一种基于用户满意度和强化学习的温控负荷频率响应控制方法与流程
本发明涉及温控负荷频率响应控制方法,尤其涉及一种基于用户满意度与深度强化学习的温控负荷频率响应控制方法。
背景技术:
1、随着电网中可再生能源占比的不断提高,其间歇性、波动性的特点将对电网有功功率平衡和频率稳定性带来很大的挑战。传统电力系统通过调整发电侧机组的出力来维持系统的平衡,调节方式较为单一且会产生额外的经济成本和环境成本;此外,随着电力负荷的增加和可再生能源的广泛接入,发电侧的调节能力逐渐下降。以新能源为主体的新型电力系统能够利用先进的信息技术整合和调度需求侧资源以提供多种辅助服务。因此,合理地控制需求侧资源能够对传统的系统频率调节进行补充,进而增强电力系统的稳定性。
2、在需求侧资源中,温控负荷(thermostatically controlled load,tcl)是一类由恒温器控制开关、能够实现电热转换、温度可调的电力设备,包括热泵、热水器、冰箱、暖通空调等。温控负荷能够被用于提供频率调节服务,这主要是基于以下三点:一是广泛分布于住宅、商业和工业建筑,可调潜能较大;二是具有良好的热存储能力,可以被视为分布式储能设备;三是控制方式较为灵活,能够及时响应系统的功率需求。因此,为充分挖掘需求侧灵活性资源的调频潜力,维持电网频率在一定的偏移范围内,需要对需求侧大规模温控负荷的控制策略进行深入研究。
3、现有技术主要采用的方法有集中控制、分散控制和混合控制。有学者建立一种分层集中式负荷跟踪控制框架,协调需求侧异构温控负荷聚合器并采用状态空间模型进行建模。分散控制将负荷控制的判断机制下放到本地控制端,预先在本地控制端设定程序或阈值,当负荷侧装置检测到重要参数变化时,负荷根据提前设定的策略动作,分散控制的判断在本地端口进行,因而对通信的需求较低,响应速度很快,但控制效果很大程度上受到用户行为和检测装置误差的影响。有研究利用多目标优化方法优化各负荷设置以减少需要的负荷响应量,并基于频率响应指标触发负荷的分散控制。混合控制结合集中控制和分散控制的特征,建立“集中参数设置-分散决策”的控制框架,通过负荷聚合商(load aggregator,la)协调大规模用户和电网控制中心,有学者基于混合控制建立了两阶段控制模型参与能源市场交易,基于混合控制利用温控负荷缓解微网社区光伏和负荷的变化,需要在控制中心与所有聚合体间建立通信网络。在关于温控负荷参与辅助服务的研究中,有文献搭建了动态模型,采用直接负荷控制验证了变频热泵在提供调频服务上具有良好的性能,但主要研究单一空调的动态响应性能,但对于大规模空调负荷的协调控制论述较少。有学者建立变频空调的虚拟储能模型,通过分层控制框架屏蔽了部分模型信息,并采用统一的广播信号简化了下行控制,但为了简化下行控制会牺牲空调集群的可调控容量。
4、温控负荷的控制方式主要有2种,分别为直接开关和温度设定。有学者基于负荷直接开关来实现对频率的调节,该方法的优点是在负荷的调节能力范围内,系统的跟踪精度较高,且对用户舒适度的影响较低;缺点是当负荷的室内温度集中位于温度边界附近时会造成设备频繁开关,不但无法完成调节任务,而且会减少设备的使用寿命。温度设定能够避免上述缺点,但是它的局限性表现在功率的跟踪效果依赖于所设计的控制器(常用的控制器有最小方差控制器、滑模控制器和内模控制器等)。此外,它的局限性还表现在温度的变化范围较大,会对用户的舒适度产生影响等方面。研究者建立了基于优化技术与机器学习模型结合的住宅建筑能量管理系统(energy management system,ems),利用真实住宅数据进行需求响应控制器的训练和测试,模型在保持热舒适性的同时,降低了能量消耗。因此在负荷响应控制过程中考虑用户满意度的影响对调度用户参与调频的积极性具有重要意义。有文献提出一种基于并联结构的混合控制策略,该策略能够提升系统的跟踪精度,减少设备的开关次数,但是温度的变化范围很大,会降低用户的舒适度。
5、近年来兴起的深度强化学习算法为电力系统频率控制问题提供了新的解决思路,利用其强大的搜索学习能力,深度强化学习算法在面对复杂非线性频率控制问题时具有在线优化决策的潜力。研究人员利用深度强化学习的q学习算法实现了分布式发电单元的协同控制,从而消除了系统的频率偏差。然而,q学习算法仅能离散化地从低维度的动作域中选择控制动作,因而无法处理含有连续变量的问题。学者提出一种作用于连续动作域的深度强化学习算法,从而实现了负荷频率的自适应控制。但仅针对单台发电机组或单个住宅建筑进行优化控制,不适用于大规模温控负荷的控制。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于用户满意度和强化学习的温控负荷频率响应控制方法,该方法基于柔性行动器-评判器框架的深度强化学习控制策略,可以减少系统频率波动,而且能够改善用户的满意度。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于用户满意度和强化学习的温控负荷频率响应控制方法,包括下列步骤:
4、1)采用一阶常微分方程建立温控负荷模型以及温控负荷参与调频的电力系统频率响应模型;
5、2)针对采用直接开关控制和温度设定控制这两种控制方式的温控负荷,分别建立两种控制方式下温控负荷的用户满意度调节指标;
6、3)根据步骤2)中建立的用户满意度调节指标,利用模糊综合评判法进行用户满意度的综合评价得到用户满意度;
7、4)根据控制周期的电力系统频率误差信号以及跟踪功率信号,定义频率调节误差指标,将步骤3)所得用户满意度与频率调节误差指标进行加权组合为综合评价指标;
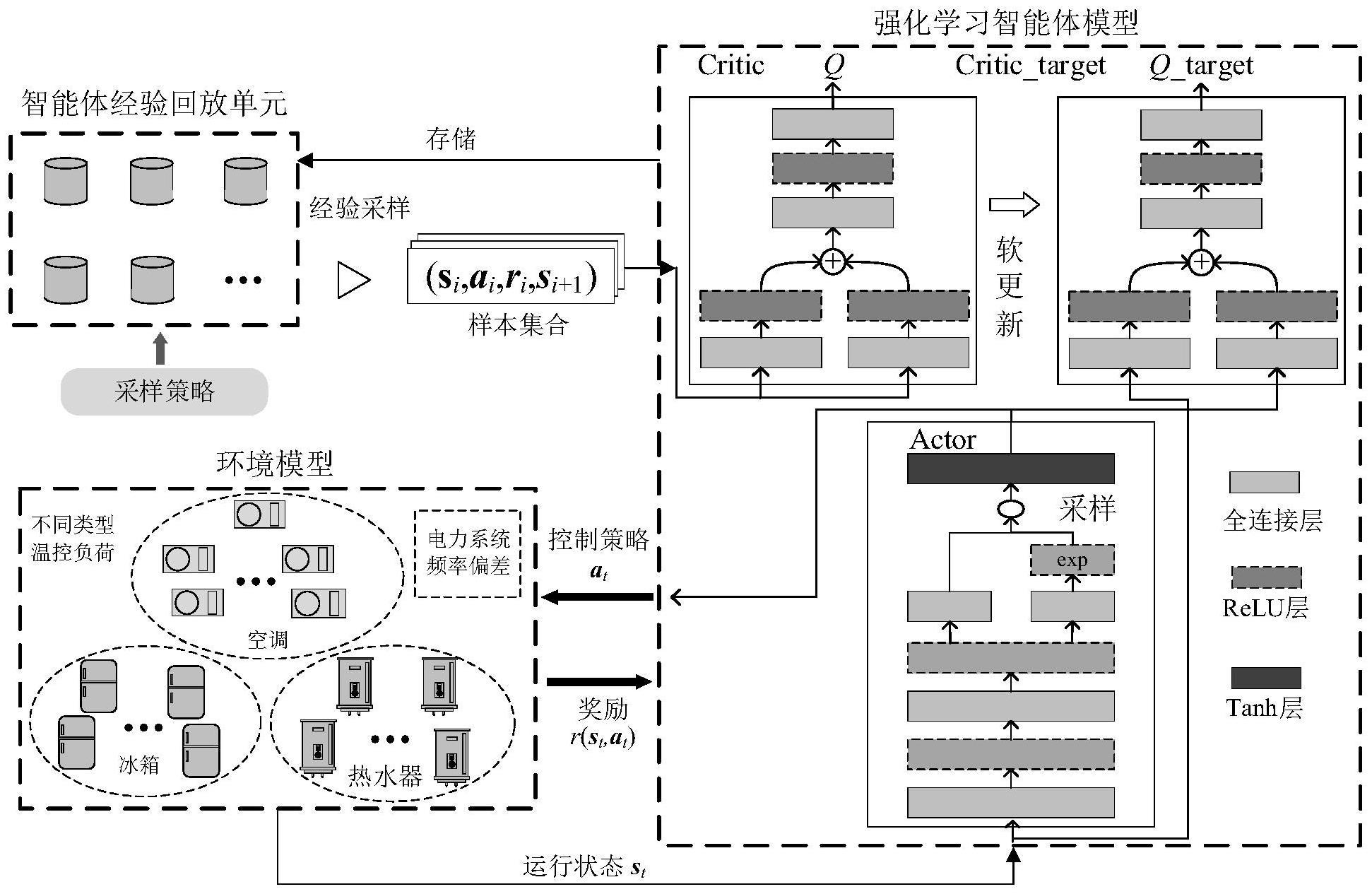
8、5)建立基于柔性行动器-评判器算法的深度强化学习智能体模型,根据电力系统频率变化、需求侧温控负荷运行状态环境信息,构造智能体动作空间、状态空间,根据步骤4)所得综合评价指标构造智能体模型的奖励函数;
9、6)利用柔性行动器-判别器算法训练智能体模型以求解出智能体模型的最优策略,其中训练过程分为智能体目标函数构建、智能体策略迭代与策略更新、智能体参数更新,根据步骤5)中的动作空间、状态空间以及奖励函数并结合策略熵构建智能体的目标函数,智能体通过不断优化策略来实现目标函数最大化,在此过程中智能体利用贝尔曼算子进行策略迭代,然后通过最小化新策略与旧策略的散度实现策略更新,构建智能体模型中q值网络与策略网络的神经网络,q值网络与策略网络以及温度参数根据不同的更新策略进行神经网络参数的迭代更新,使智能体模型的目标函数不断收敛,从而求得智能体模型的最优策略;
10、7)将步骤6)训练好的智能体模型在实际温控负荷集群中进行在线应用,将温控负荷集群的实时运行状态信息、用户满意度信息和电网频率信息输入到智能体控制模型中,训练完成的智能体可以快速计算出当前时刻温控负荷集群的控制指令,温控负荷集群按照此控制指令进行负荷调节。
11、进一步的,步骤1)采用一阶常微分方程建立温控负荷模型,具体步骤包括:
12、11)建立引入状态变量和虚拟变量的一阶常微分方程模型表征任意温控负荷的动态特性;
13、12)根据单个温控负荷动态特性方程计算出温控负荷集群的额定功率之和。
14、进一步的,步骤2)建立两种控制方式下温控负荷的用户满意度调节指标,具体步骤包括:
15、21)针对直接开关控制温控负荷集群,忽略温度设定值对用户舒适度的影响,控制方式直接作用于设备开关,对采用直接开关的温控负荷集群定义储能指标cs,智能体在输入控制指令尽可能使cs接近于0,减少设备的启停频率;
16、22)针对温度设定控制型温控负荷集群,定义不舒适度指标cu,智能体在输入控制指令尽可能使cu接近于0,降低用户的不舒适度。
17、进一步的,所述步骤3)中根据步骤2)中建立的用户满意度调节指标,利用模糊综合评判法进行用户满意度的综合评价得到用户满意度,具体步骤包括:
18、31)构建用户满意度因素集,包括储能指标cs和不舒适度指标cu,即u={cs,cu};
19、32)构建用户满意度评语集,根据用户满意度程度设定五个评语等级,即v={满意,较满意,一般,较不满意,不满意};
20、33)确定各个影响因素的所占权重,因素集由储能指标cs和不舒适度指标构成cu,设定两者对于用户的重要性相同,权重设置为[0.5,0.5];
21、34)建立模糊评判矩阵,对每个因素隶属于各个评语的程度进行评判,隶属度函数选取为高斯函数;
22、35)进行模糊综合评判,评估用户满意度,定义用户满意度m,m越小用户的满意度越高。
23、进一步的,步骤4)中将步骤3)所得用户满意度与频率调节误差指标进行加权组合为综合评价指标,具体步骤包括:
24、41)评估系统的跟踪性能,定义频率调节误差指标erms,erms越小,系统的跟踪精度越高;
25、42)将频率调节误差指标erms与用户满意度m加权组合定义为综合评价指标j。
26、进一步的,步骤5)建立基于柔性行动器-评判器算法的深度强化学习智能体模型,具体步骤包括:
27、51)确立智能体模型的输入信息,即智能体的状态空间,将智能体所控制的温控负荷集群的开关状态、额定功率、室内外温度、温控负荷的温度设定值、电力系统频率偏差以及步骤3)中计算出的用户满意度m共同组成智能体状态空间,将状态空间输入到智能体模型中,实现智能体的环境感知;
28、52)确立智能体模型的输出控制指令,即智能体的动作空间,根据温控负荷直接开关控制和温度设定控制两种控制方式,设置温控负荷的控制指令为负荷开关指令和温度设定值,制定控制指令的约束条件为温控负荷的频繁开关限制、设定温度范围限制;
29、53)根据步骤4)中建立的综合评价指标建立智能体模型的优化目标,即智能体模型所需要的奖励函数,设定奖励函数为用户满意度和频率调节误差指标加权组合形成的综合评价指标j的负值。
30、进一步的,步骤6)中柔性行动器-评判器算法的目标函数在最大化累计奖励的同时最大化策略熵,构建智能体目标函数的具体步骤为:
31、61)构建包括含熵正则项的目标函数,即
32、
33、式中:e(·)为期望函数;π为策略;sq为第q个智能体的状态空间;aq为第q个温控负荷的动作空间;r(sq,aq)为第q个智能体的奖励函数;(sq,aq)~pπ为策略π所形成的状态-动作轨迹;α为温度项,决定了熵对于奖励的影响程度;h(π(·|sq))为状态sq时的策略的熵项;
34、62)设定策略的熵项,计算方法如下:
35、
36、进一步的,步骤6)中智能体利用贝尔曼算子进行策略迭代,具体构建方法如下:
37、71)价值函数由奖励函数和状态空间st+1的期望值组成,更新策略的贝尔曼算子包含奖励函数和新值函数的期望值,计算方法如下:
38、
39、
40、式中:为状态空间为st+1的期望函数;tπ为策略π下的贝尔曼backup算子;γ为奖励的折扣因子,v(sq+1)为状态sq+1的新值函数:
41、
42、进一步的,步骤6)中q值网络通过神经网络输出单值,q值网络参数会有如下更新策略:
43、
44、式中:θ为q值网络参数;φ为策略网络参数;vθ和qθ分别为代入q值网络参数后的新值函数和价值函数;
45、策略网络输出为一个高斯分布,策略网络会有如下更新策略:
46、
47、式中:z(sq)为状态sq时的配分函数;
48、进行温度参数的更新以实现对所有可行动作的迭代测试,更新策略如下:
49、
50、式中:πq为第q个智能体的控制策略;h0为熵项;
51、深度神经网络学习不断更新q值网络参数、策略网络参数以及温度参数,使模型不断收敛,从而求解出智能体模型的最优策略。
52、本发明提出的一种基于用户满意度和强化学习的温控负荷频率响应控制方法,相较于现有技术至少包括如下有益效果:
53、一、本发明考虑用户满意度对温控负荷频率响应的影响,针对开关控制型和温度设定型温控负荷,提出分别建立储能指标和不舒适度指标的负荷调节指标来表征温控负荷用户的满意度情况,通过模糊综合评判法对用户满意度进行综合评价,从而得到用户满意度评价指标,将用户满意度评价指标作为温控负荷参与频率响应的优化目标之一。同时,考虑电力系统频率调节效果,将用户满意度评价指标与频率调节误差指标进行加权组合为目标函数,将其设定为智能体模型奖励函数。此方法对用户满意度有着较强的提升;
54、二、本发明提出建立基于柔性行动器-评判器(soft actor-critic,sac)算法的深度强化学习智能体模型,智能体和环境根据马尔可夫决策过程(markov decisionprocess,mdp)不断进行交互,获取环境状态,采取动作改变环境状态,并取得相应奖励或惩罚作为模型参数的更新指导,持续学习获得最大的累积奖励,做出精准有效的控制决策。此方法对减少频率波动有着较强的提升。
- 还没有人留言评论。精彩留言会获得点赞!