一种QC-LDPC编码算法及实现方法与流程
本发明涉及固态存储中数据编码相关技术领域,尤其是指一种qc-ldpc编码算法及实现方法。
背景技术:
低密度奇偶校验码(low-densityparitycheckcode,ldpc)是一种高效的编码技术,但由于校验矩阵具有不规律性,存在校验矩阵存储于读取困难、编码复杂度高等问题,相对难以实现。
准循环低密度奇偶校验码(quasi-cysliclow-densityparity-checkcode,qc-ldpc)即准循环ldpc码。准循环ldpc码是结构化ldpc码的重要子集,其生成矩阵g(generatematrix)和校验矩阵h(checkmatrix)都是有循环矩阵构成的阵列。循环矩阵每一行都由上一行循环右移一位得到,其中第一行的上一行为最后一行。
qc-ldpc码校验矩阵的子矩阵具有如下特点:(1)每个子矩阵是一个方阵。(2)循环子矩阵的任一行(列)都是上一行(列)向右移动一位得到的,特别的,矩阵的第一行(列)由最后一行(列)循环右移一位得到。(3)循环矩阵完全可以由其第一行或者第一列决定。
对于如下校验矩阵h,假设qc大小为c,即一个qc块为c乘以c的矩阵。
其中,hij为c乘以c的循环矩阵即全0矩阵或者循环置换矩阵,m乘以c为校验位的长度,n乘以c为原始信息位加上校验位的总长度。
生成矩阵g可以定义为:
g=(i|gp)
其中:i为单位矩阵。可得校验位为:
p=gpu
其中,p为校验位,u为原始信息位即用户数据。通过该矩阵gp,可以从原始信息位u计算出校验位p。但是,gp需要占用大量的存储空间,使得成本增加,并且计算吞吐率低。
技术实现要素:
本发明是为了克服现有技术中存在上述的不足,提供了一种能够减少存储空间且提高计算速度的qc-ldpc编码算法及实现方法。
为了实现上述目的,本发明采用以下技术方案:
一种qc-ldpc编码算法,通过构造和选择特殊形式的校验矩阵h,校验矩阵h的形式如下:
其中,blku为原始信息位u的长度,blkp为校验位p的长度,校验位p分为三个部分[p1p2p3],p1部分的长度为blkm,p3的长度为blkn,p2的长度为blkp-blkm-blkn,码字结构定义为[up1p2p3];
根据校验原理,h×[up1p2p3]t=0,求解得到,
(h′311+h313h′21+(h312+h313h22)h′11)ut+(h″311+h313h″21+(h312+h313h22)h″11)p1t=0;
其中,h11=[h′11h″11],h21=[h′21h″21],h311=[h′311h″311];
定义l=h′311+h313h′21+(h312+h313h22)h′11,
定义j=h″311+h313h″21+(h312+h313h22)h″11;
将校验矩阵h的形式调整为,
根据校验原理,h×[up1p2p3]t=0,可以得到校验位为,
p1=g0×ut
p2=h11×[up1]t
p3=[h21h22]×[up1p2]t
其中(g0=j-1×l),为稠密循环矩阵,h11,h21和h22为稀疏循环矩阵。
本发明提出一种通过使用部分生成矩阵g和部分校验矩阵h,来从原始信息位u计算出校验位p。该算法仅需使用少量的存储空间,计算速度快。
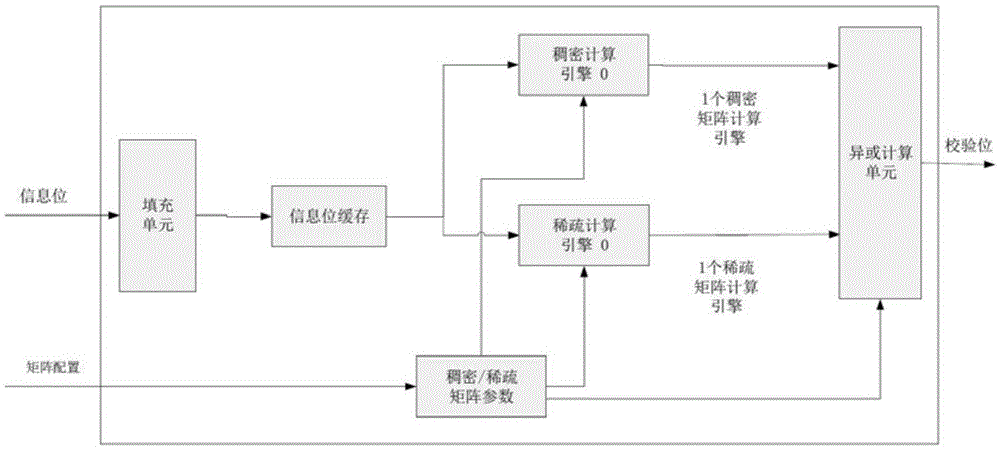
本发明还提供了一种qc-ldpc编码算法的实现方法,具体包括如下部分:
填充单元:当原始信息位u的长度不为qc长度的整数倍时,在原始信息位u中填充0或者1,使其长度为qc长度的整数倍;当原始信息位u长度为qc长度的整数倍时,则不需要填充;
信息位缓存:使用乒乓两个缓存来提高ldpc编码器的性能,如果用户对ldpc性能要求不高,则使用乒乓中的其中一个缓存;
稠密/稀疏矩阵参数:保存稠密矩阵和稀疏矩阵的计算参数,在ldpc编码过程中,用来控制每个计算时钟周期内,哪些稠密或者稀疏计算引擎参与计算;
稠密计算引擎:每个计算引擎在一个计算时钟周期内完成一个稠密qc矩阵的乘法计算;
稀疏计算引擎:每个计算引擎在一个计算时钟周期内完成一个稀疏qc矩阵的乘法计算;
异或计算单元:使用异或运算来完成矩阵乘法中的累加计算功能;
具体操作步骤如下:
(1)原始信息位u通过填充单元使得原始信息位u的长度为qc长度的整数倍;
(2)通过填充单元的信息位u使用乒乓两个缓存来提高ldpc编码器的性能,进入到稠密计算引擎和稠密计算引擎中;
(3)同时,配置稠密循环矩阵和稀疏循环矩阵,进入到稠密/稀疏矩阵参数中,用来控制每个计算时钟周期内,哪些稠密或者稀疏计算引擎参与计算;
(4)信息位u结合稠密循环矩阵和稀疏循环矩阵,通过稠密计算引擎完成稠密qc矩阵的乘法计算,通过稀疏循环矩阵完成稀疏qc矩阵的乘法计算;
(5)进入异或计算单元后,根据矩阵参数的配置信息,通过异或来实现矩阵乘法中的累加功能,最终输出校验位p。
本发明还提出一种该算法的实现方法,可以根据用户的性能需求灵活定制电路,实现性能、功耗和电路面积之间的最优化。矩阵参数可固化以节省电路面积,也可动态配置以满足不同的使用场景。
作为优选,定制稠密计算引擎的个数,实现性能、功耗和电路面积之间的最优化。
作为优选,定制稀疏计算引擎的个数,实现性能、功耗和电路面积之间的最优化。
作为优选,在步骤(5)中,矩阵参数包含稠密矩阵信息表、稀疏矩阵信息表、控制信息表,
稠密矩阵信息表:每个表项保存矩阵的首行信息;
稀疏矩阵信息表:每个表项保存矩阵首行非0值的位置信息;
控制信息表:控制信息表中每个表项对应每个计算时钟周期,内容包含稠密矩阵信息表地址索引及其有效位,稀疏矩阵信息表地址索引及其有效位,信息位地址索引,计算结束标志位。
本发明的有益效果是:仅需使用少量的存储空间,计算速度快;可以根据用户的性能需求灵活定制电路,实现性能、功耗和电路面积之间的最优化;矩阵参数可固化以节省电路面积,也可动态配置以满足不同的使用场景。
附图说明
图1是本发明的实现方法示意图;
图2是本发明具体实例一的实现方法示意图;
图3是本发明具体实例二的实现方法示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的描述。
一种qc-ldpc编码算法,通过构造和选择特殊形式的校验矩阵h,校验矩阵h的形式如下:
其中,blku为原始信息位u的长度,blkp为校验位p的长度,校验位p分为三个部分[p1p2p3],p1部分的长度为blkm,p3的长度为blkn,p2的长度为blkp-blkm-blkn,码字结构定义为[up1p2p3];
根据校验原理,h×[up1p2p3]t=0,求解得到,
(h″311+h313h″21+(h312+h313h22)h″11)ut+(h″311+h313h″21+(h312+h313h22)h″11)p1t=0;
其中,h11=[h′11h″11],h21=[h′21h″21],h311=[h′311h″311];
定义l=h′311+h313h′21+(h312+h313h22)h′11,
定义j=h″311+h313h″21+(h312+h313h22)h″11;
将校验矩阵h的形式调整为,
根据校验原理,h×[up1p2p3]t=0,可以得到校验位为,
p1=g0×ut
p2=h11×[up1]t
p3=[h21h22]×[up1p2]t
其中(g0=j-1×l),为稠密循环矩阵,h11,h21和h22为稀疏循环矩阵。
如图1所示,一种qc-ldpc编码算法的实现方法,具体包括如下部分:填充单元:当原始信息位u的长度不为qc长度的整数倍时,在原始信息位u中填充0或者1,使其长度为qc长度的整数倍;当原始信息位u长度为qc长度的整数倍时,则不需要填充;
信息位缓存:使用乒乓两个缓存来提高ldpc编码器的性能,如果用户对ldpc性能要求不高,则使用乒乓中的其中一个缓存;
稠密/稀疏矩阵参数:保存稠密矩阵和稀疏矩阵的计算参数,在ldpc编码过程中,用来控制每个计算时钟周期内,哪些稠密或者稀疏计算引擎参与计算;
稠密计算引擎:每个计算引擎在一个计算时钟周期内完成一个稠密qc矩阵的乘法计算;可以定制稠密计算引擎的个数,实现性能、功耗和电路面积之间的最优化;
稀疏计算引擎:每个计算引擎在一个计算时钟周期内完成一个稀疏qc矩阵的乘法计算;可以定制稀疏计算引擎的个数,实现性能、功耗和电路面积之间的最优化;
异或计算单元:使用异或运算来完成矩阵乘法中的累加计算功能;
具体操作步骤如下:
(1)原始信息位u通过填充单元使得原始信息位u的长度为qc长度的整数倍;
(2)通过填充单元的信息位u使用乒乓两个缓存来提高ldpc编码器的性能,进入到稠密计算引擎和稠密计算引擎中;
(3)同时,配置稠密循环矩阵和稀疏循环矩阵,进入到稠密/稀疏矩阵参数中,用来控制每个计算时钟周期内,哪些稠密或者稀疏计算引擎参与计算;
(4)信息位u结合稠密循环矩阵和稀疏循环矩阵,通过稠密计算引擎完成稠密qc矩阵的乘法计算,通过稀疏循环矩阵完成稀疏qc矩阵的乘法计算;
(5)进入异或计算单元后,根据矩阵参数的配置信息,通过异或来实现矩阵乘法中的累加功能,最终输出校验位p;矩阵参数包含稠密矩阵信息表、稀疏矩阵信息表、控制信息表,
稠密矩阵信息表:每个表项保存矩阵的首行信息;
稀疏矩阵信息表:每个表项保存矩阵首行非0值的位置信息;
控制信息表:控制信息表中每个表项对应每个计算时钟周期,内容包含稠密矩阵信息表地址索引及其有效位,稀疏矩阵信息表地址索引及其有效位,信息位地址索引,计算结束标志位。
假设qc矩阵的长度为128bit,原始信息位的长度为128个qc长度,校验位的长度为16个qc长度,其中校验位p1部分的长度blkm为3个qc长度,p3的长度blkn为1个qc长度,p2的长度为12个qc长度。校验矩阵的最大列纵不超过5。矩阵形式如下图所示,
下面根据上述假设前提下,给出两种具体实施实例,但本发明不限于这两种实施实例。
具体实例一:
用户对单个编码器吞吐率要求不高。此时实现方案如图2所示,本设计中将使用单个原始信息位缓存,使用1个稠密矩阵计算引擎,使用1个稀疏矩阵计算引擎。
具体实例二:
对于单个编码器,用户需要达到最高的编码吞吐率。此时实现方案如图3所示,本设计中将使用乒乓两个原始信息位缓存,使用3个稠密矩阵计算引擎,使用5个稀疏矩阵计算引擎。
对于使用1个稠密矩阵计算引擎和1个稀疏矩阵计算引擎,下面给出一种稠密/稀疏矩阵参数的具体实施实例,但本发明不局限于该实施实例。
包含稠密矩阵信息表,稀疏矩阵信息表,控制信息表。
稠密矩阵信息表:对于稠密矩阵,由于矩阵的其他各行可以通过首行移位得到,只需要保存矩阵的首行信息即可,所以稠密矩阵信息表中每个表项为128bit。
稀疏矩阵信息表:对于稀疏矩阵,矩阵的其他各行可以通过首行移位得到,并且每一行中只有1个非0值,因此只需要保存矩阵首行非0值的位置信息即可,所以稀疏矩阵的信息表中每个表项为7bit位置信息。
控制信息表:控制信息表中每个表项对应每个计算时钟周期,内容包含稠密矩阵信息表地址索引及其有效位,稀疏矩阵信息表地址索引及其有效位,信息位地址索引,计算结束标志位。
本方案提出一种通过使用部分生成矩阵g和部分校验矩阵h,来从原始信息位u计算出校验位p的算法,该算法仅需使用少量的存储空间,计算速度快。还提出一种该算法的实现方法,可以根据用户的性能需求灵活定制电路,实现性能、功耗和电路面积之间的最优化。矩阵参数可固化以节省电路面积,也可动态配置以满足不同的使用场景。
- 还没有人留言评论。精彩留言会获得点赞!