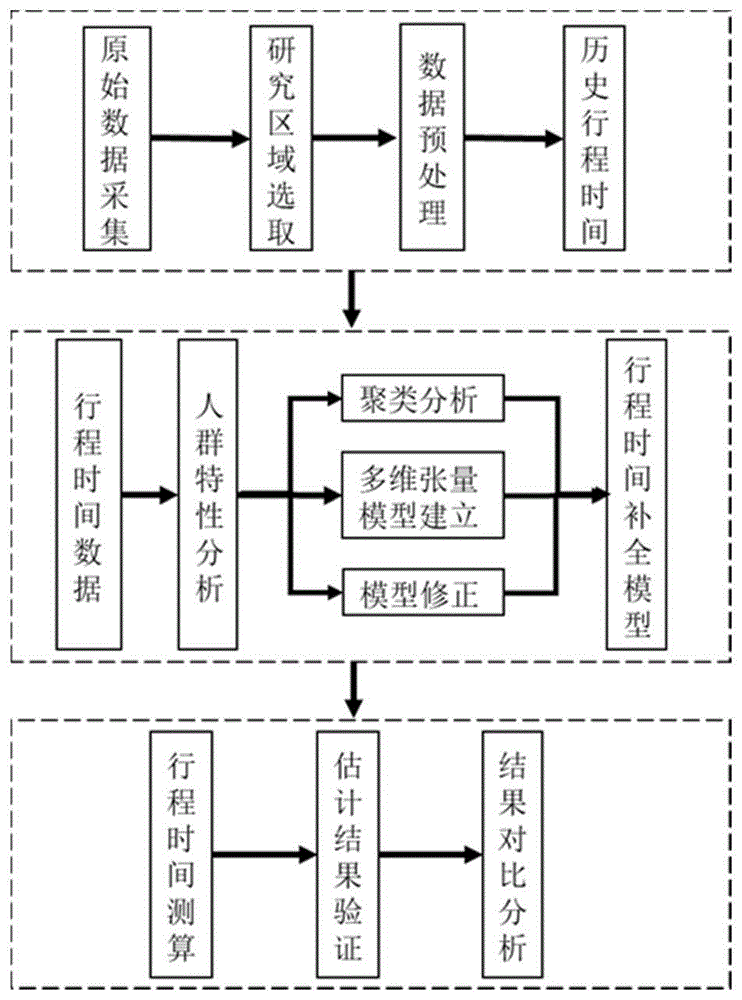
:路段旅行时间是城市交通出行信息中的一个关键指标,它可以用来评价城市道路的服务水平,反映道路的运行状况等特征。通过提供准确的旅行时间信息,个体驾驶者可以做出更好的路径选择,公交管理公司可以更有效地运营调度系统,而交通管理部门可以找到有问题的地方应该引入新的或修改后的交通控制方案来提高性能,交通政策制定部门分析交通需求和评估影响交通拥堵费等政策工具。然而,由于交通需求和供给的波动性、交通管制、信号交叉口的随机到达和离开所带来的内在不确定性等因素的影响,城市道路网络中的行驶时间估计是一个的具有挑战性的问题。近年来,信息采集和通信技术的进步正在将一个曾经数据匮乏的领域转变为数据最丰富的领域之一。越来越多的数据采集器,例如安装在出租车上的全球定位系统装置、高清卡口设备的广泛应用等。在较大的时空尺度上提供大量的车辆交通数据,并使用更复杂的模型为城市道路网络提供交通信息。但卡口数据不能提供用于分析模型通常需要的直接信息,如交通流和行程时间等信息,需要基于纯数据驱动的方法,即仅使用数据本身来发现数据内部潜在的模式和知识,据此可以发掘出很多道路或者车辆的属性特征。而现如今科技的进步,信息行业的飞速发展以及电子设备的不断更新换代,交通信息采集技术和设备也有了巨大飞跃,特别是未来5g技术在这些领域的应用将会实现车联网、路联网甚至物联网。相较于以往,如今电子设备所采集的数据指标更为多样化,准确度也不断提高。其中,道路卡口摄像监控系统就是其中之一。但是目前对于卡口数据的分析和应用主要集中在维护社会治安等方面,如抓拍违法车辆、可以车辆的识别等。车牌识别数据便于采集、识别准确率高并且体量庞大,信息客观可靠、全面并且记录连续,相较于传统的交通调查更为高效,因此使用卡口车牌识别数据可以真实的反映出车辆的出行信息,所得出的研究成果更加科学可靠,提出的建议与制定的政策也更符合实际。但是车牌识别获得的卡口数据也有一定的局限性,即加密后的车牌数据不能采集车辆驾驶员的个人社会经济属性。虽然近年来有关车牌识别数据和模型的技术有了一定的发展,但在有效的建模方法、数据稀疏性、交通条件波动等方面还存在一定的问题。技术实现要素:发明目的:针对以上不足,本发明提出一种基于城市道路卡口数据的全路网路段行程时间估计方法。技术方案:本发明所述的一种基于城市道路卡口数据的全路网路段行程时间估计方法,该方法包括以下步骤:(1)获取城市道路的若干条历史卡口数据并进行预处理,所述历史卡口数据包括卡口编号、拍摄时间、车道、车牌号;其中预处理具体为:首先将历史卡口数据中的m个卡口和n辆车重新编号为1至m和1至n,其次根据车辆编号对历史卡口数据进行排序,最后根据拍摄时间对每个车辆编号对应的历史卡口数据再次进行排序;(2)根据(1)中预处理后的历史卡口数据,计算出路段行程时间;(3)基于车辆编号、出行时段、路段行程时间、路段、车辆出行次数建立张量模型;(4)选取路段行程时间、车辆出行次数以及出行时段作为k均值聚类分析的变量,进行聚类分析;(5)基于步骤(4)中聚类分析的结果,对张量模型进行路段行程时间缺失项的补充:基于与缺失项所在的聚类类别以及对应出行时段和路段均相同的路段行程时间,对缺失项进行样条插值。进一步,步骤(2)中路段行程时间的计算方法为:对第n辆车,将其对应的第t+1条和第t条预处理后的历史卡口数据中的拍摄时间相减,即得到第t+1条和第t条预处理后的历史卡口数据对应的两个卡口之间的路段行程时间,将该行程时间添加到第t+1条预处理后的历史卡口数据中,同时删除第n辆车对应的第1条预处理后的历史卡口数据,得到新的卡口数据;其中,n=1,2,…,n,t=1,2,…,t,t为第n辆车对应的预处理后的历史卡口数据的条数。进一步,所述步骤(3)中车辆出行次数为车辆经过的路段数,出行时段为车辆进入路段的小时时段。进一步,所述步骤(3)中张量的每个维度分别表示车辆编号、出行时段、路段,每一项的值分别表示第n个车辆在第p个出行时段、第q个路段上的行程时间以及车辆出行次数。有益效果:(1)本发明提供了一种基于城市道路卡口数据的全路网路段行程时间估计方法,该方法利用卡口分布密集的城市道路卡口历史数据,挖掘出路段行程时间与卡口数据之间的联系,并考虑人群驾驶习惯的差异以及交通状况等因素进行聚类分析,对于不同状况或者不同驾驶习惯的人群进行分类;(2)本发明给出了城市道路行程时间缺失项的估计方法,基于对行程时间聚类分析的结果对于行程时间中缺失项进行补充,在进行行程时间估计时考虑了交通状况以及人群驾驶习惯差异等因素的影响,计算结果的精度和适应性都较好,从而实现了考虑人群差异性的全路网路段行程时间估计。附图说明图1为本发明的全路网路段行程时间估计方法的流程图;图2为路段1、2、3行程时间分布的频率分布直方图,其中,(a)表示路段1,(b)表示路段2,(c)表示路段3;图3为路段1、2、3的行程时间的小时分布规律图,其中,(a)表示路段1,(b)表示路段2,(c)表示路段3;图4为张量模型;图5为行程时间异常值示例;图6为不根据聚类分析结果直接插值的结果;图7为根据聚类分析结果进行插值的结果。具体实施方式下面结合附图对本发明的技术方案作进一步说明。本发明的方法利用城市道路卡口数据,首先计算出路段的行程时间,然后对于得到的行程时间数据进行人群特性分析,建立多维张量模型,并进行k均值聚类,并对于路网行程时间模型进行补全,将建模结果与实际行程时间进行比对分析,在此基础上可以为不同类型的驾驶者提供相应的行程时间参考,对于出行者路径选择具有一定的指导意义。参照图1,该方法包括以下步骤:(1)获取城市道路的若干条历史卡口数据并进行预处理,所述历史卡口数据包括卡口编号、拍摄时间、车道、车牌号;其中预处理具体为:首先将历史卡口数据中的m个卡口和n辆车重新编号为1至m和1至n,其次根据车辆编号对历史卡口数据进行排序,最后根据拍摄时间对每个车辆编号对应的历史卡口数据再次进行排序。步骤1-1、数据获取本发明使用的数据来自宁波市主城区2018年6月5日全天的城市道路卡口数据。步骤1-2、数据预处理先将原始文件导入数据库,然后根据卡口编号筛选出研究区域内的所有数据,对数据进行清洗,将重复数据、错误数据删除以及未检测出的数据删除。因原始数据中卡口编号和车辆编号较长,故为了减少文件所占用计算机内存,重新命名车牌号以及卡口编号,并保留车辆编号(newcarid)、车道(laneno)、拍摄时间(snapshottime)、卡口编号(newdeviceid)字段,并根据车辆编号以及拍摄时间排序,预处理后数据如表1所示:表1清洗后卡口数据格式示例车辆编号卡口编号拍摄时间车道1332018-06-0512:43:54.00021222018-06-0512:44:45.00021752018-06-0512:45:52.00031982018-06-0512:50:07.000311442018-06-0515:11:52.0001(2)对第n辆车,将其对应的第t+1条和第t条预处理后的历史卡口数据中的拍摄时间相减,即得到第t+1条和第t条预处理后的历史卡口数据对应的两个卡口之间的路段行程时间(单位为秒),将该行程时间添加到第t+1条预处理后的历史卡口数据中,同时删除第n辆车对应的第1条预处理后的历史卡口数据,得到新的卡口数据,如表2所示。表2行程时间数据示例车牌编号路段行程时间路段起始的卡口编号路段结束的卡口编号15133221672275125575981855898341323478(3)对于城市路网的某些具体路段的行程时间进行人群特性分析以及时空特性分析,根据卡口数据建立行程时间多维张量模型。基于车辆编号、路段行程时间、出行时段、路段出行次数等变量建立张量模型。步骤3-1、城市路网行程时间的人群特性分析根据得到的行程时间数据,对其进行人群特性分析。路段1、2、3行程时间分布的频率分布直方图如图2中的(a)至(c)所示。从图中可以看出,绝大部分出行者的行程时间都集中在某个范围区间内。路段1行程时间频率峰值集中在50s左右,路段2行程时间频率峰值集中在40s左右,路段3的行程时间频率峰值则集中在70-80s。路段1和路段2都出现了两个频率的峰值,路段1的第二个峰值出现在115s左右,路段2的第二个频率峰值出现在100s左右,而路段3的第二个峰值虽然并不明显,但是也能观察出在150s左右出现第二个高峰。不同区间中大部分的驾驶者的行程时间都是相近的,车辆的行程时间大都集中分布在某些区间内,这表明了不同驾驶员的行程时间具有一定的相似性,因此可以考虑对行程时间相近的驾驶者进行聚类分析。路段1、2、3的行程时间的小时分布规律图如图3中的(a)至(c)所示。从图中可以看出,三条路段全天的行程时间具有一定的相似性,路段行程时间均在0时至5时之间达到最低值,在早晨7时至9时出现早高峰,在傍晚17-19时出现晚高峰,在其他时刻则有所下降,曲线变化趋势符合交通工程学的理论知识。从图3还可以看出,路段3在早晨8时的行程时间明显较其它时刻偏大,推测行程时间明显增大可能是早高峰的交通量增大,信号配时发生改变或者采取了一些其他交通管理与控制措施等原因造成的。其中,这些图中还有很多离散的点,这些点与绝大多数车辆的行程时间相差较大,属于行程时间的异常值,因此在后续章节中要对其进行修正。步骤3-2、路网行程时间多维张量模型建立本发明根据车辆编号、行程时间、出行时段、出行次数等变量建立张量模型。对于出行时段这一变量,本发明中认为进入路段时卡口所记录的时间所在的小时为出行时段,利用python对于时间数据格式“xx年/x月/x日xx时/xx分”中的小时项进行提取,得到出行时段;对于每辆车的路段出行次数进行统计,将得到结果存储在一个二维数组中,并将每辆车的路段出行次数对应写入数据文件。如图4及表3所示,张量的每个维度分别表示车辆编号、出行时段、路段,每一项的值分别表示第n个驾驶员(车辆)在第p个出行时段、第q个路段上的行程时间以及车辆出行次数。表3张量模型示例车牌编号路段行程时间出行时段路段路段出行次数1511233-2251671222-75512551275-985185581298-3451321534-785(4)选取路段行程时间、路段出行次数以及出行时段作为k均值聚类分析的变量,进行聚类分析,利用python对张量模型进行处理,代入建立的模型中,设置好模型的参数,k均值聚类分析结果。从结果可以看出,行程时间可大致分为快、中以及慢三类,从行程时间、出行时段、出行次数等方面将驾驶者分为了三个大类,聚类中心结果、聚类结果示例分别见表4和5。表4k均值聚类中心0120-0.691239-0.092406-0.25491111.0143090.199209-0.2332862-0.124195-0.3031662.690035表5k均值聚类结果示例路段行程时间出行时段路段出行次数聚类类别0-0.0520830.648406-0.741329010.777812-0.290377-0.446026121.469392-0.290377-0.446026131.7736871.023919-0.44602614-0.6053461.399432-0.8594500…............(5)在所建立的张量模型中,有些路段行程时间项有明显的偏差,如表6、图5所示,其行程时间与同路段其他车辆的行程时间存在较大差异,因此需要对其进行修正。样条插值法中的分段线性插值,对行程时间缺失项进行补充。在补充时首先确定该缺失项在文件中所在的位置,然后筛选出与其路段、聚类类别、出行时段均相同的所有数据,并基于这些数据的行程时间值对行程时间的缺失项进行样条插值。表6行程时间异常值示例为了验证模型的可靠性,从研究区域内所有行程时间中随机选取1%已知行程时间的数据,分别使用两种方法来进行插值:方法一使用不根据聚类分析结果直接插值,而方法二则基于上述插值方法对其进行估计,并将两种方法所得到行程时间结果的估计值与真实值进行对比分析。插值结果分别如图6、图7所示,分别对两幅图进行回归分析,采用线性回归对于图像进行拟合,得到的结果如下:1)根据聚类分析的结果进行插值的回归公式为:y=0.9695x+2.5443其中r2=0.7572。2)直接对行程时间进行插值的线性回归公式为:y=0.9356x+5.9443其中r2=0.5756。其中,回归变量的系数β越接近于1则表明行程时间的估计值越接近于真实值,r2越接近于1表明行程时间估计的精度较高。在实际案例应用中,由于该方法的估计结果有一定的缺点和不足,因此回归系数不可能完全等于1,而截距不等于0则可能是因为估计方法具有一定的倾向性,如整体偏大。从图像以及回归结果可以看出,方法一的估计精度要优于方法二,图像上也可以直观地观察出散点较为集中和收敛,方法一的回归方程系数和r2均小于方法二,拟合程度较高,可以更为精确地估计行程时间,从而验证了本发明提出方法的可靠性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1