一种通用数据gz格式的多线程压缩与解压方法及装置与流程
本发明属于数据处理技术领域,尤其涉及一种通用数据gz格式的多线程压缩与解压方法及装置。
背景技术:
目前对于文本数据的通用压缩方案,主要采用gz压缩格式。而对于gz压缩格式来说,目前最广泛使用的库是zlib单线程gz压缩,与pigz(A parallel implementation of gzip)多线程gz压缩。采用Zlib与pigz方法的gz格式压缩软件的主要缺点主要有以下两点:
1,通用gz格式压缩软件往往假定输入为单一字符流,即只有一个数据源,对于多源数据,无法很好地进行并行处理。而在大数据领域,最常见的就是多源数据,如互联网用户信息数据收集,在同一时刻可能有多份用户信息需要压缩保存到同一份文件中。在数据量足够大的时候,唯有并行处理这些数据才能满足时间要求。zlib库只是实现了最基本的单线程gz压缩与解压,而pigz则是并行的gz压缩版本,使用pigz并行压缩保存的话,会出现严重的IO竞争,导致IO资源利用率过低,因为,与pigz将压缩与写、解压缩与读绑定在一起;另外,zlib也是将压缩与写、解压缩与读绑定在一起。将压缩与写入、解压缩与读取绑定在一起,虽然简化了用户操作,但这样的使用方式不够灵活,无法根据电脑的CPU与IO性能,使用最佳的读写配置。对于计算能力远远超出IO读写能力的计算机而言,要尽可能发挥计算机的计算性能,必须将读、写操作与解压缩、压缩计算分离开来。
2,Pigz的多线程压缩软件主要实现了单一数据的分块压缩,对于解压缩,却只提供了单线程的解决方案,这使得解压时的效率受到CPU单线程计算能力的限制。而在海量数据的解压读取方面,通过并行多线程的解压方式在产业应用和学术领域也有巨大的需求,如高通量DNA测序产生上百GB的FASTA文件;但事实上在后续生物信息分析中,只能使用1个线程进行解压读取(通常HPC一个计算节点都会提供数十个线程),这实际上就大大延长了分析的时间。
技术实现要素:
本发明提供一种通用数据gz格式的多线程压缩与解压方法及装置,旨在实现将读、写操作与解压缩、压缩计算分离开来的前提下,对原始数据进行多线程压缩,并对压缩后的数据进行多线程解压。
本发明提供了一种通用数据gz格式的多线程压缩与解压方法,包括:压缩步骤S1和解压步骤S2,其中,所述压缩步骤S1包括:
步骤S11,输入原始数据,并将所述原始数据进行分块处理,得到M份数据块;
其中,每份数据块表示为Di,i∈[0,M-1];
步骤S12,利用预置的第一线程池中的N1个线程分别压缩M份所述数据块,压缩过程中在gz格式的文件头部分预留预设空间,获得M份压缩后的数据gzDi和所述数据gzDi的大小size(gzDi);
步骤S13,按顺序将M份压缩后的所述数据gzDi写入磁盘中,并将对应的M份所述数据gzDi的size(gzDi)顺序写入所述预设空间,得到压缩数据;
其中,所述解压缩步骤S2包括:
步骤S21,输入所述压缩数据,读取写入的所述size(gzDi)的列表信息,并按照所述size(gzDi)的列表信息对所述压缩数据进行切分,得到M份数据块gzDi;
步骤S22,利用预置的第二线程池中的N2个线程分别解压M份所述数据块gzDi,获得M份解压后的原始数据Di;
步骤S23,根据所述size(gzDi)的列表信息串联解压后的所述原始数据Di,得到完整的原始数据。
本发明还提供了一种通用数据gz格式的多线程压缩与解压装置,包括:压缩模块1和解压模块2,其中,所述压缩模块1包括:
分块模块11,用于输入原始数据,并将所述原始数据进行分块处理,得到M份数据块;
其中,每份数据块表示为Di,i∈[0,M-1];
压缩模块12,用于利用预置的第一线程池中的N1个线程分别压缩M份所述数据块,压缩过程中在gz格式的文件头部分预留预设空间,获得M份压缩后的数据gzDi和所述数据gzDi的大小size(gzDi);
写入模块13,用于按顺序将M份压缩后的所述数据gzDi写入磁盘中,并将对应的M份所述数据gzDi的size(gzDi)顺序写入所述预设空间,得到压缩数据;
其中,所述解压缩模块2包括:
切分模块21,用于输入所述压缩数据,读取写入的所述size(gzDi)的列表信息,并按照所述size(gzDi)的列表信息对所述压缩数据进行切分,得到M份数据块gzDi;
解压模块22,用于利用预置的第二线程池中的N2个线程分别解压M份所述数据块gzDi,获得M份解压后的原始数据Di;
串联模块23,用于根据所述size(gzDi)的列表信息串联解压后的所述原始数据Di,得到完整的原始数据。
本发明与现有技术相比,有益效果在于:本发明提供的一种通用数据gz格式的多线程压缩与解压方法及装置,压缩的步骤为,先将输入的原始数据分块处理,然后利用N1个线程分别压缩数据块,得到M份压缩后的数据gzDi和对应的size(gzDi),最后将gzDi写入磁盘,其中,M份size(gzDi)写入gz格式的文件头部分;解压缩的步骤为,读取写入的该size(gzDi)的列表信息,并按照该列表信息对输入的压缩数据进行切分,得到M份数据块;利用N2个线程分别解压M份该数据块,获得M份解压后的原始数据Di;最后串联该原始数据Di,得到完整的原始数据;本发明与现有技术相比,采用与读写IO操作分离的并行的多线程gz压缩方法,将读、写操作与解压缩、压缩计算分离开来,可以根据实际情况进行调度,有效避免多线程压缩写操作的IO竞争;另外,采用多线程gz解压缩方法,让软件在计算机上可以使用更多的CPU进行解压缩计算,从而得到更大的数据输入,单个程序能够获得更高的计算占用率;同时,这种在文件头部分存储size(gzDi)的gz格式,使得可以利用原有的zlib或pigz的单线程解压方法进行解压,也可以采用bgz多线程解压,保证了兼容性,从而使得方法推广成本极低。
附图说明
图1是本发明实施例提供的一种通用数据gz格式的多线程压缩与解压方法的流程示意图;
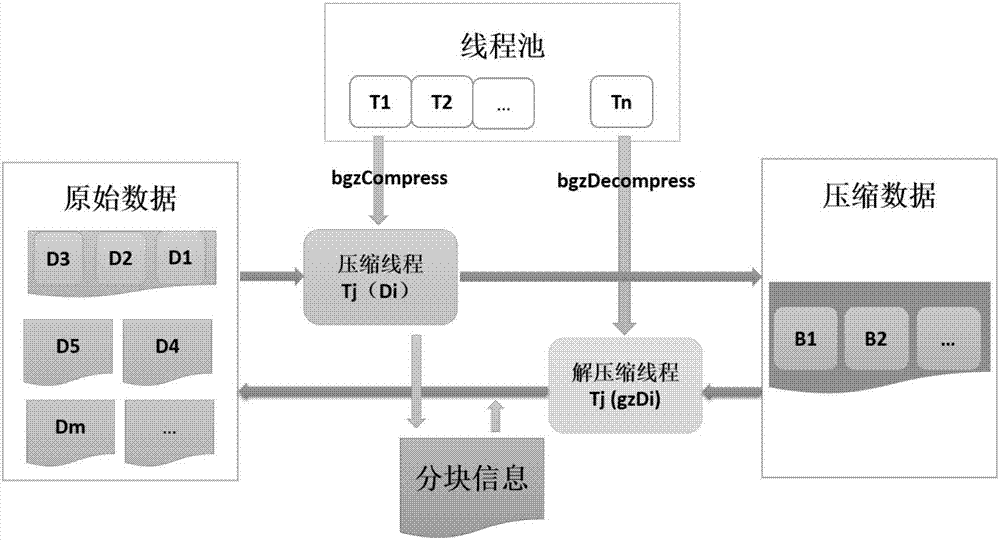
图2是本发明实施例提供的Bgz多线程压缩和解压缩的过程示意图;
图3是本发明实施例提供的一种通用数据gz格式的多线程压缩与解压装置的模块示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
由于现有技术中存在,一方面,在采用pigz并行压缩保存时,由于pigz将压缩与写、解压缩与读绑定在一起,在IO资源相对于CPU计算有限的情况下,对硬件的利用率十分低下的技术问题;另一方面,zlib和pigz都未能实现gz的多线程解压的技术问题。
为了解决上述技术问题,本发明提出一种通用数据gz格式的多线程压缩与解压方法及装置,针对目前广泛使用的gz压缩格式,开发出针对多源数据的多线程压缩与解压缩解决方案,其中,压缩计算与写操作分离,可以有效避免多线程压缩写操作的IO竞争;多线程gz解压缩方法的提供,让软件在计算机上可以使用更多的CPU进行解压缩计算,从而得到更大的数据输入,单个程序能够获得更高的计算占用率;同时本发明注意到软件兼容的情况,对压缩后的数据结构进行了特别设计,以保证现有的zlib与pigz方法无需改动即可进行单线程解压。
事实上,随着互联网以及电子技术的发展,数据信息量越来越大,计算机性能也越来越好。在数据与硬件之间,需要更适合的软件来衔接,本发明正是提供了一种灵活的大数据多线程压缩读写解决方案,针对文本数据尤其适用于多数据来源的海量大数据在高性能计算平台上压缩读写,从而让大数据软件能够更全面的发挥高性能计算机(HPC)的计算能力。大数据的存储方案必须经济合理,所以压缩存储是必然的选择。相对于普通数据的直接存储,大数据在存储时使用一定的计算资源进行压缩,降低了数据字符总量以后,再进行存储,可以大大减少IO资源以及硬盘存储空间的占用。这样的方案能够更全面、更协调地使用计算机的各部分,避免直接存储只占用IO不适用CPU的局面,全面发挥HPC的硬件性能。
下面具体介绍本发明提供的方法,本发明是基于zlib开源库的通用数据gz格式多线程压缩与解压算法bgz(block gzip),首先bgz方法利用zlib的数据结构与deflate方法,实现了与读写IO操作分离的压缩、解压函数,即gzwrite=bgzCompress+fwrite,gzread=fread+bgzDecompress;并在内存压缩与解压的基础上,实现多线程。
请参阅图1,为本发明实施例提供的一种通用数据gz格式的多线程压缩与解压方法,所述方法包括:压缩步骤S1和解压步骤S2,其中,所述压缩步骤S1包括:
步骤S11,输入原始数据,并将所述原始数据进行分块处理,得到M份数据块;
其中,每份数据块表示为Di,i∈[0,M-1];
具体地,本发明实施例提供的所述原始数据不局限于一种数据源形式,可以是来自于一个数据源,也可以是多源数据;也不局限于数据份数,可以是一份数据,也可以是多份数据。
具体地,准备原始数据,将待压缩的原始数据载入内存,进行分块处理得到M份数据,若是多份数据,则按照数据来源分类,只对大份数据进行分块。块大小可调,根据机器内存配置来设置,一般默认为10MB。比如,共有10份数据,9份1M大小,1份10G大小,那么只要对10G大小的数据进行分块即可,另9份数据可作为1份处理。
步骤S12,利用预置的第一线程池中的N1个线程分别压缩M份所述数据块,压缩过程中在gz格式的文件头部分预留预设空间,获得M份压缩后的数据gzDi和所述数据gzDi的大小size(gzDi);
具体地,在预先设置第一线程池时,需要根据机器性能,设置合理的线程数N1,一般情况下,线程数N1小于等于机器最大线程数。
具体地,上述并行压缩的过程为,一个线程处理一份数据块,循环使用线程池,直到所有数据完成压缩,不同数据压缩耗时不一,因此需要灵活调度线程池,以保证所有线程都处于计算状态。更具体地,利用预置的第一线程池中的N1个线程分别对应压缩M份所述数据块中的N1个数据块,N1个线程中的任一个线程对应的数据块压缩完毕后,继续利用所述线程处理剩余未压缩的数据块,直至M份所述数据块压缩完毕。
具体地,在gz格式的文件头部分预留预设空间的目的是为了记录多份压缩后数据的size(gzDi),作为后续解压过程中的快速地址索引,从而实现多线程解压。
步骤S13,按顺序将M份压缩后的所述数据gzDi写入磁盘中,并将对应的M份所述数据gzDi的size(gzDi)顺序写入所述预设空间,得到压缩数据;
具体地,根据需求,将压缩后的数据gzDi分别写入硬盘并记录对应的size(gzDi)。若是单硬盘系统,则单线程写入,若是多机器分布式系统即多硬盘系统,则根据实际硬盘数来确定写入线程数量。
其中,记录的size(gzDi)是多线程解压缩所必须的,本发明实施例将size(gzDi)记录在gz压缩格式的数据头中,事实上,也可以根据软件系统需求记录在内存或索引列表中。通过这种特殊设计的压缩后的数据结构,使得解压缩过程可以支持zlib与pigz的单线程解压,也可以利用size(gzDi)进行多线程解压。
其中,所述解压缩步骤S2包括:
步骤S21,输入所述压缩数据,读取写入的所述size(gzDi)的列表信息,并按照所述size(gzDi)的列表信息对所述压缩数据进行切分,得到M份数据块gzDi;
具体地,利用size(gzDi)的列表信息作为快速地址索引来进行切分,并进而实现后续的多线程解压。
步骤S22,利用预置的第二线程池中的N2个线程分别解压M份所述数据块gzDi,获得M份解压后的原始数据Di;
具体地,在预先设置第二线程池时,需要根据机器性能与块的数量,设置合理的线程数N2,一般情况下,线程数N2小于等于机器最大线程数。
具体地,上述并行解压的过程为,一个线程处理一个压缩数据块,循环使用线程池,直到所有数据解压完成。更具体地,利用预置的第二线程池中的N2个线程分别对应解压M份所述数据块gzDi中的N2个数据块,N2个线程中的任一个线程对应的数据块解压完毕后,继续利用所述线程处理剩余未解压的数据块,直至M份所述数据块解压完毕,获得M份解压后的原始数据Di。
具体地,本发明实施例中,所述第一线程池中的N1个线程等于所述第二线程池中的N2个线程。需要说明的是,若数据量较大,数据份数够多,则M最好是N1和N2的整数倍,以免计算资源闲置。事实上,N1并不限定一定等于N2。
步骤S23,根据所述size(gzDi)的列表信息串联解压后的所述原始数据Di,得到完整的原始数据。
说要说明的是,压缩与解压缩都使用了线程池技术实现多线程,压缩过程输入原始数据,产生压缩数据与分块信息;多线程解压缩过程则输入压缩数据与分块信息,获得解压缩后的原始信息,具体如图2所示。
本发明使用线程池对多线程压缩与解压缩进行调度,在不同系统上都能较好的发挥硬件的性能。其多线程调度伪代码如下:
需要说明的是,本发明的一大创新之处在于,将分块信息保存于gz压缩格式数据头中,从而保证了兼容性。使用bgz压缩方法,处理过后的格式,依旧可以使用原有的zlib或pigz的单线程解压方法,进行解压,无需任何修改。而使用bgz多线程解压时,则能够从gz压缩文件本身提取出分块信息,从而实现多线程快速解压。
Gz压缩格式数据头的数据结构如下:
从上述数据结构中,我们可以看到gz数据头中存在一个额外字段,正常情况下,额外字段不参与解压缩过程。存储到硬盘上时,gz数据头的额外字段为空。本发明提供的bgz方法能够可以事先开辟一段固定长度的额外字段(能够存储100block的分块信息),在持续压缩过程中,可以不断修改额外字段,如果数据block数目不足100,则剩余的空间以0填充。如果压缩的数据量较多,当数据块超过100时,则在第101块数据压缩时再一次开辟100block空间的额外字段,以此类推。
目前1个block分块信息占用8Byte,主要记录block的压缩前原始数据大小size(Di)与压缩后大小size(gzDi)。因为是每一个block数据独立压缩,所以每一份压缩后的数据块gzDi都会有一个gz数据头,但不是所有数据头都有含分块信息的额外字段,根据block数的不同,额外字段只存在于gzD100*i+1的数据头中,其中i=0,1,2....
存储于硬盘的bgz文件遵循gzip文件格式,由多个数据块组成,每个数据块内容构成如下:
每个数据块由三个部分构成,头部分,数据部分,尾部分。从ID1到额外的头字段为数据头部分,CRC32与ISIZE则是尾部分。除额外字段,其余内容与普通gzip格式一致,其定义如下:
ID1与ID2:各1字节。固定值,ID1=31(0×1F),ID2=139(0×8B),指示GZIP格式。
CM:1字节。压缩方法。目前只有一种:CM=8,指示DEFLATE方法。
FLG:1字节。标志。
bit 0FTEXT–指示文本数据
bit 1FHCRC–指示存在CRC16头校验字段
bit 2FEXTRA–指示存在可选项字段
bit 3FNAME–指示存在原文件名字段
bit 4FCOMMENT–指示存在注释字段
bit 5-7保留
MTIME:4字节。更改时间。UINX格式。
XFL:1字节。附加的标志。当CM=8时,XFL=2–最大压缩但最慢的算法;XFL=4–最快但最小压缩的算法
OS:1字节。指明操作系统,确切地说应该是文件系统。有下列定义:
0–FAT文件系统(MS-DOS,OS/2,NT/Win32)
1–Amiga
2–VMS/OpenVMS
3–Unix
4–VM/CMS
5–Atari TOS
6–HPFS文件系统(OS/2,NT)
7–Macintosh
8–Z-System
9–CP/M
10–TOPS-20
11–NTFS文件系统(NT)
12–QDOS
13–Acorn RISCOS
255–未知
额外的头字段:
FLG.FEXTRA=1表示存在额外字段,XLEN表示额外字段长度,为800
FLG.FNAME=0表示无原文件
FLG.FCOMMENT=0表示不存在注释信息,若等于1,添加注释信息
FLG.FHCRC=0表示采用默认的CRC32校验,若等于1,则采用CRC16校验
关于上述基于zlib多线程压缩与解压缩算法是为了DNA序列分析服务的,因此在这个生物信息大数据分析的时代,对碱基对信息文件压缩存储的效率的要求还是极为看重,所以单依靠多线程压缩和解压的提升对于海量的数据还是远远不够,我认为如今多线程的办法还可以用在文件读写和传输中,同时我们也是知道压缩存储可以固化在硬件上省区内存读写这一部分,可以让文件的压缩存储效率更高。
除此之外在本次实现的基于zlib多线程压缩解压的算法中,还可以将文件分块的信息写在zlib头文件的额外字段中,这样可以将多线程压缩解压更好的融入进zlib库中,而不用单独多建立一个index文件来记录,可以使多线程压缩解压更加的简单便利的去调用,可以省去index文件的读写时间。
本发明提供的一种通用数据gz格式的多线程压缩与解压方法,采用与读写IO操作分离的并行的多线程gz压缩方法,读、写、压缩与解压缩相互分离,可以根据实际计算平台资源合理搭配压缩与解压缩方式,压缩端与解压端可能不在同一个机器上,根据需要合理分配读写线程、压缩与解压缩线程,以最大程度发挥机器性能。另外,采用多线程gz解压缩方法,让软件在计算机上可以使用更多的CPU进行解压缩计算,从而得到更大的数据输入,单个程序能够获得更高的计算占用率;同时本发明注意到软件兼容的情况,对压缩后的数据结构进行了特别设计,即在文件头部分存储size(gzDi)的gz格式,以保证现有的zlib与pigz方法无需改动即可进行解压。这样一来,大大降低了使用者的版本更新担忧,尤其对于数据生产者与数据使用者分离的情况来说,不存在版本不兼容的情况,使得方法推广成本极低,只有当使用者认为有相关解压缩需求的时候,进行软件更换即可。
请参阅图3,为本发明实施例提供的一种通用数据gz格式的多线程压缩与解压装置,包括:压缩模块1和解压模块2,其中,所述压缩模块1包括:
分块模块11,用于输入原始数据,并将所述原始数据进行分块处理,得到M份数据块;其中,每份数据块表示为Di,i∈[0,M-1];
压缩模块12,用于利用预置的第一线程池中的N1个线程分别压缩M份所述数据块,压缩过程中在gz格式的文件头部分预留预设空间,获得M份压缩后的数据gzDi和所述数据gzDi的大小size(gzDi);
写入模块13,用于按顺序将M份压缩后的所述数据gzDi写入磁盘中,并将对应的M份所述数据gzDi的size(gzDi)顺序写入所述预设空间,得到压缩数据;
其中,所述解压缩模块2包括:
切分模块21,用于输入所述压缩数据,读取写入的所述size(gzDi)的列表信息,并按照所述size(gzDi)的列表信息对所述压缩数据进行切分,得到M份数据块gzDi;
解压模块22,用于利用预置的第二线程池中的N2个线程分别解压M份所述数据块gzDi,获得M份解压后的原始数据Di;
串联模块23,用于根据所述size(gzDi)的列表信息串联解压后的所述原始数据Di,得到完整的原始数据。
关于应用领域,在互联网文本数据归档存储、网络传输和FASTQ数据的普通存储等方面,都使用了gz压缩格式(部分网络传输使用bz2压缩)。对于数据量巨大的软件平台来说,多线程gz压缩方案被广泛使用,在linux平台上主要使用pigz方法,在windows等其他平台上,则对zlib库再开发,实现多线程压缩。这是目前已知的应用领域与应用方式。
而在高通量DNA测序领域,随着生物信息计算的进一步发展,高性能计算机用于生物信息分析,fastq数据可能被多次读取,进行信息统计或计算,所以针对fastq.gz文件格式的多线程解压缩,也将成为一个重要的潜在应用领域。
随着云计算的进一步发展,数据集中处理、集中存储的情况会越来越普遍,无论是存储还是传输,多线程压缩与解压缩都能够得到广泛的使用。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!