机械学习装置以及线圈通电加热装置的制作方法
本发明涉及机械学习装置以及包括这样的机械学习装置的线圈通电加热装置。
背景技术:
通过卷线机形成的一个单元线圈50(以下,有时简单地称为“线圈”)如图5A所示被插入到定子60的一个齿部。然后,如图5B所示,多个单元线圈50插入配置于定子60的多个齿部。
图6A以及图6B是单元线圈的局部剖视放大图。如图6A所示,为了对单元线圈的形状进行整形,加热熔融性粘接剂3预先涂布于卷线2(请参照日本特开2005-71644号公报、日本特开2002-231552号公报、日本特开平7-50218号公报、以及日本特开2002-358836号公报)。然后,在对单元线圈进行了卷曲之后,对卷线2进行通电来加热(通电加热)。结果,如图6B所示,加热熔融性粘接剂3熔融而形成围绕多个卷线2的层3a,相邻的线圈彼此粘接。
但是,在通电造成的卷线2的加热不足时,加热熔融粘接剂3的粘接性降低,由此,单元线圈松动。此外,在因通电造成卷线2被过度加热时,加热熔融粘接剂3烧焦,难以呈现出粘接性。此外,需要操作员试错而通过手动来给予这样的动作条件,因此花费工作量和工时。
技术实现要素:
本发明是鉴于上述的情况而完成的,其目的在于提供一种不需要通过手动给予细微的动作条件就能够适当地对线圈进行通电加热的机械学习装置、以及具有这样的机械学习装置的线圈通电加热装置。
为了达成上述目的,根据第一发明,提供一种机械学习装置,其能够与线圈通电加热部进行通信,并学习通过该线圈通电加热部对线圈通电加热的动作,所述机械学习装置具有:状态观测部,其对状态变量进行观测,其中,该状态变量由通过所述线圈通电加热部通电加热了的所述线圈的粘接状态、绝缘耐压、通电加热时温度、通电加热时间实际值中的至少一个,以及所述线圈通电加热部中的通电加热时间指令值、电压、电流中的至少一个构成;以及学习部,其将由所述状态观测部观测到的所述线圈的粘接状态、绝缘耐压、通电加热时温度、通电加热时间实际值中的至少一个,以及由所述状态观测部观测到的所述通电加热时间指令值、电压、电流中的至少一个关联起来进行学习。
根据第二发明,在第一发明中,所述学习部包括:回报计算部,其根据由所述状态观测部观测到的所述线圈的粘接状态、绝缘耐压、通电加热时温度、通电加热时间实际值中的至少一个来计算回报;以及函数更新部,其根据由该回报计算部计算出的回报,对用于从当前的所述状态变量决定所述通电加热时间指令值、电压、电流中的至少一个的函数进行更新。
根据第三发明,在第一或者第二发明中,所述机械学习装置具有:意图决定部,其根据所述学习部的学习结果,从当前的所述状态变量决定所述通电加热时间指令值、电压、电流中的至少一个的最佳值。
根据第四发明,在第一至第三中任一发明中,所述学习部通过多层结构运算在所述状态观测部观测到的状态变量,并实时地更新所述函数。
根据第五发明,在第一至第四中任一发明中,使用由其他机械学习装置的函数更新部更新后的函数,来更新所述函数更新部的所述函数。
根据第六发明,提供一种具有第一至第五中任一机械学习装置的线圈通电加热装置。
从附图所示的本发明的典型的实施方式的详细的说明中进一步明确本发明的这些目的、特征以及优点和其他的目的、特征以及优点。
附图说明
图1是基于本发明的线圈制造装置的功能框图。
图2是放大表示机械学习器的图。
图3是表示机械学习器的动作的流程图。
图4是表示通电加热时间与通电加热时温度等的关系的图。
图5A是表示将一个单元线圈插入到铁芯的状态的图。
图5B是表示插入了多个单元线圈的铁芯的图。
图6A是单元线圈的第一局部剖视放大图。
图6B是单元线圈的第二局部剖视放大图。
图7是表示神经元模型的示意图。
图8是表示3层神经网络模型的示意图。
具体实施方式
以下,参照附图对本发明的实施方式进行说明。在以下的附图中对相同的部件标注相同的参照符号。为了易于理解,这些附图适当变更缩尺。
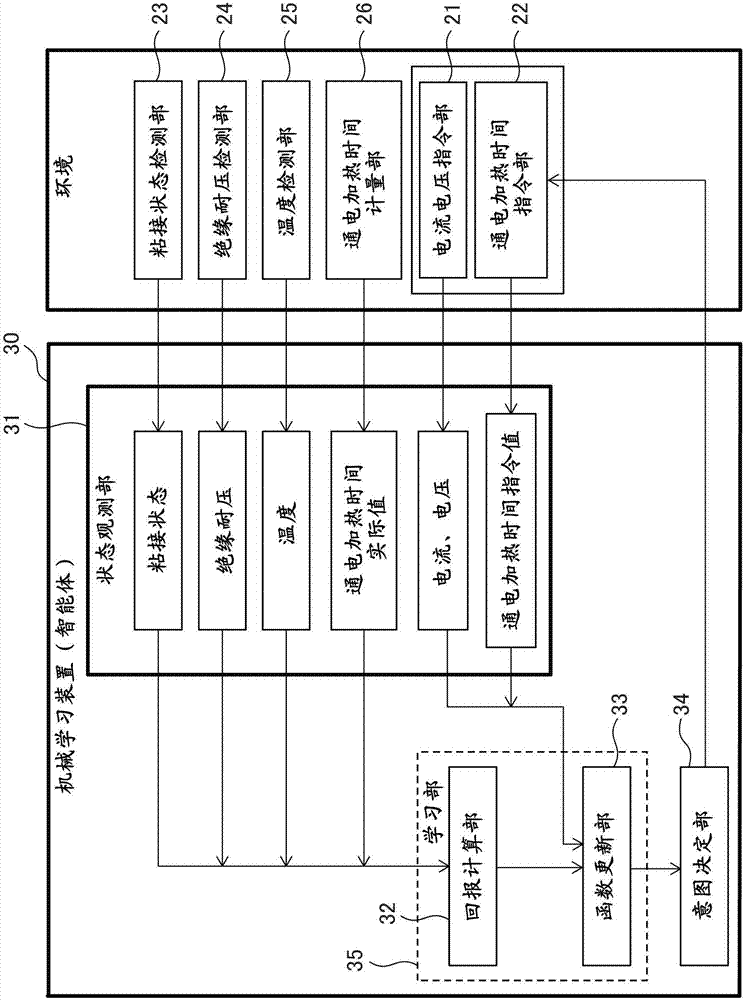
图1是基于本发明的线圈通电加热装置的功能框图。如图1所示,线圈通电加热装置1主要包括:线圈通电加热部10、控制线圈通电加热部10的控制装置20。
在图1的下方示出了线圈通电加热部10。线圈通电加热部10对由未图示的卷线机卷曲的线圈5进行通电。具体来说,如图1所示将线圈5的卷绕开始端部和卷绕结束端部与电源6连接来进行通电。此外,如上所述该线圈5的线材2通过加热熔融粘接剂3而被覆盖(请参照图6A)。
控制装置20是数字计算机,包括:电流电压指令部21,其对在线圈中通电时的电流以及电压进行指令;以及通电加热时间指令部22,其对线圈通电加热部10进行通电加热的时间进行指令。由后述的机械学习装置30决定从电流电压指令部21以及通电加热时间指令部22指令的指令值。
并且,控制装置20包括:粘接状态检测部23,其对制作出的线圈的粘接状态进行检测。粘接状态检测部23例如是照相机等。并且,控制装置20还包括:绝缘耐压检测部24,其对制作出的线圈的绝缘耐压进行检测;以及温度检测部25,其对通电加热时的线圈的温度进行检测。并且,控制装置20还包括:通电加热时间检测部26,其检测线圈通电加热部10实际对线圈进行了通电加热的时间。
如图1所示,控制装置20还包括:机械学习装置30。该机械学习装置30也可以外设于控制装置20。该情况下,控制装置20以及线圈通电加热部10能够相互通信地连接。
参照放大表示机械学习装置的图2,机械学习装置30包括对状态变量进行观测的状态观测部31,其中,该状态变量由通过线圈通电加热部10进行了通电加热的线圈的粘接状态、绝缘耐压、通电加热时温度、通电加热时间实际值中的至少一个,以及线圈通电加热部10中的通电加热时间指令值、电压、电流中的至少一个构成。状态观测部31能够将观测到上述状态变量的时间与上述状态变量一起依次存储。
并且,机械学习装置30包括:学习部35,其将由状态观测部31观测到的线圈的粘接状态、绝缘耐压、通电加热时温度、通电加热时间实际值中的至少一个,以及由状态观测部31观测到的通电加热时间指令值、电压、电流中的至少一个关联起来进行学习。
这里,学习部35能够进行有教师学习、无教师学习、半有教师学习、强化学习、转换、多任务学习等各种机械学习。在以下,设为学习部35通过Q学习(Q-learning)进行强化学习来继续说明。
这里,参照图2可知,机械学习装置30相当于强化学习中的智能体(agent)。此外,粘接状态检测部23、绝缘耐压检测部24、温度检测部25以及通电加热时间检测部26对环境的状态进行检测。
进行强化学习的学习部35包括:回报计算部32,其根据由状态观测部31观测到的线圈的粘接状态、绝缘耐压、通电加热时温度、通电加热时间实际值中的至少一个来计算出回报;以及函数更新部33(人工智能),其根据由回报计算部32计算出的回报,对用于从当前的状态变量决定通电加热时间指令值、电压、电流中的至少一个的函数例如行为价值函数(行为价值表)进行更新。当然,函数更新部33也可以更新其他函数。
并且,机械学习装置30包括:意图决定部34,其根据学习部35的学习结果,从当前的状态变量决定通电加热时间指令值、电压、电流中的至少一个的最佳值。意图决定部34学习更好的行为选择(意图决定)。另外,意图决定部34也可以不包括于机械学习装置30而包括于控制装置20中。
图3是表示机械学习器的动作的流程图。以下,参照图1~图3对机械学习装置30的动作进行说明。在每次进行由线圈通电加热部10执行的通电加热作业时实施图3所示的内容。
首先,在图3的步骤S11中,线圈通电加热部10选择指令通电加热时间指令值、以及电压和电流的指令值。这些指令值被从各自的预定范围随机地选择。
或者,还可以设为:例如首先选择通电加热时间指令值在预定范围内的最小值,接下来,在下一循环时选择微量增加的值。对于其他的指令值也是一样。也可以重复图3的处理,以便选择出通电加热时间指令值以及电压和电流的指令值的所有组合。
接下来,在步骤S12中,通过粘接状态检测部23检测出线圈的粘接状态,判定这些是否良好。这里,图4是表示通电加热时间与通电加热时温度等的关系的一例的图。图4的横轴表示通电加热时间的实际值,图4的纵轴表示线圈的绝缘耐压、通电加热时温度、粘接状态。另外,在图4中区域A1表示线圈的粘接状态不好的区域,区域A2表示粘接状态普通的区域,区域A3表示粘接状态良好的区域。并且,图4中的直线B表示线圈的绝缘耐压,曲线C表示线圈的通电加热时温度。此外,图4所示的曲线R表示回报。
如图4的区域A1~A3所示,关于线圈的粘接状态,通电加热时间越长越良好,优选通电加热时间处于区域A3,卷线2不松动,卷线2的加热熔融性粘接剂3不会焦化。此外,如直线B所示,绝缘耐压在通电加热时间超越预定值时急剧降低。然后,如直线C所示,线圈的通电加热时温度与通电加热时间一起上升。
并且,如图4的直线R所示,在线圈的绝缘耐压包含于预定的绝缘耐压范围时,在通电加热时温度实际值包含于预定的温度范围时,回报增加。但是,若通电加热时间实际值比预定时间大,则回报急剧降低。以下所示的回报的增减例如根据图4的内容来决定其增减量。
再次参照图3,当在步骤S12中粘接状态良好时,在步骤S13中回报增加。相反,在粘接状态不良时,在步骤S20中回报减少或者不变。
接下来,在步骤S14中,判定由绝缘耐压检测部24检测出的线圈的绝缘耐压是否包含于预定的绝缘耐压范围内。然后,在绝缘耐压包含于预定的绝缘耐压范围内时,在步骤S15中回报增加,在绝缘耐压不包含于预定的绝缘耐压范围内时,在步骤S20中回报减少或不变。另外,优选绝缘耐压高,也可以没有绝缘耐压范围的上限值。
接下来,在步骤S16中,判定由温度检测部25检测出的线圈的通电加热时温度是否包含于预定的温度范围内。然后,在线圈的通电加热时温度包含于预定的温度范围内时,在步骤S17中回报增加,在线圈的通电加热时温度没有包含于预定的温度范围内时,在步骤S20中回报减少或者不变。另外,优选通电加热时温度在温度范围内且处于其上限值附近。
接下来,在步骤S18中,判定由通电加热时间检测部26检测出的通电加热时间实际值是否包含于预定的通电加热时间范围内。然后,在通电加热时间实际值包含于预定的通电加热时间范围内时,在步骤S19中回报增加,在通电加热时间实际值没有包含于预定的通电加热时间范围内时,在步骤S20中,回报减少或者不变。另外,优选通电加热时间实际值短,也可以没有通电加热时间实际值的下限值。
通过回报计算部32计算出上述这样的回报增减。此外,对于回报增减的额度,也可以设定为根据步骤而其值不同。此外,也可以省略步骤S12、S14、S16、S18中的至少一个判定步骤以及相关连的回报步骤。
然后,在步骤S19中,函数更新部33更新行为价值函数。这里,学习部35实施的Q学习是在某环境状态s下,对选择出行为a的价值(行为价值)Q(s、a)进行学习的方法。然后,在处于某状态s时,选择出Q(s、a)的最高行为a。在Q学习中,因试错而在某状态s下取得各种各样的行为a,使用当时的回报来学习正确的Q(s、a)。通过以下的数学式(1)来表现行为价值函数Q(s、a)的更新式。
这里,st、at表示时刻t的环境与行为。通过行为at环境变化为st+1,通过该环境的变化,计算出回报rt+1。此外,带有max的项是:在环境st+1之下,将γ乘以选择出(当时知道的)Q值最高的行为a时的Q值。这里γ是0<γ≤1(通常是0.9~0.99)的折扣率,α是0<α≤1(通常是0.1左右)的学习系数。
该更新式表示了如下内容:若在基于a的下一环境状态中最佳的行为的评价值Q(st+1,maxat+1)比在状态s中行为a的评价值Q(st,at)大,则增大Q(st,at),反之如果小,则减小Q(st,at)。也就是说,将某种状态中某行为的价值设定为接近其下一状态中最佳的行为价值。换言之,学习部35更新线圈的通电加热时间指令值、以及电压和电流的指令值各自的最佳值。
这样,在步骤S21中,函数更新部33使用上述的数学式(1)来更新行为价值函数。然后,返回到步骤S11,选择出线圈的其他的通电加热时间指令值、以及电压和电流的其他的指令值,同样地更新行为价值函数。另外,也可以设定为代替更新行为价值函数,而是更新行为价值表。
在强化学习中,作为智能体的学习部35根据环境的状况来决定行为。所谓该情况下的行为是指:意图决定部34选择出通电加热时间指令值、以及电压和电流的指令值各自的新的值,并按照这些新的值进行为作。然后,通过这些新的值的各种指令值,图2所示的环境,例如线圈的粘接状态、绝缘耐压、通电加热时温度、通电加热时间实际值发生变化。伴随着这样的环境变化,如上所述回报被给予到机械学习装置30,机械学习装置30的意图决定部34学习更好的行为的选择(意图决定),例如以便获得更好的回报。
因此,重复多次进行图3所示的处理,由此,行为价值函数的可靠性提高。然后,在步骤S11中,根据可靠性高的行为价值函数,例如以Q值变高的方式选择出通电加热时间指令值、以及电压和电流的指令值,由此,能够更加适当地决定更确切的大小指令值。在图4所示的示例中,机械学习器30的学习结果收敛于由虚线围绕的区域Z。
这样,与形成线圈时相比,能够将由本发明的机械学习装置30的函数更新部33更新的内容自动地决定为最佳的通电加热时间指令值、以及电压和电流的指令值。然后,通过将这样的机械学习装置30导入到控制装置20,能够自动地对通电加热时间指令值等进行调整。因此,能够自动地制造出粘接力稳定的单元线圈,能够吸收线圈的个体差异导致的变动。此外,通过按照机械学习装置的学习结果,在制造线圈时操作员不需要通过手动来给予动作条件。因此,能够降低线圈制造时的工作量以及工时。结果,使生产效率提升。
此外,在未图示的实施方式中,具有与机械学习器30相同结构的其他机械学习装置30’组装于其他的线圈通电加热部10’的控制装置20’。并且,控制装置20’与控制装置20能够通信地连接。在这样的情况下,能够将由其他的机械学习装置30’的函数更新部33’更新而得的函数拷贝到机械学习器30的函数更新部33。并且,也可以使用该函数来更新函数更新部30的函数。可知在该情况下能够分散转移可靠性高的学习结果。
此外,也可以使用后述的神经网络来使用近似的函数作为行为价值函数。该情况下,也可以通过多层结构来运算由状态观测部31观测出的状态变量,实时地更新行为价值函数。由此可知能获得更加适当的学习结果。此外,该情况下,如图像数据等那样在“s”以及“a”的信息量巨大时特别有利。
这里,对于图2所示的机械学习装置30等,虽然一部分重复,但是详细地再次进行说明。机械学习装置30具有如下功能:从输入到装置的数据的集合中通过解析而提取出处于其中的有用的规则和知识表现、判断基准等,输出该判定结果,并且进行知识学习。其方法是多种多样的,但是如果大致进行区分则分为“有教师学习”、“无教师学习”、“强化学习”。并且,在实现这些方法基础上,还存在学习提取特征量本身的、被称为“深层学习”的方法。
所谓“有教师学习”是指:通过将某种输入与结果(标签label)的数据组大量地给予到学习装置,学习这些数据集(data set)中的特征,能够归纳性地获得从输入推定出结果的模型即其相关性。在本实施方式中,能够用于从线圈的上述各种指令值中推定出线圈的尺寸实际值等的部分等。能够使用后述的神经网络等算法来实现。
所谓“无教师学习”是如下方法:通过只将输入数据大量地给予到学习装置,学习输入数据进行怎样的分布,即使不给予对应的教师输出数据,也能学习对针对输入数据进行压缩、分类、整形等的装置。能够将处于这些数据集之中的特征聚类于相似者之间等。使用其结果来进行设定某个基准而使其为最佳这样的输出分配,由此,能够实现预测输出。此外,作为“无教师学习”和“有教师学习”中间的问题设定而被称为“半有教师学习”,其对应于如下情况:仅存在一部分输入和输出的数据组,除此之外仅有输入数据。在本实施方式中,在无教师学习中能够利用即使实际上不使卷线机动作也能够获得的数据来高效地进行学习。
以如下方式来设定强化学习的问题。
·卷线机以及其控制装置观测环境的状态,决定行为。
·环境按照某种规则进行变化,并且自身行为有时也对环境给予变化。
·每次行为时反馈回来回报信号。
·想要最大化的是到将来的(折扣)回报的总和。
·从完全不知道行为引起的结果或者从只是不完全知道的状态起,开始学习。以卷线机实际动作开始,能够将其结果获得为数据。也就是说,需要一边试错一边探索最佳的行为。
·可以将例如模仿人类动作这样事前学习(上述的称为有教师学习、逆强化学习这样的方法)了的状态设为初期状态,来从较好的开始点起开始学习。
所谓“强化学习”是用于如下学习的方法:不单进行判定和分类,还通过学习而在行为给予环境的相互作用基础上学习适当的行为,即,使将来获得的回报最大化。在本实施方式中,其表示能够获得对未来造成影响的行为。例如,虽然在Q学习的情况下继续说明,但是并非限定于此。
Q学习是在某种环境状态s下学习选择行为a的价值Q(s、a)的方法。也就是说,在某种状态s时,将价值Q(s、a)最高的行为a选择为最佳行为。但是,最开始对于状态s与行为a的组合来说,完全不知道价值Q(s、a)的正确值。因此,智能体(行为主体)在某种状态s下选择各种各样的行为a,并针对当时的行为a给予回报。由此,智能体继续学习更好的行为选择,即学习正确的价值Q(s、a)。
行为的结果,是想要使到将来获得的回报的总和最大化,所以目标是最终成为Q(s、a)=E[Σ γtrt](按最佳行为改变状态时得到期望值。当然,由于不知道期望值,因此不得不一边探索一边学习)。这样的价值Q(s、a)的更新式例如可以通过如下数学式来表示(与上述的数学式(1)相同)。
这里,st表示时刻t的环境状态,at表示时刻t的行为。通过行为at,状态变化为st+1。rt+1表示通过该状态的变化而得到的回报。此外,带有max的项是:在状态st+1下,将γ乘以选择出当时知道的Q值最高的行为a时的Q值。γ是0<γ≤1的参数,被称为折扣率。α是学习系数,设α的范围为0<α≤1。
该数学式表示如下方法:根据试行at的结果而反馈回来的回报rt+1,更新状态st下的行为at的评价值Q(s、a)。表示了:若回报rt+1+行为a导致的下一状态下的最佳行为max a的评价值Q(st+1、max at+1)比状态s下的行为a的评价值Q(st、at)大,则增大Q(st、at),反之如果小,则减小Q(st、at)。也就是说,使某种状态下的某种行为的价值,接近在作为结果及时反馈回来的回报和该行为导致的下一状态下的最佳的行为价值。
Q(s、a)在计算机上的表现方法有以下方法:针对所有的状态行为对(s、a),将该值保存为表格(行为价值表)的方法、以及准备用于使Q(s、a)进行近似这样的函数的方法。在后者的方法中,可以通过随机梯度下降法(Stochastic gradient descent method)等方法来调整近似函数的参数来实现上述的更新式。作为近似函数,可以使用后述的神经网络。
作为有教师学习、无教师学习以及强化学习中的价值函数的近似算法,可以使用神经网络。例如由实现模拟了图7所示那样的神经元模型的神经网络的运算装置以及存储器等来构成神经网络。图7是表示神经元模型的示意图。
如图7所示,神经元输出针对多个输入x(这里,作为一个示例,输入x1~输入x3)的输出y。对各输入x1~输入x3乘以与该输入x对应的权值w(w1~w3)。由此,神经元输出由如下数学式表现的输出y。另外,输入x、输出y以及权值w都是矢量。
这里,θ是偏置(bias),fk是激活函数(activation function)。
接下来,参照图8对具有组合了上述的神经元而得的三层权值的神经元网络进行说明。图8是表示具有D1~D3的三层权值的神经元网络的示意图。
如图8所示,从神经元网络的左侧输入多个输入x(这里作为一例是输入x1~输入x3),从右侧输出结果y(这里作为一例,结果y1~结果y3)。
具体来说,输入x1~输入x3乘以对应的权值而被输入到三个神经元N11~N13的每一个。与这些输入相乘的权值统一标记为w1。
神经元N11~N13分别输出z11~z13。这些z11~z13可以被统一标记为特征向量z1,看作是提取出输入向量的特征量而得的向量。该特征向量z1是权值w1与权值w2间的特征向量。
z11~z13乘以对应的权值而被输入到两个神经元N21、N22的每一个。与这些特征向量相乘的权值被统一标记为w2。
神经元N21、N22分别输出z21、z22。其被统一标记为特征向量z2。该特征向量z2是权值w2与权值w3之间的特征向量。
特征向量z21、z22乘以对应的权值而被输入到三个神经元N31~N33的每一个。与这些特征向量相乘的权值被统一标记为w3。
最后,神经元N31~N33分别输出结果y1~结果y3。
在神经网络的动作中有学习模式和价值预测模式,在学习模式中使用学习数据集来学习权值w,在预测模式中使用其参数进行卷线机的行为判定(为了方便而写为预测,但是也可以是检测、分类、推论等多种多样的任务)。
可以是在预测模式下对实际运行卷线机而获得的数据进行即时学习,并反映到下一行为中(在线学习),也可以是使用预先收集好的数据组来进行汇总学习,以后一直用该参数进行检测模式(批量学习)。每当积攒了其中间的某种程度数据时,就可以插入学习模式。
可以通过误差反传播法(back propagation)来学习权值w1~w3。误差信息从右侧进入流向左侧。误差反传播法是如下方法:针对各神经元调整(学习)各自的权值使得降低输入了输入x时的输出y与真的输出y(教师)之间的差量。
这样的神经网络还可以在三层以上进一步增加层(称为深层学习)。可以阶段性地进行输入的特征提取,仅从教师数据自动地获得用于反馈结果的运算装置。
因此,本实施方式的机械学习器30为了实施上述的Q学习,如图2所示而具有状态观测部31、学习部35以及意图决定部34。但是,应用于本发明的机械学习方法并不局限于Q学习。例如在应用有教师学习时,价值函数对应于学习模型、回报对应于误差。
发明效果
在第一至第三发明中,能够提供一种机械学习装置,操作员不用手给予动作条件就能自动决定更优的线圈的粘接状态等。
在第四发明中,能够获得适当的学习结果。
在第五发明中,能够将通过某机械学习装置获得的学习结果装入到其他机械学习装置,能够分散转移可靠性高的学习结果。
在第六发明中,通过按照机械学习装置的学习结果,而不需要在线圈的通电加热时操作员手动给予动作条件。因此,能够降低线圈的通电加热时的工作量以及工时。此外,能够自动地制造出粘接力稳定的单元线圈,能够吸收线圈的个体差异导致的变动。
使用典型的实施方式说明了本发明,但是本领域技术人员应当了解在不脱离本发明范围的情况下还可以进行上述的变更以及各种其他变更、省略、追加。
- 还没有人留言评论。精彩留言会获得点赞!