一种应用于公交调度中始发站非均匀发车的方法及系统与流程
1.本发明涉及公交调度技术领域,尤其是涉及一种应用于公交调度中始发站非均匀发车的方法及系统。
背景技术:
2.由于一天内公交客流量存在较大的变化,发车间隔均等的公交排班不能很好地满足乘客出行的需求,容易造成运力与需求不匹配的问题。非均匀发车算法可以依据客流需求的变化规律,调整发车间隔的大小,使公交排班更为适应客流的变化,运力分配更合理。在此基础上,当实时客流与历史客流规律不匹配时,需要及时调整之前确定的发车间隔,使之符合当前的客流情况,从而优化乘客的出行体验。
3.目前,现有的公交企业行车计划中车辆班次的编排方法较为单一,多为规律性的平均车隔排列方式,即按固定的一个时间间隔,安排车辆从始发站发出。班次时间固定,每次调班都需要人工去计算调整,这种排班调度模式不符合日益多变的客流规律变化,也对公交运力造成浪费或不足。因此,解决上述不足是我们亟待解决的问题。
技术实现要素:
4.鉴于以上现有技术的不足,本发明提供了一种应用于公交调度中始发站非均匀发车的方法及系统,不仅减少了乘客等车的时间,优化了乘客的出行体验,而且从运营管理来说,在保障运力的同时,降低了运营成本,提高了调度应变的能力。
5.为了实现上述目的及其他相关目的,本发明提供的技术方案如下:
6.一种应用于公交调度中始发站非均匀发车的方法,包括以下步骤:
7.t1:依据历史客流数据,以天为周期对乘客到达规律进行分析,将一天内单位小时线路上的最大端面客流量,按时间顺序组成一组有序样品{p1,p2,...,pn},其中n可通过设置公交运营时间得到,pi为第i小时最大断面客流量;
8.t2:基于有序样品{p1,p2,...,pn},建立有序样品聚类的fisher模型划分特征时段,步骤如下:
9.t21:计算类直径,计算有序的样品的均值从而得出样品类直径
10.t22:分类的损失函数,b(n,k)表示将n个有序样品分为k类的一种分法,常记b(n,k)为其中分点为:1=i1《i2《
…
《ik《n,分类法的损失函数为:记p(n,k)是使l[b(n,k)]达极小的分类法;
[0011]
t23:建立最小分类损失函数表,计算最小分类损失函数{l[p(l,k),3≤l≤n,2≤k≤n-1]},分别计算将l个样品分类时,最优分割的损失函数的所有结果;
[0012]
t24:求最优分类,利用fisher算法得到上下行方向的最小损失函数值随分类数变化曲线图,分析计算得到损失函数下降坡度较小的位置,合理地选取分类数量f=k,并根据分类数量反推时刻划分情况,从而得到特征时段总数f,f∈[1,f]表示特征时段的编号,tf表示f特征时间段的时间跨度,则有:
[0013][0014]
其中,ti表示各时间段的时长,f特征时段包含的小时时段{n,n+1,...,m-1,m},其中n≤m,其中n和m分别表示f时段的起始时段序号和终止时段序号;
[0015]
t25:在f时段,乘客在k站的到达率λ
k,f
,计算如下:
[0016][0017]
其中,p
k,f
为乘客在f时间段内到达k站的人数,tf为f时段的大小;
[0018]
t3:分别计算每个时段内的发车班次数nf,并计算得到总发车次数:
[0019][0020]
其中,f表示特征时段的编号,f表示特征时段总数,f∈[1,f],nf为f时段内的发车班次,p
mf
为f时段内的公交线路高断面高峰小时客流量,α为f时段车辆的满载率,分高峰和平峰,n为公交车辆额定载客量,tf为f特征时段的时间跨度,n为线路配车数;
[0021]
t4:基于乘客等待时间最少和运营收益最大为目标,并设置最小发车间隔约束,以所有班次发车时刻序列为决策变量,利用遗传算法求解基本发车时刻表,使之符合历史客流规律,得出运营收益最大目标函数:
[0022]
其中,其中r
k,f
表示第f个特征时段在第k站的乘客到达率,tf表示f特征时段的时间跨度,p表示统一的票价,c为车辆运营的单位成本,l为线路总的长度,n为发车班次数,
[0023]
与此同时,得出乘客等待时间最小的目标函数:
[0024][0025]
其中,λ
n,k
为在k站台的第n个班次上车的乘客人数,w
n,k
为在k站台的第n个班次上车的乘客最大等待时间,
[0026]
分别对两个目标函数进行统一化处理,处理公式为:
[0027][0028]
其中f为目标函数值,f
max
为目标函数的最大可能取值,f
min
为目标函数的最小可能取值,f`为归一化后的目标函数值;
[0029]
t5:基于归一化后的目标处理公式f`,针对f1和f2,得到目标优化函数:minf=
w2f
′
2-w1f
′1,
[0030]
其中,w1,w2为加权系数,两者的比值表示两个优化目标的比重。
[0031]
进一步的,所述目标优化函数的约束条件分别为:
[0032]
约束1:最大最小发车时间间隔约束:任意相邻两车之间的发车间隔要满足最大最小发车时间间隔约束:
[0033]
δt
min
≤t
i-t
i-1
≤δt
max
,其中,δt
max
表示相邻两车之间的最大发车间隔,δt
min
表示相邻两车之间的最小发车间隔,
[0034]
约束2:两个相邻的发车间隔之差的约束:为保证发车时刻的连续性,任意两个相邻的发车间隔之差小:
[0035]
|(t
i+1-ti)-(t
i-t
i-1
)|≤ε,
[0036]
约束3:平均满载率的约束:
[0037][0038]
其中,q表示车辆满载时的容量,θ表示每车平均期望满载率,tf表示f特征时段的时间跨度,r
k,f
表示第f个特征时段在第k站的乘客到达率。
[0039]
进一步的,在步骤t5中,所述w1,w2为所述目标优化函数的加权系数,满足:w1+w2=1。
[0040]
为了实现上述目的及其他相关目的,本发明还提供了一种应用于公交调度中始发站非均匀发车的系统,所述系统包括:
[0041]
输入模块,用于数据参数的输入;
[0042]
数据处理模块,用于数据的分析和处理;
[0043]
存储模块,用于历史数据的存储;
[0044]
输出模块,用于数据的输出;
[0045]
显示模块,用于不同类型数据的显示;
[0046]
所述数据处理模块与所述输入模块、所述存储模块、所述输出模块、所述显示模块电性连接。
[0047]
进一步的,所述数据参数包括历史客流数据、公交车额定载客量、公交运营时间、车辆在各个站点间的行程时间、发车间隔约束、相邻的发车间隔之差最大值、最小平均满载率、票价、车辆运营单位成本和运营线路总长度。
[0048]
进一步的,所述所述数据的输出包括基本的行车时刻表和各站点客流到达率。
[0049]
本发明具有以下积极效果:
[0050]
1)本发明从乘客满意度来说,减少了乘客等车的时间,大大优化了乘客的出行体验。
[0051]
2)本发明从运营管理来说,在保障运力的同时,降低了运营成本,提高了调度应变的能力。
附图说明
[0052]
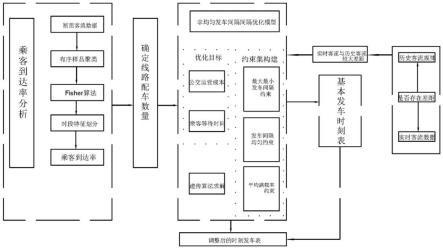
图1为本发明流程示意图;
[0053]
图2为本发明fisher算法流程示意图。
具体实施方式
[0054]
下面结合附图和实施例,对本发明的具体实施方式作优选详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0055]
实施例:如图1或2所示,一种应用于公交调度中始发站非均匀发车的方法,包括以下步骤:
[0056]
t1:依据历史客流数据,以天为周期对乘客到达规律进行分析,将一天内单位小时线路上的最大端面客流量,按时间顺序组成一组有序样品{p1,p2,...,pn},其中n可通过设置公交运营时间得到,pi为第i小时最大断面客流量;
[0057]
t2:基于有序样品{p1,p2,...,pn},建立有序样品聚类的fisher模型划分特征时段,步骤如下:
[0058]
t21:计算类直径,计算有序的样品的均值从而得出样品类直径
[0059]
t22:分类的损失函数,b(n,k)表示将n个有序样品分为k类的一种分法,常记b(n,k)为其中分点为:1=i1《i2《
…
《ik《n,分类法的损失函数为:记p(n,k)是使l[b(n,k)]达极小的分类法;
[0060]
t23:建立最小分类损失函数表,计算最小分类损失函数{l[p(l,k),3≤l≤n,2≤k≤n-1]},分别计算将l个样品分类时,最优分割的损失函数的所有结果;
[0061]
t24:求最优分类,利用fisher算法得到上下行方向的最小损失函数值随分类数变化曲线图,分析计算得到损失函数下降坡度较小的位置,合理地选取分类数量f=k,并根据分类数量反推时刻划分情况,从而得到特征时段总数f,f∈[1,f]表示特征时段的编号,tf表示f特征时间段的时间跨度,则有:
[0062][0063]
其中,ti表示各时间段的时长,f特征时段包含的小时时段{n,n+1,...,m-1,m},其中n≤m,其中n和m分别表示f时段的起始时段序号和终止时段序号;
[0064]
t25:在f时段,乘客在k站的到达率λ
kf
,计算如下:
[0065][0066]
其中,p
k,f
为乘客在f时间段内到达k站的人数,tf为f时段的大小;
[0067]
t3:分别计算每个时段内的发车班次数nf,并计算得到总发车次数:
[0068]
[0069]
其中,f表示特征时段的编号,f表示特征时段总数,f∈[1,f],nf为f时段内的发车班次,p
mf
为f时段内的公交线路高断面高峰小时客流量,α为f时段车辆的满载率,分高峰和平峰,n为公交车辆额定载客量,tf为f特征时段的时间跨度,n为线路配车数;
[0070]
t4:基于乘客等待时间最少和运营收益最大为目标,并设置最小发车间隔约束,以所有班次发车时刻序列为决策变量,利用遗传算法求解基本发车时刻表,使之符合历史客流规律,得出运营收益最大目标函数:
[0071][0072]
其中,其中r
k,f
表示第f个特征时段在第k站的乘客到达率,tf表示f特征时段的时间跨度,p表示统一的票价,c为车辆运营的单位成本,l为线路总的长度,n为发车班次数,
[0073]
与此同时,得出乘客等待时间最小的目标函数:
[0074][0075]
其中,λ
n,k
为在k站台的第n个班次上车的乘客人数,w
n,k
为在k站台的第n个班次上车的乘客最大等待时间,
[0076]
分别对两个目标函数进行统一化处理,处理公式为:
[0077][0078]
其中f为目标函数值,f
max
为目标函数的最大可能取值,f
min
为目标函数的最小可能取值,f`为归一化后的目标函数值;
[0079]
t5:基于归一化后的目标处理公式f`,针对f1和f2,得到目标优化函数:minf=w2f
′
2-w1f
′1,其中,w1,w2为加权系数,两者的比值表示两个优化目标的比重。
[0080]
进一步的,所述目标优化函数的约束条件分别为:
[0081]
约束1:最大最小发车时间间隔约束:任意相邻两车之间的发车间隔要满足最大最小发车时间间隔约束:
[0082]
δt
min
≤t
i-t
i-1
≤δt
max
,其中,δt
max
表示相邻两车之间的最大发车间隔,δt
min
表示相邻两车之间的最小发车间隔,
[0083]
约束2:两个相邻的发车间隔之差的约束:为保证发车时刻的连续性,任意两个相邻的发车间隔之差小:
[0084]
|(t
i+1-ti)-(t
i-t
i-1
)|≤ε,约束3:平均满载率的约束:
[0085][0086]
其中,q表示车辆满载时的容量,θ表示每车平均期望满载率,tf表示f特征时段的时间跨度,r
k,f
表示第f个特征时段在第k站的乘客到达率。
[0087]
进一步的,在步骤t5中,所述w1,w2为所述目标优化函数的加权系数,满足:w1+w2=1。
[0088]
为了实现上述目的及其他相关目的,本发明还提供了一种应用于公交调度中始发
站非均匀发车的系统,所述系统包括:
[0089]
输入模块,用于数据参数的输入;
[0090]
数据处理模块,用于数据的分析和处理;
[0091]
存储模块,用于历史数据的存储;
[0092]
输出模块,用于数据的输出;
[0093]
显示模块,用于不同类型数据的显示;
[0094]
所述数据处理模块与所述输入模块、所述存储模块、所述输出模块、所述显示模块电性连接。
[0095]
进一步的,所述数据参数包括历史客流数据、公交车额定载客量、公交运营时间、车辆在各个站点间的行程时间、发车间隔约束、相邻的发车间隔之差最大值、最小平均满载率、票价、车辆运营单位成本和运营线路总长度。
[0096]
进一步的,所述所述数据的输出包括基本的行车时刻表和各站点客流到达率。
[0097]
综上所述,本发明不仅减少了乘客等车的时间,优化了乘客的出行体验,而且从运营管理来说,在保障运力的同时,降低了运营成本,提高了调度应变的能力。
[0098]
以上所述仅是本技术的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本技术技术原理的前提下,还可以做出若干改进和替换,这些改进和替换也应视为本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1