基于预训练随机傅里叶特征核LMS的超参数优化方法与流程
本发明属于核自适应滤波器的超参数优化技术领域,具体涉及一种基于预训练随机傅里叶特征核lms(leastmeansquare,最小均方算法)的超参数优化方法。
背景技术:
核自适应滤波器是一种核学习方法和传统自适应滤波方法相结合的滤波技术。引入了将原始空间的非线性问题转化为高维特征空间的线性优化问题进行求解的思想。在非线性信号处理的多个领域(非线性系统辨识、非线性时间序列预测、回声消除等)广泛证实了其具有较好的非线性系统建模能力。
随机傅里叶特征核最小均方算法是基于核近似技术的一种核自适应滤波算法。其结构本质上是一种单层神经网络模型。核近似技术通过近似核映射函数或核矩阵降低计算复杂度。随机傅里叶特征方法通过近似高斯核得到显式的特征映射表达,从而得以通过迭代的权值网络进行计算,得到接近线性算法的计算复杂度。相比于nystrom方法,基于随机傅里叶特征的核最小均方算法可以得到一个近似线性算法的计算过程。即使在非平稳下,网络规模不会增长。
由bochner理论可知,高斯核存在一个对应的概率分布p(w),使得核函数存在无偏估计。为了保证得到实数化的特征,由cos(w′(x-y))近似替代ejw′(x-y)。因此假设存在cos(w′(x-y))=zw(x)tzw(y),使得一组随机基满足zw(x)=[cos(w′x)sin(w′x)]。为了降低近似误差,进一步采用蒙特卡洛平均方法,即:
因此随机特征基可表示为:
其中蒙特卡洛样本
实际工程应用当中,蒙特卡洛样本通过随机采样方法获取并直接用于随机傅里叶特征核最小均方算法的参数赋值。但是直接使用随机采样值会带来随机采样差异问题,如图1所示。
100次独立蒙特卡洛采样得到100组w样本集,通过训练随机傅里叶特征核最小均方算法继而得到训练和测试稳态均方误差。得到100组训练和测试稳态均方误差之间的差异值很大。因此,在工程应用中使用随机傅里叶特征核最小均方算法时,为了保证算法的精度性能以及降低计算复杂度,如何获取一组超参数值仍面临着极大的挑战。
技术实现要素:
本发明的目的是为了解决为保证算法的精度性能和降低计算复杂度,如何获取一组超参数值的问题。
本发明为解决上述技术问题采取的技术方案是:
基于预训练随机傅里叶特征核lms的超参数优化方法,该方法包括以下步骤:
步骤一、给定一组训练集
步骤二、确定核参数σ的取值,并预先设定m个维度参数的取值为[d1,d2,…,dj,…,dm],其中:d1,d2,dj和dm分别代表第1个维度参数的取值,第2个维度参数的取值,第j个维度参数的取值和第m个维度参数的取值;
步骤三、对于步骤二的每一个维度均生成n组独立同分布的超参数w集合,超参数w集合满足高斯分布n(0,σ2i),其中:i是指与输入信号x(i)同维度的单位向量;
步骤四、建立预训练随机傅里叶特征核lms算法,利用步骤一确定的预训练集对建立的算法进行预训练,得到第j个维度下的任一组超参数w集合的稳态均方误差值;
步骤五、对于第j个维度下的其他n-1组超参数w集合均重复步骤四的过程,得到第j个维度下的其他n-1组超参数w集合的稳态均方误差值,通过比较得到第j个维度下的最小的稳态均方误差值;
步骤六、重复步骤四和步骤五的过程,分别得到其余m-1个维度下的最小的稳态均方误差,将不同维度下的最小的稳态均方误差进行比较,并将最小的稳态均方误差中的最小值对应的超参数w集合的值作为超参数的值。
本发明的有益效果是:本发明的基于预训练随机傅里叶特征核lms的超参数优化方法,本发明的方法基于随机傅里叶特征核最小均方算法,在预训练集合的基础上,实现各维度下的随机傅里叶特征的性能评价,在最小均方误差准则下能够通过预训练得到的最小均方误差值确定最优维度下的一组傅里叶特征超参数取值集合,本发明的方法提高了随机傅里叶特征建模的精度,在自适应滤波系统中提高被建模系统与随机傅里叶特征网络的耦合度,克服了超参数取值由于随机采样差异性带来的稳态性能不稳定的问题。
在核自适应滤波系统的时间序列预测应用场景下,本发明方法在保证相同的精度下,维度可以减小3/4,即计算复杂度平均减小3/4;在核自适应滤波系统的信道均衡应用场景下,本发明方法在保证相同的精度下,维度可以减小2/3,即计算复杂度平均减小2/3。
附图说明
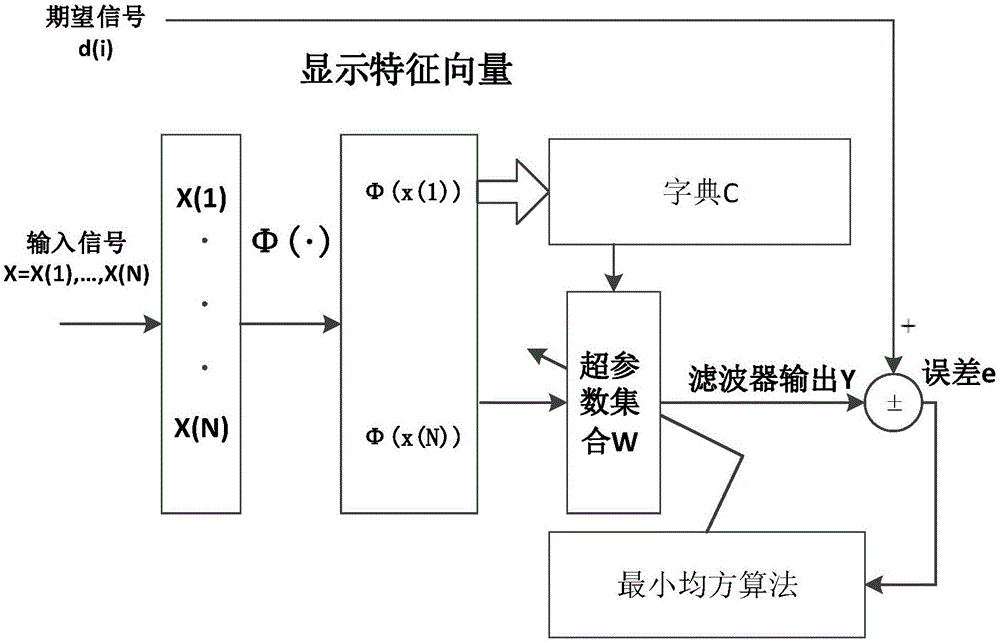
图1是传统核自适应滤波器系统的结构框图;
图1中x(1)和x(n)分别代表第1组输入信号和第n组输入信号,φ(x(1))和φ(x(n))分别代表第1组输入信号对应的显示特征向量和第n组输入信号对应的显示特征向量;
图2是本发明方法的流程图;
图3是随机傅里叶特征核lms算法的结构图;
图4是在lorenz混沌时间序列预测的实验中,量化核最小均方算法、随机傅里叶特征核最小均方算法(维度d=100)、随机傅里叶特征核最小均方算法(维度d=400)和本发明预训练随机傅里叶特征核lms(预训练随机傅里叶特征核最小均方算法,维度d=100)的稳态均方误差对比图;
图5是在时变信道均衡实验中,量化核最小均方算法、随机傅里叶特征核最小均方算法(维度d=100)、随机傅里叶特征核最小均方算法(维度d=300)和本发明预训练随机傅里叶特征核lms(预训练随机傅里叶特征核最小均方算法,维度d=100)的稳态均方误差对比图。
具体实施方式
下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
具体实施方式一:结合图2说明本实施方式。本实施方式所述的基于预训练随机傅里叶特征核lms的超参数优化方法,该方法包括以下步骤:
步骤一、给定一组训练集
步骤二、确定核参数σ的取值,并预先设定m个维度参数的取值为[d1,d2,…,dj,…,dm],其中:d1,d2,dj和dm分别代表第1个维度参数的取值,第2个维度参数的取值,第j个维度参数的取值和第m个维度参数的取值;
步骤三、对于步骤二的每一个维度均生成n组独立同分布的超参数w集合,超参数w集合满足高斯分布n(0,σ2i),其中:i是指与输入信号x(i)同维度的单位向量;
步骤四、建立预训练随机傅里叶特征核lms算法,(预训练随机傅里叶特征核lms算法是指:该算法利用
步骤五、对于第j个维度下的其他n-1组超参数w集合均重复步骤四的过程,得到第j个维度下的其他n-1组超参数w集合的稳态均方误差值,通过比较得到第j个维度下的最小的稳态均方误差值;
步骤六、重复步骤四和步骤五的过程,分别得到其余m-1个维度下的最小的稳态均方误差,将不同维度下的最小的稳态均方误差进行比较,并将最小的稳态均方误差中的最小值对应的超参数w集合的值作为超参数的值。
本实施方式方法的特点:
稳态性能:得到的超参数集合,使得算法性能即使在用于其他建模场景,也能保证一定的稳态性能。本发明的预训练随机傅里叶特征核最小均方算法具有超越平均均方误差的优良性能。
计算复杂度:相比于未预训练的随机傅里叶特征核最小均方算法,预训练的核最小均方算法可以采用较低的维度实现相同的精度。因此同样精度下,计算复杂度更低。
具体实施方式二:本实施方式对实施方式一所述的基于预训练随机傅里叶特征核lms的超参数优化方法进行进一步的限定,所述步骤二中核参数σ的取值范围为[0.01,2]。
核参数的取值方法:需要多次尝试根据训练误差的效果确定取值。
具体实施方式三:本实施方式对实施方式一所述的基于预训练随机傅里叶特征核lms的超参数优化方法进行进一步的限定,所述步骤二中第j个维度参数dj的取值范围为[10,1000],其中:j=1,2,…,m。
维度参数dj取值方法:建议倍数取值法:如dj+1为2倍的dj;dj+2为2倍的dj+1;以此类推;
通过训练得到多个核参数下的稳态误差,选择稳态误差最小的核参数值,根据实际计算复杂度及存储需求确定m个维度参数;即实验过程中根据训练得到的多个核参数下的稳态误差不断调整核参数σ值和m个维度的参数值。
具体实施方式四:本实施方式对实施方式二或三所述的基于预训练随机傅里叶特征核lms的超参数优化方法进行进一步的限定,所述步骤四的具体过程为:
如图3所示,通过特征映射φ(·)的映射,得到显示特征向量φw(x(i′))表示为:
其中:超参数
预训练随机傅里叶特征最小均方算法如下:
将步骤一确定的预训练集
初始化预训练随机傅里叶特征核lms算法值向量ω(1),设置迭代循环的次数为p;
对于第1次迭代:通过特征映射φ(·)的映射,计算得到显示特征向量φw(x(1))为:
其中:超参数
利用显示特征向量φw(x(1))计算出滤波器输出y(1)为:
y(1)=ω(1)tφw(x(1))
其中:ω(1)t为ω(1)的转置;
利用滤波器输出y(1)计算出期望误差e(1)为:
e(1)=d(1)-y(1)
并得到更新后的权值向量ω(2)为:
ω(2)=ω(1)+μe(1)φw(x(1))
对于第2次迭代:计算得到显示特征向量φw(x(2))为:
计算滤波器输出y(2)为:
y(2)=ω(2)tφw(x(2))
计算期望误差e(2)为:
e(2)=d(2)-y(2)
并得到更新后的权值向量ω(3)为:
ω(3)=ω(2)+μe(2)φw(x(2))
同理,直至完成p次迭代;
取p次中最后50次迭代的期望误差的平方的均值作为输入的超参数w集合的稳态均方误差值。
实施例
实例1:lorenz混沌时间序列预测
实验条件:应用场景为已知过去的样本值[x(n-5),x(n-4),…,x(n-1)],预测当前的样本值x(n);
lorenz模型描述为以下的三阶差分方程:
其中,a=10;b=8/3;c=28;四阶龙格库塔法的步长0.01。生成的时间序列添加20db白噪声。
预训练随机傅里叶特征核最小均方算法的参数设置:步长为0.1;维度选择为10,30,50,100,200,400,800,1600;核参数为1;
由图4可知,在lorenz混沌时间序列预测的实验中,提出的方法相比于未预训练的随机傅里叶特征方法,在相同的精度下维度为其1/4,即相当于计算复杂度为原来方法的1/4;
实例2:时变信道均衡
实验条件:信道模型线性部分的传递函数定义如下:
其中:h0=0.3482;h1=0.8704;h2=0.3482;h0(j),h1(j),h2(j)分别为时变系数,
由二阶markov模型生成,其中白噪声由二阶巴特沃斯滤波器生成。信道非线性部分的模型定义如下:r(n)=x(n)+0.2x(n)2+v(n),其中v(n)为信噪比为20db的白高斯噪声。
预训练随机傅里叶特征核最小均方算法的参数设置:步长为0.1;维度选择为10,30,50,100,200,400,800,1600;核参数为2;
由图5可知,在时变信道均衡实验中提出的方法相比未预训练的随机傅里叶特征方法相比,相同精度下维度为原来的1/3,即计算复杂度为原来的1/3;
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!