极化码的译码方法、译码器及译码设备与流程
本申请涉及译码技术,尤其涉及一种极化码的译码方法、译码器及译码设备。
背景技术:
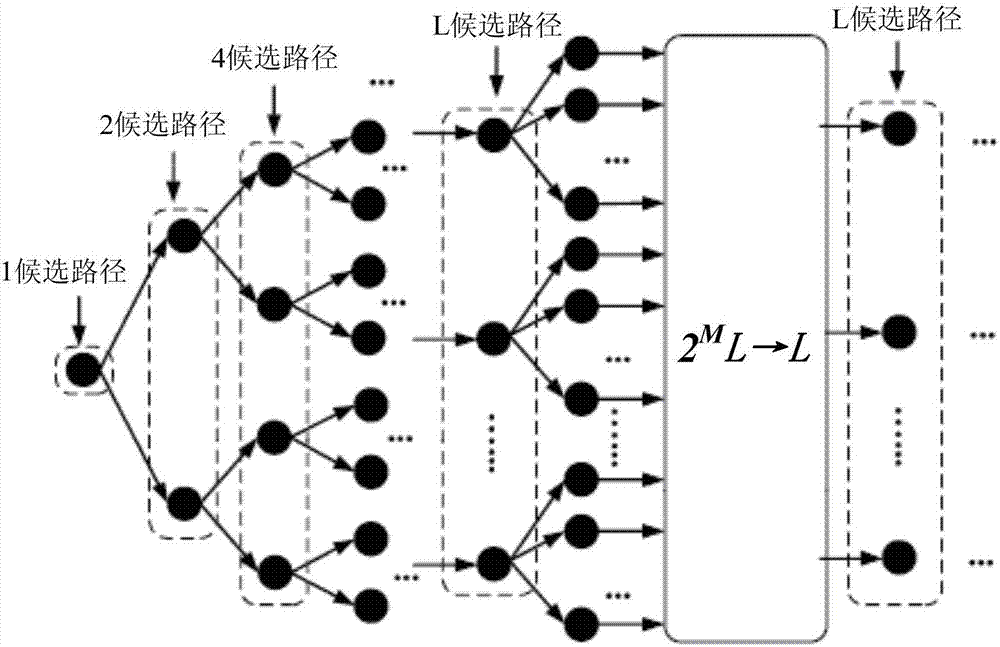
:通信系统通常采用信道编译码提高数据传输的可靠性,以保证通信的质量。土耳其教授arikan提出的极化码(polarcodes)是第一个理论上可以达到香农容量且具有低编译码复杂度的好码。因此,polar码在5g中具有很大的发展和应用前景,并在3gpp(the3rdgenerationpartnerproject,第三代合作伙伴项目)ran1(ran的英文全称:radioaccessnetwork;ran的中文全称:无线接入网络)87次会议上被接纳用于控制信道编译码。目前常用的polar码译码通常采用顺序消除列表(successivecancellationlist,scl)译码。在具体的译码过程中,为了提高译码效率,会采用多比特(multibit)scl译码器进行译码。图1为现有技术中提供的multibitscl译码方法。如图1所示,其中,multibitscl译码器在译码过程中,每一级译码不是针对一个bit译码,而是对连续m个比特进行译码,即每次同时处理m个bit的判决。在得到l条候选路径之后,针对每条候选路径对连续m个bit进行译码,得到2m条候选路径,则l条候选路径最终得到2m×l条候选路径,然后在2m×l条候选路径选取其中l条最优路径输出到下一级。在最后一级译码结束以后,从l条路径中选取满足crc校验关系的最优路径作为译码器的输出结果。然而,在multibitscl译码器通过增加同时处理的比特数量以提高译码效率时,译码复杂度较高。技术实现要素:本申请提供一种极化码的译码方法、译码器及译码设备,以提高译码效率。第一方面,本申请提供一种极化码的译码方法,包括:初始化译码级数,从译码级数i=0开始译码,采取逐级译码的过程,在一级译码结束后,译码级数递增1;根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值,其中,所述m=m1+m2,m1为本级译码待译码的信息比特的数目,m2为本级译码待译码的冻结比特的数目;为了便于说明,将上一级译码得到的序列称为第一译码后序列,将本级译码得到的序列称为第二译码后序列;针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,确定l条最优译码路径;其中,所述第一译码后序列在本级译码中对应2m个译码路径,所述l条最优译码路径为所述2m个译码路径中分支度量小于其它译码路径的分支度量的译码路径,各所述分支度量是根据所述m个对数似然比值确定的;针对l条第一译码后序列,在l×l条最优译码路径中确定本级译码对应的l条第二译码后序列。本实施例通过根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值,针对任一第一译码后序列,根据第一译码后序列在本级译码中对应的m个对数似然比值,确定l条最优译码路径;其中,l条最优译码路径对应的分支度量均小于其它译码路径的分支度量,各分支度量是根据m个对数似然比值确定的,即通过分支度量,确定每个第一译码后序列对应的l条最优译码序列,从而针对l条第一译码后序列,在l×l条最优译码路径中确定本级译码对应的l条第二译码后序列,相对于获取2m×l条译码路径,并在2m×l条译码路径中选择l条译码路径而言,复杂度降低。在一种可能的设计中,所述在l×l条最优译码路径中确定本级译码对应的l条所述第二译码后序列,包括:获取每条最优译码路径各自对应的第一译码后序列的第一累积度量;根据每条最优译码路径对应的分支度量和对应的第一译码后序列的第一累积度量之和,得到l×l个第二累积度量;根据所述l×l个第二累积度量,确定l条所述第二译码后序列,所述l条第二译码后序列对应的第二累积度量均小于其它最优译码路径对应的第二累积度量。在一种可能的设计中,若所述冻结比特数量m2等于0,所述根据所述第一译码后序列在本级译码中的m个对数似然比值,确定l条最优译码路径,包括:针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,获取序列全局最优解;其中,所述序列全局最优解对应的分支度量pm等于0;根据各所述对数似然比值的绝对值从小到大的排序结果,确定l-1项目标加扰序列;根据所述序列全局最优解和所述l-1项目标加扰序列,确定l条最优译码路径。在一种可能的设计中,所述根据所述对数似然比值的绝对值从小到大的排序结果,确定l-1项目标加扰序列,包括:以所述序列全局最优解为索引,在加扰项集合中查找所述索引对应的备选加扰项集合,所述备选加扰项集合中包括p个初始加扰序列;根据各所述对数似然比值的绝对值从小到大的排序结果,在所述p个初始加扰序列中选择l-1项初始加扰序列,其中,所述l-1项初始加扰序列对应的分支度量均小于所述p个初始加扰序列中的其它初始加扰序列对应的分支度量,所述分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,所述加扰位的排序位置与所述对数似然比值的绝对值的排序位置相同;根据所述对数似然比值的绝对值从小到大的排序结果以及各所述对数似然比值的原始顺序,对所述初始l-1项中的加扰序列进行换序,确定所述l-1项目标加扰序列,其中,换序后的加扰位的排序位置与所述对数似然比的原始排序位置相同。本实施例通过在加扰项集合中确定备选加扰项集合,不需对2m条译码路径进行排序得到最优的l条路径,只需要从一个2m条译码路径的一个子集中(备选加扰项集合)中得到l条路径,当m的取值非常大时,计算复杂度收益会很明显。在一种可能的设计中,在加扰项集合中查找所述索引对应的备选加扰项集合之前,还包括:将备选加扰项集合初始化为空,将长度为m的矢量中的信息比特中的每个比特任取1或0,得到2m个长度为m的矢量v;对所述2m个矢量中的每一个矢量v,将所述矢量v与编码矩阵相乘,得到2m个长度为m的矢量x;根据每个所述矢量x中比特值1的数量,将所述2m矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;遍历所述m+1个si集中的每个集合,针对任一集合si,获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序,其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;依次取所述si集合中的每个矢量x,在所述备选加扰项集合中确定是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量,若存在所述l个矢量指示的分支度量小于所述x指示的分支度量,则继续遍历si集合中的其它矢量x;若不存在所述l个矢量指示的分支度量小于所述x指示的分支度量,将所述矢量x加入所述备选加扰项集合,直至遍历完成,得到所述备选加扰项集合。在一种可能的设计中,所述信息比特数量m1大于等于第一预设值且所述信息比特数量m1小于m时,所述根据所述第一译码后序列在本级译码中的m个对数似然比值,确定l条最优译码路径,包括:针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,获取无约束的序列全局最优解;其中,所述无约束的序列全局最优解对应的分支度量pm等于0;根据编码矩阵,得到所述无约束的序列全局最优解对应的编码前序列;从所述编码前序列中提取所述冻结比特的位置对应的比特,得到冻结比特序列;根据所述冻结比特序列和各所述对数似然比值的绝对值从小到大的排序结果,确定l项目标加扰序列;根据所述无约束的序列全局最优解和所述l项目标加扰序列,确定l条最优译码路径。在一种可能的设计中,所述根据所述冻结比特序列和各所述对数似然比值的绝对值从小到大的排序结果,确定l项目标加扰序列,包括:以所述冻结比特序列为索引,在加扰项集合中查找所述索引对应的备选加扰项集合,所述备选加扰项集合中包括p个初始加扰序列;根据各所述对数似然比值的绝对值从小到大的排序结果,在所述p个初始加扰序列中选择l项初始加扰序列,其中,所述l项初始加扰序列对应的分支度量均小于所述p个备选加扰项中的其它初始加扰序列对应的分支度量,所述分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,所述加扰位的排序位置与所述对数似然比值的绝对值的排序位置相同;根据所述对数似然比值的绝对值从小到大的排序结果以及各所述对数似然比值的原始顺序,对所述初始l项中的加扰序列进行换序,确定所述l项目标加扰序列,其中,换序后的加扰位的排序位置与所述对数似然比的原始排序位置相同。在一种可能的设计中,在以所述冻结比特序列为索引,在加扰项集合中查找所述索引对应的备选加扰项集合之前,还包括:将长度为m的矢量中的预设的冻结比特的比特值任取0或1;针对任一长度为m的矢量,将所述长度为m的矢量中的信息比特中的每个比特任取1或0,得到2m1个长度为m的矢量v,并将备选加扰项集合初始化为空,其中,每个长度为m的矢量各自对应一个备选加扰项集合;对所述2m1个矢量中的每一个矢量v,将所述矢量v与编码矩阵相乘,得到2m1个长度为m的矢量x;根据每个所述矢量x中比特值1的数量,将所述2m1矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;遍历所述m+1个si集中的每个集合,针对任一集合si,获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序,其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;依次取所述si集合中的每个矢量x,在所述备选加扰项集合中确定是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量;若存在所述l个矢量指示的分支度量小于所述x指示的分支度量,则继续遍历si集合中的其它矢量x;若不存在所述l个矢量指示的分支度量小于所述x指示的分支度量,将所述矢量x加入所述备选加扰项集合,直至遍历完成,得到所述参考比特序列对应的备选加扰项集合,所述备选加扰项集合中包括p个备选加扰项。在一种可能的设计中,在所述备选加扰项集合中确定是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量,包括:针对任意第一比较矢量和第二比较矢量,所述第一比较矢量为所述备选加扰项集合中的矢量,所述第二比较矢量为所述si集合中的矢量,在所述第一比较矢量对应的十进制数小于等于所述第二比较矢量对应的十进制数时,确定从右到左所述第一比较矢量的第一个比特值为1的比特所处的位置j;在确定所述第二比较矢量中针对位置j的右边存在取值为1的比特时,确定所述第二比较矢量中位置j右边的第一个取值为1的比特位置为位置k;将所述第一比较矢量中的位置j和所述第二比较矢量中位置k的值设置为0;若能够遍历完所述第一比较矢量中的所有取值为1的比特,则所述第一比较矢量指示的分支度量小于所述第二比较矢量指示的分支度量。在一种可能的设计中,所述信息比特数量m1大于0且所述信息比特数量m1小于等于第一预设值时,所述根据所述第一译码后序列在本级译码中对应的m个对数似然比值,确定l条最优译码路径,包括:将每个信息比特的取值任取1或0,并根据所述冻结比特的位置,得到2m1个长度为m的矢量e;根据所述m个对数似然比值,计算每个矢量e对应的分支度量,得到2m1个分支度量;根据每个矢量e对应的分支度量的大小,确定l条最优译码路径。在一种可能的设计中,所述根据所述l×l个第二累积度量,确定l条所述第二译码后序列,包括:通过并行排序网络并行执行每个第二累积度量分别与其它第二累积度量进行比较的过程,得到每个第二累积度量与其它第二累积度量之间的大小关系;根据每个第二累积度量与其它第二累积度量之间的大小关系,进行关系累加处理,得到每个第二累积度量对应的累加值;根据累加值从小到大的顺序,确定前l个第二累加值对应的第二译码后序列。在一种可能的设计中,所述根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值之前,还包括:获取初始译码的第一译码信息,所述第一译码信息包括初始译码对应的译码排列,所述译码排列用于指示冻结比特和信息比特的数量和分布,所述初始译码对应的译码排列中的信息比特的数量大于等于第二预设值,且所述初始译码对应的译码排列中的信息比特的数量小于第三预设值,所述第三预设值等于母码长度减1;根据所述初始译码对应的冻结比特和信息比特的数量和分布,将所述译码排列拆分成至少两个子译码排列;根据本级译码对应的子译码排列,获取本级译码待译码的信息比特的数目以及本级译码待译码的冻结比特的数目。通过拆分的方式进行译码,可以大大减少译码复杂度,提高译码效率。在一种可能的设计中,所述根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值之前,还包括:获取初始译码的第二译码信息,所述第二译码信息包括多级译码排列对应的译码长度,其中,所述多级译码排列包括本级译码级别和所述本级译码级别之后的连续多个译码级别;若所述本级译码级别对应的译码排列与所述本级译码之后连续的至少一个译码级别对应的译码排列合并形成的目标译码排列的长度小于等于最大处理并行度,且所述目标译码排列的长度为2的整数次幂,并满足全部比特为冻结比特或者信息比特的数量小于第一预设值,则对所述本级译码级别对应的译码排列与所述本级译码之后连续的至少一个译码级别对应的译码排列进行合并,得到合并后的译码排列;根据合并后的译码排列,获取本级译码待译码的信息比特的数目以及本级译码待译码的冻结比特的数目。通过合并的方式进行译码,可以减少对数似然比值的计算时间,以及译码时间提高了译码效率。第二方面,本申请提供一种极化码的译码器,包括:对数似然比值获取模块,用于根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值,其中,所述m=m1+m2,m1为本级译码待译码的信息比特的数目,m2为本级译码待译码的冻结比特的数目;译码路径确定模块,用于针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,确定l条最优译码路径;其中,所述第一译码后序列在本级译码中对应2m个译码路径,所述l条最优译码路径为所述2m个译码路径中分支度量小于其它译码路径的分支度量的译码路径,各所述分支度量是根据所述m个对数似然比值确定的;译码序列确定模块,用于针对l条第一译码后序列,在l×l条最优译码路径中确定本级译码对应的l条第二译码后序列。在一种可能的设计中,所述译码序列确定模块,具体用于:获取每条最优译码路径各自对应的第一译码后序列的第一累积度量;根据每条最优译码路径对应的分支度量和对应的第一译码后序列的第一累积度量之和,得到l×l个第二累积度量;根据所述l×l个第二累积度量,确定l条所述第二译码后序列,所述l条第二译码后序列对应的第二累积度量均小于其它最优译码路径对应的第二累积度量。在一种可能的设计中,若所述冻结比特数量m2等于0,所述译码路径确定模块具体用于:针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,获取序列全局最优解;其中,所述序列全局最优解对应的分支度量pm等于0;根据各所述对数似然比值的绝对值从小到大的排序结果,确定l-1项目标加扰序列;根据所述序列全局最优解和所述l-1项目标加扰序列,确定l条最优译码路径。在一种可能的设计中,所述译码路径确定模块具体用于:以所述序列全局最优解为索引,在加扰项集合中查找所述索引对应的备选加扰项集合,所述备选加扰项集合中包括p个初始加扰序列;根据各所述对数似然比值的绝对值从小到大的排序结果,在所述p个初始加扰序列中选择l-1项初始加扰序列,其中,所述l-1项初始加扰序列对应的分支度量均小于所述p个初始加扰序列中的其它初始加扰序列对应的分支度量,所述分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,所述加扰位的排序位置与所述对数似然比值的绝对值的排序位置相同;根据所述对数似然比值的绝对值从小到大的排序结果以及各所述对数似然比值的原始顺序,对所述初始l-1项中的加扰序列进行换序,确定所述l-1项目标加扰序列,其中,换序后的加扰位的排序位置与所述对数似然比的原始排序位置相同。在一种可能的设计中,还包括:加扰项集合获取模块,用于在在加扰项集合中查找所述索引对应的备选加扰项集合之前,将备选加扰项集合初始化为空,将长度为m的矢量中的信息比特中的每个比特任取1或0,得到2m个长度为m的矢量v;对所述2m个矢量中的每一个矢量v,将所述矢量v与编码矩阵相乘,得到2m个长度为m的矢量x;根据每个所述矢量x中比特值1的数量,将所述2m矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;遍历所述m+1个si集中的每个集合,针对任一集合si,获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序,其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;依次取所述si集合中的每个矢量x,在所述备选加扰项集合中确定是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量,若存在所述l个矢量指示的分支度量小于所述x指示的分支度量,则继续遍历si集合中的其它矢量x;若不存在所述l个矢量指示的分支度量小于所述x指示的分支度量,将所述矢量x加入所述备选加扰项集合,直至遍历完成,得到所述备选加扰项集合。在一种可能的设计中,所述译码路径确定模块具体用于:针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,获取无约束的序列全局最优解;其中,所述无约束的序列全局最优解对应的分支度量pm等于0;根据编码矩阵,得到所述无约束的序列全局最优解对应的编码前序列;从所述编码前序列中提取所述冻结比特的位置对应的比特,得到冻结比特序列;根据所述冻结比特序列和各所述对数似然比值的绝对值从小到大的排序结果,确定l项目标加扰序列;根据所述无约束的序列全局最优解和所述l项目标加扰序列,确定l条最优译码路径。在一种可能的设计中,所述译码路径确定模块具体用于:以所述冻结比特序列为索引,在加扰项集合中查找所述索引对应的备选加扰项集合,所述备选加扰项集合中包括p个初始加扰序列;根据各所述对数似然比值的绝对值从小到大的排序结果,在所述p个初始加扰序列中选择l项初始加扰序列,其中,所述l项初始加扰序列对应的分支度量均小于所述p个备选加扰项中的其它初始加扰序列对应的分支度量,所述分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,所述加扰位的排序位置与所述对数似然比值的绝对值的排序位置相同;根据所述对数似然比值的绝对值从小到大的排序结果以及各所述对数似然比值的原始顺序,对所述初始l项中的加扰序列进行换序,确定所述l项目标加扰序列,其中,换序后的加扰位的排序位置与所述对数似然比的原始排序位置相同。在一种可能的设计中,还包括:加扰项集合获取模块,用于在以所述冻结比特序列为索引,在加扰项集合中查找所述索引对应的备选加扰项集合之前,将长度为m的矢量中的预设的冻结比特的比特值任取0或1;针对任一长度为m的矢量,将所述长度为m的矢量中的信息比特中的每个比特任取1或0,得到2m1个长度为m的矢量v,并将备选加扰项集合初始化为空,其中,每个长度为m的矢量各自对应一个备选加扰项集合;对所述2m1个矢量中的每一个矢量v,将所述矢量v与编码矩阵相乘,得到2m1个长度为m的矢量x;根据每个所述矢量x中比特值1的数量,将所述2m1矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;遍历所述m+1个si集中的每个集合,针对任一集合si,获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序,其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;依次取所述si集合中的每个矢量x,在所述备选加扰项集合中确定是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量;若存在所述l个矢量指示的分支度量小于所述x指示的分支度量,则继续遍历si集合中的其它矢量x;若不存在所述l个矢量指示的分支度量小于所述x指示的分支度量,将所述矢量x加入所述备选加扰项集合,直至遍历完成,得到所述参考比特序列对应的备选加扰项集合,所述备选加扰项集合中包括p个备选加扰项。在一种可能的设计中,所述加扰项集合获取模块还具体用于:针对任意第一比较矢量和第二比较矢量,所述第一比较矢量为所述备选加扰项集合中的矢量,所述第二比较矢量为所述si集合中的矢量,在所述第一比较矢量对应的十进制数小于等于所述第二比较矢量对应的十进制数时,确定从右到左所述第一比较矢量的第一个比特值为1的比特所处的位置j;在确定所述第二比较矢量中针对位置j的右边存在取值为1的比特时,确定所述第二比较矢量中位置j右边的第一个取值为1的比特位置为位置k;将所述第一比较矢量中的位置j和所述第二比较矢量中位置k的值设置为0;若能够遍历完所述第一比较矢量中的所有取值为1的比特,则所述第一比较矢量指示的分支度量小于所述第二比较矢量指示的分支度量。在一种可能的设计中,所述信息比特数量m1大于0且所述信息比特数量m1小于等于第一预设值时,所述译码路径确定模块具体用于:将每个信息比特的取值任取1或0,并根据所述冻结比特的位置,得到2m1个长度为m的矢量e;根据所述m个对数似然比值,计算每个矢量e对应的分支度量,得到2m1个分支度量;根据每个矢量e对应的分支度量的大小,确定l条最优译码路径。在一种可能的设计中,所述译码序列确定模块还具体用于:通过并行排序网络并行执行每个第二累积度量分别与其它第二累积度量进行比较的过程,得到每个第二累积度量与其它第二累积度量之间的大小关系;根据每个第二累积度量与其它第二累积度量之间的大小关系,进行关系累加处理,得到每个第二累积度量对应的累加值;根据累加值从小到大的顺序,确定前l个第二累加值对应的第二译码后序列。在一种可能的设计中,还包括:译码排列拆分模块,用于在所述根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值之前,获取初始译码的第一译码信息,所述第一译码信息包括初始译码对应的译码排列,所述译码排列用于指示冻结比特和信息比特的数量和分布,所述初始译码对应的译码排列中的信息比特的数量大于等于第二预设值,且所述初始译码对应的译码排列中的信息比特的数量小于第三预设值,所述第三预设值等于母码长度减1;根据所述初始译码对应的冻结比特和信息比特的数量和分布,将所述译码排列拆分成至少两个子译码排列;根据本级译码对应的子译码排列,获取本级译码待译码的信息比特的数目以及本级译码待译码的冻结比特的数目。在一种可能的设计中,还包括:译码排列合并模块,用于在所述根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值之前,获取初始译码的第二译码信息,所述第二译码信息包括多级译码排列对应的译码长度,其中,所述多级译码排列包括本级译码级别和所述本级译码级别之后的连续多个译码级别;若所述本级译码级别对应的译码排列与所述本级译码之后连续的至少一个译码级别对应的译码排列合并形成的目标译码排列的长度小于等于最大处理并行度,且所述目标译码排列的长度为2的整数次幂,并满足全部比特为冻结比特或者信息比特的数量小于第一预设值,则对所述本级译码级别对应的译码排列与所述本级译码之后连续的至少一个译码级别对应的译码排列进行合并,得到合并后的译码排列;根据合并后的译码排列,获取本级译码待译码的信息比特的数目以及本级译码待译码的冻结比特的数目。第三方面,本申请还提供一种极化码的译码设备,所述译码设备包括接收器和处理器,所述接收器用于接收编码设备发送的待译码序列,所述处理器用于执行第一方面及第一方面各种可能的设计对所述待译码序列进行译码。第四方面,本申请还提供一种存储介质,所述存储介质包括可读存储介质以及存储在所述可读存储介质上的计算机程序,该计算机程序用于实现第一方面及第一方面各种可能的设计所对应的译码方法。附图说明图1为现有技术中提供的multibitscl译码方法;图2示出了本申请实施例可能适用的一种网络架构;图3为本申请一实施例提供的极化码的译码方法的流程示意图;图4为本申请一实施例提供的极化码的译码方法的流程示意图;图5为本申请一实施例提供的备选加扰项集合生成示意图;图6为本申请一实施例提供的冻结比特处理的原理示意图;图7为本申请一实施例提供的极化码的译码方法的流程示意图;图8为本申请一实施例提供的备选加扰项集合生成示意图;图9为本申请一实施例提供的矢量比较示意图;图10为本申请一实施例提供的译码方法的流程示意图;图11为本申请一实施例提供的并行sorter网络的结构示意图;图12为本申请一实施例提供的并行排序网络电路模块示意图;图13为本申请一实施例提供的极化码的译码器的结构示意图;图14为本申请另一实施例提供的极化码的译码器的结构示意图;图15为本申请一实施例提供的极化码的译码设备的硬件结构示意图。具体实施方式本申请实施例描述的网络架构以及业务场景是为了更加清楚的说明本申请实施例的技术方案,并不构成对于本申请实施例提供的技术方案的限定,本领域普通技术人员可知,随着网络架构的演变和新业务场景的出现,本申请实施例提供的技术方案对于类似的技术问题,同样适用。本申请实施例的技术方案可以应用4g、5g通信系统或未来的通信系统,也可以用于其他各种无线通信系统,例如:全球移动通讯(globalsystemofmobilecommunication,gsm)系统、码分多址(cdma,codedivisionmultipleaccess)系统、宽带码分多址(widebandcodedivisionmultipleaccess,wcdma)系统、通用分组无线业务(generalpacketradioservice,gprs)、长期演进(longtermevolution,lte)系统、lte频分双工(frequencydivisionduplex,fdd)系统、lte时分双工(timedivisionduplex,tdd)、通用移动通信系统(universalmobiletelecommunicationsystem,umts)等。本申请实施例可以应用于对信息比特进行极化(polar)编码的场景,可应用于wifi、4g、5g以及未来的通信系统中。图2示出了本申请实施例可能适用的一种网络架构。如图2所示,本实施例提供的网络架构包括:网络设备01和终端02。本申请实施例所涉及到的终端可以包括各种具有无线通信功能的手持设备、车载设备、可穿戴设备、计算设备或连接到无线调制解调器的其他处理设备,以及各种形式的用户设备(terminaldevice),移动台(mobilestation,ms)等等。本申请实施例所涉及到的网络设备是一种部署在无线接入网中用以为终端提供无线通信功能的设备。在本实施例中,该网络设备例如可以为图2所示的基站,该基站可以包括各种形式的宏基站,微基站,中继站,接入点等等。本领域技术人员可以理解,其它需要译码的网络设备也可以应用本申请提供的方法,本实施例并不限于基站。在本实施例中,发送端在对信息序列进行极化编码后,将编码后的序列发送给接收端,接收端对该编码后的序列进行译码,得到信息序列。当上述的网络设备为发送端时,则对应的终端为接收端,当上述的发送端为终端时,则对应的接收端为网络设备。在本实施例中,编码采用polar码,这里的polar码包括但不限于arikanpolar码、pc-polar码、ca-polar码、pc-ca-polar码。arikanpolar是指原始的polar码,没有与其它码级联,只有信息比特和冻结比特。pc-polar是级联了奇偶校验(paritycheck,pc)的polar码,ca-polar是级联了crc的polar码及其他级联polar码。pc-ca-polar码是同时级联了pc和循环冗余校验(cyclicredundancycheck,crc)的polar码。pc-polar和ca-polar是通过级联不同的码来提高polar码的性能。其中,polar码是一种线性块码,其编码矩阵为gn,编码过程为ungn=xn,其中un=(u1,u2,...,un)是一个二进制的行矢量,长度为n(即母码长度);gn是一个n×n的矩阵,且这里矩阵是f2的克罗内克幂(kroneckerpower),定义为具体而言,un=(u1,u2,...,un)中包括k个信息比特和n-k个冻结比特。一般可以将该n-k个冻结比特填充为全0符号,其中,k≤n。实际上,只需要收发端预先约定,冻结比特的值和位置可以被任意设置。例如,编码器和译码器先验约定为0,编码时输入0进行编码,译码时直接使用0作为对应bit的先验信息。对于译码端,在知道冻结比特的值和位置,以及信息比特的位置的情况下,对发送端发送的编码后序列进行译码,得到信息比特。常用的译码方法有多比特(multibit)scl,但是多比特scl译码在比特数m较多的情况下,复杂度较高。本申请提供一种极化码的译码方法,以解决译码复杂度高的问题。图3为本申请一实施例提供的极化码的译码方法的流程示意图。本实施例的执行主体,可以为上述的网络设备或终端。本实施例提供的方法包括:s301、根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值,其中,所述m=m1+m2,m1为本级译码待译码的信息比特的数目,m2为本级译码待译码的冻结比特的数目。在接收端接收到发送端发送的编码后序列之后,接收端开始译码。接收端根据编码后序列的长度,或者母码长度等,来初始化译码级数。例如,母码长度n=2048,每级译码长度为m=16,则译码级数为128。在译码过程中,初始化译码级数,从译码级数i=0开始译码,采取逐级译码的过程,在一级译码结束后,译码级数递增1,继续对译码级别i=i+1进行译码,直至最后一级译码完成。在本实施例中,每级译码过程相似,本实施例以任一级译码过程为例,对译码的实现方式进行详细说明。为了便于说明,将上一级译码得到的序列称为第一译码后序列,将本级译码得到的序列称为第二译码后序列。在译码过程中,在上一级译码结束后,得到l条第一译码后序列,即备选的接收端编码后序列。在该第一译码后序列的基础上,可以计算得到本级译码过程中所需的m个对数似然比值。其中,对数似然比值的数量为本级译码待译码的冻结比特的数量m1和信息比特的数量m2之和,即每个待译码的比特各自对应一个对数似然比值。s302、针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,确定l条最优译码路径;其中,所述第一译码后序列在本级译码中对应2m个译码路径,所述l条最优译码路径为所述2m个译码路径中分支度量小于其它译码路径的分支度量的译码路径,各所述分支度量是根据所述m个对数似然比值确定的。在本实施例中,通过分支度量来确定最优译码路径。其中,分支度量pm由m个对数似然比得到。具体可通过如下公式一得到:其中,αi代表本级译码中的第i个比特对应的对数似然比值,ηi=1-2βi,其中βi为每个译码路径中的译码结果,即每个比特的编码结果。本领域技术人员可以理解,针对第一译码后序列所对应的下一级所有的译码路径(候选路径),每个路径中相同位置的比特所对应的对数似然比值相同,所不同的是每个对数似然比值对应的ηi的符号不同,例如编码结果为0,则ηi=1,编码结果为1,则ηi=-1。由此,不同的译码路径对应不同的pm。进一步地,pm的取值与译码路径的似然值成反比。即pm的取值越小,译码路径正确的概率越大。具体地,第一译码后序列在本级译码中对应2m个译码路径,本实施例在2m个译码路径中找到l个最优译码路径。该l个最优译码路径的分支度量小于2m个译码路径中除该l个最优译码路径之外的其它译码路径的分支度量。例如,可以先确定第一译码后序列对应的序列全局最优解,该序列全局最优解对应的分支度量为0,然后在序列全局最优解的基础上进行加扰,在加扰过程中,以得到pm最小为原则,最终得到l-1个目标加扰序列,通过该l-1个目标加扰序列对序列全局最优解进行加扰,得到l-1个最优译码路径,同时该序列全局最优解为一个最优译码路径,最终得到l个最优译码路径。s303、针对l条第一译码后序列,在l×l条最优译码路径中确定本级译码对应的l条所述第二译码后序列。在本实施例中,针对每个第一译码后序列,得到l条最优译码路径,针对l条第一译码后序列,最终得到l×l条最优译码路径,然后在在l×l条最优译码路径中确定l条第二译码后序列即可,不需要在2m×l条译码路径中选择l条第二译码后序列,大大简化了运算复杂度。在一种可能的实现方式中,确定l条第二译码后序列的实现方式可以为:获取每条最优译码路径各自对应的第一译码后序列的第一累积度量;根据每条最优译码路径对应的分支度量和对应的第一译码后序列的第一累积度量之和,得到l×l个第二累积度量;根据l×l个第二累积度量,确定l条第二译码后序列,l条第二译码后序列对应的第二累积度量均小于其它最优译码路径对应的第二累积度量。本领域技术人员可以理解,最终输出的译码结果是对每一级幸存路径组成的总路径进行crc校验,选择最优的总路径作为译码器的输出结果。因此,在l×l条最优译码路径中,确定l条第二译码后序列时,需要考虑上一级以及上上一级的累积度量。具体地,第一累积度量为对应的上一级的分支度量以及上上一级等直至第一级分支度量的累加。将每条最优译码路径与该最优译码路径对应的第一译码后序列的第一累积度量求和,得到本级译码对应的l×l个第二累积度量,对l×l个第二累积度量从小到大进行排序,将前l个第二累积度量对应的最优译码路径作为第二译码后序列。本实施例通过根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值,针对任一第一译码后序列,根据第一译码后序列在本级译码中对应的m个对数似然比值,确定l条最优译码路径;其中,l条最优译码路径对应的分支度量均小于其它译码路径的分支度量,各分支度量是根据m个对数似然比值确定的,即通过分支度量,确定每个第一译码后序列对应的l条最优译码序列,从而针对l条第一译码后序列,在l×l条最优译码路径中确定本级译码对应的l条第二译码后序列,相对于获取2m×l条译码路径,并在2m×l条译码路径中选择l条译码路径而言,复杂度降低。下面针对不同的信息比特数量和冻结比特数量,对上述实施例中的s302进行详细说明。第一种实现方式:冻结比特数量m2=0,即全部为信息比特。本实施例通过对序列全局最优解进行加扰得到。具体地,针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,获取序列全局最优解;其中,所述序列全局最优解对应的分支度量pm=0;根据各所述对数似然比值的绝对值从小到大的排序结果,确定l-1项目标加扰序列;根据所述序列全局最优解和所述l-1项目标加扰序列,确定l条最优译码路径。在本实施例中,在本实施例中,序列全局最优解即x0=(1-η0,...,1-ηm-1)/2,ηi=sgn(αi)时x0的取值。其中sgn(·)为符号函数,当αi大于等于0时,ηi等于1;当αi小于0时,ηi等于-1。由此,针对公式一可知,序列全局最优解对应的分支度量pm=0。在x0基础上加小的扰动即可得到l条最优译码路径,即x0,x1,...,xl-1,其中x1=x0+p1,x2=x0+p2,......xl-1=x0+pl-1,p1、p2......pl-1为在最优解x0基础上的l-1个加扰序列,该加扰序列即对应了扰动。在本实施例中,在确定加扰序列的过程中,是以所确定的加扰序列使得pm值最小为准。具体地,由上述可知,pm值越小,对应的译码路径正确的概率越大。在序列全局最优解的基础上,需要加扰序列对应的pm越小越好。在序列全局最优解的基础上,当对某一位进行加扰时,则该位对应的对数似然比值的符号取反,其它不变。此时,pm的值不再为零,而是由于加扰项的影响,而发生改变,pm的值此时即为该对数似然比值的绝对值。因此,根据对数似然比序列的绝对值从小到大的排序结果,可以确定l-1项目标加扰序列。以一个具体的实施例为例,其中,m=8,l=8。具体可如表一和表二所示。表一序号pm(从小到大)译码路径加扰项100000000020.20337010000000100000030.214177000000100000001040.2762000100000001000050.294453000010000000100060.30119001000000010000070.34377100000001000000080.417547010000100100001090.479570101000001010000100.4978230001001000010010表二α绝对值排序α对应加扰项0.343776100000000.203371010000000.301195001000000.27623000100000.2944534000010000.5718077000001000.2141772000000100.689546800000001如表二所示,第一译码后序列在本级译码中对应的8个对数似然比按顺序如表一中的α列所示,如表一所示,序列全局最优解为00000000。对m个对数似然比的绝对值进行从小到大排列,排序结果可如“绝对值排序”列所示。对全局序列最优解进行加扰之后,对应的加扰后的分支度量如公式二所示。公式二示出了一个加扰位对应的分支度量,对于两个加扰位对应的分支度量,则是两个对数似然比的绝对值之和,对于三个加扰位,以此类推。由上可知,第二位对应的α1的绝对值最小,因此,根据该α1对第二位进行加扰,对应的加扰项为01000000,第七位对应的α6次小,根据该α6对第七位进行加扰,对应的加扰项为00000010,依次类推。同时,由于α1+α6<α5,即绝对值排序1+绝对值排序2<绝对值排序7,因此,加扰项对应的加扰位为第二位和第七位,而不是第六位,此时的加扰项为01000010。由此,即得到了7项目标加扰序列为01000000、00000010、00010000、00001000、00100000、10000000、01000010。其中,目标加扰序列中的“1”代表对应位置上的全局最优解的比特符号进行翻转。通过目标加扰序列对序列全局最优解进行加扰,最后得到l条最优译码路径,即上述序号1至序号8对应的译码路径。在上述实施例的基础上,为了能够快速得到加扰项,还可以设置加扰项集合,具体可如图4所示实施例。图4为本申请一实施例提供的极化码的译码方法的流程示意图,如图4所示,该方法包括:s401、针对任一第一译码后序列,根据第一译码后序列在本级译码中对应的m个对数似然比值,获取序列全局最优解;其中,序列全局最优解对应的分支度量pm=0。s402、以序列全局最优解为索引,在加扰项集合中查找所述索引对应的备选加扰项集合,备选加扰项集合中包括p个初始加扰序列;s403、根据各所述对数似然比值的绝对值从小到大的排序结果,计算每个初始加扰序列对应的分支度量;s404、对p个分支度量进行排序,在p个初始加扰序列中选择l-1项初始加扰序列,其中,l-1项初始加扰序列对应的分支度量均小于p个初始加扰序列中的其它初始加扰项对应的分支度量;所述分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,所述加扰位的排序位置与所述对数似然比值的绝对值的排序位置相同;s405、根据所述对数似然比值的绝对值从小到大的排序结果以及各所述对数似然比值的原始顺序,对所述初始l-1项中的加扰序列进行换序,确定所述l-1项目标加扰序列;其中,换序后的加扰位的排序位置与所述对数似然比的原始排序位置相同。s406、根据序列全局最优解和l-1项目标加扰序列,确定l条最优译码路径。为了便于说明,下面结合表三和表四所示进行说明。表三序号pm(从小到大)译码路径加扰项101111000020.010584111101000000010030.01818111000000001000040.028764111001000001010050.159110100000010000060.169584110101000010010070.17718110000000011000080.1877641100010000110100表四α绝对值排序α对应加扰项-0.53369810000000-0.20391501000000-0.159300100000-0.018182000100000.4098377000010000.0105841000001000.1965314000000100.27256600000001根据x0=(1-η0,...,1-ηm-1)/2,ηi=sgn(αi),得到序列全局最优解为11110000。以序列全局最优解为索引,在加扰项集合中确定备选加扰项集合,备选加扰项集合中包括p个初始加扰序列。其中,加扰项集合中包括不同的序列全局最优解对应的备选加扰项集合。在本实施例中,以11110000为索引,查找到的备选加扰项集合中的p个初始加扰序列为:00000000、10000000、01000000、00100000、00010000、00001000、00000100、00000010、11000000、10100000、01100000、10010000、11100000。在本实施例中,各初始加扰序列中的加扰位是由分支度量所对应的至少一个对数似然比值的绝对值的排序位置确定的。例如,针对初始加扰序列10000000,其加扰位为第一位,对应绝对值排序为1的对数似然比值的绝对值,对应的pm=0.010584,针对01000000,其加扰位为第二位,对应绝对值排序为2的对数似然比值的绝对值,对应的pm=0.01818,针对00100000,其加扰位为第三位,对应绝对值排序为3的对数似然比值的绝对值,对应的pm=0.159,再例如,针对11000000,其加扰位为第一位和第二位,对应绝对值排序为1和2的对数似然比值,对应的pm=0.010584+0.01818=0.028764。对于初始加扰序列对应的pm的值,依次类推,本实施例此处不再赘述。在上述实施例的基础上,对得到的pm进行从小到大排序,选取前7个pm对应的初始加扰序列。在本实施例中,以上述计算得到的pm值为例,从小到大的顺序为0.010584、0.01818、0.028764等,对应的初始加扰序列为00000100,00010000、00010100等。本领域技术人员可以理解,由于分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,加扰位的排序位置与对数似然比值的绝对值的排序位置相同,因此,还需要根据对数似然比值的绝对值从小到大的排序结果以及各对数似然比值的原始顺序,对初始l-1项中的加扰序列进行换序,确定l-1项目标加扰序列。例如,针对10000000,绝对值排序为1,对应的对数似然比值的原始顺序为6,则将加扰位由第一位换序至第六位,得到的目标加扰序列为00000100,依此类推,最终得到了7项目标加扰序列为00000100、00010000、00010100、00100000、00100100、00110000、01100100。再使用目标加扰序列对全局最优加扰序列进行加扰,得到l条最优译码路径为:11110000、11110100、11100000、11100100、11010000、11010100、11000000、11000100。本实施例通过在加扰项集合中确定备选加扰项集合,不需对2m条译码路径进行排序得到最优的l条路径,只需要从一个2m条译码路径的一个子集中(备选加扰项集合)中得到l条路径,当m的取值非常大时,计算复杂度收益会很明显。下面以一个具体的实施例,来说明备选加扰项集合的生成方法。本领域技术人员可以理解,各备选加扰项集合在设计时事先用以下流程计算得到并放入译码器中供译码时查询使用,也可以在译码前或者译码过程中实时计算得到。图5为本申请一实施例提供的备选加扰项集合生成示意图。如图5所示,该方法包括:s501、将长度为m的矢量中的信息比特中的每个比特任取1或0,得到2m个长度为m的矢量v;s502、对2m个矢量中的每一个矢量v,将矢量v与编码矩阵相乘,得到2m个长度为m的矢量x;s503、根据每个矢量x中比特值1的数量,将2m矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;s504、置i=0;s505、初始化对应于该长度为m的矢量的备选加扰项集合为空s506、获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序;其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;s507、取si中的第一个矢量x,记为z;s508、判断备选加扰项集合中是否存在l个矢量指示的分支度量小于矢量z指示的分支度量,若否,则执行s509,若是,则执行s510;s509、将矢量z加入备选加扰项集合;s510、是否已遍历si中的所有矢量x,若否,则执行s511,若是,则执行s512;s511、取si中的下一个矢量,记为z,返回s508;s512、i<m?若否,则执行s513,若是,则执行s514;s513、置i=i+1,返回执行s506;s514、将备选加扰项集合存储为长度为m的矢量对应的备选加扰项集合。本领域技术人员可以理解,对于给定并行度为m的场景和给定l的取值时,加扰项集合中的备选加扰项集合都是固定的,当l发生变化时,加扰项集合会发生变化,l越大集合也越大。第二种实现方式:所述信息比特数量m1大于等于第一预设值且小于m。针对m1小于第一预设值的实现方式,可参见第三种实现方式。具体地,假定并行处理粒度m比特,其中包含k个信息比特,(m-k)个冻结比特(所有冻结比特先验为0),其中k=m1。假定fi代表冻结比特,ii代表信息比特,编码前的m比特的样式为[f0,f1,...,fm-k-1,i0,i1,...,ik-1],对于信息比特和冻结比特间插出现的情况,以下处理流程也可以同样处理。处理原理为首先仍然按照x0=(1-η0,...,1-ηm-1)/2,ηi=sign(αi)取到无约束情况下的最优解。但与第一种实现方式不同,该无约束情况下的最优解可能不满足冻结比特位置为0引入的校验关系,所以需要在此无约束最优解基础上引入一个扰动,将该无约束最优解对应的冻结比特位置上的非0值置为0,同时保证该扰动导致的pm变化最小。图6为本申请一实施例提供的冻结比特处理的原理示意图。如图6所示,处理原理为:a:根据x0=(1-η0,...,1-ηm-1)/2,ηi=sign(αi)获取无约束的序列全局最优解,对应的编码前序列u0=x0f,其中,f为编码矩阵,u0中冻结比特位置取值可能不为零,即不是polar码的译码结果。b:在无约束的序列全局最优解x0的基础上,加一个扰动x,对应的编码前序列为u=xf。其中,u中冻结比特位置的取值与u0中对应位置相同(即u0+u后的结果对应冻结比特位置取0,满足polar码校验关系),其它信息比特位置取值的选取为在无约束的序列全局最优解的基础上进行加扰,该加扰方式类似第一种实现方式,即根据各对数似然比值的绝对值从小到大的排序结果进行加扰,使得满足校验方程的情况下分支度量最小。c:符合校验方程(对应冻结比特为0)的译码后序列x’,对应的编码前序列为u’=u0+u=x’f=(x0+x)f。在具体实现过程中,可以将冻结比特对应的扰动和对信息比特的扰动综合考虑,通过一个加扰序列来实现。具体可通过查找加扰项集合来获取加扰序列。具体实现过程可如图7所示。图7为本申请一实施例提供的极化码的译码方法的流程示意图,该方法包括:s701、针对任一第一译码后序列,根据第一译码后序列在本级译码中对应的m个对数似然比值,获取无约束的序列全局最优解;其中,无约束的序列全局最优解对应的分支度量pm=0;s702、根据编码矩阵,得到无约束的序列全局最优解对应的编码前序列;s703、从编码前序列中提取冻结比特的位置对应的比特,得到冻结比特序列;s704、以冻结比特序列为索引,在加扰项集合中查找索引对应的备选加扰项集合,备选加扰项集合中包括p个初始加扰序列;s705、根据各对数似然比值的绝对值从小到大的排序结果,计算每个初始加扰序列对应的分支度量;s706、对p个分支度量进行排序,在p个初始加扰序列中选择l项初始加扰序列,其中,l项初始加扰序列对应的分支度量均小于p个备选加扰项中的其它初始加扰序列对应的分支度量;分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,加扰位的排序位置与对数似然比值的绝对值的排序位置相同;s707、根据对数似然比值的绝对值从小到大的排序结果以及各对数似然比值的原始顺序,对初始l项中的加扰序列进行换序,确定l项目标加扰序列;其中,换序后的加扰位的排序位置与对数似然比的原始排序位置相同;s708、根据无约束的序列全局最优解和l项目标加扰序列,确定l条最优译码路径。本实施例与图4所示实施例所不同的是,本实施例先得到冻结比特序列,再以冻结比特序列为索引,来确定备选加扰项集合。在得到备选加扰项集合之后,后续流程与图4所示实施例类似,本实施例此处不再赘述。在本实施例中,在得到无约束的序列全局最优解x0之后,通过编码矩阵f可以得到对应的编码前序列u0=x0f,然而,u0中冻结比特位置取值可能不为零,即在该编码前序列的基础上,获取的冻结比特序列并不是全零序列,该冻结比特序列可能并不是最终正确的冻结比特序列,为了便于区分,本实施例将该冻结比特序列记为f0',...,f'm-k-1。然后以f0',...,f'm-k-1为索引,在加扰项集合中查找该索引对应的备选加扰项集合。其中,加扰项集合的一种可能的实现方式可如表五所示:表五该表五可以事先计算得到并放入译码器中供译码时查询使用,也可以在译码前或者译码过程中实时计算得到。下面采用详细的实施例,来说明备选加扰项集合的生成过程。在本实施例中,将长度为m的矢量中的预设的冻结比特的比特值任取0或1。在具体实现过程中,冻结比特所处的位置可以为连续的,也可以为不连续的。其中,为了便于说明,以上述表五为例,以冻结比特所处的位置为连续的为例进行说明。在此基础上,可以将连续的冻结比特同样采用f0',...,f'm-k-1来标识。下面结合图8,对备选加扰项集合的生成过程进行详细说明。在本实施例中,信息比特数量m1=k,冻结比特数量m2=m-k。图8为本申请一实施例提供的备选加扰项集合生成示意图。如图8所示,该方法包括:s801、初始化f0',...,f'm-k-1的比特全为0;s802、将f0',...,f'm-k-1置于长度为m的矢量中的冻结比特所处的位置,将长度为m的矢量中的信息比特中的每个比特任取1或0,得到2k个长度为m的矢量v;s803、对2k个矢量中的每一个矢量v,将矢量v与编码矩阵相乘,得到2k个长度为m的矢量x;s804、根据每个矢量x中比特值1的数量,将2k矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;s805、置i=0;s806、初始化对应于该f0',...,f'm-k-1的备选加扰项集合为空;s807、获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序,其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;s808、取si中的第一个矢量x,记为z;s809、判断备选加扰项集合中是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量,若否,执行s810,若是,执行s811;s810、将矢量z加入备选加扰项集合;s811、是否已遍历si中的所有矢量x,若否,执行s812,若是,执行813;s812、取si中的下一个矢量,记为z,返回s809;s813、i<m?若否,执行s814,若是,执行s815;s814、置i=i+1,并返回执行s807;s815、将该备选加扰项集合存储为该f0',...,f'm-k-1对应的备选加扰项集合;s816、是否已将f0',...,f'm-k-1的比特取值,取遍2m-k种组合?若否,执行s817,若是,则结束流程;s817、将f0',...,f'm-k-1的取值取2m-k种组合中的下一种,重新执行s802后续流程。本领域技术人员可以理解,f0',...,f'm-k-1包括m-k个比特,由于每个比特可以任取0或1,所以f0',...,f'm-k-1的比特取值有2m-k种组合,每种组合对应一个备选加扰项集合。例如,s801至s815可以得到全0比特对应的备选加扰项集合,在s817中,选择下一种组合方式,重复执行s802至s815,可以得到下一组合方式对应的备选加扰项组合,依次类推,可以得到每种组合对应的备选加扰项集合。在上述图5和图8所示的实施例中,在s508和s809中,涉及备选加扰项集合中是否存在l个矢量指示的分支度量小于矢量x指示的分支度量,这就涉及一个矢量patterna=(a0,…,am-1)是否优于另一个矢量patternb=(b0,…,bm-1),即判断针对任意给定的从小到大排序的序列(α'0,…,α'm-1)序列,是否都能保证具体判断patterna是否优于patternb的处理过程可如图9所示。图9为本申请一实施例提供的矢量比较示意图。针对任意第一比较矢量和第二比较矢量,第一比较矢量为备选加扰项集合中的矢量,第二比较矢量为si集合中的矢量,比较方式如图9所示,该方法包括:s901、判断第一比较矢量中1的个数是否大于第二比较矢量中1的个数,若是,则无法比较,若否,则执行s902;s902、判断第一比较矢量对应的十进制数是否小于等于第二比较矢量对应的十进制数时,若否,则无法比较,若是,则执行s903;s903、确定从右到左第一比较矢量的第一个比特值为1的比特所处的位置j;s904、判断第二比较矢量中针对位置j的右边(含j的位置)是否存在取值为1的比特,若否,则无法比较,若是,则执行s905;s905、记第二比较矢量中位置j右边(含j的位置)从右向左数第一个取值为1的比特的位置为位置k;s906、将第一比较矢量中的位置j和第二比较矢量中位置k的值设置为0;s907、是否已经处理到第一比较矢量最左边取值为1的比特,若是,则确定第一比较矢量优于第二比较矢量,若否,则执行s908;s908、取第一比较矢量j左边的取值为1的比特的元素位置为新的j,返回执行s904。以几个具体的例子为例,例如第一比较矢量为10000010,第二比较矢量10010100,第一比较矢量中1的个数小于第二比较矢量中1的个数。第一比较矢量对应的十进制数为65,第二比较矢量对应的十进制数为41。第一比较矢量对应的十进制数大于第二比较矢量对应的十进制数,则无法比较。例如,第一比较矢量为10010000,第二比较矢量为11110000,第一比较矢量中1的个数小于第二比较矢量中1的个数。第一比较矢量对应的十进制数为9,第二比较矢量对应的十进制数为15。确定从右到左第一比较矢量的第一个比特值为1的比特所处的位置j,即1001(j)0000,第二比较矢量中针对位置j的比特的取值是为1,即1111(j)0000,记第二比较矢量中位置j的位置为位置k,将第一比较矢量中的位置j和第二比较矢量中的位置k的值为0,得到新的第一比较矢量为10000000,新的第二比较矢量为11100000。再次取第一比较矢量j左边的取值为1的比特的元素位置为新的j,即1(j)0000000,新的第一比较矢量的十进制数为1,第二比较矢量的十进制数为7。第二比较矢量中j的右边的比特的取值为1,记第二比较矢量中位置j右边的比特取值为1的位置为位置k,即11(k)100000,将第一比较矢量中的位置j和第二比较矢量中位置k的值设置为0,则第一比较矢量最终为00000000,第二比较矢量最终为10100000,此时,已经处理到第一比较矢量最左边取值为1的比特,最终确定10010000优于10010100。通过本实施例,可以对从较多的矢量中,选择部分矢量作为备选加扰项集合中的初始加扰序列,从而在译码过程中,可以获取到有针对性的初始加扰序列,提高了译码效率。在本实施例中,为了便于说明,以spc(singleparitycheck)为例进行说明。其中,spc是指在一组连续的输入编码器的序列中,第一个比特为冻结比特,其它比特均为信息比特,即形如fiiiiiiiiiiiiiii的pattern(f为冻结比特,i为信息比特)。此时根据polar码的生成矩阵特性为:编码后的输出比特序列中第一个比特为其它比特的偶校验,后面其它比特可取任意值。由于编码前序列u0~u15和编码后序列x0~x15的关系为x=u*f,即(x0,x1,…,x15)=(u0,u1,…,u15)*f,其中f为做4次kronecker积结果,即:所以有x0=u0+u1+u2+u3+u4+u5+u6+u7+u8+u9+u10+u11+u12+u13+u14+u15由于u0为frozenbit值固定为0,即x0为信息比特u1~u15的偶校验位。并且,在gf(2)下,f做逆变换后仍为f本身,u=x*f,有x0+x1+x2+x3+x4+x5+x6+x7+x8+x9+x10+x11+x12+x13+x14+x15=u0=0即x0与其它x1~x15满足偶校验的关系。由于这个特性,所以叫做singleparitycheck节点。将f中对应冻结比特的列取出后转置组成16x1的校验矩阵h,为ht=[1111111111111111]根据之前的分析,可知所有x都需满足x·h=0考虑到所有无约束情形下,最优的x不一定能满足上式的校验关系,即可能出现x·h=1和x·h=0两种情形,分别对应将索引f0',…,fm-k-1'选择为f0'=0与f0'=1两种情况。针对f0'=0的情况,通过图9所示方法,可以得到备选加扰项集合为:0000000000000000,1100000000000000,1010000000000000,0110000000000000,1001000000000000,0101000000000000,0011000000000000,1000100000000000,0100100000000000,1000010000000000,1000001000000000,1000000100000000,111100000000000。针对f0'=1的情况,类似地,通过图9所示的方法,备选加扰项集合为:1000000000000000,0100000000000000,0010000000000000,0001000000000000,0000100000000000,0000010000000000,0000001000000000,00000001000000001110000000000000,1101000000000000,1011000000000000,0111000000000000,1100100000000000。这些扰动序列与最优结果相加后产生13条备选路径,经过排序后选择l条最优路径参加所有路径的排序。第三种实现方式在信息比特数量m1大于0且小于等于第一预设值时,可以在所有可能的组合中选择l条最优译码路径。具体可参见图10所示。图10为本申请一实施例提供的译码方法的流程示意图。如图10所示,该方法包括:s1001、将每个信息比特的取值任取1或0,并根据所述冻结比特的位置,得到2m1个长度为m的矢量e;s1002、根据所述m个对数似然比值,计算每个矢量e对应的分支度量,得到2m1个分支度量;s1003、根据每个矢量e对应的分支度量的大小,确定l条最优译码路径。在本实施例中,该预设值可以为系统预先设定的,例如该预设值等于5。即在一个编码前序列中包含的信息比特数量小于等于5的情况。此时其它比特均为冻结比特。每个比特取所有可能的组合,则可能的情况小于等于25=32,即最终得到2m1个长度为m的矢量e。此时根据对数似然比值,得到2m1个分支度量,对分支度量进行从小到大的排序,取前l个分支度量对应的矢量e,作为l条最优译码路径,本实施例可以大大提高译码效率。第四种实现方式由上述可知,针对spc的情况,当冻结比特数量为1,且第一位为冻结比特时,在确定备选加扰项集合时,只需要确定1对应的备选加扰项集合和0对应的备选加扰项集合,相对于多个冻结比特而言,大大减少了计算复杂度。同时,当一级译码过程中,全部为冻结比特时,不需要进行译码,直接输出0即可。综上,在考虑第一种实现方式、第二种实现方式中的spc的情况、第三种实现方式以及冻结比特全为0的输出情况,以及初始译码对应的译码排列中的信息比特的数量大于等于第二预设值,且初始译码对应的译码排列中的信息比特的数量小于第三预设值,可进行拆分译码,其中,第三预设值=母码长度-1,母码长度为编码前的长度。该第二预设值可以与上述的第一预设值相同,也可以不同,本实施例对第二预设值的具体设置方式不做特别限制。具体地,获取初始译码的第一译码信息,第一译码信息包括初始译码对应的译码排列,译码排列用于指示冻结比特和信息比特的数量和分布,根据初始译码对应的冻结比特和信息比特的数量和分布,将译码排列拆分成至少两个子译码排列。例如,如一个长度为16的节点下所有比特的类型为fffifiiifiiiiiii,那么可以拆为fffifiii和fiiiiii两个长度为8的节点处理,其中前者是k<=5的节点,后者是spc的节点。本领域技术人员可以理解,该接收端存在对应16比特的译码器和8比特的译码器。第五种实现方式根据编码前的冻结比特分布信息,如果当前处理的译码长度的与紧接下一个合并以后的总长度为2的整数次幂且信息比特长度仍然小于等于最大的计算并行度,同时不会增加计算复杂度,则对该两个译码进行合并以后一次处理,合并可以连续重复多次,一直到无法继续合并为止。具体地,获取初始译码的第二译码信息,第二译码信息包括多级译码排列对应的译码长度,其中,多级译码排列包括本级译码级别和本级译码级别之后的连续多个译码级别;若本级译码级别对应的译码排列与本级译码之后连续的至少一个译码级别对应的译码排列合并形成的目标译码排列的长度小于等于最大处理并行度,且为2的整数次幂,并满足全部比特为冻结比特,或者信息比特的数量小于第一预设值,则对本级译码级别对应的译码排列与本级译码之后连续的至少一个译码级别对应的译码排列进行合并,得到合并后的译码排列。例如,当前译码对应16个冻结比特,下一个译码也为16个冻结比特,则可以对这两个译码合并成32个冻结比特统一处理。由此可以减少两次长度为16的对数似然比计算时间和一次长度为16的译码时间。下面采用具体的实施例,对上述图3实施例中所涉及的对第二累计度量进行排序的具体实现方式进行详细说明。在本实施例中,通过并行排序网络来实现第二累积度量的排序。具体地,通过并行排序网络并行执行每个第二累积度量分别与其它第二累积度量进行比较的过程,得到每个第二累积度量与其它第二累积度量之间的大小关系;根据每个第二累积度量与其它第二累积度量之间的大小关系,进行关系累加处理,得到每个第二累积度量对应的累加值;其中,若为大于关系,则取值为1,若为小于关系,则取值为0;根据累加值从小到大的顺序,确定前l个第二累加值对应的第二译码后序列。在本实施例中,该并行排序网络可以为并行sorter网络,也可以为并行rn网络等。本实施例对并行排序网络的具体实现方式不做特别限制,只要能够实现上述原理即可。在此,以一个4输入4输出的并行sorter网络为例进行说明。图11为本申请一实施例提供的并行sorter网络的结构示意图。如图11所示,设sorter网络的输入为x={x0,x1,x2,x3},则令d0={x0>x1,x0>x2,x0>x3}定义矩阵dd中下三角部分的值都是由上三角对应位置的值取反得到的。比较的次数为设w(di)为求d中每行的行重,得到4输入4输出的sorter的排序p={p0,p1,p2,p3}为pi=xj|w(dj)=i(i∈[0,3])。例如,当x0=4、x1=7,x2=8,x3=3时,针对大于关系,取值为1,针对小于关系,取值为0,所以对应x0的行重p0=1,对应x1的行重p1=2,对应x2的行重p2=3,对应x3的行重p2=0。在得到所有的行重之后,根据行重(累加值)的排序,即得到了第二累积度量从小到大的顺序,取前l个第二累积度量对应的第二译码后序列。由上可知,d矩阵的上三角部分由一次并行比较生成,比较器数目为将比较器和相应的反相器(用以生成下三角部分)称为d电路;求每行行重为累加电路,称之为w电路,累加的数目与输入数据数目n有关,累加的结果位宽为log2(n);最终输出的排序结果的电路是由w电路的结果作为控制信号的n个n输入选择器,称之为mux网络。作为等价替换的并行排序网络电路模块如图12所示。本领域技术人员可以理解,在根据各对数似然比值的绝对值从小到大的排序结果,在p个初始加扰序列中选择l-1项初始加扰序列,或选择l项初始加扰序列时,也可以采用并行排序网络来实现,对于具体的实现过程,与累积度量的实现过程类似,本实施例此处不再赘述。下面以一个具体的实施例,来说明一个完整的译码过程。在本实施例中,信息比特数量k=1024,码率为1/2,对应的母码长度,即编码前和译码后的比特数量n=2048,每级译码数量m=16。根据置信度大小分配冻结比特和信息比特,然后按照相邻16比特分为一组,考虑每16比特内的冻结比特和信息比特的分布类型。根据不同分布类型中的信息比特个数对各分布进行分类,下表中为包含不同信息比特的分布个数的统计。n=2048包含128个16比特分组,其中全部为冻结比特的分组个数为23个,全部为信息比特对应的分组个数也为23个,这两类分组直接用冻结比特全输出和第一种实现方式来处理。对于其它的一些分布对应的分组如表六所示:表六其中,16i1代表本级译码对应的译码后序列的比特数为16,i1代表信息比特的数量为1,其它依次类推,本实施例此处不再赘述。其中上述所涉及的实现方式的具体实现过程,可参见上述实施例,本实施例此处不再赘述。现有的技术最多只能支持m=4处理,与之相关的是译码时间和llr计算的并行度都受限于m=4。采用本申请的m=16的方式处理,可以同时减少译码和llr计算的时间,总体时间减少到原来的31%。图13为本申请一实施例提供的极化码的译码器的结构示意图。如图13所示,本实施例提供的译码器10包括:对数似然比值获取模块11,用于根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值,其中,所述m=m1+m2,m1为本级译码待译码的信息比特的数目,m2为本级译码待译码的冻结比特的数目;译码路径确定模块12,用于针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,确定l条最优译码路径;其中,所述第一译码后序列在本级译码中对应2m个译码路径,所述l条最优译码路径为所述2m个译码路径中分支度量小于其它译码路径的分支度量的译码路径,各所述分支度量是根据所述m个对数似然比值确定的;译码序列确定模块13,用于针对l条第一译码后序列,在l×l条最优译码路径中确定本级译码对应的l条第二译码后序列。本实施例提供的译码器,可用于执行上述的方法实施例,其实现原理和技术效果类似,本实施例此处不再赘述。图14为本申请另一实施例提供的极化码的译码器的结构示意图。如图14所示,本实施例提供的译码器10还包括:加扰项集合获取模块14、译码排列拆分模块15以及译码排列合并模块16。可选地,所述译码序列确定模块13,具体用于:获取每条最优译码路径各自对应的第一译码后序列的第一累积度量;根据每条最优译码路径对应的分支度量和对应的第一译码后序列的第一累积度量之和,得到l×l个第二累积度量;根据所述l×l个第二累积度量,确定l条所述第二译码后序列,所述l条第二译码后序列对应的第二累积度量均小于其它最优译码路径对应的第二累积度量。可选地,若所述冻结比特数量m2等于0,所述译码路径确定模块12具体用于:针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,获取序列全局最优解;其中,所述序列全局最优解对应的分支度量pm等于0;根据各所述对数似然比值的绝对值从小到大的排序结果,确定l-1项目标加扰序列;根据所述序列全局最优解和所述l-1项目标加扰序列,确定l条最优译码路径。可选地,所述译码路径确定模块12具体用于:以所述序列全局最优解为索引,在加扰项集合中查找所述索引对应的备选加扰项集合,所述备选加扰项集合中包括p个初始加扰序列;根据各所述对数似然比值的绝对值从小到大的排序结果,在所述p个初始加扰序列中选择l-1项初始加扰序列,其中,所述l-1项初始加扰序列对应的分支度量均小于所述p个初始加扰序列中的其它初始加扰序列对应的分支度量,所述分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,所述加扰位的排序位置与所述对数似然比值的绝对值的排序位置相同;根据所述对数似然比值的绝对值从小到大的排序结果以及各所述对数似然比值的原始顺序,对所述初始l-1项中的加扰序列进行换序,确定所述l-1项目标加扰序列,其中,换序后的加扰位的排序位置与所述对数似然比的原始排序位置相同。可选地,还包括:加扰项集合获取模块14,用于在在加扰项集合中查找所述索引对应的备选加扰项集合之前,将备选加扰项集合初始化为空,将长度为m的矢量中的信息比特中的每个比特任取1或0,得到2m个长度为m的矢量v;对所述2m个矢量中的每一个矢量v,将所述矢量v与编码矩阵相乘,得到2m个长度为m的矢量x;根据每个所述矢量x中比特值1的数量,将所述2m矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;遍历所述m+1个si集中的每个集合,针对任一集合si,获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序,其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;依次取所述si集合中的每个矢量x,在所述备选加扰项集合中确定是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量,若存在所述l个矢量指示的分支度量小于所述x指示的分支度量,则继续遍历si集合中的其它矢量x;若不存在所述l个矢量指示的分支度量小于所述x指示的分支度量,将所述矢量x加入所述备选加扰项集合,直至遍历完成,得到所述备选加扰项集合。可选地,所述译码路径确定模块12具体用于:针对任一第一译码后序列,根据所述第一译码后序列在本级译码中对应的m个对数似然比值,获取无约束的序列全局最优解;其中,所述无约束的序列全局最优解对应的分支度量pm等于0;根据编码矩阵,得到所述无约束的序列全局最优解对应的编码前序列;从所述编码前序列中提取所述冻结比特的位置对应的比特,得到冻结比特序列;根据所述冻结比特序列和各所述对数似然比值的绝对值从小到大的排序结果,确定l项目标加扰序列;根据所述无约束的序列全局最优解和所述l项目标加扰序列,确定l条最优译码路径。可选地,所述译码路径确定模块12具体用于:以所述冻结比特序列为索引,在加扰项集合中查找所述索引对应的备选加扰项集合,所述备选加扰项集合中包括p个初始加扰序列;根据各所述对数似然比值的绝对值从小到大的排序结果,在所述p个初始加扰序列中选择l项初始加扰序列,其中,所述l项初始加扰序列对应的分支度量均小于所述p个备选加扰项中的其它初始加扰序列对应的分支度量,所述分支度量的取值是根据初始加扰序列中的加扰位对应的对数似然比值的绝对值确定的,所述加扰位的排序位置与所述对数似然比值的绝对值的排序位置相同;根据所述对数似然比值的绝对值从小到大的排序结果以及各所述对数似然比值的原始顺序,对所述初始l项中的加扰序列进行换序,确定所述l项目标加扰序列,其中,换序后的加扰位的排序位置与所述对数似然比的原始排序位置相同。可选地,还包括:加扰项集合获取模块14,用于在以所述冻结比特序列为索引,在加扰项集合中查找所述索引对应的备选加扰项集合之前,将长度为m的矢量中的预设的冻结比特的比特值任取0或1;针对任一长度为m的矢量,将所述长度为m的矢量中的信息比特中的每个比特任取1或0,得到2m1个长度为m的矢量v,并将备选加扰项集合初始化为空,其中,每个长度为m的矢量各自对应一个备选加扰项集合;对所述2m1个矢量中的每一个矢量v,将所述矢量v与编码矩阵相乘,得到2m1个长度为m的矢量x;根据每个所述矢量x中比特值1的数量,将所述2m1矢量分成m+1个集合s0、s1……sm,其中,si中比特值为1的比特数量为i;遍历所述m+1个si集中的每个集合,针对任一集合si,获取si集合中的每个矢量x形成的二进制数对应的十进制数,根据各十进制数从小到大的顺序,对si集合中的矢量x进行排序,其中,所述矢量x中最左边的比特为最低位,所述矢量x中最右边的比特为最高位;依次取所述si集合中的每个矢量x,在所述备选加扰项集合中确定是否存在l个矢量指示的分支度量小于所述矢量x指示的分支度量;若存在所述l个矢量指示的分支度量小于所述x指示的分支度量,则继续遍历si集合中的其它矢量x;若不存在所述l个矢量指示的分支度量小于所述x指示的分支度量,将所述矢量x加入所述备选加扰项集合,直至遍历完成,得到所述参考比特序列对应的备选加扰项集合,所述备选加扰项集合中包括p个备选加扰项。可选地,所述加扰项集合获取模块14还具体用于:针对任意第一比较矢量和第二比较矢量,所述第一比较矢量为所述备选加扰项集合中的矢量,所述第二比较矢量为所述si集合中的矢量,在所述第一比较矢量对应的十进制数小于等于所述第二比较矢量对应的十进制数时,确定从右到左所述第一比较矢量的第一个比特值为1的比特所处的位置j;在确定所述第二比较矢量中针对位置j的右边存在取值为1的比特时,确定所述第二比较矢量中位置j右边的第一个取值为1的比特位置为位置k;将所述第一比较矢量中的位置j和所述第二比较矢量中位置k的值设置为0;若能够遍历完所述第一比较矢量中的所有取值为1的比特,则所述第一比较矢量指示的分支度量小于所述第二比较矢量指示的分支度量。可选地,所述信息比特数量m1大于0且所述信息比特数量m1小于等于第一预设值时,所述译码路径确定模块12具体用于:将每个信息比特的取值任取1或0,并根据所述冻结比特的位置,得到2m1个长度为m的矢量e;根据所述m个对数似然比值,计算每个矢量e对应的分支度量,得到2m1个分支度量;根据每个矢量e对应的分支度量的大小,确定l条最优译码路径。可选地,所述译码序列确定模块13还具体用于:通过并行排序网络并行执行每个第二累积度量分别与其它第二累积度量进行比较的过程,得到每个第二累积度量与其它第二累积度量之间的大小关系;根据每个第二累积度量与其它第二累积度量之间的大小关系,进行关系累加处理,得到每个第二累积度量对应的累加值;根据累加值从小到大的顺序,确定前l个第二累加值对应的第二译码后序列。可选地,译码排列拆分模块15,用于在所述根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值之前,获取初始译码的第一译码信息,所述第一译码信息包括初始译码对应的译码排列,所述译码排列用于指示冻结比特和信息比特的数量和分布,所述初始译码对应的译码排列中的信息比特的数量大于等于第二预设值,且所述初始译码对应的译码排列中的信息比特的数量小于第三预设值,所述第三预设值等于母码长度减1;根据所述初始译码对应的冻结比特和信息比特的数量和分布,将所述译码排列拆分成至少两个子译码排列;根据本级译码对应的子译码排列,获取本级译码待译码的信息比特的数目以及本级译码待译码的冻结比特的数目。可选地,译码排列合并模块16,用于在所述根据上一级译码得到的l条第一译码后序列,获取每条第一译码后序列在本级译码中对应的m个对数似然比值之前,获取初始译码的第二译码信息,所述第二译码信息包括多级译码排列对应的译码长度,其中,所述多级译码排列包括本级译码级别和所述本级译码级别之后的连续多个译码级别;若所述本级译码级别对应的译码排列与所述本级译码之后连续的至少一个译码级别对应的译码排列合并形成的目标译码排列的长度小于等于最大处理并行度,且所述目标译码排列的长度为2的整数次幂,并满足全部比特为冻结比特或者信息比特的数量小于第一预设值,则对所述本级译码级别对应的译码排列与所述本级译码之后连续的至少一个译码级别对应的译码排列进行合并,得到合并后的译码排列;根据合并后的译码排列,获取本级译码待译码的信息比特的数目以及本级译码待译码的冻结比特的数目。本实施例提供的译码器,可用于执行上述的方法实施例,其实现原理和技术效果类似,本实施例此处不再赘述。上述译码器可应用于网络设备、终端设备、或其他需要执行译码动作的实体。在本申请所提供的几个实施例中,应该理解到,所揭露译码器,可以通过其它的方式实现。例如,以上所描述的译码器实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如根据上述的几种实现方式,每种实现方式各自对应一个模块,再或者多个模块可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。图15为本申请一实施例提供的极化码的译码设备的硬件结构示意图。如图15所示,该译码设备20包括接收器21和处理器22。接收器21用于接收编码设备发送的待译码序列;处理器22用于执行上述的译码方法,对待译码序列进行译码,处理器22执行的动作可以参照上述实施例提供的译码方法中的内容,在此不再赘述。可选地,该译码设备20还可以包括存储器24,该存储器24用于存储数据和程序指令。该存储器24既可以是独立的,也可以跟处理器22集成在一起。当存储器24是独立于处理器22之外的器件时,该译码设备20还可以包括:总线23,用于连接存储器24、接收器21和处理器22。在一种可能的实现方式中,该处理器22可能是一种集成电路芯片。在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路完成。上述的处理器可以是专用集成电路(asic)、现成可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。上述的译码器中的各模块所实现的功能,可以由处理器中的集成逻辑电路完成,该译码器可以理解为集成逻辑电路的一种。该集成逻辑电路例如可以为与非门、比较器等组成的电路。此时,存储器24可以用于缓存数据。在另一种可能的实现方式中,该处理器22可能是一种中央处理单元(英文:centralprocessingunit,简称:cpu),还可以是其他通用处理器、数字信号处理器(英文:digitalsignalprocessor,简称:dsp)。该通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本申请所公开的方法的步骤可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。上述的译码器可以被实现在处理器中,为处理器中的一个功能模块。此时,存储器24中存储有计算机程序,处理器22运行存储器24中存储的计算机程序执行上述的译码方法。本实施例提供的译码设备,可以为网络设备、终端设备、或其他需要执行译码动作的实体。本申请还提供一种存储介质,该存储介质包括可读存储介质以及存储在可读存储介质上的计算机程序,该计算机程序用于实现上述的译码方法。该存储介质可以为随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。最后应说明的是:尽管参照前述各实施例对本方案进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不能使相应技术方案的本质脱离本申请各实施例技术方案的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1