咬尾卷积码的译码方法与流程
本发明属于信道编码技术领域,特别涉及咬尾卷积码的译码方法,可用于军事通信系统、卫星通信系统和蜂窝通信系统以及下一代宽带无线通信系统中的短码场景。
背景技术:
自卷积码被发明以来,它一直作为一种高效的信道编码技术应用在通信系统中。LTE系统作为3GPP标准化组织提出无线空口技术的演进,目前正在全球范围内得到大力的发展和部署,该系统需要实现更高的带宽、更大的容量、更高的数据传输速率、更低的传输时延、更低的运营成本。同时为满足用户对于广播及多播业务等实时业务的高速率需求,LTE系统在信道编码过程中根据不同传输信道采用了Turbo编码和咬尾卷积编码。其中咬尾卷积编码主要用于广播信道BCH、上下行的控制信息DCI、UCI编码过程,并且对于不同类型的传输信道和控制信道使用的编码方案和编码速率也有所不同。咬尾卷积码编码过程首先会用到咬尾技术,即保证格形起始和结尾在同一个状态,这就需要将被编码的数据块的最后几个比特作为寄存器的初始状态。
卷积码在结尾的时候通常要做归零处理,运用维特比VA译码,好处是在结尾后,trellis网格图结束的最后一个零状态是确定的,但是在信息比特流较短的情况下,结尾会造成较多的码率损失,性能较差。
Rose Y.Shao等人在其发表的论文“Two Decoding Algorithms for Tailbiting Codes”(IEEE Transactions on Communications,2003:1658-1665)中提出了一种环绕维特比算法WAVA。该译码算法必须将维特比算法应用于整个码字,进行迭代译码,在每一次迭代译码后,对首尾状态进行判断,对所有状态进行搜索回溯,找到首尾状态相同的路径,对路径中权值最大的一条进行译码输出,否则进行下一迭代译码,直到迭代译码次数达到最大迭代次数,进行译码输出,该算法达到了良好的性能,性能逼近了最大似然译码的性能。但是,该方法仍然存在的不足之处是,译码运算复杂度较高,不能得到很好的应用。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种咬尾卷积码的译码方法,在保证译码性能的前提下,降低译码复杂度。
本发明的技术思路是:对信道接收到的对数似然比,进行两次维特比译码,通过比较最终状态的路径度量值选取最优路径,译码输出分别从两次译码中选择可靠度高的比特输出,最终得到良好的译码判决性能。其实现方案包括如下:
1.咬尾卷积码的译码方法,包括:
(1)计算路径度量值:
定义输入比特数为1,输出比特数为n,移位寄存器数为m的(n,1,m)卷积码,它有2m个状态;
在编码端,利用(n,1,m)卷积码对信息比特x=[x1,x2,...,xp,...xC]进行编码,得到长度为L=n×C的发送码字;其中xp表示第p个信息比特,1≤p≤C,C为发送的信息比特长度;
在译码端,将从信道接收到的对数似然比y=[y1,y2,...,yq,...yL]按顺序分成C组,每组有n个对数似然比和2n条路径,计算每条路径的度量值为:
其中,yq表示第q个对数似然比,1≤q≤L,dist[j]表示第j条路径度量值,0≤j≤2n-1,ai为j的第i位二进制表示:j=(a1,a2,...ai...an),ai=j%(2i),ai∈{0,1},1≤i≤n;
(2)设译码的初始状态度量值为0,根据每条路径的度量值dist[j]进行第一次Viterbi译码,当最后一组路径度量值译码结束后,得到第一次译码的最终的状态度量值;
(3)将第一次译码的最终状态度量值作为第二次译码的初始状态值,再进行第二次Viterbi译码,得到第二次译码的最终状态度量值;
(4)根据第二次译码的最终状态度量值进行回溯,即将第二次译码的前m比特作为译码比特输出的前m比特,将第一次译码的后C-m比特作为译码输出的后C-m比特,最终输出第二次译码输出的前m比特和第一次译码输出的后C-m比特,共C比特,译码结束。
第一,本发明由于进行了2次译码,选择第二次译码的前m比特和第一次译码的后C-m比特,这些比特的可靠度比其他比特的可靠度高,可以达到WAVA算法的性能。
第二,本发明由于只进行了2次译码,相比于WAVA算法进行的2m次译码,大大降低了译码复杂度。
附图说明
图1是本发明的译码框图;
图2是本发明中使用的卷积码框图;
图3是本发明中的编码器编码状态转移图;
图4是本发明的译码输出框图;
图5是本发明的误帧率仿真结果图。
具体实施方式
下面结合附图对本发明译码实现作详细描述。
参照图1,本发明的实现步骤如下:
步骤1,编码端产生发送码字:
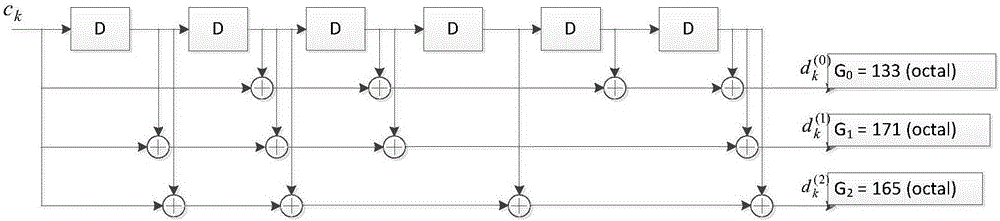
本发明采用的编码器是(3,1,6)卷积码,它有64个状态,每个状态有1bit输入,3bits输出,6个移位寄存器,卷积码结构如图2所示;
本发明的编码采用状态转移图来实现,该状态转移图如图3所示,即在t时刻输入比特为ct={0,1},状态为输出分别为同时跳转到下一时刻的状态其中n=0,1...63,m=0,1...63,n≠m。
令C为发送的信息比特长度,经过卷积码编码后产生长度为L=3C的发送码字。
步骤2,计算路径度量值。
将从信道接收到的对数似然比y=[y1,y2,...,yq,...yL]按顺序分成C组,每组有3个对数似然比和23=8条路径,计算每条路径的度量值为:
其中,yq表示第q个对数似然比,1≤q≤L,dist[j]表示第j条路径度量值,0≤j≤7,ai为j的第i位二进制表示:j=(a1,a2,...ai...a3),ai=j%(2i),ai∈{0,1},1≤i≤3;
步骤3,进行第一次viterbi译码。
3a)设第一次译码的初始状态度量值为0;
3b)在第一时刻,将第一组路径度量值和初始状态度量值进行加比选操作,更新得到下一时刻的状态度量值;
3c)同理,在第t时刻,将第t组路径度量值和t-1时刻的状态度量值进行加比选操作,更新得到t时刻的状态度量值;
3d)重复3c)的操作,直到t=C,得到第一次译码的最终状态度量值,第一次译码结束,其中C为发送的信息比特长度。
步骤4,进行第二次viterbi译码。
4a)设第二次译码的初始状态度量值为第一次译码的最终状态度量值;
4b)在第t+1时刻,将第一组路径度量值和第二次的初始状态度量值进行加比选操作,更新得到下一时刻的状态度量值;
4c)同理,在第C+t时刻,将第t组路径度量值和C+t-1时刻的状态度量值进行加比选操作,更新得到C+t时刻的状态度量值;
4d)重复4c)的操作,直到t=2C,得到第二次译码的最终状态度量值,第二次译码结束,其中C为发送的信息比特长度。
步骤5,回溯输出译码比特:
由于咬尾卷积码的首尾状态是一样的,这导致了第一次译码的最后的判决状态极有可能发生错误,为了提高最后一个状态的准确性,本发明进行了第二次Viterbi译码。由于第一次译码的前6比特的可靠度不高,如果直接从第二次的末尾回溯到第一次的所有比特数作为译码结果,会导致前6个比特出错,所以将第二次译码的前6比特作为译码比特输出的前6比特;
由于中间的度量值的可靠度高,所以将第一次译码的后C-6比特作为译码输出的后C-6比特。最终输出为第二次译码输出的前6比特和第一次译码输出的后C-6比特,共C比特,如图4所示,译码结束。
本发明的效果可通过以下仿真进一步说明:
按照图2的卷积码结构,在码率为1/3,信道为AWGN信道,调制方式为QPSK,信息比特长度为20bits,码长为60bits条件下使用本发明的译码方法和现有WAVA算法对上述卷积码进行了仿真,仿真结果如图5所示。通过仿真发现使用本发明的低复杂度译码方法可以近似达到WAVA算法的译码性能。
- 还没有人留言评论。精彩留言会获得点赞!