一种基于LSTM深度学习的工业企业短期负荷预测方法与流程
本发明涉及电力数据处理,具体而言,涉及一种基于lstm深度学习的工业企业短期负荷预测模型。
背景技术:
1、短期负荷预测作为工业企业日常运行的重要指导,对其进行精确而高效的预测具有重要的意义和实用价值。对于不同工业企业的用电负荷,由于受生产计划、行业分布、天气、突发事件等综合因素的影响,通过单一的物理数学模型实现工业企业的个性化短期负荷预测相对困难。
2、随着计算机技术的高速发展,各种各样的算法广泛应用于各行业的不同领域。常用的算法可分为传统算法、模糊预测和基本机器学习方法、深度学习算法三大类。这些算法在应用之前,都需要对采集到的历史数据进行预处理,由于在历史用电负荷数据中,存在着大量不完全的、有噪声的、模糊的、随机的数据,这些数据会干扰短期负荷预测的精度。除此以外,预测模型的水平亦决定负荷预测的准确性。短期负荷预测属于非线性回归问题,传统预测方法由于其无法处理非线性关系和大数据,缺乏鲁棒性,难以支撑高效精准的负荷分析。现代模糊预测理论和基本的机器学习方法虽具备学习负荷序列中的非线性能力,但在大数据下分析效率不高,无法充分利用序列中的时序信息,难以实用。深度学习方法的出现,为现实世界复杂时间序列数据的应用提供了新的思路。
3、因此,提出一种基于lstm(long short-term memory用于序列数据处理的循环神经网络)深度学习的工业企业短期负荷预测模型,以满足工业企业短期负荷预测需求。
技术实现思路
1、鉴于此,本发明提出了一种基于lstm深度学习的工业企业短期负荷预测模型,旨在解决传统预测方法无法处理非线性数据缺乏鲁棒性,难以支撑高效精准的负荷分析的问题。
2、本发明提出了一种基于lstm深度学习的工业企业短期负荷预测模型,包括:
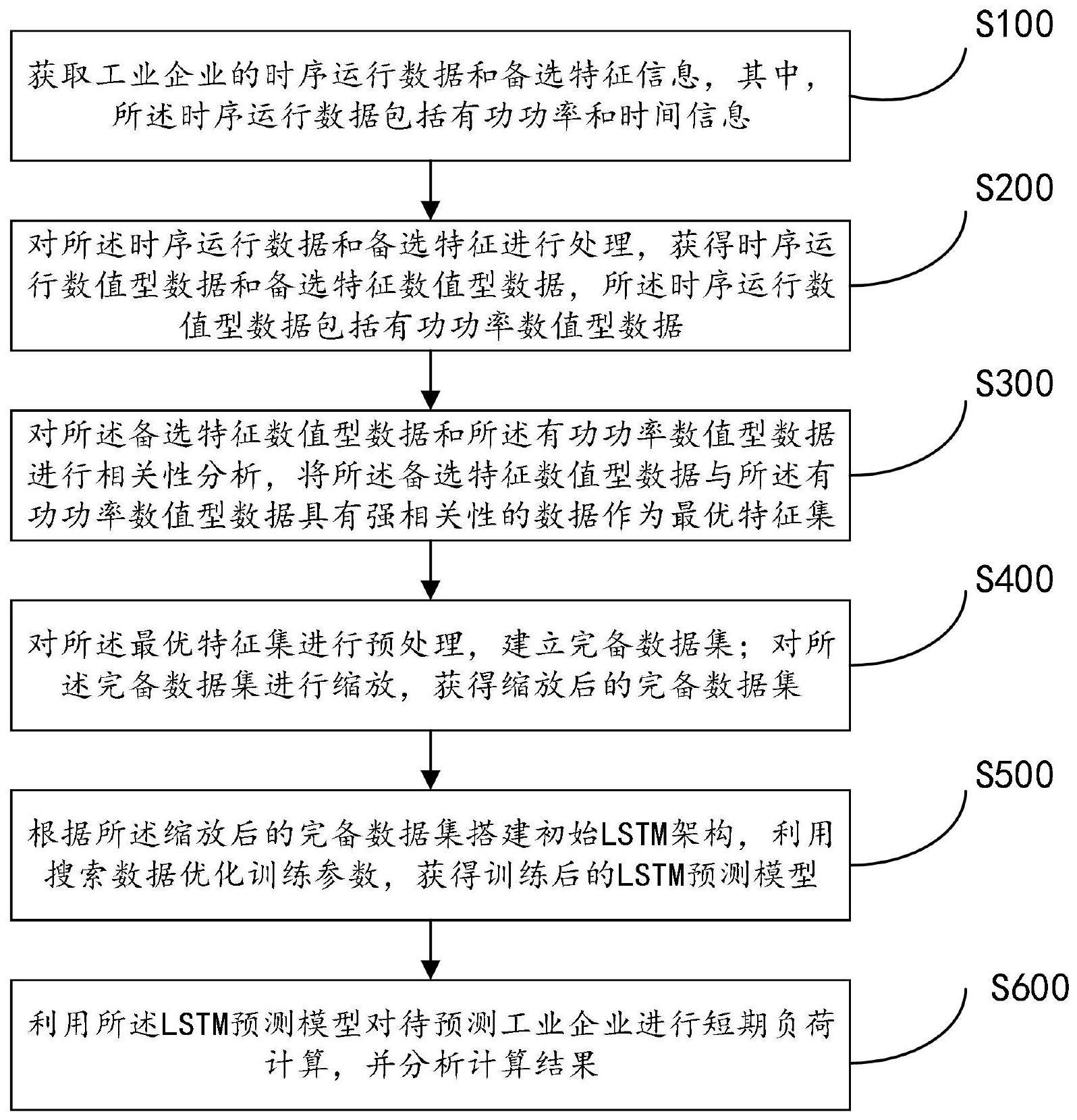
3、步骤s100:获取工业企业的时序运行数据和备选特征信息,其中,所述时序运行数据包括有功功率和时间信息;
4、步骤s200:对所述时序运行数据和备选特征进行处理,获得时序运行数值型数据和备选特征数值型数据,所述时序运行数值型数据包括有功功率数值型数据;
5、步骤s300:对所述备选特征数值型数据和所述有功功率数值型数据进行相关性分析,将所述备选特征数值型数据与所述有功功率数值型数据具有强相关性的数据作为最优特征集;
6、步骤s400:对所述最优特征集进行预处理,建立完备数据集;对所述完备数据集进行缩放,获得缩放后的完备数据集;
7、步骤s500:根据所述缩放后的完备数据集搭建初始lstm架构,利用搜索数据优化训练参数,获得训练后的lstm预测模型;
8、步骤s600:利用所述lstm预测模型对待预测工业企业进行短期负荷计算,并分析计算结果。
9、进一步的,所述步骤s200中对所述时序运行数据和备选特征进行处理,获得时序运行数值型数据和备选特征数值型数据,包括:
10、对所述时序运行数据和所述备选特征进行数据清洗;
11、所述数据清洗包括:
12、缺失值处理,采用中位数法填补缺失的数值点,将同一变量下的时间序列数据按照从小到大的顺序排列,选择中位数对序列中的缺失值进行填补;
13、重复值处理,针对所述同一变量下时间序列数据,若所述序列数据中某一数字出现频次占所述序列长度的比例大于等于0.6时,直接删除该序列;若所述序列数据中某一数字出现频次占所述序列长度的比例小于0.6时,不删除该序列。
14、进一步的,所述步骤s300中对所述备选特征数值型数据和所述有功功率数值型数据进行相关性分析,包括:
15、基于皮尔逊相关系数方法判断所述备选特征数值型数据与有功功率数值型数据之间的相关性,其计算公式为:
16、
17、其中,将各备选特征数值型数据集视作向量x=(x1,x2,x3...),有功功率数值型数据集视作向量y=(y1,y2,y3...),p为衡量两个向量之间的相似度,xi,yi表示向量中对应数据值,表示向量元素的均值;
18、进一步的,所述步骤s300中将所述备选特征数值型数据与所述有功功率数值型数据具有强相关性的数据作为最优特征集,包括:
19、根据p的大小确定相关性强弱;
20、当0.8≤p≤1.0时,所述备选特征数值型数据与所述有功功率数值型数据具有极强相关;
21、当0.6≤p<0.8时,所述备选特征数值型数据与所述有功功率数值型数据具有强相关;
22、当0.4≤p≤0.6时,所述备选特征数值型数据与所述有功功率数值型数据具有中等强度相关;
23、当0.2≤p≤0.4时,所述备选特征数值型数据与所述有功功率数值型数据具有弱相关;
24、当0≤p≤0.2时,所述备选特征数值型数据与所述有功功率数值型数据具有极弱相关。
25、进一步的,所述步骤s400中对所述最优特征集进行预处理,建立完备数据集,包括:
26、以所述最优特征集与有功功率数值型数据为横坐标,以时间序列为纵坐标构成所述完备数据集,并在不改变原来序列顺序的原则下以纵坐标长度为标准将所述完备数据集划分为训练集、验证集和测试集。
27、进一步的,所述步骤s400中对所述完备数据集进行缩放,获得缩放后的完备数据集,包括:
28、采用鲁棒函数法对所述完备数据集中的数据进行缩放,其计算公式为:
29、
30、其中,vi表示特征数据集和负荷数据集中的某个样本值;median表示样本所在列的中位数;iqr表示样本的四分位距;vi'表示某个样本的标准化值,iqr的计算公式为:
31、iqr=q3-q1 (3)
32、其中,将样本所在列的数据由小到大排序,将数据分为四份,其中分隔点分别记为q1、q2、q3。
33、进一步的,所述步骤s500中根据所述完备数据集搭建初始lstm架构,利用搜索数据优化训练参数,获得训练后的lstm预测模型,包括:
34、所述训练参数包括记忆单元、隐藏层层数和dropout参数;
35、所述搜索数据基于随机搜索法和网格搜索法获得;
36、其中,所述随机搜索法是通过scikit-learn提供的randomizedsearchcv中的参数空间确定最优参数的可能存在范围;
37、所述网格搜索法获是在所述随机搜索法的基础上通过对所述训练参数的各个可能取值进行排列组合,列出所有的组合结果生成网格,最后通过将估计函数的参数通过交叉验证的方式得到最优的参数取值结果。
38、进一步的,步骤s600中利用所述lstm预测模型对待预测工业企业进行短期负荷计算,包括:
39、所述lstm接受x值输入序列,所述lstm将x值输入序列映射到相应的顺序并输出y,学习训练过程从t=1到t=τ每一个步长均需进行,对于每一时间点t处,每一层的lstm参数通过以下等式更新其状态:
40、
41、γu=σ(wu[a<t-1>,x<t>]+bu) (5)
42、γf=σ(wf[a<t-1>,x<t>]+bf) (6)
43、γo=σ(wo[a<t-1>,x<t>]+bo) (7)
44、
45、a<t>=γo*g(c<t>) (9)
46、y<t>=g(wya<t>+by) (10)
47、式中,x<t>表示第t步的输入数据;y<t>是其对应的预测结果;a<t>表示传递的状态量;σ、g为激励函数,一般使用tanh、sigmoid函数;γu、γf、γo为更新信息、保留信息、输出信息的控制函数;c<t>为细胞状态信息。
48、进一步的,步骤s600中利用所述lstm预测模型对待预测工业企业进行短期负荷计算,并分析计算结果,其中分析计算结果包括定量分析预测精度;
49、所述定量分析指利用rmse、mse定量分析预测精度,其计算公式如下:
50、
51、
52、其中,rmse(root mean squared error,均方根误差)表示预测值与实际值的差值平方和平均后再求根号,mse(mean squared error,均方误差)表示预测值与实际值的差值平方和求平均;n表示预测点总数;yactual表示实际点的值;ypredicted表示预测点的值。
53、与现有技术相比,本发明的有益效果在于:通过使用lstm深度学习模型,并选择与有功功率强相关的最优特征集,实现了工业负荷短期负荷预测模型建模,可以更准确地捕捉负荷数据的特征和模式,提高预测准确性对于指导工业企业运行具有实用价值。本技术提高了负荷预测准确性,实现了自适应特征学习,通过数据预处理和缩放提升了模型性能,并为工业企业的负荷调度和能源管理提供了精细化支持。
- 还没有人留言评论。精彩留言会获得点赞!