基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法与流程
本发明涉及电力系统及其自动化领域,具体是基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法。
背景技术:
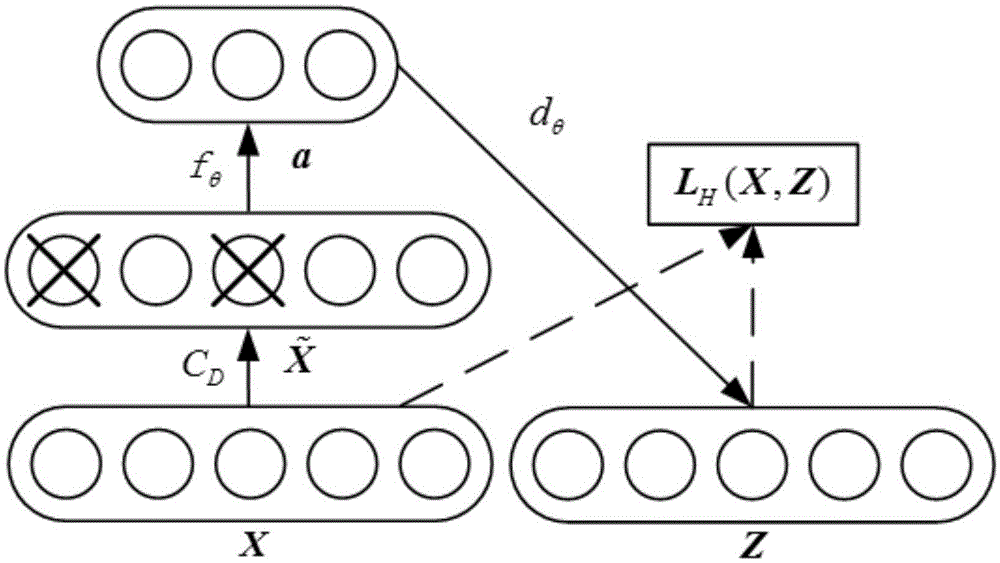
:随着可再生能源的日益普及,电力系统的不确定性激增。概率最优潮流(popf)可计及电力系统运行中的各种不确定性因素,已成为确保电力系统安全经济运行的重要工具。现有的概率最优潮流求解技术一般可以分为解析法和模拟法。前者仅适用于某些类型的概率分布,在实际应用中无法处理概率最优潮流的一般情况。后者计算结果精确,应用灵活,但涉及大量的抽样且需要重复求解非线性和非凸的最优潮流(opf)问题,导致计算时间较长。计算耗时已成为概率最优潮流在电力行业实际应用中的主要瓶颈。技术实现要素:本发明的目的是解决现有技术中存在的问题。为实现本发明目的而采用的技术方案是这样的,基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法,主要包括以下步骤:1)建立sdae最优潮流模型。所述sdae最优潮流模型包括n个顺序堆叠的dae模型。其中,第l-1层dae的输入层为第l-2层dae的中间层。第l-1层dae的中间层为第l层dae的输入层。所述dae模型主要包括1个输入层、1个中间层和1个输出层。输入层的神经元个数设为a。任意输入层神经元记为ui,i=1、2…a。输入层的输入样本x中的数据主要包括电力系统中所有新能源节点和负荷节点的有功功率和无功功率。中间层的神经元个数设为m。任意输入层神经元记为vi,i=1、2…m。输出层的神经元个数设为q。任意输出层神经元记为me,e=1、2…q。输出层的输出向量y中的数据主要包括电力系统节点电压幅值和相角、发电机有功功率、发电机有功功率无功功率、支路有功功率、支路无功功率和发电成本。建立sdae最优潮流模型的主要步骤如下:1.1)随机腐蚀训练输入样本x,从而得到局部受腐蚀的输入样本局部受腐蚀的输入样本如下所示:式中,qd为随机局部腐蚀过程,即随机选取一定数量的输入变量置零。1.2)利用编码函数fθ得到中间层a。中间层a如下所示:式中,w为编码函数的权值。b为编码函数的偏置。s为激活函数。fθ为编码函数。为局部受腐蚀的输入样本。激活函数s如下所示:s(x)=max(0,x)。(3)式中,x为输入向量x中的数据。1.3)利用解码函数gθ′得到dae的输出层z。输出层z如下所示:z=gθ′(a)=s(w′a+b′)。(4)式中,w′为解码函数的权值。w′=wt。b′为解码函数的偏置。s为激活函数。gθ′为解码函数。1.4)将dae逐层堆叠,从而得到sdae最优潮流模型。1.5)提取最优潮流输入数据x的高维特征,拟合得到输出yt。输出yt如下所示:其中,为第l层dae的编码函数,l=1,2,…,n,n为sdae最优潮流模型中dae的个数。为顶层编码函数。x为输入样本。2)获取sdae最优潮流模型输入层的输入样本x。3)对sdae最优潮流模型进行初始化。对sdae最优潮流模型进行初始化的主要步骤如下:3.1)利用最大最小法对输入向量x和输出向量y进行归一化处理式中,x为输入向量x中的数据。xmin为输入向量x中的最小数据。xmax为输入向量x中的最大数据。利用最大最小法对输出向量y进行归一化处理。式中,y为输出向量。ymin为最小输出向量。ymax为最大输出向量。3.2)将处理后的训练输入样本x分成m个批量。3.3)根据电力系统的规模和复杂程度设定sdae最优潮流模型的总层数n、每层神经元的个数和学习率η。4)对sdae最优潮流模型进行训练,从而得到训练后的sdae最优潮流模型。对sdae最优潮流模型进行训练的主要步骤如下:4.1)对sdae最优潮流模型进行无监督预训练,主要步骤如下:4.1.1)根据第l层dae的输入xl和输出zl构造均方差损失函数lη(xl,zl)。4.1.2)根据均方差损失函数lη(xl,zl)获得优化目标函数优化目标函数如下所示:式中,xl为第l层dae的输入,也即第l-1层dae的中间层输出al-1。zl是第l层dae的输出。lη(xl,zl)为根据第l层dae的输入xl和输出zl构造的均方差损失函数。4.1.3)利用rmsprop学习算法和动量学习率,构建sdae最优潮流模型无监督预训练参数更新公式。无监督预训练参数更新公式如公式9至公式12所示。第t+1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值如下所示:式中,是第t次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。第t+1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的偏移量如下所示:式中,是第t次参数更新后,第l层dae中间层的第i个神经元的偏移量。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的偏移量。其中,第t次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值更新过程中的如下所示:式中,η为学习速率。m为此批量样本数量。p为动量因子。ρ为梯度累积指数。ε为常数。⊙是hadamard乘子。lh(zl,xl)为根据第l个dae的输出层输出和训练样本输入x构造均方差损失函数。k为任意样本。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。是第t次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。r和r+m分别是此批量的起始样本序号。为前t次权值迭代积累的梯度。为前t-1次权值迭代积累的梯度。δ为增量符号。d为微分符号。σ为常数。为偏导符号。第t次参数更新后,第l层dae中间层的第i个神经元的偏移量更新中的如下所示:式中,lh(yt,y)为根据顶层输出和训练样本输出y构造均方差损失函数。k为任意样本。是第t次参数更新后,第l层dae中间层的第i个神经元的偏移量。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的偏移量。为前t次偏置迭代积累的梯度;为前t-1次偏置迭代积累的梯度。4.1.4)根据无监督预训练参数更新公式计算每层dae的最优编码参数θ={w,b},并将最优编码参数θ={w,b}作为有监督微调的初始编码参数。4.2)对sdae最优潮流模型进行有监督微调,主要步骤如下:4.2.1)根据顶层输出和训练样本输出y构造均方差损失函数lh(yt,y),从而得到优化目标函数argθminj(w,b)。argθminj(w,b)=argθminlh(yt,y)。(13)式中,lh(yt,y)为根据顶层输出和训练样本输出y构造均方差损失函数。yt为输出样本。y为训练样本输出。4.2.2)根据优化目标函数argθminj(w,b),从而对sdae最优潮流模型最优编码参数θ={w,b}进行微调。4.2.3)将微调后的sdae最优潮流模型最优编码参数θ={w,b}代入公式2中,从而得到第l层dae的编码函数和顶层dae的编码函数4.2.4)将第l层dae的编码函数和顶层dae的编码函数代入公式7中,从而得到训练好的sdae最优潮流模型。5)采用mcs法对待计算概率潮流的电力系统的随机变量进行抽样,从而获取计算样本。所述随机变量主要包括待计算概率最优潮流的电力系统的风速、光照辐射度和负荷。6)将步骤5得到的训练样本数据一次性输入步骤4中训练完成的sdae最优潮流模型中,从而计算出最优潮流在线概率。7)对所述最优潮流在线概率进行分析,即绘制sdae最优潮流模型的输出变量的概率密度曲线。本发明的技术效果是毋庸置疑的。本发明选择堆栈降噪自动编码器(sdae)来学习最优潮流的优化过程并进一步结合蒙特卡洛模拟法实现概率最优潮流的在线计算。本发明建立的基于sdae的最优潮流模型能够有效挖掘最优潮流模型的高维非线性特征,快速准确地得到最优潮流的计算结果,体现了sdae模型对最优潮流模型的强大逼近能力。本发明提出的基于sdae与mcs的概率最优潮流在线算法,可有效处理电力系统中的各种不确定性因素,通过mcs法对电力系统状态进行抽样,再由sdae最优潮流模型直接映射出所有抽样样本的最优潮流计算结果,从而在不增加硬件成本的前提下实现了概率最优潮流的高精度在线计算。本发明可广泛应用于电力系统的概率最优潮流求解,特别适用于新能源渗透率高导致系统不确定性增强的在线分析情况。附图说明图1为dae的结构图;图2为基于sdae的最优潮流结构图;图3a为基于内点法的mcs法(m0)求得的最优潮流概率密度曲线与基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法(m1)求得的最优潮流概率密度曲线在节点10的电压幅值对比图;图3b为基于内点法的mcs法(m0)求得的最优潮流概率密度曲线与基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法(m1)求得的最优潮流概率密度曲线在节点10的发电机有功出力对比图;图3c为基于内点法的mcs法(m0)求得的最优潮流概率密度曲线与基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法(m1)求得的最优潮流概率密度曲线在节点10的支路5-6的有功功率对比图;图3d为基于内点法的mcs法(m0)求得的最优潮流概率密度曲线与基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法(m1)求得的最优潮流概率密度曲线的目标值对比图。具体实施方式下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。实施例1:参见图1和图2,基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法,主要包括以下步骤:1)建立sdae最优潮流模型。利用sdae具有深层堆栈结构以及编码解码过程从而能够有效挖掘非线性最优潮流模型的高阶特征的特点,建立基于sdae的最优潮流模型。考虑到最优潮流模型含有非线性等式、不等式约束从而导致输入输出之间非线性特征复杂,提出了结合最大最小归一化数据预处理方法和基于动量学习率的小批量梯度下降学习算法的深度神经网络训练方法,以提高训练精度与速度。训练后的sdae最优潮流模型能够非迭代地直接映射出由mcs法生成的随机样本的最优潮流计算结果而无需优化,具有计算速度快、精度高的特点。最后,在ieee118系统上进行仿真,采用基于sdae的最优潮流模型仅需数秒便可准确求得系统概率最优潮流,计算速度与传统的基于内点法的mcs法相比提高了上千倍。sdae最优潮流模型由降噪自动编码器(denoisingauto-encoders,dae)逐层堆栈构成。dae是自动编码器(ae)的一种扩展,是加入了随机因素的自动编码器,通过局部腐蚀输入x(即引入随机噪声)的方式以强制自动编码器全面地提取输入的高维特征,从而实现腐蚀后的输入的重构,由此提高了模型的鲁棒性。所述sdae最优潮流模型包括n个顺序堆叠的dae模型。其中,第l-1层dae的输入层为第l-2层dae的中间层。第l-1层dae的中间层为第l层dae的输入层。dae输出层z并不参与sdae的数据流通。所述dae模型主要包括1个输入层、1个中间层和1个输出层。输入层的神经元个数设为a。任意输入层神经元记为ui,i=1、2…a。输入层的输入样本x中的数据主要包括电力系统中所有新能源节点和负荷节点的有功功率和无功功率。中间层的神经元个数设为m。任意输入层神经元记为vi,i=1、2…m。输出层的神经元个数设为q。任意输出层神经元记为me,e=1、2…q。a、m和q的取值由电力系统的规模和复杂程度决定。输出层的输出向量y中的数据主要包括电力系统节点电压幅值和相角、发电机有功功率、发电机有功功率无功功率、支路有功功率、支路无功功率和发电成本。建立sdae最优潮流模型的主要步骤如下:1.1)随机腐蚀训练输入样本x,从而得到局部受腐蚀的输入样本局部受腐蚀的输入样本如下所示:式中,qd为随机局部腐蚀过程,即随机选取一定数量的输入变量置零。1.2)利用编码函数fθ得到中间层a。中间层a如下所示:式中,w为编码函数的权值。b为编码函数的偏置。s为激活函数。fθ为编码函数。为局部受腐蚀的输入样本。编码函数的权值w是一个dy×dx维的矩阵。编码函数的偏置b是一个dy维的向量。本发明选择目前已获得广泛应用的relu(rectifiedlinearunit)函数作为编码和解码过程激活函数。dx和dy分别为输入层和中间层向量的维度。激活函数s如下所示:s(x)=max(0,x)。(3)式中,x为输入向量x中的数据。1.3)利用解码函数gθ′得到dae的输出层z。输出层z如下所示:z=gθ′(a)=s(w′a+b′)。(4)式中,w′为解码函数的权值。w′=wt。b′为解码函数的偏置。s为激活函数。gθ′为解码函数。1.4)将dae逐层堆叠,从而得到sdae最优潮流模型。1.5)提取最优潮流输入数据x的高维特征,拟合得到输出yt。输出yt如下所示:其中,为第l层dae的编码函数,l=1,2,…,n,n为sdae最优潮流模型中dae的个数。为顶层编码函数。x为输入样本。为第1层dae的编码函数。2)获取sdae最优潮流模型输入层的输入样本x。3)对sdae最优潮流模型进行初始化。对sdae最优潮流模型进行初始化的主要步骤如下:3.1)利用最大最小法对输入向量x和输出向量y进行归一化处理式中,x为输入向量x中的数据。xmin为输入向量x中的最小数据。xmax为输入向量x中的最大数据。利用最大最小法对输出向量y进行归一化处理。式中,y为输出向量。ymin为最小输出向量。ymax为最大输出向量。3.2)将处理后的训练输入样本x分成m个批量。3.3)根据电力系统的规模和复杂程度设定sdae最优潮流模型的总层数n、每层神经元的个数和学习率η。4)对sdae最优潮流模型进行训练,从而得到训练后的sdae最优潮流模型。对sdae最优潮流模型进行训练的主要步骤如下:4.1)对sdae最优潮流模型进行无监督预训练,主要步骤如下:4.1.1)根据第l层dae的输入xl和输出zl构造均方差损失函数lη(xl,zl)。4.1.2)根据均方差损失函数lη(xl,zl)获得优化目标函数优化目标函数如下所示:式中,xl为第l层dae的输入,也即第l-1层dae的中间层输出al-1。zl是第l层dae的输出。lη(xl,zl)为根据第l层dae的输入xl和输出zl构造的均方差损失函数。4.1.3)利用rmsprop学习算法和动量学习率,构建sdae最优潮流模型无监督预训练参数更新公式。无监督预训练参数更新公式如公式9至公式12所示。第t+1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值如下所示:式中,是第t次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。第t+1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的偏移量如下所示:式中,是第t次参数更新后,第l层dae中间层的第i个神经元的偏移量。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的偏移量。其中,第t次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值更新过程中的如下所示:式中,η为学习速率。m为此批量样本数量。p为动量因子。ρ为梯度累积指数,是一个接近于1的值,本实施例取ρ=0.999。ε是一个接近于0分值,本实施例取ε=10-8。⊙是hadamard乘子。lh(zl,xl)为根据第l个dae的输出层输出和训练样本输入x构造均方差损失函数。k为任意样本。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。是第t次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的权值。r和r+m分别是此批量的起始样本序号。为前t次权值迭代积累的梯度。为前t-1次权值迭代积累的梯度。δ为增量符号。d为微分符号。σ为常数。本实施例取σ=10-6,用于被小数除时的数值稳定。为偏导符号。为第t次迭代的权值增量。为第t-1次迭代的权值增量。为第t次迭代的权值微分。为第t次迭代的权值偏导。第t次参数更新后,第l层dae中间层的第i个神经元的偏移量更新中的如下所示:式中,lh(yt,y)为根据顶层输出和训练样本输出y构造均方差损失函数。k为任意样本。是第t次参数更新后,第l层dae中间层的第i个神经元的偏移量。是第t-1次参数更新后第l-1层dae中间层的第j个神经元到第l层dae中间层的第i个神经元的偏移量。为前t次偏置迭代积累的梯度;为前t-1次偏置迭代积累的梯度。为第t次迭代的偏置增量。为第t-1次迭代的偏置增量。为第t次迭代的偏置微分。为第t次迭代的偏置偏导。4.1.4)根据无监督预训练参数更新公式计算每层dae的最优编码参数θ={w,b},并将最优编码参数θ={w,b}作为有监督微调的初始编码参数。4.2)对sdae最优潮流模型进行有监督微调,主要步骤如下:4.2.1)根据顶层输出和训练样本输出y构造均方差损失函数lh(yt,y),从而得到优化目标函数argθminj(w,b)。argθminj(w,b)=argθminlh(yt,y)。(13)式中,lh(yt,y)为根据顶层输出和训练样本输出y构造均方差损失函数。yt为输出样本。y为训练样本输出。4.2.2)根据优化目标函数argθminj(w,b),从而对sdae最优潮流模型最优编码参数θ={w,b}进行微调。4.2.3)将微调后的sdae最优潮流模型最优编码参数θ={w,b}代入公式2中,从而得到第l层dae的编码函数和顶层dae的编码函数4.2.4)将第l层dae的编码函数和顶层dae的编码函数代入公式7中,从而得到训练好的sdae最优潮流模型。5)采用mcs法对待计算概率潮流的电力系统的随机变量进行抽样,从而获取计算样本。所述随机变量主要包括待计算概率最优潮流的电力系统的风速、光照辐射度和负荷。6)将步骤5得到的训练样本数据一次性输入步骤4中训练完成的sdae最优潮流模型中,从而计算出最优潮流在线概率。7)对所述最优潮流在线概率进行分析,即绘制sdae最优潮流模型的输出变量的概率密度曲线。实施例2:参见图3a至图3d,一种基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法的仿真实验,主要包括以下步骤:1)最优潮流样本获取。本实施例中采用ieee118标准系统进行仿真。本实施例在母线59、80和90上引入风电场,风电场最大出力分别为220、200、260mw,在母线13、14、16和23上引入光伏发电站,光伏发电站最大出力分别为100、150、100、150mw。其中,假定风速服从两参数weibull分布,其尺度参数为2.016,形状参数为5.089。光照强度服从beta分布,光伏发电站的形状参数和风电场的切入风速、额定风速、切出风速参见表1。此外,假定各节点负荷的随机特性服从正态分布,其标准差为各节点负荷期望值的5%。表1光伏发电站和风电场相关参数然后,通过蒙特卡洛法对上述随机变量进行5万次抽样并采用内点法对每个抽样状态进行最优潮流的求解。将所有抽样状态的新能源节点和负荷节点的有功和无功作为训练样本输入x。由内点法求得的所有抽样状态的最优潮流计算结果(即电力系统各节点电压幅值和相角、发电机有功无功出力、各支路功率、发电成本)作为训练样本的输出y。2)sdae最优潮流模型初始化包括数据预处理以及sdae最优潮流模型超参数的确定。使用最大最小法对训练样本的输入和输出数据进行归一化处理。根据训练样本容量,将训练样本分成100个批量。腐蚀训练样本输入x。最后,根据待求解的电力系统规模和复杂程度,设定sdae最优潮流模型的层数l为5、每层神经元个数分别为236、200、200、200、717,学习率η为0.001。3)sdae最优潮流模型无监督预训练。首先,利用训练样本输入x,构建第一层dae的均方差损失函数lh(z1,x1)。然后,使用基于动量学习率的小批量梯度下降算法,根据参数更新公式,迭代求解第一层dae的最优参数w1、b1、w′1、b′1。之后,得到第一层dae的中间层输出,作为第二层dae的输入,以相同的方法构建第二层dae的损失函数lh(z2,x2),并以相同的方法更新参数,以此类推,自底至顶逐层求解每层dae的最优编码参数θ={w,b},并将该最优编码参数作为下阶段有监督微调的初始参数。4)sdae最优潮流模型有监督微调首先,利用训练样本输入x和输出y,构建sdae最优潮流模型的均方差损失函数lh(yt,y)。然后,仍然使用基于动量学习率的小批量梯度下降算法,同样根据参数更新公式,迭代求解sdae最优潮流模型的所有最优编码参数θ={w,b}。至此,完成了sdae最优潮流模型的训练。5)系统状态抽样本实施例采用mcs法对所研究电力系统中的不确定因素,即风速、光照辐射强度、负荷等随机变量按其各自分布进行抽样以获取足够数量的测试样本,本发明选择的抽样次数n为50000。也可采用改进mcs法。6)概率最优潮流在线求解将步骤(5)中得到的测试样本一次性输入步骤(4)中训练完成的sdae最优模型中,该模型可直接映射出所有测试样本的最优潮流值。仿真结果如下:1)具体算例及最优潮流计算对比方法具体算例为:ieee118系统,各节点负荷方差均为5%。仿真中最优潮流计算对比方法包括m0-m1:m0:基于内点法的mcs法,作为验证标准。m1:基于堆栈降噪自动编码器的电力系统概率最优潮流计算方法。在训练上述神经网络时,训练结束判据为连续10次迭代中均方差的最小值没有减小。7)sdae最优流模型计算精度分析本实施例为了验证sdae最优潮流模型计算最优潮流的总体精度及泛化能力,由算例经mcs法抽取50000个测试样本,并由两种对比算法计算所有样本的最优潮流,表2列出了由两种算法求得的节点电压幅值误差超过0.01p.u.的概率、发电机有功出力误差超过5mw的概率、支路有功误差超过5mw的概率、发电成本误差超过3000元的概率。表2m0-m1基于绝对误差的最优潮流计算精度比较由表2可知,由sdae最优潮流模型计算所得的四个指标中,绝对误差大于设置数值的概率集中在0.1%以下,最大概率为0.09%,可见,sdae凭借其深层堆栈结构与编码解码过程,有效地提取了最优潮流的非线性特征,实现了最优潮流由输入到输出的高精度快速映射。因此,本发明构建的sdae最优潮流模型具有较高的最优潮流计算精度和较强的泛化能力。8)概率最优潮流在线算法计算性能分析本实施例从所提概率最优潮流在线算法的计算精度和速度两方面分析其性能。在抽取的50000个样本的条件下,本实施例以节点10的电压幅值、节点10的发电机有功出力、节点5-节点6的支路有功和发电成本为例,绘制出本发明方法与基于内点法的mcs法求得的所列随机变量的概率密度曲线,如图3a至图3d所示。从图中可见,本发明方法求得的最优潮流概率密度曲线与作为验证标准的基于内点法的mcs法得到的最优潮流概率密度曲线几乎相同。因此,本发明方法满足概率最优潮流的计算精度要求。表3列出了由m0、m1法计算概率最优潮流所需的时间。由表3可见,由m0法计算概率最优潮流耗时7582.6秒,而m1法仅需5.046秒,计算速度提高了上千倍。可见,采用本发明方法计算概率最优潮流可大幅度提高计算速度,能够满足概率最优潮流在线计算的速度要求。表3m0-m1计算概率最优潮流的时间对比方法m0m1时间(秒)7582.65.046从实验结果可知:本发明所提出的基于sdae并结合mcs法的概率最优潮流在线算法,能够以非常高的精度逼近高维非线性最优潮流模型,从而实现了最优潮流的非迭代计算,具有高计算精度,并且对于训练中未涉及的测试样本也能直接映射出最优潮流值,其计算结果及最优潮流的概率密度曲线与基于内点法的mcs法的计算结果良好吻合,具有很强的泛化能力,同时较内点法大幅度减少了计算时间,从而实现了概率最优潮流的高精度在线计算。综上所述,本发明提出了一种基于sdae并结合mcs法的概率最优潮流快速求解算法,克服了现有算法求解速度慢的问题,能够在不增加硬件成本的前提下,大大提高概率最优潮流的计算速度。此外,本发明引入了最大最小归一化法以及基于动量学习率的小批量梯度下降法,提升了sdae最优潮流模型的训练精度和速度。通过算例仿真分析,验证了本发明所提方法的有效性。因此,本发明可为电力系统概率最优潮流的高精度在线计算提供技术支撑。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1