数据压缩编码方法、解码方法、其装置及其程序与流程
以下的本实施方式涉及数据压缩编码方法、解码方法、其装置及其程序。
背景技术:
近年来,构思了构筑如下传感器网络:使多个带有传感器的无线终端分散在空间中,并使它们协作获取环境、物理状况。此外,随着汽车的电子控制化的发展,各种车载用的传感器网络得以实用化。
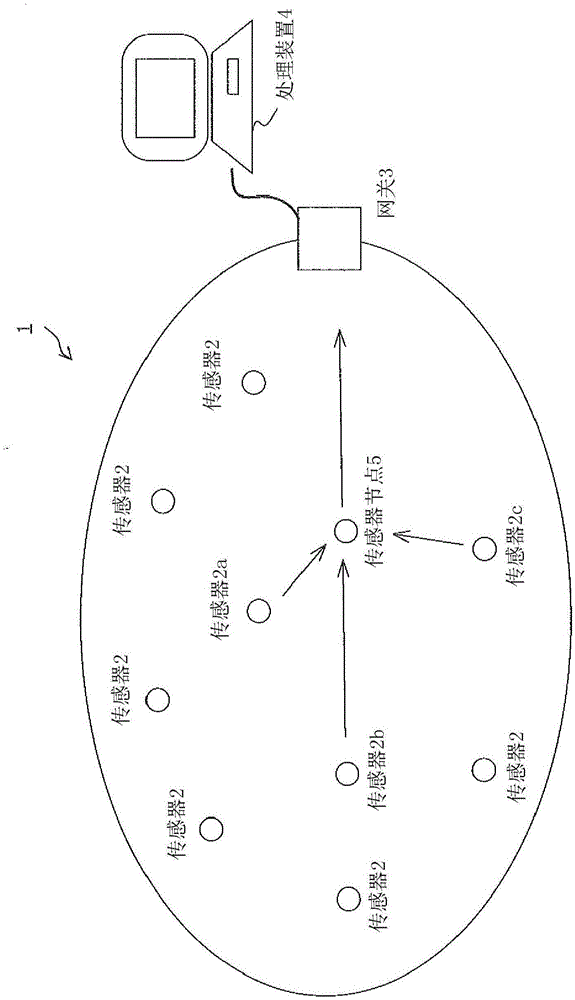
图1是示意性地例示出这些传感器网络的概略图。例如在传感器网络1中,将传感器2a等所检测到的数据经由传感器节点5和网关3发送到处理装置4。在将传感器2a、2b、2c所取得的数据发送到处理装置4的情况下,发送的数据具有数据尺寸成为固定长度的倾向。另外,在图1的例子中,数据压缩装置处于传感器节点。
将由各传感器所检测到的环境的状态等容量被预先确定的数据按照特定的排列顺序配置而成的数据列称为记录。在这样的情况下,1个记录是由固定长度的位串构成的固定长度数据。在传感器网络中,将传感器时刻检测到的环境状态等数据作为记录而连续地输出。这里,传感器包含温度传感器、湿度传感器、压力传感器、转速传感器、风速传感器、流速传感器、加速度传感器、速度传感器、或者位置传感器、或者检测开关的开/关信息的传感器等。
图2是对上述固定长度数据例进行说明的图。
在图2所示的例子中,示出了传感器2a的检测信息是旋转脉冲数、传感器2b、2c的检测信息是各自所对应的开关的开/关信息的情况。
通过传感器网络1发送和接收的固定长度数据的位长度被设定为固定值。而且,该固定长度位数据的内部也可以按照每规定数量的位而划分出记述的数据种类被确定的字段。例如,在图2的(a)中,记载了固定长度数据由10进制数表示的例子。在图2的(a)的例子中,在固定长度数据的起始的字段记述了26位的时刻,在接下来的字段记述了作为旋转脉冲数传感器2a的输出的14位的旋转脉冲数。此外,在接下来的字段记述了表示传感器2b的检测信息为开还是关的1位的数据,在接下来的字段记述了表示传感器2c的检测信息为开还是关的1位的数据。而且,整体的数据位长度为固定值。另外,在图1和图2的例子中,示出了在传感器网络1的1个传感器节点5上设置有3个传感器。但是,设置于1个传感器节点的传感器的种类和传感器数量不限于此,可以设置1个以上的任意数量的任意种类的传感器。
在图2的(b)中,将图2的(a)的由10进制数表示的固定长度数据以2进制数表示。在该情况下,也是从起始处记述有26位的时刻、14位的旋转脉冲数、1位的传感器1的接通/断开状态、传感器2的接通/断开状态。图2的(c)是将图2的(b)的由2进制数表示的固定长度数据记作连续位而成的。在该情况下,也预先确定了从起始处开始的第几位到第几位表示什么样的信息,因此,接受到了固定长度数据的装置通过从起始处开始依次读入位,能够识别记述在固定长度数据内的数据。
另外,在图1~图2的例子中,作为传感器的检测信息,示出了旋转脉冲数和开关的开/关信息的情况,但本实施方式的传感器不限于此,例如,可以是检测温度、湿度、位置、速度、加速度、风速、流速、压力等各种各样的检测量的传感器。
而且,也没有必要将发送和接收的数据限定为传感器的检测信息。本发明不限于传感器的检测信息,能够应用于从发送源依次发送的数据。
在连续传输这样的固定长度的记录的情况下,有时使用如下方法:存储某种程度的分量的数据,并通过现有的压缩技术使数据容量减小然后进行传输,在接收侧进行解压缩。
在该情况下,当累积量并非很大时,压缩效率不高,因此,如果优先考虑压缩效率,则产生了累积时间上的延迟。因此,在要求即时性的情况下,有时不进行压缩而发送。但是,如果不压缩而传输的话,相比于压缩的情况,数据传送量较大。
作为数据压缩的现有技术,存在专利文献1~5和非专利文献1所公开的技术,但是,它们都未记载适合在对固定长度的数据进行编码的情况下使用的数据的压缩编码方法。
现有技术文献
专利文献
专利文献1:日本特开2007-214998号
专利文献2:美国专利公开第2011/0200104号
专利文献3:日本特表2014-502827号
专利文献4:日本特开2010-26884号
专利文献5:日本特开2007-214813号
专利文献6:国际公开2013/175909号
专利文献7:日本特开2007-221280号
专利文献8:日本特开2011-48514号
非专利文献
非专利文献1:losslesscompressionhandbook,academicpress,2002/8/15,isbn-10:0126208611,isbn-13:978-0126208610
技术实现要素:
发明要解决的课题
因此,在基于本发明的一个方面的实施方式中,其目的在于提供适用于对固定长度数据进行编码,然后再进行解码的数据压缩编码方法、解码方法、其装置及其程序。
用于解决课题的手段
本发明的一个方面的数据压缩编码包含以下步骤:将记录以与所述字段的边界不相关的方式划分为规定的位宽的列,该记录由包含1个以上的字段的固定长度位串构成,该1个以上的字段是,在预先确定的字段中的相同字段中记述有同种数据的字段;以及在多个记录中按照每个列求解列中相同位置的位值的出现概率,并根据该出现概率对多个所述记录进行熵编码。
此外,本发明的另一方面的数据压缩编码是将从1个以上的传感器输入的各传感器数据与由固定长度位串构成的记录结合起来而对该记录进行压缩编码并输出的传感器数据的压缩编码,其中,按照与规定数量的记录的量对应的次数反复进行如下步骤:将所述记录划分为规定的位宽的列,在该时刻之前已被输入的多个记录中按照每个列求解列中的相同位置的位值的出现概率,并根据该出现概率而通过熵编码对构成所述记录的各列进行编码,将所述编码后的各列结合起来而输出。
即,将依次串行输入的规定数量的、由从1个以上的传感器输入的传感器数据结合而得的固定长度位串视作假想的表数据,并将该假想的表数据沿列方向压缩。
另外,熵编码是通过对出现概率较大的码分配较短的码长度、对出现概率较小的码分配较长的码长度来进行压缩的编码方式。作为熵编码所使用的代表的符号,公知有哈夫曼编码、算术编码等。
哈夫曼编码存在有自适应型哈夫曼编码、canonicalhuffmancodes(范式哈夫曼编码)等诸多方式,在算术编码中公知有自适应型算术编码以及利用了q编码器和区间编码器等的诸多方式。
发明效果
根据基于本发明的一个方面的实施方式,能够提供适合在对固定长度数据进行编码的情况下使用的数据压缩编码方法、解码方法、其装置及其程序。
附图说明
图1是示意性地例示传感器网络的概略图。
图2是对固定长度数据例进行说明的图。
图3是对基于本实施方式的编码方法的列划分进行说明的图。
图4a是示出本实施方式的数据压缩编码装置的功能块结构的一例的图。
图4b是示出本实施方式的数据压缩编码装置的功能块结构的其他例的图。
图5a是示出本实施方式的解码装置的功能块结构的一例的图。
图5b是示出本实施方式的第2解码装置的功能块结构的其他例的图。
图6是对使用了自适应型的熵编码方法的本实施方式的数据压缩编码方法进行一般性说明的流程图。
图7是对使用了累积型的熵编码方法的本实施方式的数据压缩编码方法进行一般性说明的流程图。
图8是对累积型哈夫曼(huffman)编码方法进行说明的流程图。
图9是对累积型哈夫曼解码方法进行说明的流程图。
图10是对自适应型哈夫曼编码方法进行说明的流程图。
图11是对自适应型哈夫曼解码方法进行说明的流程图。
图12是对自适应型算术编码方法进行说明的流程图。
图13是对自适应型算术解码方法进行说明的流程图。
图14a是例示出用于通过具体例对本实施方式的累积型哈夫曼编码方法进行说明的记录组的图。
图14b是例示出用于通过具体例对本实施方式的累积型哈夫曼编码方法进行说明的编码词典的图。
图14c是通过具体例对基于本实施方式的累积型哈夫曼编码方法的编码数据进行说明的图。
图15a是通过具体例对本实施方式的自适应型哈夫曼编码方法进行说明的图。(其1)。
图15b是通过具体例对本实施方式的自适应型哈夫曼编码方法进行说明的图。(其2)。
图16a是通过具体例对本实施方式的自适应型哈夫曼编码方法进行说明的图。(其3)。
图16b是通过具体例对本实施方式的自适应型哈夫曼编码方法进行说明的图。(其4)。
图17a是通过具体例对本实施方式的自适应型哈夫曼编码方法进行说明的图。(其5)。
图17b是通过具体例对本实施方式的自适应型哈夫曼编码方法进行说明的图。(其6)。
图18a是通过具体例对以1个位的单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其1)。
图18b是通过具体例对以1个位的单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其2)。
图19a是通过具体例对以1个位的单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其3)。
图19b是通过具体例对以1个位的单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其4)。
图20a是通过具体例对以1个位的单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其5)。
图20b是通过具体例对以1个位的单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其6)。
图21a是通过具体例对以1个位为单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其7)。
图21b是通过具体例对以1个位为单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其8)。
图22a是通过具体例对以1个位为单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其9)。
图22b是通过具体例对以1个位为单位进行列划分的本实施方式的数据压缩编码方法进行说明的图(其10)。
图23a是通过具体例来说明基于对通过本实施方式的累积型哈夫曼编码方法被编码后的编码数据进行解码的解码方法的编码词典的制作的图。
图23b是通过具体例对通过本实施方式的累积型哈夫曼编码方法被编码后的编码数据的解码进行说明的图。
图24a是通过具体例来说明对通过本实施方式的自适应型哈夫曼编码方法被编码后的编码数据进行解码的解码方法的图(其1)。
图24b是通过具体例来说明对通过本实施方式的自适应型哈夫曼编码方法被编码后的编码数据进行解码的解码方法的图(其2)。
图25a是通过具体例来说明对通过本实施方式的自适应型哈夫曼编码方法被编码后的编码数据进行解码的解码方法的图(其3)。
图25b是通过具体例来说明对通过本实施方式的自适应型哈夫曼编码方法被编码后的编码数据进行解码的解码方法的图(其4)。
图26a是通过具体例来说明对通过本实施方式的自适应型哈夫曼编码方法被编码后的编码数据进行解码的解码方法的图(其5)。
图26b是通过具体例来说明对通过本实施方式的自适应型哈夫曼编码方法被编码后的编码数据进行解码的解码方法的图(其6)。
图27a是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其1)。
图27b是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其2)。
图28a是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其3)。
图28b是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其4)。
图29a是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其5)。
图29b是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其6)。
图30a是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其7)。
图30b是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其8)。
图31a是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其9)。
图31b是通过具体例来说明对通过本实施方式的自适应型算术编码方法被编码后的编码数据进行解码的解码方法的图(其10)。
图32是在将本实施方式安装于程序的情况下的、执行程序的例示的计算机的硬件环境图。
具体实施方式
图3是对基于本实施方式的列划分进行说明的图。
图3示出了由固定长度位串构成的固定长度数据的1个记录的例子。记录由已经确定的位位置和位宽的字段构成,在字段1~字段n中记述有数据。在本实施方式中,将记录划分为由规定位宽构成的列。例如,在图3的情况下,列1由1~a1位构成,列2由a1+1~a2位构成,列3由a2+1~a3位构成,之后,同样地,列m由am-1+1~am位构成。a1~am可以是相同值,也可以是分别不同的值。此外,列可以按照字段的位置和位宽来划分,也可以与字段的宽度、位置不相关地进行划分。此外,列的位宽例如可以是1位、2位、4位、8位、16位等。
另外,虽然在固定长度数据中将有意义的数据构成为可变长度数据,但也包含对数据的后方追加“0”来调整数据长度,从而成为固定长度数据的数据,可变长度数据由存储同种数据的字段构成,当在后方的数据中未记录有数据时,由“0”补位,从而使数据长度为固定值,即使在该情况下,也能够应用本实施方式的方法。如上所述,在本实施方式中,由固定长度数据的固定长度位串构成的记录由在多个已确定的字段中记述的具有不同含义的数据构成,使每个记录中的处于相同位置的字段中所记述的数据为相同种类的数据。而且,通过将记录划分为任意的位数的块、即列,并对列以相互独立的方式沿列方向连续地编码,而实现了比以往的编码方法有效的压缩编码。即,在本实施方式中,通过针对多个记录的相同位置的每个列连续地对各列进行编码,而对一个记录进行编码。
这里,对列以相互独立的方式进行编码是指,编码的过程不依赖于不同的列的数据。此外,字段是存储有一段数据,并且在每个字段中所存储的一段数据的含义已经被确定的固定长度数据内的数据存储位置。固定长度数据由存储在1个以上的字段中的数据构成。列是针对固定长度数据划分而得到的,但存储在列中的数据未必一定是一段具有含义的数据。如果列以跨越字段的方式被划分,则一个字段也有时也被划分为多个列等,而成为单纯地划分的数据的段。但是,列的划分方法在多个固定长度数据中是相同的,在多个固定长度数据中,同一列表示同样部分的数据段。
图4a是示出本实施方式的数据压缩编码装置的功能块结构的一例的图。如图4a所示,在通过划分单元10将输入记录划分为列之后,各列的数据被分别暂时存储于各列用的寄存器11-1~11-m中,然后,通过各列用编码单元12-1~12-m按照每个列而被单独地压缩编码。压缩编码后的各列的数据借助混合单元13而成为1个数据流,并作为1个记录的编码数据输出而输出。
虽然在这里记载了各列用编码单元12-1~12-m分别设置有单独的编码单元,但是并不限定于此,也可以是,以时分的方式对压缩编码处理进行处理,以使1个编码单元针对每个列单独进行压缩编码。另外,如图1的例子那样,本实施方式的数据压缩编码装置例如设置于传感器节点。
图4a中表示功能块结构的数据压缩编码装置所使用的压缩编码方法例如可以是包含哈夫曼编码等方法在内的熵编码方法。在列用编码单元12-1~12-m采用了熵编码方法的情况下,如图4a所示,在各列用编码单元12-1~12-m中存储有频度表和编码表。
这样的本实施方式的压缩编码方法在固定长度位串由多个独立的信息构成时尤其有效。即使在对列进行划分时无视包含固定长度位串的独立信息在内的字段的边界,通过忽略列之间的相关性,能够减少压缩编码后的平均数据量。
图4b是示出本实施方式的数据压缩编码装置的功能块结构的其他例的图。图4b所示的例子是使用算术编码的情况。
如图4b所示,在算术编码中的编码的情况下,针对记录输入由划分单元10a按照每个列进行划分,在列用寄存器11a-1~11a-m中保存各列的数据。然后,在列划分范围判定单元12a-1~12a-m中,根据各个列中的所读入的数据值的频度计算出现概率,从而针对每个列来判定划分与该列对应的当前的区间的值。而且,通过区间划分单元,根据求出的值和列的值来求出与接下来的列对应的区间。
即,当列1的列划分范围判定单元12a-1完成处理时,在区间划分单元18-1中,根据列1的数据和对列1的数据进行处理后的结果,根据算术编码方法来划分与列2对应的区间。接下来,列2的列划分范围判定单元12a-2根据列2的数据的出现概率来判定划分列2的区间的值,区间划分单元18-2根据该结果和列2的数据来划分接下来的列3所需的区间。以下,同样地,反复进行上述处理直至列m。而且,在编码单元19中,对根据如下值而输入的记录进行编码,得到编码数据输出,该值使作为区间划分单元18-m的区间划分结果的区间中所包含的由二进制表示最短。
图5a是示出本实施方式的解码装置的功能块结构的一例的图。
图5a所示的解码装置是与图4a所示的数据压缩编码装置对应的解码装置。当被输入通过图4a的数据压缩编码装置而被编码的编码数据时,划分单元16将编码数据划分为列。然后,多个解码单元14-1~14-m对各列的编码数据进行解码。此时,解码单元14-1~14-m按照具体的编码方法,参照按照编码前的数据的每个列而设置的频度表、编码表15-1~15-m来进行解码。例如,在编码方法是哈夫曼编码的情况下,依次读入编码数据,参照针对各列1~列m设置编码数据的符号方式所得到的频度表、编码表来生成解码数据的符号。
然后,通过混合单元17将按照每个列进行解码而得到的解码数据结合起来,输出解码记录。
图5b是示出本实施方式的解码装置的功能块结构的其他例的图。
图5b所示的解码装置是与图4b所示的数据压缩编码装置对应的解码装置。
在图5b所示的算术编码的解码的情况下,被进行了编码的记录被输入到列1的列划分范围判定单元20-1。然后,在列划分范围判定单元20a-1~20a-m中,根据各个列中的解码后的数据值的频度来计算出现概率,求出划分与该列对应的当前的区间的值。然后,在列1解码单元14a-1~列m解码单元14a-m中,对划分与各列对应的当前的区间的值和编码数据的值进行比较而来求出该列的解码数据。进而,根据该解码数据和先前求出的划分当前的区间的值,通过区间划分单元来求出与接下来的列对应的区间。借助混合单元17a使列1解码单元14a-1~列m解码单元14a-m的解码数据结合起来,输出解码记录。
图6是对使用了自适应型的熵编码方法的本实施方式的数据压缩编码方法进行一般性说明的流程图。在自适应型的编码方法中,随着输入数据而逐次进行压缩编码。
首先,在步骤s10中,将熵编码所使用的频度表初始化。频度表是通过对某个符号在编码数据内出现多少次进行计数而得的。该频度表本身是以往在熵编码中使用的,在本实施方式中,特征在于对在多个记录的同一位置的列中存在的符号进行计数。作为初始化,例如,将全部项目设定为0。
接下来,在步骤s11的循环中,按照与1个记录的列数对应的次数反复进行步骤s12的处理。在步骤s12中,根据频度表进行编码表的制作。在哈夫曼编码的情况下,编码表是哈夫曼编码词典,在算术编码的情况下,编码表是出现概率,是在实际将原始数据置换为编码信息的情况下使用的表。
当步骤s11中的与列数对应的次数的反复处理完成时,进入步骤s13。在步骤s11的最初的处理中,根据在步骤s10中进行初始化而得到的频度表制作编码表。
在步骤s13中,读入作为固定长度位串的1个记录。接下来,在步骤s14中,按照预先确定的方法将记录划分为列。在步骤s14a中,按照每个列进行编码,在步骤s15中,将每个列的编码数据混合而成为1个记录的压缩编码数据。在步骤s16中,输出1个记录的量的压缩编码后的数据。在针对全部记录的该1个记录的量的数据输出结束时,输入数据的压缩编码完成。
接下来,在步骤s16之后,进入步骤s17,按照与列数对应的次数反复进行步骤s18的处理。在步骤s18中,进行频度表的更新。此时,频度表针对每个列是独立的,具有与列数对应的个数。频度表的更新不使用其他列的编码结果,而是随着针对记录的规定的列对记录进行依次编码,根据以前的记录的对应的列的编码结果而更新的。
当步骤s17的循环处理完成时,返回到步骤s11,根据在步骤s17的循环处理中被更新的各列的频度表制作编码表,进入步骤s13,从而进入接下来的记录的编码处理。当不存在要处理的记录时,压缩编码完成。
另外,在后文,列举具体例对与熵编码方式对应的几个方式更详细地进行说明。
图7是对基于使用了累积型的熵编码方法的本实施方式的数据压缩编码方法进行一般性说明的流程图。在累积型的编码方法中,将要进行压缩编码的数据暂时全部读入,然后对它们进行压缩编码。即,暂时全部读入编码的数据并完成频度表,然后,再次读入数据并进行编码。
首先,在步骤s19中,将频度表初始化。在步骤s20的循环中,对要编码的数据的全部记录进行与记录数对应的次数的反复处理。在步骤s21中,读入1个记录,在步骤s22中,通过预先确定的方法将记录划分为列。在步骤s23的循环中,按照与列数对应的次数反复处理步骤s24。在步骤s24中,对按照每个列而单独设置的频度表进行更新。当步骤s23的与列数对应的次数的反复处理结束时,判断步骤s20的与记录数对应的次数的反复处理是否已结束,在未结束的情况下,继续反复处理,在结束的情况下,进入步骤s25。在到达步骤s25的时刻,针对要编码的全部数据完成了频度表的更新,因此,输出频度表,进入步骤s26。
在步骤s26中,按照与列数对应的次数反复进行步骤s27的处理。在步骤s27中,根据频度表制作编码表。在哈夫曼编码的情况下,编码表是哈夫曼编码词典,在算术编码的情况下,编码表是出现概率,是在实际将原始数据置换为编码信息的情况下使用的表。当步骤s26的与列数对应的次数的反复处理完成时,进入步骤s28。
在步骤s28中,按照与要编码的数据所包含的记录数对应的次数进行反复处理。在步骤s29中,读入1个记录,在步骤s30中,按照预先确定的方法划分记录。在步骤s31中,按照每个列进行压缩编码,在步骤s32中,将压缩编码数据混合而得到1个记录的压缩编码数据。在步骤s33中,输出1个记录的量的数据。在步骤s28的循环处理中,在与记录数对应的次数的反复处理完成的情况下,结束处理。
另外,这里,例如在要进行压缩编码的数据是从传感器等接收的固定长度数据的情况下,要压缩编码的数据的记录数取决于以何种程度将数据汇总而进行压缩编码。要汇总而进行压缩编码的数据的容量取决于编码装置所具有的存储器的容量等,但这应当由使用本实施方式的本领域技术人员来适当确定。而且,根据从发送源依次发送数据的情况,而反复进行汇总上述数据的压缩编码。
图8和图9是对累积型哈夫曼编码和解码方法更详细地进行说明的流程图。
在图8所示的累积型哈夫曼编码方法中,在步骤s40中,将频度表初始化。在步骤s41的循环中,按照与记录数对应的次数反复进行步骤s41的期间中的处理。在步骤s42中,读入1个记录,在步骤s43中,按照规定的方法将记录划分为列。在步骤s44的循环中,按照与列数对应的次数反复进行步骤s45。在步骤s45中,按照每个列来更新频度表。而且,当将全部列的频度表更新时,在步骤s46中输出频度表,进入步骤s47的循环。
在步骤s47的循环中,按照与列数对应的次数反复进行步骤s48的处理。在步骤s48中,根据频度表制作编码表。
接下来,在步骤s49的循环中,按照与记录对应的次数反复进行处于步骤s49期间的处理。在步骤s50中,读入1个记录。在步骤s51中,按照规定的方法将记录划分为列。在步骤s52的循环中,按照与列数对应的次数反复进行步骤s53的处理。在步骤s53中,对列数据进行编码。接下来,在步骤s54中,将在步骤s52的循环中求出的编码数据混合成1个记录。在步骤s55中,输出1个记录的量的数据。当与记录数对应的量的处理完成时,结束处理。
在图9所示的累积型哈夫曼解码方法中,在步骤s60中,读入频度表。在步骤s61的循环中,按照与列数对应的次数反复进行步骤s62。在步骤s62中,根据频度表制作编码表。在步骤s63的循环中,按照与记录数对应的次数反复进行步骤s63期间的处理。在步骤s64中,读入1个记录。在步骤s65的循环中,按照与列数对应的次数反复进行步骤s66。在步骤s66中,根据在步骤s62中制作的编码表对列数据进行解码。在步骤s67中,将各列的解码数据混合成1个记录。在步骤s68中,输出1个记录的量的数据。当与记录数对应的量的处理完成时,结束处理。
图10和图11是对自适应型哈夫曼编码和解码方法进行说明的流程图。
在图10所示的自适应型哈夫曼编码方法中,在步骤s70中,将频度表初始化。在步骤s71的循环中,按照与列数对应的次数反复进行步骤s72的处理。在步骤s72中,在初次处理中根据在步骤s70中被初始化后的频度表制作编码表,在这以后,根据在步骤s80中被更新的频度表来制作编码表。在步骤s73中,读入1个记录。在步骤s74中,按照规定的方法将记录划分为列。在步骤s75的循环中,按照与列数对应的次数反复进行步骤s76的处理。在步骤s76中,根据在步骤s72中制作的编码表对列数据进行编码。在步骤s77中,将各列的编码数据按照1个记录的量混合。在步骤s78中,输出1个记录的量的数据。在步骤s79的循环中,按照与列数对应的次数反复进行步骤s80的处理。在步骤s80中,将各列的频度表更新。当与列数对应的次数的反复执行完成时,返回到步骤s71,制作编码表,反复进行步骤s73以后的接下来的记录的处理。
图11所示的自适应型哈夫曼解码方法对通过图10所示的自适应型哈夫曼编码方法进行编码得到的数据进行解码。编码数据的解码是通过针对编码所使用的编码表进行反向解析,根据编码数据而求出原来的列的数据来进行的。因此,在图11所示的流程中,图10所示的流程的列数据的编码的步骤和将编码数据混合的步骤被置换为,列数据的解码的步骤和将解码数据混合的步骤,1个记录读入步骤被置换为1个记录的量的编码数据读入步骤,编码数据的输出步骤被置换为解码后的记录的输出步骤。
如图11所示,在步骤s85中,将频度表初始化。在步骤s86的循环中,按照与列数对应的次数反复进行步骤s87的处理。在步骤s87中,在初次处理中根据在步骤s85中进行初始化而得到的频度表来制作编码表,在这以后,根据在步骤s94中被更新的频度表来制作编码表。在步骤s88中,读入1个记录的量的编码数据。在步骤s89的循环中,按照与列数对应的次数反复进行步骤s90的处理。在步骤s90中,根据在步骤s87中制作的编码表对列数据进行解码。在步骤s91中,将各列的解码数据按照1个记录的量混合。在步骤s92中,输出1个记录的量的数据。在步骤s93的循环中,按照与列数对应的次数反复进行步骤s94的处理。在步骤s94中,将各列的频度表更新。当与列数对应的次数的处理完成时,返回到步骤s86,制作编码表,反复进行步骤s88之后的接下来的记录的处理。
图12和图13是对自适应型算术编码和解码方法进行说明的流程图。与先前通过图4b和图5b所说明的功能块的结构对应,利用使这些流程图所示的算法得到执行的程序,能够以计算机实现自适应型算术编码装置和解码装置。
在图12所示的自适应型算术编码方法中,在步骤s95中,将频度表初始化。在步骤s96的循环中,按照与列数对应的次数反复进行步骤s97的处理。在步骤s97中,在初次处理中,根据在步骤s95中被初始化的频度表来制作出现概率表,在这以后,根据在步骤s106中被更新的频度表来制作出现概率表。在步骤s98中,读入1个记录。在步骤s99中,按照规定的方法将记录划分为列。在步骤s100中,将区间初始化。在步骤s101的循环中,按照与列数对应的次数反复进行步骤s102的处理。在步骤s102中,按照算术编码方法来对区间进行划分。在步骤s103中,根据在步骤s101的循环中最终得到的区间来生成编码数据。在步骤s104中,将该编码数据作为1个记录的量的编码数据而输出。在步骤s105的循环中,按照与列数对应的次数反复进行步骤s106的处理。在步骤s106中,将频度表更新。当与列数对应的次数的处理完成时,返回到步骤s96,制作出现概率表,反复进行步骤s98以后的接下来的记录的处理。
图13所示的自适应型算术解码方法对通过图12所示的自适应型算术编码方法编码后的数据进行解码。
如图13所示,在步骤s110中,将频度表初始化。在步骤s111的循环中,按照与列数对应的次数反复进行步骤s112的处理。在步骤s112中,根据频度表来制作出现概率表。在步骤s113中,读入1个记录的量的编码数据。在步骤s114中,将区间初始化。在步骤s115的循环中,按照与列数对应的次数反复进行步骤s116a、步骤s116和步骤s117的处理。在步骤s116a中,根据各个列中的解码后的数据值的频度来计算出现概率,并求出划分与该列对应的当前的区间的值。在步骤s116中,对划分与各列对应的当前的区间的值和编码数据的值进行比较而求出该列的解码数据。在步骤s117中,根据在步骤s116中求出的解码数据和在步骤s116a中求出划分当前的区间的值来求出与接下来的列对应的区间。在步骤s118中,将在步骤s116中求出的列解码数据按照1个记录的量混合。在步骤s119中,输出1个记录的量的数据。在步骤s120的循环中,按照与列数对应的次数反复进行步骤s121的处理。在步骤s121中,将各列的频度表更新。当与列数对应的次数的处理完成时,返回到步骤s111,制作出现概率表,反复进行步骤s113之后的接下来的记录的处理。
以上,参照图6~图13对本实施方式的数据压缩编码方法和解码方法进行了说明,但也可以利用使用了这些附图中所记载的流程图所示的算法的程序、将本实施方式的数据压缩编码装置和解码装置安装到计算机上。
接下来,使用记录的具体例对本实施方式的数据压缩编码/解码进行说明。
图14a~图22b示出本实施方式的数据压缩编码方法的处理例。
图14a~图14c是通过具体例对本实施方式的累积型哈夫曼编码方法进行说明的图。在图14a~图14c所示的例子中,累积10个记录,然后统一地进行压缩编码。
图14a所例示的是由固定长度8位的10个记录构成的记录组20。各记录例如被划分为位宽为4位的列1和列2。另外,在此后的其他的方式的编码的说明中,同样使用记录组20作为被设为编码的对象的记录组。
图14b所例示的是使用哈夫曼编码的情况下的编码词典25的例子。以往的哈夫曼编码的方法可参照非专利文献1。在本实施方式的情况下,针对各个列而单独地具有编码词典25。对同一列使用相同编码词典。在图14a~图14c的情况下,将1个记录划分为2个列,因此,编码词典也设置有2个。
在图14b中,引用码21所示的是各个列中可能出现的数据。即,1个列由4位构成,因此,0与1的排列存在24种。因此,为了将这些位的全部组合包括在内,编码词典25由16个行构成。
引用码22所示的数据是对记录组20中的各位模式的出现次数进行求解而得的。根据该出现次数求解出的各数据的出现概率的数据由引用码23示出,引用码24示出的是自信息熵。出现概率23是通过将出现次数22除以记录数而得到的。例如,在引用码25所示的编码词典的左侧的编码词典中,“0010”的出现次数为7次,全记录数是10件,因此,出现概率23为7/10=0.7。此外,当设自信息熵24为s、设出现概率23为p时,则s=-log(p)。根据该出现概率23和自信息熵24进行编码。
引用码27所示的数据是通过上述编码而得到的各列的编码数据。通过结合该哈夫曼编码而得到了将记录压缩编码后的编码数据。图14c的引用码26所示的数据是对应于记录组20的各记录的编码数据。当比较记录组20与编码数据26时,可以判断出数据量减少,但在该方法中,在进行解码时需要参照在压缩编码时所使用的编码词典,因此,需要另行发送接收引用码22的频度表(或者,引用码25的编码词典)。在图14a~图14c所例示的累积型的情况下,适合于将某种程度的记录汇总而进行压缩编码。
另外,在图6和图7的说明中,说明了频度表和编码表是独立的表格的情况,但在图14a~图14c的例子中,采用了频度表包含于编码表的构造。
图15a~图17b是通过具体例对本实施方式的自适应型哈夫曼编码方法进行说明的图。在自适应型的编码解码方法中,无需事先求出出现概率或者产生频度,能够在产生记录数据的时刻即时性地进行编码。此外,能够对该编码后的信息即时性地进行解码。
图15a所示的是由引用码30-1所示出的初始状态的编码表25、记录组20以及最初的记录的编码数据31-1。输入的记录组20与图14所示的记录组20相同。不过,如图15a所示,输入的记录由粗字表示,未输入的记录由细字表示。
编码表25的构造与图14所示的编码词典25的构造相同。仅在图15a中对同一项目标注同一引用码。对初始状态的编码表25所包含的频度表22应用拉普拉斯平滑化而使它们全部成为同一值“1”。根据该频度来求解出现概率、自信息熵、哈夫曼编码,使用该码对最初的记录进行编码。编码结果如编码数据31-1所示,是与输入记录相同的值。在初始状态下,全部频度相等,因此,未得到压缩效果。
接下来,根据最初的记录将频度表更新。使与出现的数据相应的项的频度增加一定值。如图15b所示,在左列中,“0010”的产生次数增加1,在右列中,“1000”的产生次数增加1。根据该频度表而重新求解出现概率、自信息熵而得的数据是作为30-2而示出的编码表25,求解哈夫曼编码而得的数据在编码数据31-2中由粗字表示。在编码数据31-2中,显示出了:相比于未得到压缩效果的最初的记录,表现出了压缩效果。
接下来,如图16a所示,在第3个记录的左列再次出现“0010”,在右列再次出现“1000”,因此,作为30-3而示出的编码表的左侧的频度表的“0010”的项和右侧的频度表的“1000”的项被更新为3。根据该频度表进行哈夫曼编码而得的结果在编码数据31-3中示出。
而且,在图16b中,在第4个记录的左列出现了“0010”,在右列出现了“1100”,因此,在作为30-4而示出的编码表的频度表中,在左侧的频度表中,“0010”的项被更新为4。此外,在右侧的频度表中,首次出现“1100”的项,但由于初始值为1,因此未被更新。根据该频度表进行哈夫曼编码而得的结果在编码数据31-4中示出。
而且,在图17a中,在第5个记录的左列出现了“1010”,在右列出现了“1000”,因此,在作为30-5而示出的编码表的频度表中,在左侧的频度表中,“1010”的项被维持为初始值1。此外,在右侧的频度表中,“1000”的项被更新为4。根据该频度表进行哈夫曼编码而得的结果在编码数据31-5中示出。
而且,在图17b中,在第6个记录的左列出现了“0010”,在右列出现了“1000”,因此,在作为30-6而示出的编码表的频度表中,在左侧的频度表中,“0010”的项被更新为5。此外,在右侧的频度表中,“1000”的项被更新为5。根据该频度表进行哈夫曼编码而得的结果在编码数据31-6中示出。
通过像这样反复进行处理而依次进行编码。在图17a、图17b中,记载了到6个记录为止的编码表,但通过同样地更新频度表、反复求解出现概率、自信息熵、哈夫曼编码并进行编码,能够对全部记录进行编码。
这样,当使用自适应型的编码方法时,不需要发送接收编码词典,因此,即使是记录数较少的数据,也能够得到压缩效果。
图18a~图22b是通过具体例对以列划分作为1比特单位的本实施方式的数据压缩编码方法进行说明的图。
通过该方法能够减少在编码和解码时用于频度表的记录的存储器容量。
在划分为比特单位时,能够应用算术编码(arithmeticcoding)的方法进行编码。此外,由于一边沿列方向依次编码一边将频度更新,因此,使用自适应型二进制算术编码方法。算术编码的方法本身能够采用以往公知的方法。根据需要,可参照非专利文献1。
输入的记录组20是与图14a所示的记录组20相同的数据,但被列划分为1比特单位。
图18a所示的表40-1的上部是频度,下部是与该频度对应的出现概率。以下的图18a~图22b也同样。表40-1是初始状态的表。本来,在数据为“0”的情况和数据为“1”的情况下,需要各自的频度,但在表40-1中仅记载有“0”的频度。不记录“1”的情况下的频度,而设置总记录数41-1的栏。“1”的频度能够通过从总记录数中减去“0”的频度来求得。关于初始值,仍然使用拉普拉斯平滑化使“0”的频度为1,使总记录数为2。根据该频度而求得的“0”的出现概率记载在表40-1的下部。出现概率能够利用频度/总记录数来求得。此外,“1”的出现概率能够通过(1-(“0”的出现概率))来计算。
根据该出现概率进行算术编码。这里,在本实施方式中,使用按照每个列而独立(在该例的情况下,按照每个位而独立)的出现概率(频度)。第1个记录的算术编码结果在编码数据42-1中示出。此外,通过算术编码求得的区间的值记载在编码数据42-1的右侧。该区间所包含的最短位数所能够表现的数值的2进制数形式的小数部分是算术编码的结果。在该例的情况下,由于0.00101(2进制数)=0.15625(10进制数),因此,结果是“00101”。一般情况下,在算术编码的情况下,即使将编码结果的末尾的“0”省略,也能够进行解码,因此,正常情况下,这里省略末尾的“0”。此外,作为编码结果,在本实施方式中,以位为单位进行列划分,因此,频度与记录内的其他的位的频度没有关系,但是,在不同的记录之间,就像第1位对应第1位的出现频度、第2位对应第2位的出现频度···那样,对由位的位置确定的位的出现频度进行计数。因此,出现概率通过将在规定的位的位置出现的“0”的数量除以要处理的记录数而得到。“1”的出现概率通过从1中减去“0”的出现概率而得到。
在第1个记录的编码后被更新的第2个记录的出现频度和出现概率在图18b的表40-2中示出。由于仅求解“0”的频度,因此,在表40-2中,在第1个记录中,仅在出现“0”的位置频度增加1。出现“1”的第3位和第5位的位置的频度保持为初始值。此外,总记录数41-2增加到3。根据频度和总记录数求出的出现概率记载在频度表40-2的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-2的第2行与第2个记录对应地示出。可知算术编码的区间的值发生变化。该区间所包含的最小位数的二进制形式为0.01(二进制)=0.25(十进制),因此,编码的结果为“01”。
在第2个记录的编码后被更新的第3个记录的出现频度和出现概率在图19a的表40-3中示出。在表40-3中,在第2个记录中,仅在出现“0”的位置频度增加1,它们分别成为3。出现“1”的第3位和第5位的位置的频度保持为初始值。此外,总记录数41-2增加到4。根据频度和总记录数求出的出现概率记载在表40-3的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-3的第3行与第3个记录对应地示出。可知算术编码的区间的值发生变化。由于0.01(二进制)=0.25(十进制),因此,编码的结果为“01”。
在第3个记录的编码后被更新的第4个记录的出现频度和出现概率在图19b的表40-4中示出。在表40-4中,在第3个记录中,仅在出现“0”的位置频度增加1,它们分别成为4。出现“1”的第3位和第5位的位置的频度保持为初始值。此外,总记录数41-4增加到5。根据频度和总记录数求出的出现概率记载在表40-4的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-4的第4行与第4个记录对应地示出。可知算术编码的区间的值发生变化。由于0.1(二进制)=0.5(十进制),因此,编码的结果为“1”。
在第4个记录的编码后被更新的第5个记录的出现频度和出现概率在图20a的表40-5中示出。在表40-5中,在第4个记录中,仅在出现“0”的位置频度增加1,它们分别成为5。在第4个记录中新出现了“1”的第3位、第5位以及第6位的位置的频度保持为以前的值。此外,总记录数41-5增加到6。根据频度和总记录数求出的出现概率记载在表40-5的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-5的第5行与第5个记录对应地示出。可知算术编码的区间的值发生变化。由于0.111(二进制)=0.875(十进制),因此,编码的结果为“111”。
在第5个记录的编码后被更新的第6个记录的出现频度和出现概率在图20b的表40-6中示出。在表40-6中,在第5个记录中,仅在出现“0”的位置频度增加1。在第5个记录中新出现了“1”的第1位、第3位以及第5位的位置的频度保持为以前的值。此外,总记录数41-6增加到7。根据频度和总记录数求出的出现概率记载在表40-6的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-6的第6行与第6个记录对应地示出。可知算术编码的区间的值发生变化。由于0.01(二进制)=0.25(十进制),因此,编码的结果为“01”。
在第6个记录的编码后被更新的第7个记录的出现频度和出现概率在图21a的表40-7中示出。在表40-7中,在第6个记录中,仅在出现“0”的位置频度值增加1。在第6个记录中新出现了“1”的第3位和第5位的位置的频度保持为以前的值。此外,总记录数41-7增加到8。根据频度和总记录数求出的出现概率记载在表40-7的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-7的第7行与第7个记录对应地示出。可知算术编码的区间的值发生变化。由于0.01(二进制)=0.25(十进制),因此,编码的结果为“01”。
在第7个记录的编码后被更新的第8个记录的出现频度和出现概率在图21b的表40-8中示出。在表40-8中,在第7个记录中,仅在出现“0”的位置频度增加1。在第7个记录中新出现了“1”的第3位和第5位的位置的频度保持为以前的值。此外,总记录数41-8增加到9。根据频度和总记录数求出的出现概率记载在表40-8的下部。而且,根据该出现概率进行算术编码的结果在编码数据42-8的第8行与第8个记录对应地示出。可知算术编码的区间的值发生变化。由于0.01(二进制)=0.25(十进制),因此,编码的结果为“01”。
在第8个记录的编码后被更新的第9个记录的出现频度和出现概率在图22a的表40-9中示出。在表40-9中,在第8个记录中,仅在出现“0”的位置频度值增加1。在第8个记录中新出现了“1”的第3位和第5位的位置的频度保持为以前的值。此外,总记录数41-9增加到10。根据频度和总记录数求出的出现概率记载在表40-9的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-9的第9行与第9个记录对应地示出。可知算术编码的区间的值发生变化。由于0.10101(二进制)=0.65625(十进制),因此,编码的结果为“10101”。
在第9个记录的编码后被更新的第10个记录的出现频度和出现概率在图22b的表40-10中示出。在表40-10中,在第9个记录中,仅在出现“0”的位置频度增加1。在第9个记录中新出现了“1”的第3位和第4位的位置的频度保持为以前的值。此外,总记录数41-10增加到11。根据频度和总记录数求出的出现概率记载在表40-10的下部。而且,根据该出现概率而进行算术编码的结果在编码数据42-10的第10行与第10个记录对应地示出。可知算术编码的区间的值发生变化。由于0.101111(二进制)=0.734375(十进制),因此,编码的结果为“101111”。
这样,通过反复进行频度的更新和算术编码来进行编码。
当在上述每个位的划分中使用算术编码的情况下,具有以下的效果。
即,如果将记录整体看作1列,则成为与现有技术同样的压缩,但在本实施方式的例子中,在以位为单位划分了8位的记录的情况下,所需的频度表的大小为8+1=9,但在现有技术中,需要256的大小。另外,由于出现概率能够根据频度表来计算,因此,无需另行存储。
当假设记录长度为32位(在本实施方式的例子中是33位)时,在现有技术中,是2的32次方=4294967296,如果记录长度是较长的数据,则将记录整体看作1列的方法在现实中是不可能的。在进行划分的情况下,相比于使用整体具有1种词典的以往的压缩技术的方法,本实施方式的例子的方法能够得到较高的压缩效果。
另外,在以1位为单位划分而沿列方向进行压缩编码的情况下,具有以下的效果。例如,在以多个位为单位划分的情况下,必须按照划分单位的位模式来保存用于置换为编码用的信息,但如果是1位的单位,则只要预先保存这1位是否是“1”即可,因此,在压缩编码时所需的作业存储器的容量较少。此外,在以多个位为单位进行划分的情况下,按照每个划分单位而进行符号的置换,需要按照1个记录的量来进行压缩编码,但在以1位为单位进行划分的情况下,只要获得1个记录的位数和“1”或者“0”的位数便能够进行压缩编码,因此,用于进行压缩编码的逻辑也变得简单。
图23a~图31b示出了本实施方式的解码方法的处理例。
图23a、图23b是说明对通过图14a~图14c所示的累积型哈夫曼编码方法而被编码后的编码数据进行解码的解码方法的图。
事先确定对通过图14a~图14c所示的累积型哈夫曼编码方法而被编码的编码数据进行解码,即,事先确定对由2个4位的列构成的8位的记录进行处理。此外,也预先确定了求解哈夫曼编码的方式。
并且,在解码侧,事先准备图23a所示的解码词典50-1的区域。通过上述确定而制成了由16(2的4次方)行2块构成的表。此外,表的a列以外的列被预先设为空栏。
接下来,将通过编码而制作的符号的产生频度读入到列b中。在该情况下,读入32个整数值。根据该产生频度计算列c的出现概率而制作哈夫曼树,在列e中求解哈夫曼编码而完成了解码词典50-1。哈夫曼编码的计算步骤需要使用与编码相同的步骤。该解码信号50-1与图14b所示的编码词典24相同。
也存在发送接收列c的出现概率而非发送接收列b的产生频度的方法。此外,也能够发送接收列e的哈夫曼编码表,在该情况下,无需事先确定求解哈夫曼编码的方式。
接下来,读入编码位串而根据解码词典50-1求出解码数据。由于哈夫曼编码是前缀码,因此能够从起始处依次对编码位串进行解码。不需要特别的分隔符。
图23b示出了使用解码词典50-1对编码数据51-1进行解码而得的解码记录51-2。当观察编码数据51-1的第1行时,编码数据为“00”。当观察解码词典50-1的列a和列e时,在左列中,编码数据“0”与符号列“0010”对应,在右列中,编码数据“0”与符号列“1000”对应。因此,编码数据“00”在解码后成为“00101000”。直到编码数据51-1的第3行为止,与上述情况同样。
编码数据51-1的第4行是“010”。根据解码词典50-1,在左列中,不存在“01”这样的符号,因此,左列的编码数据取“0”。这在解码后与“0010”对应。右列的编码数据成为“10”,因此,当观察解码词典50-1时,编码后成为“1100”。因此,解码后的符号列成为“00101100”。以下,同样地,能够对编码数据51-1进行解码。
图24a~图26b是说明对通过图15a~图17b所示的自适应型哈夫曼编码方法被编码的编码数据进行解码的解码方法的图。
事先确定对通过图15a~图17b所示的自适应型哈夫曼编码方法被编码的编码数据进行解码,即,事先确定对由2个4位的列构成的8位的记录进行处理。此外,还预先确定了求解哈夫曼编码的方式。
在解码侧,事先准备图24a所示的表50-2。通过上述确定而制成了由16(2的4次方)行2块构成的表。在该方法中,由于事先未进行频度表的发送接收,因此,产生频度的初始值与编码时同样,使用拉普拉斯平滑化而全部设为“1”来计算哈夫曼编码。结果为,制作了与图15a所示的初始状态的编码表30-1相同的表。
这里,如果在将最初的编码数据“00101000”读入到区域51-2中的时刻根据表50-2的e列中求出对应的码,则a列为解码数据。对左列和右列进行上述处理,将2个解码数据在表51-3上结合,由此,能够对编码前的记录进行解码。由于哈夫曼编码是前缀码,因此,能够从起始处依次对编码位串进行解码,因此,不需要特别的分隔符。
由于左列的解码数据为“0010”,右列的解码数据为“1000”,因此,在表50-2的相应的栏的频度上加1。根据该相加后的频度求出图24b所示的表50-3的哈夫曼编码。
这里,读入第2个记录的数据“010101”。首先,根据左侧的e列对第1列进行解码。即,从编码数据的起始找到“010”,获知它在表50-3中与解码后的数据“0010”对应。接下来,根据右侧的e列对第2列进行解码。即,编码数据的剩余部分为“101”,因此,当观察表50-3时,可知它与“1000”对应。因此,获知了解码后的右列的数据为“1000”。而且,将左列和右列的解码后的符号列结合,得到了“00101000”。然后,将表50-3更新。由于哈夫曼编码是前缀码,因此,不需要分隔符。通过反复进行该处理,能够进行解码。
在图25a中,第3个编码数据为“001001”,因此,根据表50-4的左列可知“001”与“0010”对应,根据右列可知“001”与“1000”对应。因此,第3个解码后符号列为“00101000”。
此外,如图25b所示,第4个编码数据为“00100010”,因此,根据表50-5可知左列的“001”与“0010”对应,右列的“00010”与“1100”对应。因此,可知第4个解码后的符号列为“00101100”。
如图26a所示,第5个编码数据为“0000011”,因此,根据表50-6的左列可知,“00000”与“1010”对应,根据右列可知,“11”与“1000”对应。因此,第5个解码后符号列为“10101000”。
此外,第6个编码数据为“0101”,因此,根据表50-7可知,左列的“01”与“0010”对应,右列的“01”与“1000”对应。因此,可知第6个解码后的符号列为“00101000”。通过反复进行以上的处理,能够进行全部记录的解码。
图27a~图31b是说明对通过图18a~图22b所示的自适应型算术编码方法而被编码的编码数据进行解码的解码方法的图。
事先确定对通过图18a~图22b所示的自适应型算术编码方法而被编码的编码数据进行解码,即,事先确定对由1位的列×8列构成的8位的记录进行处理。此外,也预先确定了算术编码的方式。
在解码侧,事先准备图27a所示的表60-1。通过上述确定而制成了由8块构成的表。虽然在各块中,列数据为“0”和“1”这2种情况是必要的,但与编码时同样,仅存储“0”时的数据。在自适应型中,由于事先不进行频度表的发送接收,因此,产生频度的初始值与编码时同样,使用拉普拉斯平滑化而全部设为“1”以计算出现概率,所得的表是图27a所示的表60-1。
这里,将第1个记录的数据“00101”读入到区域61-2中。另外,由于算术符号并非前缀码,因此,需要使用能够判定记录分隔符的协议。
当将接收数据“00101”解释为二进制小数时,得到了编码数据0.15625。根据该数据来判定列值并通过与算术编码同样的方法进行区间的划分,由此,如表61-3所示,得到了编码前的记录、即解码数据“00101000”。
在记录数上加1并在该解码数据“00101000”的“0”所处的列的频度上加1而重新计算出现概率,得到了图27b所示的表60-2。
这里,读入第2个记录的数据“01”。
当将接收数据“01”解释为二进制小数时,得到了编码数据0.25。根据该数据来判定列值并通过与算术编码同样的方法进行区间的划分,由此,得到了解码数据“00101000”。以下,为了明确起见,对用于取得该第2个解码数据的处理例进行详细说明。
在表60-2中,通过输入第1个编码数据,而记载图27b所示的频度。输入的第2个编码值“01”是二进制小数0.01的小数部分,在十进制形式中,是0.25。利用根据该十进制形式的值“0.25”和解码后的各列的“0”的频度而求得的每个列(位)的“0”的出现概率,按照每个位来依次求解解码数据。对最初的位进行解码时的区间的初始值为[0,1)。根据每个列的“0”的出现概率来反复进行区间划分。划分值通过“(区间的最大值-区间的最小值)*“0”的概率+区间的最小值”这一计算式来计算。
首先,根据在表60-2的最初的列中记载的“0”的频度“2”和记录数“3”而如表60-2中记载的那样求出出现概率“0.667”,通过上述式子求出当前的区间的划分值。当前的区间是初始值的[0,1),因此,计算出的划分值为“0.667”。求解该划分值的处理与图5b所示的列划分范围判定单元20-1的处理对应。(另外,也可以在频度更新时预先计算出现概率。)
解码后的记录的各列的值在码值<=划分值时为“0”,在符号值>划分值时为“1”。在目前的情况下,划分值为“0.667”,符号值为“0.25”,因此,最初的列的解码后的位值为“0”。该处理与图5b的列1解码单元14a-1的处理对应。此外,由于最初的列的位值为“0”,划分值为“0.667”,因此,使接下来的区间为比划分值小的范围的[0,0.667)。该处理与图5b的区间划分单元21-1的处理对应。
接下来,根据表60-2的第2列的“0”的出现频度求解当前的区间[0,0.667)的划分值“0.444”,根据该划分值和符号值“0.25”的大小关系,第2列的解码后的位值为“0”。此外,根据该解码位值,接下来的区间为[0,0.444)。这些针对第2列的处理与针对最初的列的处理同样,与图5b中记载的通过列划分范围判定单元20-2、列2解码单元14a-2以及区间划分单元21-2进行的处理对应。
以下,同样地,根据表60-2的第3列的“0”的出现频度求解当前的区间[0,0.444)的划分值“0.148”,根据该划分值与符号值“0.25”之间的大小关系,第3列的解码后的位值为“1”。此外,根据该解码位值,接下来的区间为[0.148,0.444)。
通过按照每个列依次反复进行上述处理,而完成1个记录的解码。
这样,通过图5b的混合单元17a将被依次解码的列数据混合而成为1个记录的解码数据。
接下来,在图27b所示的表60-2的记录数上加上1,在第2个解码数据“00101000”的“0”所处的列的频度上加上1而重新计算出现概率,该计算是在图28a所示的表60-3中进行的。
这里,读入第3个记录的数据“01”。当将接收数据“01”解释为二进制小数时,得到了编码数据0.25。根据该数据来判定列值并通过与针对第2个记录进行说明的方法同样的方法进行区间的划分,由此,得到了解码数据“00101000”。
在记录数上加1并在该解码数据“00101000”的“0”所处的列的频度上加1而重新计算出现概率,该计算是在图28b所示的表60-4中进行的。
这里,读入第4个数据“1”。当将接收数据“1”解释为二进制小数时,得到了编码数据0.5。根据该数据来判定列值并通过与先前说明的方法同样的方法进行区间的划分,由此,得到了解码数据“00101100”。
在记录数上加1并在该解码数据“00101100”的“0”所处的列的频度上加1而重新计算出现概率,该计算是在图29a所示的表60-5中进行的。
这里,读入第5个记录的数据“111”。当将接收数据“111”解释为二进制小数时,得到了编码数据0.875。根据该数据来判定列值并通过与先前说明的方法同样的方法进行区间的划分,由此,得到了解码数据“10101000”。
在记录数上加1并在该解码数据“10101000”的“0”所处的列的频度上加1而重新计算出现概率,该计算是在图29b所示的表60-6中进行的。
这里,读入第6个记录的数据“01”。当将接收数据“01”解释为二进制小数时,得到了编码数据0.25。根据该数据来判定列值并通过与先前说明的方法同样的方法进行区间的划分,由此,得到了解码数据“00101000”。
在记录数上加1并在该解码数据“00101000”的“0”所处的列的频度上加1而重新计算出现概率,该计算是在图30a所示的表60-7中进行的。
这里,读入第7个记录的数据“01”。当将接收数据“01”解释为二进制小数时,得到了编码数据0.25。根据该数据来判定列值并通过与先前说明的方法同样的方法进行区间的划分,由此,得到了解码数据“00101000”。
在记录数上加1并在该解码数据“00101000”的“0”所处的列的频度上加1而重新计算出现概率,该计算是在图30b所示的表60-8中进行的。
这里,读入第8个记录的数据“01”,当将接收数据“01”解释为二进制小数时,得到了编码数据0.25。根据该数据来判定列值并通过与先前说明的方法同样的方法进行区间的划分,由此,得到了解码数据“00101000”。
在记录数上加1并在该解码数据“00101000”的“0”所处的列的频度上加1而重新计算出现概率,该计算是在图31a所示的表60-9中进行的。
这里,读入第9个记录的数据“10101”。当将接收数据“10101”解释为二进制小数时,得到了编码数据0.65625。根据该数据来判定列值并通过与先前说明的方法同样的方法进行区间的划分,由此,得到了解码数据“00110000”。
在记录数上加1并在该解码数据“00110000”的“0”所处的列的频度上加1而重新计算出现概率,该计算是在图31b所示的表60-10中进行的。
这里,读入第10个记录的数据“101111”。当将接收数据“101111”解释为二进制小数时,得到了编码数据0.734375。根据该数据来判定列值并通过与先前说明的方法同样的方法进行区间的划分,由此,得到了解码数据“00111100”。
图32是在将本实施方式以程序来安装的情况下的、执行程序的例示的计算机的硬件环境图。
例示的计算机60例如包含cpu50、rom51、ram52、网络接口53、存储装置56、读写驱动器57以及输入输出器件59。它们通过总线55而相互连接。
cpu50执行安装了本实施方式的程序。程序被记录在存储装置56或者便携记录介质58中,并通过从这些介质展开到ram52中而能够由cpu50执行。
存储装置56例如是硬盘等。便携记录介质58包含软盘等磁盘、cd-rom、dvd、blu-ray等光盘、ic存储器等半导体存储器等,该便携记录介质58被插入于读写驱动器57,而进行向便携记录介质58的读写。在本实施方式中,安装有本实施方式的程序不仅可以记录在存储装置56或便携记录介质58中,还可以将作为编码对象的输入固定长度数据暂时记录在该程序中,然后读出到ram52中并进行编码。
rom51存储有用于执行经由总线55的通信以及网络接口53、输入输出器件59的功能的bios等基本程序。cpu50执行这些基本程序,由此,实现例示的计算机60的基本功能。
输入输出器件59用于受理来自使用例示的计算机60的用户的信息输入或者向用户输出信息。输入输出器件59例如包含键盘、鼠标、触摸板、显示器、打印机等。
网络接口53用于供例示的计算机60经由网络54与其他的计算机或网络装置等进行通信。在本实施方式中,安装有本实施方式的程序能够借助网络54而记录在存储装置56或者便携记录介质58中。此外,也可以在与网络54连接的其他的计算机或网络装置上执行安装有本实施方式的程序,并经由网络53进行该输入输出数据的发送和接收。而且,要编码的固定长度数据也可以从与网络54连接的具有传感器的终端发送。
网络54只要是有线网络、无线网络等能够在计算机彼此之间或者计算机与网络装置之间进行通信的网络即可,可以是任意网络。在一例中,网络54能够包含互联网、lan(localareanetwork:局域网)、wan(wideareanetwork:广域网络)、固定电话网络、移动电话网络、自组织网络、vpn(virtualprivatenetwork:虚拟专用网)、传感器网络等。
如以上说明的那样,在本发明的一个方面的本实施方式中,在固定长度数据的固定长度位串由多个已确定的字段中所记述的具有不同的含义的数据构成,并且每个固定长度数据的位于相同位置的字段中所记述的数据是相同种类的数据的情况下,将固定长度数据的固定长度位串划分为任意的位数的列,并且以使列彼此独立的方式沿列方向连续地进行编码,由此,能够实现压缩率比以往的编码方法高的压缩编码。
作为提高压缩率的例子,根据本发明者利用本实施方式试制的压缩编码装置,能够将70,016字节、560,128位的原始数据压缩至13,532字节、94,000位(不包含补位)。gzip是14,464字节、115,712位的压缩,bzip2是12,985字节、103,880位的压缩,因此,能够理解本实施方式的压缩编码方法的有效性。
此外,本实施方式的编码装置也可以通过fpga(fieldprogrammablegatearray:现场可编程门阵列)等硬件来安装。
例如,本实施方式的编码装置也可以一部分是硬件,另一部分是软件,通过将硬件与软件组合来实现。
此外,上述各实施方式能够相互独立地或者相互组合地来实现。
在上述实施方式中,在使用自适应型编码方法的实施方式中,能够逐次地进行压缩编码,无需暂时将数据汇总而存储,因此,能够实时地执行编码。在将上述实施方式应用于实时的编码的情况下,则将依次输入的规定数的记录假想作为表数据,沿列方向进行压缩。
标号说明
1:传感器网络
2:传感器
3:网关
4:处理装置
10、10a、16:划分单元
11-1~11-m、11a-1~11a-m:列1~m寄存器
12-1~12-m:列1~m编码单元
12a-1~12a-m、20-1~20-m:列1~m列划分范围判定单元
13、17、17a:混合单元
14-1~14-m、14a-1~14a-m:列1~m解码单元
15-1~15-m:列1~m频度表、编码表
18-1~18-m、21-1~21-m:区间划分单元
19:编码单元
50:cpu
51:rom
52:ram
53:网络接口
54:网络
55:总线
56:存储装置
57:读写驱动器
58:便携记录介质
59:输入输出器件
- 还没有人留言评论。精彩留言会获得点赞!