具有关联处理单元的基于N元组的分类的制作方法
概括地说,本发明涉及基于n元组(n-gram)的分类,并且具体地说,本发明涉及使用超维向量的这种分类。
背景技术:
1、超维计算(hdc)是一种用于模拟大脑的神经活动模式的计算范式,其考虑大多数神经元接收大量输入的事实。利用超维空间的点对神经活动模式进行建模,其中每个模式都是一个超维向量,被称为“超向量”,并且每个超向量可以具有到其的1000到10,000个点。
2、hdc已经用于许多不同类型的学习应用,这些应用涉及对非常大的模式的操作和比较,通常是存储器中的(in-memory)。例如,karunaratne等人的美国专利公开2020/0380384描述了一种用于使用存储器中计算进行针对推理任务(例如语言分类)的超维计算的系统,其中存储器阵列是忆阻阵列。
3、现在参考图1,图1示出了用于语言分类的hdc过程。单一语言的大量文本主体10,例如许多书籍、报纸、网站等,通常可以由一组特征向量表示,每个特征向量通常非常大,例如具有16k比特。可以将特征向量提供给特征提取器12,特征提取器12可以从文本的特征向量中提取“n元组”。n元组是n个项的有序序列。在语言分类的情况中,n元组是n个字母的序列,按照它们在文本中出现的顺序排列。因此,如果n是3并且文本是“hello world”,则有9个不同的3元组:“hel”、“ell”、“llo”、“lo_”、“o_w”、“_wo”、“wor”、“orl”和“rld”,其中_指示空格。这可以有效地区分序列“hel”和“hle”。
4、语言分类器14可以对n元组进行操作,以确定文本10的语言的特性指纹(fingerprint)向量并且可以将该指纹存储在数据库16中。语言分类器14可以对多个文本主体10进行操作,每个文本主体采用不同的语言,以生成每种语言的指纹向量。
5、当接收到未知语言的一段文本时,特征提取器12可以生成针对其的n元组,并且可以将其提供给语言分类器14。语言分类器14又可以将其指纹向量与每种语言的指纹向量进行比较,以确定新的文本片段最接近哪种语言。
6、在hdc中,语言的每个字母或符号(包括空格字符)由d维的单独超向量v表示。通常,d可以超过10,000比特长,并且每个比特可以被随机设置为1或0。由于这种随机性,不相关的超向量几乎彼此正交。
7、现在简要参考图2,其示出了16384比特的3个超向量v,代表英语中的字母“a”、“b”和“z”。在示例中,“a”的超向量以序列1001开始并以01结束,而“b”的超向量以序列0011开始并以10结束。“z”的超向量以0101开始并以10结束。
8、为了表示hdc中的n元组,特征提取器12在表示n元组中的字母和/或符号(例如“llo”)的n个超向量上计算以下函数:
9、ak = β(n-1)v[1] xnor β(n-2)v[2] xnor … xnor β1v[n-1] xnor v[n] (1)
10、其中,ak是第k个n元组的hdc表示,xnor是互斥nor运算,并且β(n-x)v[x]指示对表示n元组中的第x个符号的超向量v[x]进行n-x置换操作(即移位和旋转n-x次)。
11、在hdc中,为了创建语言指纹,语言分类器14首先将文本10的大量n元组ak转换成双极性形式。转换为双极性形式涉及将每个“0”值转换为“-1”值。语言分类器14然后将大量双极性n元组ak添加到带符号的全局语言向量中,其中hdc n元组ak的每个向量元素被单独求和。最后,语言分类器14将带符号的全局语言向量二值化为二元全局语言向量(即语言指纹),并将该语言指纹存储在数据库16中。
12、一旦已经创建了各种语言指纹,语言分类器14然后就可以实现“检索阶段”,其中未知语言的指纹被生成,然后与数据库16中存储的指纹进行比较。通常利用k最近邻(knn)相似性搜索来执行比较,并且产生“前k个(top-k)”候选语言指纹。
13、由于超向量太大,因此在标准cpu(中央处理单元)上执行计算公式1的n元组的操作在计算上很困难。karunaratne等人在忆阻阵列上实现了存储器中hdc。然而,karunaratne等人宣称公式1在计算上很难按原样实现。因此,他们首先将公式1转换为“2n-1个小项的逐分量求和”,然后,由于总和随n呈指数增长,因此他们发现了2小项近似值,当n为偶数时该2小项近似值为真。
技术实现思路
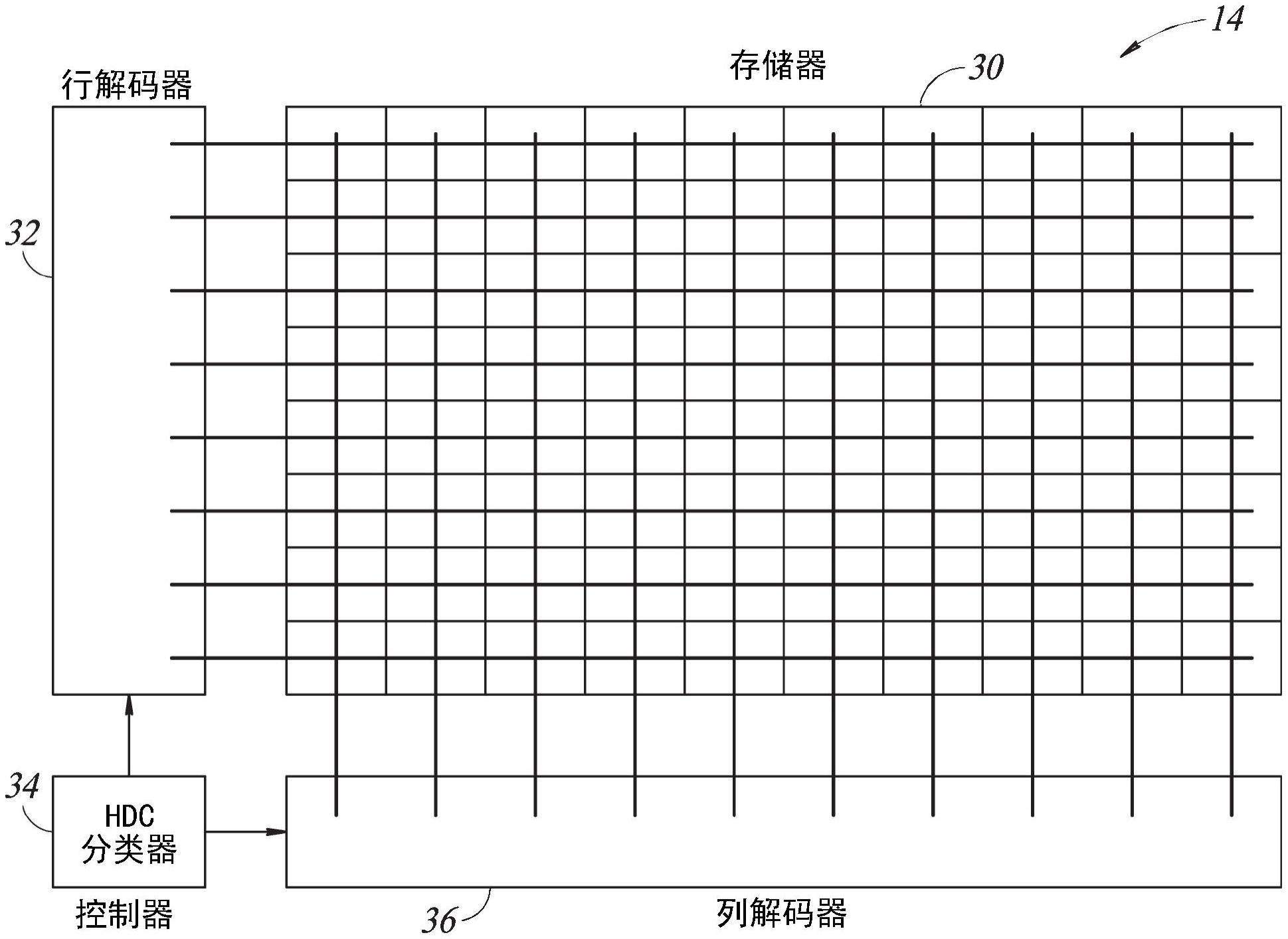
1、根据本发明的优选实施例,提供了一种用于经由超维计算在感兴趣领域中进行n元组分类的系统,所述系统包括关联存储器阵列和控制器。所述关联存储器阵列将超维向量存储在所述阵列的行中。所述超维向量表示感兴趣领域中的符号,并且所述阵列包括沿所述阵列的位线的部分的位线处理器。所述控制器激活所述阵列的行以利用所述位线处理器对所述超维向量执行xnor、置换和相加操作,对其中具有n个符号的n元组进行编码,根据所述n元组生成所述感兴趣领域的一部分的指纹,将所述指纹存储在所述关联存储器阵列内,以及将输入序列与所存储的指纹之一进行匹配。
2、另外,根据本发明的优选实施例,所述感兴趣领域是音乐。
3、此外,根据本发明的优选实施例,所述控制器存储第一n元组的中间n元组结果,并生成后续n元组,所述后续n元组是根据其先前n元组的所述中间n元组结果生成的。
4、根据本发明的优选实施例,还提供了一种用于经由超维计算在感兴趣领域中进行n元组分类的方法。所述方法包括:将超维向量存储在关联存储器阵列的行中;以及激活所述阵列的行以利用所述位线处理器对所述超维向量执行xnor、置换和相加操作,对其中具有n个符号的n元组进行编码,其中n大于2,根据所述n元组生成所述感兴趣领域的一部分的指纹,将所述指纹存储在所述关联存储器阵列内,以及将输入序列与所存储的指纹之一进行匹配。
5、另外,根据本发明的优选实施例,所述方法包括:存储第一n元组的中间n元组结果,并生成后续n元组,所述后续n元组是根据其先前n元组的所述中间n元组结果生成的。
技术特征:
1.一种用于经由超维计算在感兴趣领域中进行n元组分类的系统,所述系统包括:
2.根据权利要求1所述的系统,其中,所述感兴趣领域是音乐。
3.根据权利要求1所述的系统,所述控制器用于存储第一n元组的中间n元组结果,并生成后续n元组,所述后续n元组是根据其先前n元组的所述中间n元组结果生成的。
4.一种用于经由超维计算在感兴趣领域中进行n元组分类的方法,所述方法包括:
5.根据权利要求4所述的方法,其中,所述感兴趣领域是音乐。
6.根据权利要求1所述的方法,并且包括存储第一n元组的中间n元组结果,并生成后续n元组,所述后续n元组是根据其先前n元组的所述中间n元组结果生成的。
技术总结
一种用于经由超维计算在感兴趣领域中进行N元组分类的系统包括关联存储器阵列和控制器。所述关联存储器阵列将超维向量存储在所述阵列的行中。所述超维向量表示所述感兴趣领域中的符号,并且所述阵列包括沿所述阵列的位线的部分的位线处理器。所述控制器激活所述阵列的行以利用所述位线处理器对所述超维向量执行XNOR、置换和相加操作,对其中具有N个符号的N元组进行编码,根据所述N元组生成所述感兴趣领域的一部分的指纹,将所述指纹存储在所述关联存储器阵列内,以及将输入序列与所存储的指纹之一进行匹配。
技术研发人员:D·伊兰,T·谢雷
受保护的技术使用者:GSI 科技公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!