一种面向动态车流的基于强化学习的交叉口信号周期稳定配时方法
1.本发明属于智能交通控制领域,特别涉及了一种面向动态车流的基于强化学习的交叉口信号周期稳定配时方法。
背景技术:
2.目前,随着汽车行业的快速发展,城市交通拥堵加剧,对环境和经济造成了相当大的损失,因此提高城市的交通运输效率迫在眉睫。交通信号控制(tsc)向来是城市交通管控的重要手段之一,而传统的交通信号控制方法一般是基于规则的,这些规则或是启发式的,或是来自专家经验,智能体接收一定的交通信息(如车辆排队长度)后根据嵌入程序中预先定义的规则来进行相应的信号控制,如固定时间法、最长队列优先法、最大压力法。并且传统的交通信号控制方法还会对交通系统进行一定的假设,这些假设往往在实际交通环境中并不成立。所以,传统的基于规则和系统假设的控制方法很难解决实际交通环境模态不断改变的问题。随着人工智能技术的发展,基于人工智能技术的自适应交通信号控制(atsc)愈加受到研究者的关注,各种相关技术已被应用于atsc,如模糊逻辑、遗传算法、群体智能和强化学习(rl)等。而近年来,深度强化学习(drl)作为一种强大的用于解决动态控制的人工智能范式,在交通信号控制领域中显示出了巨大的潜力。
3.目前,利用深度强化学习进行交通信号控制的尝试,都是先将交叉口环境建模成一个马尔可夫决策过程(mdp),再通过与环境交互来学习如何控制信号能获得更高的奖励值。而这种控制具有以下几个缺点:首先,强化学习算法要从头开始学习交通信号控制,而没有利用任何的先验知识,尤其是当前交叉口的历史交通数据,一方面,会造成训练资源的浪费,另一方面,因为其仅在特定的交通场景中进行训练,具有强化学习本质的过拟合特性,也会造成训练完的强化学习模型对交通控制的泛化能力不足;其次,用于交通信号控制的强化学习模型通常采用设定下一个相位的动作,这常常会造成信号配时的不稳定,存在安全问题。
技术实现要素:
4.为了解决上述背景技术提出的技术问题,本发明旨在提供一种面向动态车流的基于强化学习的交叉口信号周期稳定配时方法,克服现有技术存在的缺陷,在保证信号配时稳定性的同时,提高交通通行效率。
5.为了实现上述技术目的,本发明的技术方案为:
6.一种面向动态车流的基于强化学习的交叉口信号周期稳定配时方法,包括以下步骤:
7.步骤1:随机选取一个交叉口作为训练环境,并采集计算运行时间内交叉口各方向每车流计算周期内的车流量大小;
8.步骤2:根据上一步计算得到的离线流量数据,按比例划分每个车流计算周期内的
信号周期配时,作为强化学习交互训练时需要使用的基本信号周期配时方案;
9.步骤3:在相应的随机交叉口环境中,使用深度强化学习算法soft-actor-critic进行多轮交互训练;
10.步骤4:在多个随机交叉口环境中训练完毕后,将强化学习模型保存下来,以便应用到目标交叉口环境中进行在线的信号周期配时工作。
11.进一步地,在步骤1中,运行时间是指环境的仿真时长,车流计算周期是指在计算交叉口各方向车流量时所需设置的时间长度,一般是根据交叉口的车流变化剧烈程度,从十分钟到一小时内进行选择,交叉口各方向每车流计算周期内的车流量大小是通过计算车流计算周期内各个相位允许通行方向上的所有进入车道上通行车辆数之和,其计算公式为:
[0012][0013]
其中,表示第j个相位phasej对应的车流量大小,inputlane_num表示当前相位phase允许通行的进入车道数;throughput_newi和throughput_oldi分别表示进入车道i上当前车流计算周期内通行车辆总数和当前车流计算周期前进入但仍在该车道通行的车辆总数,二者之差,即表示当前车流计算周期内进入车道i上的通行车辆数。此步骤采集计算出的流量数据是对同一环境下的历史流量数据的一种模拟。
[0014]
进一步地,在步骤2中,所述每个车流计算周期内的信号周期配时的计算公式为:
[0015][0016]
其中,表示第j个相位phasej对应分配的时长,g为设定的信号周期总时长;phase_num表示当前交叉口的相位个数;所述基本信号周期配时方案的形式如下:
[0017][0018]
其中,num_calculation是指运行时间内的车流计算周期个数,其值等于运行时间除以车流计算周期。
[0019]
进一步地,在步骤3中,深度强化学习算法soft-actor-critic的训练过程为:
[0020]
步骤3-1:在选取的交叉口环境中,首先重置环境,以获得环境的初始状态,环境状态具体定义为交叉口各进入车道上的车辆数,再使用第一个车流计算周期内的信号周期配时,作为该交叉口信号周期的基本分配原则;
[0021]
步骤3-2:将环境状态输入强化学习模型,获得动作输出,接着根据动作,在基本分配原则的基础上,调整信号周期内各个信号的配时,具体地,将以一秒为单位来微调各个相位的时长,并保证信号周期的总时长不变,再将调整后的信号周期应用到交叉口环境中,当该信号周期结束,即可获得环境反馈的奖励和环境新状态,其中,奖励定义为交叉口各进入车道上的队列长度之和取负值;
[0022]
步骤3-3:环境状态、调整动作、奖励值以及环境新状态即是一个样本,表示为(s,a,r,s
′
),将其存入缓存区d中;此外,若此时已经经过一个车流计算周期,则使用基本信号周期配时方案中的下一个车流计算周期内的信号周期配时,作为该交叉口信号周期的基本
分配原则;
[0023]
步骤3-4:当缓存区内的样本数量达到设定的batch_size时,从缓存区采样batch_size个样本,计算损失函数值,同时对soft-actor-critic模型进行反向梯度传播,以更新网络参数。
[0024]
进一步地,在步骤3-4中,网络参数更新的具体形式为:
[0025]
critic网络(又称q网络)的损失函数定义如下:
[0026][0027][0028]
其中,q
φ
(s,a)表示状态动作对的价值函数,即critic网络的输出值,φ为网络中的可训练参数;y(r,s
′
)表示critic网络的目标输出值;e[
·
]表示取期望;表示critic网络对应的目标网络,目标网络参数是critic网络参数的指数移动平均数,表达式为指数移动平均系数τ一般取0.01,而a
′
则是一个信号周期后可采取的动作;π
θ
(a
′
|s
′
)表示actor网络的输出值,输入状态,输出对应每一个可能动作的概率值,θ为网络中的可训练参数;γ为折扣系数,一般取0.9到0.99;α为正则化系数,用于协调奖励值和策略的熵的重要性,它的自动调节方法是通过最小化以下损失函数实现:
[0029][0030]
其中,κ是一个表示目标熵的超参数;actor网络(又称策略网络)的损失函数定义如下:
[0031][0032]
其中,q
φ
(s,a)和π
θ
(a|s)与上述相同,分别表示critic网络和actor网络的输出值。
[0033]
采用上述技术方案带来的有益效果:首先,根据历史流量数据计算得的基本信号周期配时方案能够保证交叉口信号配时的稳定,不会出现极端情况,即前一个信号周期与后一个信号周期之间差距很大。而稳定的信号配时是交通工程中必须满足的,因为它符合驾驶员的期望并且可以避免安全问题;其次,强化学习算法能够处理交通流量的动态变化,从而提高交叉口的通行效率;此外,由于强化学习算法是基于历史流量数据进行训练,因此可保证该强化学习算法在训练初期即可快速收敛,即充分利用了先验知识以克服传统强化学习样本利用率低的问题;最后,本发明所提的面向动态车流的交叉口信号周期稳定配时方法还具有一定的可迁移性,即在未见过的动态环境中也能利用已学知识取得优于传统控制的效果。
附图说明
[0034]
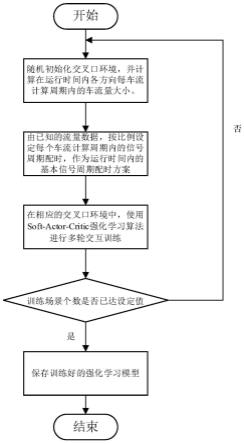
图1是本发明的方法流程图;
[0035]
图2、3分别是深度强化学习算法soft-actor-critic的具体训练过程和流程图;
[0036]
图4是具有不同相位设置的交叉口环境;
[0037]
图5是在三个随机的双相位交叉口环境中的训练对比曲线;
[0038]
图6是在相应的双相位交叉口环境以及目标交叉口环境中的测试对比曲线;
[0039]
图7是在一个四相位交叉口环境中的训练和测试对比曲线。
具体实施方式
[0040]
为了加深对本发明的认识和理解,以下将结合附图,对本发明的技术方案进行详细说明。
[0041]
实施例1:一种面向动态车流的基于强化学习的交叉口信号周期稳定配时方法,所述方法包括以下步骤:
[0042]
首先,一个交叉口环境的交通信号控制问题,通常可以被简化描述为如下优化问题:
[0043][0044]
s.t.g
min
≤g
phase_i
≤g
max
,i=1,...,phase_num
[0045][0046]
其中,tj为从车道j进入交叉口的车辆的总通行时间;g
phase_i
是分配给相位i的绿灯时间;gj是进入车道j可通行的绿灯时间;c是该交叉口的信号周期总时长;f
in,j
和u
sat,j
分别是进入车道j上的车流量以及饱和流量。
[0047]
接着,将交叉口环境建模成一个马尔可夫决策过程,表示为《s,a,p,r》,下面具体说明每一个元素:
[0048]
状态空间定义为:s={f
in,j
,v
in,j
},j=1,...,lane_num,其中,f
in,j
是进入车道j上每车流计算周期内的车流量;v
in,j
则是进入车道j上的实时车辆数。
[0049]
动作空间定义为:a={g
phase_i
},i=1,...,phase_num,即进行信号周期配时。
[0050]
状态转移概率p是交叉口环境本身决定的,而奖励定义为:其中q
in,j
是进入车道j上的实时队列长度,因为奖励越高越好,所以对队列长度之和取负值作为奖励。
[0051]
至此,就将交叉口信号控制问题转化成一个强化学习能够解决的序列决策问题,而本发明的目标就是利用强化学习来稳定地提高交叉口环境的交通通行效率。
[0052]
基于上述设计目标,如图1所示,本发明的具体步骤为:首先,随机初始化一个交叉口环境,并运行一定时间,计算出其中各方向上每个车流计算周期内的车流量大小;接着,由已知的流量数据,按比例设定每个车流计算周期内的信号周期配时,作为该环境下运行时间内的基本信号周期配时方案;然后,在相同的交叉口环境中,使用soft-actor-critic算法进行交互训练;最后,判断训练的交通场景个数是否已达到设定值,若未达到,则重复
上述过程,若已达到,则将训练好的强化学习模型保存下来,以便应用到目标交叉口环境中,进行在线的信号周期配时。
[0053]
本发明采用的深度强化学习算法soft-actor-critic是一种最大化熵的强化学习,与一般的强化学习目标是最大化累计奖励不同,其目标函数为:
[0054][0055]
其中,α为正则化系数,h(π
θ
(
·
|s
t
))是策略网络的熵,其表示式为而因为动作空间是离散的,所以本发明使用的是离散化的最大化熵强化学习,如图2和图3所示,其具体的训练过程为:
[0056]
第一步:设置超参数,包括目标熵κ,学习率λq,λ
π
,λ
α
,指数移动平均系数τ;并初始化样本缓存区d、策略网络参数θ、两个q网络参数φ1,φ2以及对应的目标网络参数本算法训练两个q网络,通过取二者输出的最小值作为最终的q值,以克服q值过估计的问题。
[0057]
第二步:通常强化学习算法要与同一环境进行多轮交互,一轮交互称为一个episode,即运行环境一定时间,而在每轮交互结束后,在下轮开始前,环境都要被重置,以获得环境的初始状态。
[0058]
第三步:每隔一个信号周期,与环境进行交互,具体过程为:通过策略网络输出当前状态s下应采取的动作a,再将动作作用于环境,获得其反馈的奖励r和下一状态s
′
,并将样本(s,a,r,s
′
)存入缓存区d。
[0059]
第四步:当缓存区d内样本数量达到设定的batch_size时,从缓存区中采样,并根据各个网络对应的损失函数进行多步梯度下降,以更新网络参数,利用指数移动平均来更新q网络对应的目标网络参数。此外还利用正则化系数α的损失函数来自动调节它。各个损失函数的计算公式如下:
[0060]
critic网络(又称q网络)的损失函数定义如下:
[0061][0062][0063]
其中,q
φ
(s,a)表示状态动作对的价值函数,即critic网络的输出值,φ为网络中的可训练参数;v(r,s
′
)表示critic网络的目标输出值;e[
·
]表示取期望;表示critic网络对应的目标网络,目标网络参数是critic网络参数的指数移动平均数,表达式为:指数移动平均系数τ一般取0.01,而a
′
则是一个信号周期后可采取的动作;π
θ
(a
′
|s
′
)表示actor网络的输出值,输入状态,输出对应每一个动作的概率值,θ为网络中的可训练参数;γ为折扣系数,一般取0.9到0.99;α为正则化系数,用于协调奖励值和策略的熵的重要性,它的自动调节方法是通过最小化以下损失函数实现:
[0064]
[0065]
其中,κ是一个表示目标熵的超参数;actor网络(又称策略网络)的损失函数定义如下:
[0066][0067]
其中,q
φ
(s,a)和π
θ
(a|s)与上述相同,分别表示critic网络和actor网络的输出值。
[0068]
下文通过实施例来说明本发明。
[0069]
(1)环境设置
[0070]
如图4所示,本发明在两相位交叉口环境和四相位交叉口环境中进行实验,其中,两相位包括东西直行和南北直行;而四相位包括东西直行、南北直行、东西左转以及南北左转。需要说明的是,在两相位交叉口环境中,每个方向仅有一个进入车道,而在四相位交叉口环境中,每个方向实际有三个进入车道,分别是直行车道、左转车道以及右转车道,因为右转不受信号控制,所以未在图中画出。
[0071]
(2)参数设置
[0072]
每个交叉口环境训练轮数为200次,一轮的仿真时间(交互时间或运行时间)为7200s,计算车流量的车流计算周期为10分钟;一次信号周期总时长为60s,其中包括切换相位时的红灯时间,设置为3s,因此一轮的控制步有7200/60=120步;随机交叉口环境个数设为3个,随机原则是在车流配置文件中每隔二十分钟随机从[2,20]中选择一个作为当前时间的车流到达率,单位为s/vehicle;soft-actor-critic算法相关参数设置有:奖励归一化常数为250,每轮结束参数更新次数为3次,且每个环境下训练的探索步数为200;网络层数为2,包括输入层和一层隐含层(输出层),隐含层神经元个数为32;batch_size为32,折扣系数γ为0.99,指数移动平均系数τ为0.01,q网络、策略网络以及正则化系数α的学习率都设为0.0003,样本缓存区的容量设为1000。
[0073]
(3)对比方法及衡量指标
[0074]
对比方法:
[0075]
为证明本发明的稳定性和高效性,将其与以下的方法进行对比:
[0076]
fixtime_avg:固定地平均地分配每个相位的时长。
[0077]
fixtime_cur:考虑实时的交通流量,通过计算前十分钟的车流量,为后十分钟按车流量比例进行信号周期配时。
[0078]
fitime_pred:考虑历史同一时期的交通流量,利用后十分钟的历史车流量,为后十分钟按车流量比例进行信号周期配时。
[0079]
cycle_rl:即是本发明提出的方法,基于历史同一时期的交通流量(实际仿真测试时,是通过预先运行环境两小时,以采集计算出的每十分钟各方向的车流量作为历史值的),利用后十分钟的历史车流量,为后十分钟按比例计算出基本信号周期配时方案,此外,在每个信号周期后利用强化学习算法soft-actor-critic,考虑实时的交通状态,进而动态地调整下一个信号周期内各相位的配时。
[0080]
衡量指标包括:交叉口的队列长度之和取负值即奖励值(-queue length)和通过交叉口的车辆的平均通行时间(traveltime)。
[0081]
(4)实验1:在两相位环境中,验证本发明的收敛性、有效性和可迁移性。
[0082]
如图5所示,其中每一行的图分别对应三个随机生成的两相位交叉口环境的训练曲线,具体地,左图是以交叉口的奖励值作为指标的对比图,而右图是以通过交叉口的车辆的平均通行时间作为指标的对比图。
[0083]
可以看出,在三个不同的交叉口环境中,且在两个衡量指标下,fixtime_cur都取得了最差的效果,这是因为基于上一个时间段的流量来控制下一个时间段的信号,非常容易产生冲突,比如上一个时间段是南北直行车流最多,但在下一个时间段就反过来,东西直行车流反而更多,类似这样的情况导致了fixtime_cur的效果还不如fixtime_avg这种固定配时方案,而fixtime_pred可以取得仅次于cycle_rl的效果,是因为采用的车流数据是离线计算得的,比较准确。此外,本发明提出的方法cycle_rl在不同训练过程中都可以收敛到最好的效果上,从而验证了cycle_rl的收敛性和有效性。
[0084]
如图6所示,前三行图分别对应在上述三个随机生成的交叉口训练环境下的测试曲线,是以测试一轮中的每个信号周期后对应的指标为度量的,即横轴的单位是控制步,可以看出,cycle_rl在两小时的测试过程中,能够实时响应交通动态变化,从而取得更高的通行效率。最后一行图是直接将训练好的cycle_rl模型应用到目标交叉口环境中得到的测试曲线,可以看出,cycle_rl在未见过的场景中,仍然可以利用已学得的知识,动态调整信号配时,使得交叉口的总队列长度尽可能小、平均通行时间尽可能短,具体地说,对于奖励值指标,cycle_rl比fixtime_avg提高了20.3%,比fimtime_cur提高了28.26%,比fixtime_pred提高了10%;对于平均通行时间指标,cycle_rl比fixtime_avg提高了12.68%,比fimtime_cur提高了19.5%,比fixtime_pred提高了6.64%,从而验证了cycle_rl的可迁移性。
[0085]
(5)实验二:在四相位交叉口环境中,验证本发明的高效性。
[0086]
如图7所示,第一行是训练曲线,第二行是测试曲线。由于具有四相位的交叉口环境,其信号配时更加复杂,可以看到在本环境中,fixtime_pred的效果和固定配时的fixtime_avg接近,说明环境的动态变化很大,使得基于历史同一时期的车流量,无法给出更合理的信号配时方案,但是,从另一个角度看,交通动态越复杂,变化越剧烈时,交通效率的提升空间就更大,因此在此环境中,cycle_rl可以提升更多的通行效率。具体地说,对于奖励值指标,cycle_rl比fixtime_avg提高了11.62%,比fimtime_cur提高了18.4%,比fixtime_pred提高了11.64%;对于平均通行时间指标,cycle_rl比fixtime_avg提高了3.4%,比fimtime_cur提高了5.45%,比fixtime_pred提高了3.21%,从而验证了cycle_rl的高效性。
[0087]
实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1