具有输入/输出数据速率对齐的存储器部件的制作方法
具有输入/输出数据速率对齐的存储器部件
1.本技术是申请日为2017年07月07日、申请号为201780035329.3、发明名称为“具有输入/输出数据速率对齐的存储器部件”的发明专利申请的分案申请,原申请的全部内容通过引用结合在本技术中。
技术领域
2.本公开涉及集成电路数据存储。
附图说明
3.在附图的各图中借由示例而非限制的方式说明了在此所公开的各个实施例,以及其中相同的附图标记指代相同元件,以及其中:
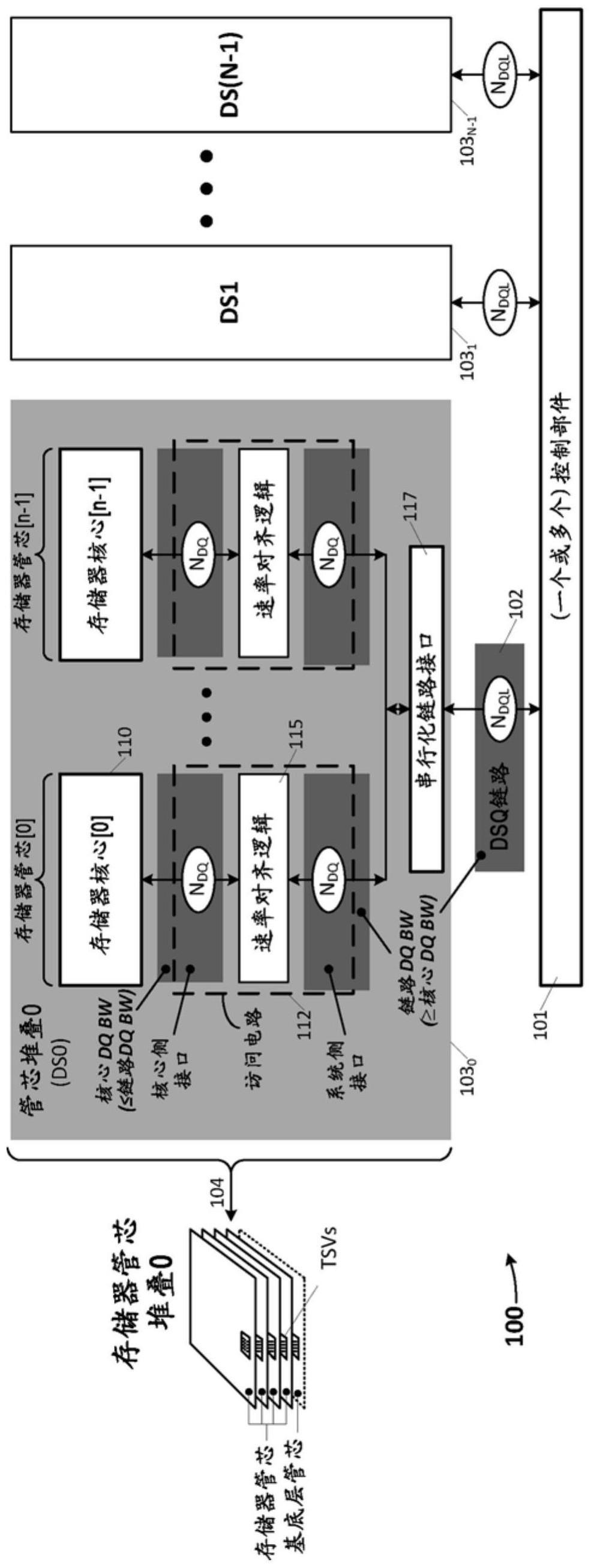
4.图1图示了示例性计算系统,其中一个或多个控制部件经由各自由许多数据链路和控制链路构成的多个信令信道102而耦合至存储器子系统;
5.图2对比了在具有不均匀存储器核心带宽的存储器管芯堆叠
‘
x’和
‘
y’内的示例性存储器访问操作;
6.图3图示了在图1的堆叠管芯存储器部件内的成员存储器管芯的实施例;
7.图4a、图4b和图4c图示了对于具有不同存储器核心速率的图3存储器部件的实例的示例性流水线存储器访问操作;
8.图5a和图5b图示了出站数据(读取数据)速率对齐逻辑及其操作的示例性实施方式;
9.图6a和图6b图示了入站数据(写入数据)速率对齐逻辑及其操作的示例性实施方式;
10.图7a图示了备选的速率对齐存储器部件实施例,其中相对于每个成员存储器管芯来异步地管理存储器核心和速率对齐逻辑,从而杠杆调节来自相应存储器核心的自定时信息以确定出站(读取)数据何时能够从给定存储器管芯获得;
11.图7b图示了在图7a的存储器管芯内的激活/读取操作的示例性对;
12.图7c图示了在图7a的存储器管芯内的激活/写入操作的示例性对;
13.图7d和图7e分别图示了在图7a的存储器管芯内的先读取后写入操作和先写入后读取操作,从而展示了在尽管存储器核心带宽较低的情况下的在链路接口的全带宽上的无争用数据传输;以及
14.图8图示了其中速率对齐逻辑替代于组接口而布置在tsv接口处的备选存储器管芯实施例。
具体实施方式
15.在此所公开的各个实施例中,存储器部件实施在它们相应的内部存储器核心与固定速率外部链路接口电路之间的数据速率转换,以使得具有非均匀存储器核心数据速率的存储器部件群体能够产生在外部信令链路的全带宽下的数据吞吐量。在许多实施例中,例
如,在多部件存储器子系统内的每个存储器部件包括多个存储器管芯,其中每个存储器管芯具有多个独立可访问的存储器组。关于每个存储器组提供速率对齐逻辑,以使得在尽管对给定组的存储器核心具有较低的带宽访问的情况下,能够在存储器部件的全外部接口速率(“链路接口”速率)下执行关于各个存储器组的数据输入/输出(i/o)。通过该操作,对相同存储器部件内不同存储器组(或相同存储器部件或不同存储器部件内的不同存储器管芯)的数据读取/写入访问可以在链路接口的全带宽下背对背执行而没有资源冲突。在其他实施例中,在给定存储器部件的链路接口处提供速率对齐逻辑并在部件的成员存储器组之中共用,以便可以关于相同存储器部件(或不同存储器部件)内不同存储器管芯来执行背对背数据读取/写入访问,从而实际上以减小的速率-对齐花销为代价将事务并发限制到存储器管芯级别(替代于更细粒度的组级别)。进一步地,可以与存储器核心的同步或异步操作结合而实施速率对齐逻辑,后者允许潜在地减小的访问等待时间和/或减小的定时开销。以下更详细讨论这些和其他特征和实施例。
16.图1图示了示例性计算系统,其中一个或多个控制部件(共同地101)经由多个信令信道102耦合至存储器子系统,每个信令信道102由许多数据链路(n
dql
)和控制链路(未具体示出)构成。控制部件101可以由任意数目的处理器核心和可选的开关电路实施,开关电路使得处理核心能够访问存储器子系统100内的任何和所有的成员存储器部件103
0-103
n-1
。
17.仍然参照图1,单独的存储器部件103
0-103
n-1
(统称作存储器部件103)由具有多个存储器管芯以及可选的基底层/缓冲管芯的相应的集成电路(ic)封装来实施。在104处所示的特定实施例以及以下所示和所述的其他示例中,存储器管芯和基底层管芯布置在三维(3d)管芯堆叠中并由硅通孔(tsv)互连。链路接口(未具体示出)实施在基底层管芯中并互连至n
dql
外部信令信道102的相应集合。在所有情况下,给定存储器部件的成员存储器管芯可以布置在备选的拓扑中(例如,一个或多个存储器管芯或存储器管芯群组与集成电路封装内的另一存储器管芯或存储器管芯群组相邻布置),并由引线接合、弯曲电缆、或者替代于tsv或除tsv之外的任何其他可实施互连技术来互连。此外,可以省略基底层(或缓冲器)管芯,并且链路接口替代地实施在多管芯封装的“主”存储器管芯上。在该情况下,该主存储器管芯可以不同于在多个管芯封装中的其他“副”管芯而实施(例如,主存储器管芯具有链路接口和基底层管芯的其他电路,而副存储器管芯省略了这种电路),或者所有存储器管芯可以等同地实施,其中链路接口在副存储器管芯上被禁用。
18.现在参照堆叠管芯存储器部件1030的详细视图,给定管芯堆叠(或其他多管芯封装)内
‘
n’个存储器管芯的每一个存储器管芯包括由许多核心数据线(n
dq
)和核心控制信号线(未具体示出)互连的相应的存储器核心110和访问电路112。每个存储器管芯内的访问电路包括由tsv和/或其他互连来耦合至如上所讨论的基底层管芯或主存储器管芯上的共用链路接口的系统侧接口(与由核心数据线和控制线所形成的核心侧接口相对比)。在所示的实施例中,每个存储器管芯内的访问电路112包括速率对齐逻辑115,其按需提升(加速)传出(读取)数据速率以及减小(降低)传入(写入)数据速率,以在系统侧接口处模仿或模拟可操作在与外部存储器链路102的数据传输带宽匹配的数据传输带宽下的存储器核心,因此使得核心侧数据速率(也即在存储器核心与速率对齐逻辑115之间的峰值数据传输速率)能够小于或等于系统侧数据速率。因此,即使在给定管芯堆叠内存储器核心的数据传输带宽本质上低于链路接口带宽的情况下,速率对齐逻辑使得对于有限的时间突发而言,存储器
核心的数据速率等于链路接口的数据速率。通过该操作以及通过在存储器管芯堆叠(也即如下所述的存储器核心内不同存储器组和/或不同存储器核心)内插入到同时可访问资源的存储器访问,可以在链路接口的全带宽下执行关于给定存储器管芯堆叠的数据传输(并且因此处于由链路102所形成的外部信令信道的全速率下并控制与其相连的部件接口),尽管存储器核心带宽低于链路带宽。此外,具有数十、数百或更多的多管芯存储器部件103和外部信令链路102的相应集合的相对更大的存储器子系统(例如,96个存储器管芯堆叠,每个存储器管芯堆叠经由n
dql
信令链路的相应集合而耦合至(一个或多个)控制部件101,并且每个堆叠具有四个、八个或更多个成员存储器管芯)可以操作在全外部链路信令带宽下,尽管管芯之间或者存储器部件之间的核心带宽不均匀。该操作是特别有益的,其中外部链路带宽固定在控制部件域处(例如,控制部件工作在亚低温下,其中量化的功率输送在(一个或多个)控制部件内建立了均匀且不容易可调节的时域)。
19.图2对比了在具有非均匀存储器核心带宽的存储器管芯堆叠
‘
x’和
‘
y’内的示例性存储器访问操作131和133。在所示的特定示例中,管芯堆叠x内的存储器管芯带宽仅是外部链路带宽的一半,而管芯堆叠y的核心比管芯堆叠x核心快一倍并且因此与外部链路带宽匹配。此外,在备选实施例中,当x和y管芯堆叠存储器核心(和以下所述其他存储器核心)假设为通过连续行(激活)和列访问(读取或写入)操作而访问的动态随机访问存储器(dram)时,存储器核心可以在所有情况下由任何存储器技术(或存储器技术的组合)而实施,包括例如但不限于,各种类型的静态随机访问存储器(sram)核心和非易失性存储器核心(例如闪存存储器核心)。
20.首先参照图131,响应于经由命令/地址链路(图1中未具体示出)所传递的控制信号(包括命令和地址)而在管芯堆叠x内执行存储器读取访问的序列。更具体地,在141处接收到指向管芯堆叠x内第一存储器核心的行激活命令/列读取命令(注意可以在时间上分立且顺序地接收行激活和列读取命令,或者如图所示在统一的命令传输中接收行激活和列读取命令),以及在161处接收到指向相同管芯堆叠内另一存储器管芯的另一行激活命令/列读取命令。每个行激活/列读取命令触发了相应的行访问143、163(例如,行激活,其中存储单元的行地址所选择的行的内容被传输至感测放大器组以形成数据的打开“页面”),接着是列访问操作145、165(例如,每个列访问从感测放大器组内的打开页面读取数据的列地址所选择的列)的相应对,其中通过访问电路将相应数据列(qa/qb)传输至链路接口,并随后在该链路接口中串行化以用于在外部信令链路147、167上传输。如图所示,在146和166处,在核心dq线上的数据传输(例如,从存储器核心至访问电路)花费了两倍于在外部信令链路上的对应的数据传输147和167的时间——这是由管芯堆叠x内的速率对齐逻辑所实现的数据速率增大(在该示例中速率倍增)的结果。也即,参照图1,在速率对齐逻辑的系统侧上(也即在将给定存储器管芯连接至链路接口的ndq链路上)的数据速率与外部信令链路上的数据速率匹配,并且是在核心侧数据线(也即耦合在速率对齐逻辑与存储器核心之间的ndq线)上的数据速率的两倍。
21.现在参照在管芯堆叠y内所示的存储器访问序列(即,图133),命令并执行了两个相同的存储器访问事务,但是以管芯堆叠x的核心数据速率的两倍的速率。因此,关于每个存储器访问的行激活操作花费时间明显少于在管芯堆叠x中(例如长度为在管芯堆叠x中的一半,尽管由于核心速率独立定时延迟而稍微多于管芯堆叠x的激活时间的一半),并且对
于每个存储器访问的列读取操作花费时间为在管芯堆叠x中的一半,从而匹配了外部链路数据路径的全速率。
22.参照图1和图2并且与管芯堆叠x和管芯堆叠y存储器访问事务对比,外部链路数据传输以相同的“链路”数据速率发生,并且因此除了由于半速率管芯堆叠x存储器核心而导致的更长的总管芯堆叠x访问等待时间(也即,在管芯堆叠与外部信令链路之间接口处读取数据输出的行激活命令的开始与到达之间的时延)之外,从(一个或多个)控制部件101的角度反映了相同的数据吞吐量。因此,使得(一个或多个)控制部件101能够以均匀、固定的外部链路数据速率从各个管芯堆叠接收读取数据,但是该外部链路数据速率具有根据管芯堆叠经受给定访问或访问序列的核心速率的变化的等待时间。在一个实施例中,例如,(一个或多个)控制部件101关于每个存储器管芯堆叠执行训练序列以查明读取时延(可以假设写入时延从主机角度是均匀的,即使内部数据写入操作可以在更慢核心管芯堆叠中花费更长),从而在寄存器/查找表内记录对于每个管芯堆叠的读取时延值,以及此后应用读取等待时间值以确定对于从给定存储器管芯堆叠请求的读取数据的数据接收时间。在其他实施例中,可以通过询问关于单个管芯堆叠或管芯堆叠群组所提供的一个或多个非易失性存储器元件而查明对于单独的存储器管芯堆叠(例如,如在串行存在检测(spd)存储器中)的读取等待时间,其中同样在运行时间可访问寄存器或查找表存储器内记录读取等待时间以确定管芯堆叠专用的读取数据接收定时。在任一情况下,(一个或多个)控制部件可以通过根据预先确定的或运行时间确定的数目定时事件(例如时钟信号转变)延迟读取数据接收而对管芯堆叠专用等待时间负责,其是存储器部件专用的并且与在外部信令链路102之上数据传输同步。
23.图3图示了在图1的堆叠管芯存储器部件内的成员存储器管芯180的实施例。在所示的示例中,存储器管芯180包括耦合至tsv接口183的多个存储器组181
0-181
n-1
(每个统称作组180并且具有组接口和核心存储阵列),其中tsv接口自身由tsv 185耦合至在基底层管芯或主存储器部件(其可以是存储器管芯180的一部分)上的链路接口187。更具体地,tsv接口183通过许多(n
ca
)命令/地址信号线而从链路接口接收命令/地址信号,并通过读取数据线(nd)和写入数据线(nd)的相应集合来输出数据,所有这些线直接或间接地耦合至在链路接口内的配对的信号接收器191、193和输出驱动器195。通常,tsv接口187内的信令速率以预先确定的串行化/去串行化因子而慢于配对的外部信令链路的信令速率,其中tsv接口的带宽借由增大的信号线计数而与外部信令链路的带宽匹配。在一个实施例中,例如,每个外部信令链路以10gb/s(每秒10吉比)传递信息(通过q
l
链路的命令/地址/控制信号,通过ca
l
链路的读取数据信号,通过dl链路的写入数据信号),而tsv接口183与链路接口187之间的每个信号线以及tsv接口183与存储器组181之间的每个信号线以0.25gb/s传递信息(在以下示例中向前携带的示例性传输速率,尽管在所有情况下可以应用更高或更低的速率)。因此,为了将tsv接口的带宽与外部信令链路的带宽均等化,实施40:1的信号线比率(即,对于每个外部信令链路而言,40个信号线进入并离开tsv接口183),以及在链路接口187内提供串行化/去串行化电路以串行化传出的数据(即,串行器201将来自40个tsv连接的信号线中的每一个信号线的相应位复用为在外部信号链路上的40位间隔的突发)并且去串行化传入的数据(去串行器203和205将来自40位串行突发信号的相应位解复用为在相应tsv连接的信号线上的40位的并行集合)。tsv接口183也接收或得到(例如通过分频)一个或多个接口
定时信号(其根据最大核心时钟速率或其倍数(并且因此在该示例中在0.25ghz下或更高)而循环),将接口定时信号传递至存储器组181,以及同样将数据时钟传至tsv接口的入站寄存器209、211和出站寄存器215中。
24.如关于存储器组181i所示,存储器组181的每一个存储器组包括存储器组“核心”211和组接口223,其中后者耦合在核心与tsv接口183之间。在一个实施例中,每个组接口223包括命令/地址(ca)逻辑,其将行和列控制信号以及对应的行和列地址同步发送至组核心(和其中的存储阵列),以执行如由经由tsv接口183到达的命令/地址信息来信号通知的行激活、列访问(读取和写入)、预充和维持操作。输入的命令/地址信息也可以包括各种控制和定时信号,包括例如且不限于,芯片选择信息(例如,为了使得存储器管芯能够确定是否关于其核心存储阵列的一个或多个核心存储阵列来执行所请求的行、列或维护操作,或者请求是否指向不同的存储器管芯),前述的接口定时信号,时钟使能信号,总线翻转控制信号,校准控制信号,错误代码(检测/纠正)信号等等。
25.仍然参照图3,每个组接口223也包括速率对齐逻辑229,其按需复用/串行化出站数据(提高出站数据速率)以及解复用/去串行化入站数据(降低入站数据速率),以使得较慢的核心存储阵列能够在链路接口的全带宽下关于tsv接口183(并因此关于链路接口185)传输数据。更具体地,速率对齐逻辑229根据核心存储阵列和tsv接口的相对带宽来操作,以将相对长的核心数据检索间隔压缩成更短的读取数据突发间隔、并相反地将相对压缩的写入数据突发根据核心定时约束而扩展成更长的核心写入间隔。在以下更详细讨论的一个实施方式中,速率对齐逻辑229包括以足够坚决(resolute)的时钟速率(例如比tsv接口的时钟速率更快)来操作的状态机,以缓冲用于临时压缩的突发输出的出站读取数据,并且缓冲用于至核心存储阵列的临时扩展的输出的入站写入数据(例如,按需在核心存储阵列的开放页面内覆盖数据的列)。如图所示,也将供应给同步命令/地址逻辑227的命令/地址信号或至少其子集提供给速率对齐逻辑229,以使得速率对齐逻辑能够确定何时将在给定方向上发生数据传输、以及何时相应地执行缓冲/速率增大或缓冲/速率降低。供应给速率对齐逻辑的命令/地址信号可以包括上述接口定时信号,该接口定时信号包括用于时钟控制有限状态机或在速率对齐逻辑内的其他控制电路的一个或多个定时/时钟信号。
26.图3的实施例中的每个存储器组内的专用速率对齐逻辑229和/或命令/地址逻辑227使得能够以在tsv接口和外部信令链路的全带宽下产生连续数据传输的速率来流水线进行指向不同组的存储器访问事务,尽管具有潜在地更慢的存储器核心。图4a、图4b和图4c图示了对于不同存储器核心速率的该流水线操作,包括分别在全速率、半速率和2/3速率存储器核心的上下文中重叠由专用组资源(命令/地址和速率对齐逻辑)所使能的组访问操作。首先参照图4a的全速率存储器核心示例(即,250mb/s存储器核心以40:1读取数据串行化而接口至10gb/s链路的集合),在281处所示的初始控制器感知的4纳秒(ns)的“核心循环”期间在外部链路接口内接收到的激活/读取命令,在下一个核心循环(283)期间被存储在tsv接口寄存器内、并且随后在一个核心循环之后(285)被存储在组接口内的寄存器内,从而实际上在连续的核心循环中从外部链路传播至tsv接口并传播至组接口。在激活/读取命令到达对应的组接口处之后的核心循环中,在所选择存储器管芯的地址专用组内开始行激活操作287,并且在该示例中,该行激活操作在关于现在所激活存储器行(即,现在打开的存储器页面)的地址专用列而开始背对背列读取操作289、291之前延伸10ns。在所示的实施
例以及以下所展示的其他示例中,产生后续存储器读取操作的列读取命令和列地址在初始激活/读取ca信号中传递(例如,在281处所示的命令/地址信息的量(或数据包或块或其他单元)内),尽管可以备选地在不同时间(例如,在接收到激活命令和地址之后的预先确定的时间)提供列命令和地址。在任何情况下,在289处以及再一次在291处应用列地址使得读取数据能够分别再次在291处从所选择组的存储器核心输出,其中在链路接口内被串行化并被驱动至301处的外部信令链路上之前,列读取数据通过组接口(297)和tsv接口(299)内的相应寄存器传播。因为存储器核心以控制器感知的核心循环时间操作(即,以每个核心数据线250mb/s操作并因此以每个外部信令链路10gb/s操作),来自组的4ns数据输出时间和接口内的存储时间与tsv接口内的4ns数据存储间隔和通过外部信令链路的4ns数据突发时间匹配。此外,即使对于给定激活/读取操作的10ns行访问(激活)间隔超过组合的8ns数据输出时间背对背列读取数据传输,在分离组中行激活操作的执行也避免资源冲突——即,同时地(至少时间上部分重叠)执行两个行激活以在链路接口处维持连续(背对背无延迟)的列数据输出。因此,在311处将连续的激活/读取命令发出至不同的组(具有由阴影所指示的对应/后续流水线事件)产生了与在281处激活/读取命令相同的流水线简档,其中在两个不同组中具有时间上重叠的行激活操作,但是穿过tsv接口并通过外部信令链路具有离散(非重叠)4ns流水线阶段的顺序和连续的数据传输。
27.现在参照图4b的半速率存储器核心示例(即,被接口至具有相同40:1读取数据串行化的10gb/s链路的集合的125mb/s存储器核心),如在图4a中,在331处的初始控制器感知的4ns的“核心循环”(即,4ns流水线阶段)期间在外部链路接口内接收到并存储的激活/读取命令,在随后的流水线阶段333期间被存储在在tsv接口寄存器内、并且随后在一个流水线阶段之后335被存储在组接口内的寄存器内。此外,与之前一样,激活/读取命令在337处触发了在地址专用行和存储器族内的行激活,接着是一对列读取操作339、341。然而,因为减小的核心速率,行激活操作花费时间明显比在全速率核心示例中花费更长时间(16ns vs图4a中的10ns),并且每个列访问操作花费时间为在全速率核心中的两倍(每个列访问8ns,而不是4ns)。不论它们扩展的持续时间如何,这些组级别的行和列操作可以在整个操作流水线内重叠(即,由于其中专用的组资源和并行操作),因此在331和361处接收的、并且指向相应存储器组的激活/读取命令,在8ns列数据传输间隔(例如,343、345)在组接口的系统侧处被压缩(即,由速率对齐逻辑)之前触发了时间上重叠的、时间交错的行激活和列访问操作对,以使能通过tsv接口(349)和链路接口(351)来发送来自组接口(347)的系统侧的流水线的、非冲突的数据输送。然而,延长的行访问和列访问时间并非没有影响,因为整体读取时延(即,从在331处接收激活/读取命令至在351处开始输出数据至外部链路上)相应地增长—在该示例中以关于图4a中全速率核心的时延的14ns增长(即,对于行访问的附加6ns以及对于列访问的附加8ns)。的确,如以下进一步详述,速率对齐逻辑根据在链路接口处维持不间断输出所需的时延而建立了读取数据输出时间。因此,执行并发组访问以关于尽管具有延长的等待时间的、在全外部链路数据速率下的慢核心存储器管芯来维持数据吞吐量。
28.图4c图示了另一部分速率核心示例——在该情况下具有为250gb/s全核心速率的三分之二(2/3)、也即167gb/s的存储器核心速率——以展示在上角部(100%)与下角部(50%)情况之间的可容许核心速率的相对连续范围。如图4a和图4b中所示,在初始控制器感知的4ns核心循环(流水线阶段381)期间在链路接口内接收并存储的激活/读取命令,在
后续流水线阶段期间被存储在tsv接口寄存器内、并随后在一个流水线阶段之后被存储在组接口内的寄存器内。与其他核心速率一样,激活/读取命令触发了在地址专用行和存储器组内的行激活,接着是列读取操作对。然而,由于小于全存储器核心速率,行激活操作费时显著长于全速率核心示例(14ns vs图4a中的10ns),并且列访问操作费时近似比全速率核心长50%(每个列访问6ns,而不是4ns)。如在图4b的半速率核心示例中所述,这些组级别的行和列操作在整个事务流水线内重叠,其中每个激活/读取命令指向相应的存储器组,该相应的存储器组在列数据传输间隔在组接口的系统侧处被压缩以及tsv接口和链路接口内的连续流水线阶段之前触发了在偶数流水线阶段间隔(即,两个4ns流水线阶段间隔并因此在所示的示例中为8ns)上的时间交错的行激活和列访问操作。整体读取时延(即,从在381处接收激活/读取命令至在401处开始输出数据至外部链路上)根据延长的行和列操作时间而增长——在该示例中关于图4a中全速率核心的等待时间增长8ns(即,对于行访问的附加4ns以及对于两个列访问中的每一个列访问的附加2ns)。与在半速率情况下一样,执行并发的行访问,以在全核心数据速率下维持较慢核心存储器管芯的控制侧吞吐量、并且速率对齐逻辑根据在链路接口处维持不间断全速率输出所需的等待时间而建立读取数据输出时间。
29.图5a和图5b图示了出站数据(读取数据)速率对齐逻辑420及其操作的示例性实施方式。首先参照图5a,速率对齐逻辑420以落在预先定义的最小与最大(全核心)速率之间的任何速率处的数据速率来从可变速率域(例如,在图3的实施例中的存储器核心)读取数据,并且以全核心数据速率输出数据至速率已对齐域。因此,“可变速率域”指代具有任意地落在最小与最大(全核心)数据速率之间的标称固定数据速率(即,不考虑例如由于电压/温度变化引起的变化)的时间域。
30.仍然参照图5a,速率对齐逻辑420包括用以交替地缓冲核心供应的读取数据的一对寄存器421和420(r0,r1),用以交替地选择寄存器421和423以发源传出读取数据的复用器425,以及响应于命令/地址流(ca)内的传入命令和接口速率比(irr)数值、以将读取数据加载到寄存器421、423中并控制复用器425的输出选择的有限状态机427(fsm)。有限状态机427也接收作为命令/地址信号的一部分或者命令/地址信号之外的信号的控制时钟信号,其以两倍于全速率核心循环时间振荡并且因此在所示的示例中具有2ns循环时间(500mhz),尽管可以使用更快或更慢的控制时钟。图5b图示了速率对齐逻辑420关于控制时钟(ck)的示例性操作,包括对于图4a-图4c中所示三个示例性核心时钟速率的每一个核心时钟速率(即,如图4a中的全核心速率,如图4c中的2/3的速率,以及如图4b中的一半速率)而言的寄存器加载信号(lr0,lr1)和由有限状态机427发出的复用器控制信号(sel)的定时。在451处的全速率(250mhz)核心示例中,有限状态机在可变速率核心数据输出的4ns(全速率列循环时间,t
cc
)数据有效间隔的中点处断言寄存器加载信号lr0和lr1,因此在时钟中连续地将输出数据位
‘
a0’和
‘
a1’加载至寄存器r0和r1中。复用器选择信号“sel”在r0加载操作之后的4ns流水线阶段间隔期间升高,以及随后在r1加载操作之后的后续4ns流水线阶段期间降低,从而以全核心速率在速率对齐域内输出a0和a1读取数据位。注意,尽管描述了流过速率对齐逻辑的数据位流,速率对齐电路可以按需包括用于尽可能多的位道的寄存器和复用电路,以满足对象接口宽度。
31.仍旧参照图5b,在453处所示的2/3速率核心示例(即,具有6ns列循环时间)中,有
限状态机427在核心数据位输出之后(a0和a1)的相应控制时钟循环开始处断言寄存器加载信号lr0和lr1。尽管a0数据位的相对早的可用性,有限状态机推迟(延迟)将a0数据位复用至速率已对齐接口上直至时间461,时间461对于与全核心速率(即,控制部件感知的250mb/s核心速率)相对应的相应间隔而言允许将a0和a1数据位背对背输出至速率已对齐接口(即,q
rac
)上,从而按需添加时延至a0位输出,以在速率已对齐域内将输出位压缩成背对背全核心速率传输间隔(4ns)。在455处所示的半速率核心示例(也即t
cc
=8ns)中,有限状态机427类似地在核心数据位之后的控制时钟边沿处断言寄存器加载信号,并且随后将a0数据位延迟复用至比在2/3示例中的更大程度(即,直至467,并且因此替延迟两个核心时钟循环而不是一个),以在全核心速率下在速率已对齐接口处产生a0和a1读取数据位的背对背输出。
32.图6a和图6b图示了入站数据(写入数据)速率对齐逻辑480及其操作的示例性实施方式。如在以上所讨论的实施例中,入站数据速率对齐逻辑480可以与出站数据速率对齐逻辑共同耦合至双向数据路径(即,在不同时间通过相同输入/输出(i/o)路径传播的读取和写入数据),或者可以提供专用的读取和写入数据路径。在任一情况下,入站数据速率对齐逻辑包括入站寄存器对481、483、复用器485、以及有限状态机487(其可以由如上关于出站数据速率对齐逻辑420所讨论的相同寄存器、复用器和/或状态机来实施),并且执行了基本上为出站数据速率对齐逻辑的相反操作——按需扩展传入写入数据位的数据有效间隔、以满足较慢核心存储器管芯中的核心数据速率(比较图6b中所示的4ns、6ns和8ns的t
cc
间隔)。
33.如图5b和图6b所展示,控制时钟频率建立了速率对齐逻辑,以据此区分不同存储器核心速率的粒度(分辨率)——控制时钟越快,可区分定时情景的数目以及可向控制部件报告(即,可向如图1中所示的部件101报告)的对应读取时延定时点就越多。因为更快的控制时钟通常要求更大的功耗,因此根据可用的功率预算的在给定计算系统中的时延粒度可能受损(即,受约束或受限)。图7a图示了备选的速率已对齐存储器部件的实施例500,其中关于每个成员存储器管芯异步地管理存储器核心和速率对齐逻辑,从而杠杆调节来自相应存储器核心的自定时信息,以确定出站(读取)数据何时从给定存储器管芯可用、并因此实现最低可能输出等待时间而并未抬高功耗。在所示的示例性实施方式中,在链路接口内提供有限状态机501,以根据传入的命令/控制信号(nc)而将行地址选通(ras)和列地址选通(cas)信号发送至管芯堆叠内的每个存储器管芯(即,“mem 0”、“mem 1
”…
),从而将传出的ras和cas信号与芯片选择信号(cs)配对、以使能存储器管芯中所选择的存储器管芯执行信号通知的行或列操作。参照存储器管芯0(“mem 0”)的细节图,去串行化的行地址信号和列地址信号被路由至用于每个存储器组(“bank”)的行地址和列地址解码逻辑块(521、523),其中ras和cas信号分别顺序地触发核心存储阵列内的行激活以及感测放大器组内的列读取/写入操作(包括将行和列地址选通至寄存器522和524中)。如图所示,cas信号附加地在列写入操作中将写入数据选通至寄存器527中。
34.仍然参照图7a,来自存储器核心的自定时信号(例如,从异步定时链输出的信号,该异步定时链模拟或逼近延迟和/或复制在核心存储阵列和感测放大器组内的电路和信令路径)被提供至如先进先出(fifo)缓冲器而操作的读出存储器530。因此,在存储器读取操作期间,只要读取数据变为可用,该读取数据就被推送至fifo 530中,从而推进加载指针(“ld ptr”)以标记下一个可用的fifo缓冲器存储元件。有限状态机501维持指向fifo第一
存储元件的读取指针(“rd ptr”)、以在列读取操作期间供应数据至链路接口,并推进读取指针至fifo存储元件,该fifo存储元件在链路接口内(也即在出站数据串行器541内)已经串行化了来自第一存储元件的数据、并且经由外部信令链路从存储器部件输出之后,向链路接口供应数据。通过该异步核心管理和fifo加载,可以调节存储器核心速率的连续范围(例如,根据fifo深度在预先定义的最小与最大速率之间)而并不要求在组接口内的高分辨率时钟控制。此外,因为在由自定时存储器核心所指示的时刻处在fifo 530内可用读取数据,所以可以根据对象存储器核心速率而最小化读出时延。
35.图7b图示了在图7a的存储器管芯内的激活/读取操作的示例性对。如图所示,指向两个不同存储器组(在给定存储器部件的相同或不同存储器管芯上)的激活/读取命令经由外部命令/地址链路(ca l)而在背对背4ns流水线阶段间隔中到达,并且在后续流水线阶段期间在有限状态机(即,图7a的元件501)内被去串行化并被捕捉。有限状态机通过将ras信号(ras t)和对应的行地址信号(ra t)一个接一个地发出至相应存储器组(即,由伴随激活/读取命令的组地址所指定)而对传入的激活/读取命令做出响应。ras信号在芯片所选择存储器管芯和组地址指定组的行地址寄存器内断言行地址捕捉(“rowadr”),接着是在相应组内的行访问/激活操作(“row acc”)的开始。为了示例的目的,假设两个存储器组呈现不同的定时特性(如可以是在相同存储器管芯内、不同的存储器管芯内以及不同存储器部件内的组之间的情况)。在示例性的14ns ras至cas延迟(trcd)之后,有限状态机发送cas信号的序列,以锁存在地址所选择组的列地址寄存器内的列地址,并且触发列访问操作(ca dec1,ca dec2)。在组专用、自定时的列访问间隔经过(即,tca1,tca2)之后,将与列访问中的每个列访问相对应的数据加载至目标存储器组的相应读取数据fifos中(rd fifo 11,rd fifo 12),并且推进加载指针以标识每个存储器组中的下一个将加载的fifo元件。在一个实施例中,在fifo加载操作之后(例如,根据指定的或根据运行时间所确定的组访问时间的固定时间,或者响应于fifo加载操作的通知),有限状态机卸载fifo预先确定的时间,从而在链路接口(图7a的元件541)内在读取数据串行器的寄存器内连续从组中的每个组捕捉存储器读取数据,并随后驱动读取数据至外部信令链路上。因此,如在图3-图6b的实施例中,尽管存储器子系统的一个或多个存储器部件(或存储器管芯或存储器组)中存储器核心带宽较低,基于fifo的速率对齐逻辑使能在链路接口的全带宽下的数据传输。
36.图7c图示了图7a的存储器管芯内的激活/写入操作的示例性对。在该情况下,指向两个不同存储器组(在给定存储器部件的相同或不同存储器管芯上)的激活/写入命令经由外部命令/地址链路(ca 1)而以背对背4ns流水线阶段间隔到达,并且在后续流水线阶段期间在有限状态机(即,图7a的元件501)内被去串行化并被捕捉。有限状态机通过将ras信号(ras t)和对应的行地址信号(ra t)一个接一个地发出至相应存储器组(即,由伴随激活/读取命令的组地址所指定)而对传入的激活/写入命令做出响应。ras信号断言使能在芯片选择的存储器管芯和组地址指定的组的行地址寄存器内的行地址捕捉("rowadr"),接着开始在相应组内的行访问/激活操作("row acc")。如在以上示例中,假设两个存储器组呈现不同的定时特性,如可以是在相同存储器管芯内、不同存储器管芯内以及不同存储器部件内的组之间的情况。在示例性的14ns trcd间隔之后,有限状态机发出cas信号的序列,以锁存在地址选择的组的列地址寄存器内的列地址,并且触发列访问操作(ca decl,ca dec2)。在组专用、自定时的列访问间隔经过之后(即,tcal,tca2),将经由链路接口和tsv接口接收
的、具有与列访问中的每个列访问相对应的在wr 1和wr t处所示定时(即,在链路接口的全带宽下)的写入数据被加载至目标存储器组的相应写入寄存器中(wr regl,wr reg2),并且被写入至在由激活写入命令内所接收的相应列地址所建立的列偏移处的开放存储器页面。因此,尽管在存储器子系统的一个或多个存储器部件(或存储器管芯或存储器组)中存储器核心带宽较低,写入路径速率对齐逻辑使能在链路接口的全带宽下的写入数据传输。图7d和图7e类似地分别图示了在图7a的存储器管芯内不同组(即,混合了图7b和图7c中所示的操作)中的先读取后写入操作和先写入后读取操作,从而展示了:尽管在存储器子系统的一个或多个存储器部件(或存储器管芯或存储器组)中存储器核心带宽较低,在链路接口的全带宽下无争用的数据传输。
37.图8说明了备选的存储器管芯实施例601,其中速率对齐逻辑603(其可以是如图7a和图7b中的fifo实施方式)替代于在组接口中而被设置在tsv接口处(例如,将图3实施例的寄存器209、215替代地设置在组接口内609、615处),从而实际上减小了速率对齐逻辑的实例的数目(每个管芯一个实例,而不是每个组一个实例),这以关于并发操作减小粒度为代价。即,因为速率对齐逻辑603的核心侧以存储器核心速率接收并输出数据(并且因此可能比全链路接口速率更慢),以其他方式的在不同存储器组内时间上重叠的操作将在数据分布线q
x
、d
x
上冲突,因此限制了在速率对齐逻辑的系统侧上以及因此在不同存储器管芯内的并发操作。另外,在具有八个、十六个或更多存储器管芯的堆叠的存储器部件中,在不具有每个组接口内的速率对齐电路的开销的情况下,操作并发性可以足够关于链路接口(以及终点控制部件)来维持峰值数据传输速率。
38.应该注意,在此所公开的各个电路可以按照它们的行为、寄存器传输、逻辑部件、晶体管、布局几何结构、和/或其他特性,使用计算机辅助设计工具描述并表达(或表示)作为具体化在各个计算机可读媒介中的数据和/或指令。其中可以实施该电路表达的文件和其他对象的格式的计算机可读介质包括但不限于各种形式的计算机存储介质(例如光学、磁性或半导体存储介质,不论是否以该方式独立地分布,或被“原位(in situ)”存储在操作系统中)。
39.当经由一个或多个计算机可读介质在计算机系统内接收时,上述电路的这种基于数据和/或指令的表达可以由计算机系统内的处理实体(例如,一个或多个处理器)结合一个或多个其他计算机程序的执行而被处理,计算机程序包括但不限于网表生成程序、布图和布线程序等,用以生成这种电路的物理表现的表示或图像。该表示或图像可以此后用于器件制造,例如通过使能生成用于在器件制造工艺中形成电路的各个部件的一个或多个掩模。
40.在前述说明书和附图中,已经阐述了具体术语和附图符号以提供对于所公开实施例的全面理解。在一些情形中,术语和符号可以暗示不要求用以实践那些实施例的具体细节。例如,任意的特定电压、像素阵列尺寸、信号路径宽度、信令或操作频率、部件电路或器件等等可以不同于在备选实施例中以上所述的那些。附加地,集成电路器件或者内部电路元件或块之间的链路或其他互连可以示出为总线或单个信号线。总线中的每个总线可以备选地是单个信号线,并且信号线中的每个信号线可以备选地是总线。无论何种方式示出或描述的信号和信令链路可以是单端或差分的。无论何种方式示出或描述的定时边沿可以在备选实施例中具有上升边沿和/或下降边沿敏感度,并且有效高或有效低逻辑电平可以与
所示那些相反。当信号驱动电路断言(或去断言,如果由上下文明确陈述或指示)了在耦合在信号驱动与信号接收电路之间的信号线上的信号时,信号驱动电路被称作“输出”信号至信号接收电路。术语“耦合”在此用于表示直接连接以及通过一个或多个介入电路或结构的连接。集成电路器件“编程”可以包括例如但不限于,响应于主机指令(并因此控制器件的操作方面和/或建立器件配置)或通过一次性编程操作(例如,在器件制造期间吹断配置电路内的熔丝)加载控制值至集成电路内的寄存器或其他存储电路中,和/或将器件的一个或多个所选择管脚或其他接触结构连接至参考电压线(也称作跨接)以建立器件的特定器件配置或操作方面。如应用于辐射的术语“光”不限于可见光,并且当用于描述传感器功能时意在应用于特定像素构造(包括任何对应的滤波器)对其敏感的波段。术语“示例性”和“实施例”用于表示示例而非优选或要求。此外,术语“可以”(“may”和“can”)可互换地使用以标志可选的(可容许的)主题。任一术语的缺失不应理解为意味着需要给定的特征或技术。
41.可以在不脱离本公开的更宽阔精神和范围的情况下对在此所展示的实施例做出各种修改和改变。例如,任意实施例的特征或特征方面可以与任意其他实施例组合或者替代其配对特征或特征方面而被应用。因此,说明书和附图应该视作是示意性而非限制性的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1