一种测试向量的无损压缩和解压缩方法与流程
本发明涉及数据压缩和解压缩领域,具体涉及一种测试向量的无损压缩和解压缩方法。
背景技术:
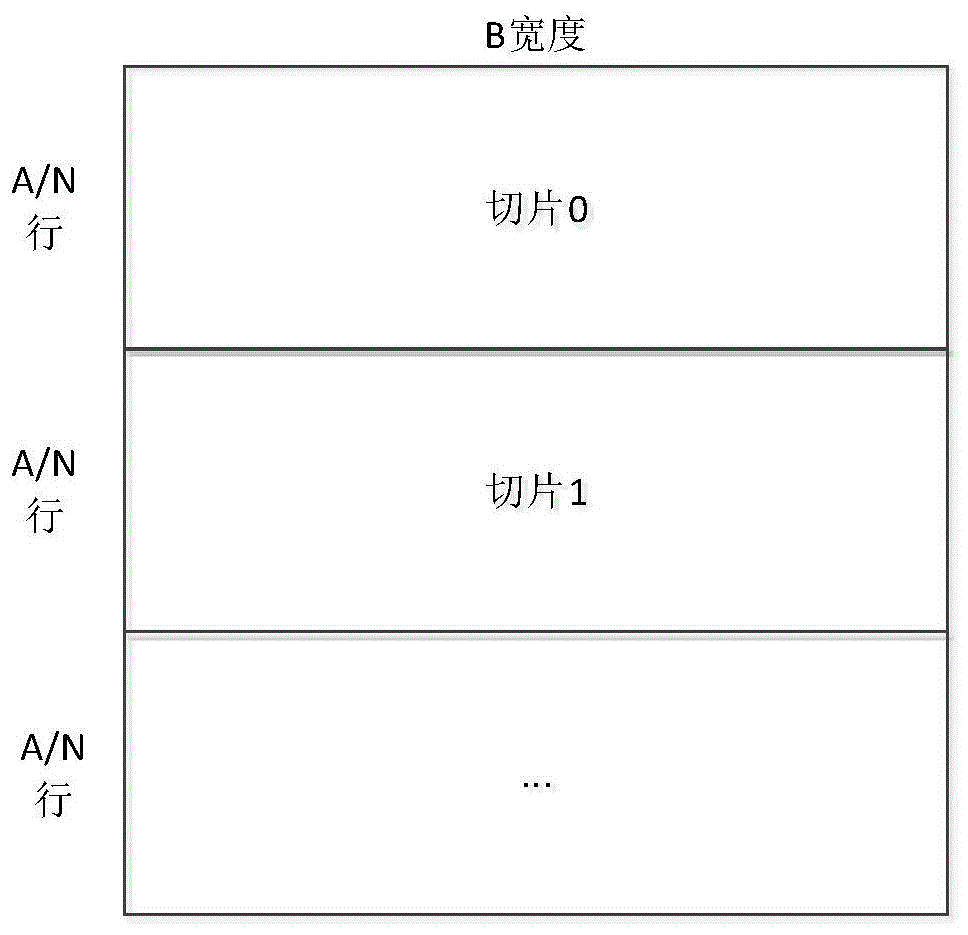
:现有技术中数据压缩包括有损压缩和无损压缩;有损压缩是利用了人类对图像或声波中的某些频率成分不敏感的特性,允许压缩过程中损失一定的信息;虽然不能完全恢复原始数据,但是所损失的部分对理解原始图像的影响缩小,却换来了大得多的压缩比。无损压缩是对文件本身的压缩,和其它数据文件的压缩一样,是对文件的数据存储方式进行优化,采用某种算法表示重复的数据信息,文件可以完全还原,不会影响文件内容,对于数码图像而言,也就不会使图像细节有任何损失。在ate(automatictestequipment)测试领域,被压缩的数据是芯片测试向量,必须无损压缩,而当前主流的无损压缩算法为lz77系列,采用的是哈夫曼编码技术,需要使用字典进行压缩解压缩,可以达到极高的压缩效果。适合在cpu上实现,但是不便于在fpga、asic(applicationspecificintegratedcircuit)上实现。针对ate领域,需要的是一种能够对数据流进行实时压缩,不需要采用字典以便于在fpga上实现的无损压缩算法。压缩率反而不是最重要的需求。技术实现要素:本发明的目的是提供一种测试向量的无损压缩和解压缩方法,压缩方法简单快速,可适用于ate测试领域。为了实现上述目的,本发明采用如下技术方案:一种测试向量的无损压缩方法,包括如下步骤:s01:将测试向量转换为a行b列的数据流,所述数据流采用二进制表示;其中每一列表示一个测试通道在不同时刻的测试数据;每一行表示不同测试通道在同一时刻的测试数据;a和b为大于1的整数;s02:依次对数据流进行逐列压缩,形成每一列数据对应的压缩字和非压缩字;具体对每一列数据进行压缩方法为:s021:设置宽度为1bit深度为m行的窗口,将窗口从该列数据的顶部开始逐行向下滑行,当窗口中添加m-1bit数据时,若m-1bit数据中既有0又有1,则不进行压缩,形成mbit的非压缩字,其中,所述非压缩字中第m-1bit表示压缩标记,第m-2至第0bit表示窗口中对应的m-1bit数据;若m-1bit数据中只有0或者1,则进行压缩,并且窗口继续逐行向下滑行,直至窗口中最新添加数据与窗口中其他行数据不同或者滑行至该列底部,形成mbit的压缩字,其中,所述压缩字中第m-1bit表示压缩标记,第m-2bit表示压缩字符,第m-3至第1bit表示m-1bit数据中压缩字符的个数cnt;第0bit表示窗口中最新添加数据的尾数;s022:形成压缩字或者非压缩字之后,所述窗口滑行至该列数据中未处理的行位置,重复步骤s021,直至窗口滑行至该列数据的底部,得到该列数据的压缩数据;m为大于2小于a的正整数;s03:将每一列数据的压缩数据进行汇合,形成压缩数据流。进一步地,所述步骤s01和步骤s02之间还包括:将a行b列的数据流分割为n个切片,所述切片包括a/n行b列的数据流,所述步骤s02中将n个切片在n个压缩单元中分别进行压缩,得到n个压缩数据模块;a/n为大于m的正整数。进一步地,所述步骤s03将n个压缩数据模块按照切片的顺序进行排列,且相邻的切片对应的压缩数据模块通过插入标记隔开。进一步地,所述压缩字和非压缩字中的压缩标记不同。进一步地,所述步骤s021中当窗口逐行向下滑行时,若窗口中最新添加数据与窗口中其他行数据相同,则压缩字符的个数cnt加1。一种进行无损解压缩方法,包括如下步骤:t01:对每一列的压缩数据按顺序进行解压缩,具体包括:对于非压缩字,去除第m-1bit之后,剩下的第m-2至第0bit数据即为解压缩数据;对于压缩字,将所述压缩字中的压缩字符扩展到cnt位,加上所述压缩字中第0bit的尾数,即为解压缩数据;将该列压缩数据按照顺序组合即为解压缩之后的列数据;to2:重复步骤t01得到b列数据,并将各列数据组合为a行b列的数据流。进一步地,在压缩过程中,将a行b列的数据流分割为n个切片,所述切片包括a/n行b列的数据流,将n个切片在n个压缩单元中分别进行压缩,得到n个压缩数据模块;a/n为大于m的正整数。所述步骤t01中将n个压缩数据模块在n个解压缩单元中分别进行解压缩,得到n个对应的解压缩数据模块。进一步地,所述步骤t01之前还包括接收n个压缩数据模块,其中,在接收每个压缩数据模块时,分析依次接收到的压缩字和非压缩字的位数,若依次接收到的压缩字和非压缩字的位数等于a/n时,则接收到的压缩字和非压缩字为该压缩数据模块中的一列数据,其中,非压缩字的位数等于m-1bit,压缩字的位数等于该压缩字中压缩字符的个数cnt+1。进一步地,依次对每个压缩数据模块进行逐行解压缩,并将解压之后的n个解压缩数据模块中对应的列数据进行无缝拼接,得到对应列的解压缩列数据本发明的有益效果为:本发明提供的一种测试向量的无损压缩和解压缩方法,利用ate数据在列方向上具有高继承性的特点,采用数据流列向滑行压缩算法,能够实现无损压缩和解压缩,且压缩和解压缩过程简单快捷,可适用于ate测试领域。附图说明附图1为实施例1中将数据流分割为n个切片的示意图;附图2为实施例1中对每一列数据进行压缩的方法示意图;附图3为实施例1中形成非压缩字的示意图;附图4为实施例1中形成压缩字的示意图;附图5为实施例1中一个切片压缩形成对应压缩数据模块的示意图;附图6为实施例1中n个切片形成完整压缩数据流的示意图;附图7为实施例1中一个切片对应的压缩数据模块进行解压缩的示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明的具体实施方式做进一步的详细说明。本发明提供的一种测试向量的无损压缩方法,包括如下步骤:s01:将测试向量转换为a行b列的数据流,数据流采用二进制表示;其中每一列表示一个测试通道在不同时刻的测试数据;每一行表示不同测试通道在同一时刻的测试数据;a和b为大于1的整数。本发明方法适用于对ate测试数据进行压缩和解压缩,ate测试向量具有一个特征就是,其二进制数据在列方向上具有很高的继承性,对于大部分通道来说,不需要频繁切换数据,更多的是保持当前值。对于每一列,它的数据变化非常少或者说非常缓慢,可以进行压缩。而在列与列之间,即行方向,由于每个通道的数据是完全独立的,因此不具有压缩空间。因此本发明压缩针对每一列数据进行,为了缩短压缩和解压缩时间,可以将每一列分为多个切片,独立进行压缩和解压缩,再按照切片的顺序进行组合。具体操作如下:将a行b列的数据流分割为n个切片,切片包括a/n行b列的数据流,a/n为大于m的正整数。s02:依次对数据流进行逐列压缩,形成每一列数据对应的压缩字和非压缩字。当数据流被分割为n个切片时,可以将n个切片在n个压缩单元中分别进行压缩,得到n个压缩数据模块。其中,每个压缩单元中也是对每一列数据进行单独压缩,且每个压缩单元的操作均相同。本发明每列的压缩可以独立进行,因此非常方便在fpga上并行处理,也适合cpu的多线程处理。具体对每一列数据进行压缩方法为:s021:设置宽度为1bit深度为m行的窗口,将窗口从该列数据的顶部开始逐行向下滑行,当窗口中添加m-1bit数据时,若m-1bit数据中既有0又有1,则不进行压缩,形成mbit的非压缩字,其中,非压缩字中第m-1bit表示压缩标记,第m-2至第0bit表示窗口中对应的m-1bit数据;若m-1bit数据中只有0或者1,则进行压缩,并且窗口继续逐行向下滑行,直至窗口中最新添加数据与窗口中其他行数据不同或者滑行至该列底部,形成mbit的压缩字,其中,压缩字中第m-1bit表示压缩标记,第m-2bit表示压缩字符,在二进制数据流中,压缩字符为0或1,表示对0或者1进行压缩,第m-3至第1bit表示m-1bit数据中压缩字符的个数cnt;第0bit表示窗口中最新添加数据的尾数。当窗口逐行向下滑行时,若窗口中最新添加数据与窗口中其他行数据相同,则压缩字符的个数cnt加1。上述压缩字和非压缩字中的压缩标记不同,例如可以用0表示没有进行压缩,用1表示进行了压缩。s022:形成压缩字或者非压缩字之后,窗口滑行至该列数据中未处理的行位置,重复步骤s021,直至窗口滑行至该列数据的底部,得到该列数据的压缩数据;m为大于2小于a的正整数。本发明中每一列的压缩数据中可能只包含压缩字或者只包含非压缩字或者同时包含压缩字和非压缩字,并且压缩数据中的压缩字和非压缩字是按照依次形成的顺序进行排列的。s03:将每一列数据的压缩数据进行汇合,形成压缩数据流。当数据流被分给为n个切片时,每一个切片压缩形成的压缩数据模块中包含b列压缩数据,将每一个切片中各列的压缩数据按照列的顺序排列起来,在进行压缩数据汇合的时候,将n个压缩数据模块按照切片的顺序进行排列,且相邻的切片对应的压缩数据模块通过插入标记隔开,从而得到完整的压缩数据流。本发明在上述压缩基础上提供的一种无损解压缩方法,包括如下步骤:t01:对每一列的压缩数据按顺序进行解压缩,具体包括:对于非压缩字,去除第m-1bit之后,剩下的第m-2至第0bit数据即为解压缩数据;对于压缩字,将压缩字中的压缩字符扩展到cnt位,加上压缩字中第0bit的尾数,即为解压缩数据;将该列压缩数据按照顺序组合即为解压缩之后的列数据。若在压缩过程中,将a行b列的数据流分割为n个切片,切片包括a/n行b列的数据流,将n个切片在n个压缩单元中分别进行压缩,得到n个压缩数据模块,本步骤在进行解压缩之前需要分别接受n个压缩数据模块,并将n个压缩数据模块在n个解压缩单元中分别进行解压缩,得到n个对应的解压缩数据模块。由于在上述完整的压缩数据流中各个压缩数据模块采用插入标记进行隔离,因此,在完整的压缩数据流中区分n个压缩数据模块还是很容易的。对于接受到的每一个压缩数据模块,需要分析依次接收到的压缩字和非压缩字的位数,若依次接收到的压缩字和非压缩字的位数等于a/n时,则接收到的压缩字和非压缩字为该压缩数据模块中的一列数据,其中,非压缩字的位数等于m-1bit,压缩字的位数等于该压缩字中压缩字符的个数cnt+1。对压缩数据模块中每一列的压缩数据进行解压缩的方法如上述所示。to2:重复步骤t01得到b列数据,并将各列数据组合为a行b列的数据流。当压缩数据流中包含n个压缩数据模块时,在接收每一个压缩数据模块时,已经对其进行列区分,将n个压缩数据模块解压缩之后的解压缩模块按照对应列进行无缝拼接,即可得到完整数据流中对应的列,从而组合为a行b列的数据流。以下通过具体实施例1对本发明进行进一步解释,实施例1中采用的向量数据流列向滑行压缩算法的命名为vscx-1613。实施例1本发明提供的一种测试向量的无损压缩方法,包括如下步骤:s01:将测试向量转换为a行b列的数据流,数据流采用二进制表示;其中每一列表示一个测试通道在不同时刻的测试数据;每一行表示不同测试通道在同一时刻的测试数据;a和b为大于1的整数。如附图1所示,将a行b列的数据流分割为n个切片,切片包括a/n行b列的数据流,a/n为大于m的正整数。以vscx-1613算法为例,通常将8000行做为一个切片,即a/n为8000。s02:将n个切片在n个压缩单元中分别进行压缩,得到n个压缩数据模块;每个压缩单元依次对每一个切片进行逐列压缩,形成每一列数据对应的压缩字和非压缩字。本发明中vscx-1613算法形成的压缩字和非压缩均为16bit的字,其每个位数上的含义分别为表1和表2所示:表1:vscx-1613算法中压缩字各个位数上含义表2:vscx-1613算法中非压缩字各个位数上含义bit名称说明15压缩标记=00:非压缩;1:压缩14:0原始数据15bit原始数据如附图2所示,具体对每一列数据进行压缩方法为:s021:设置宽度为1bit深度为16行的窗口,将窗口从该列数据的顶部开始逐行向下滑行,当窗口中添加15bit数据时,若15bit数据中既有0又有1,则不进行压缩,形成16bit的非压缩字,其中,非压缩字中第15bit表示压缩标记,第14至第0bit表示窗口中对应的15bit数据;若15bit数据中只有0或者1,则进行压缩,并且窗口继续逐行向下滑行,直至窗口中最新添加数据与窗口中其他行数据不同或者滑行至该列底部,形成16bit的压缩字,其中,压缩字中第15bit表示压缩标记,第14bit表示压缩字符,即0或者1;第13至第1bit表示15bit数据中压缩字符的个数cnt;第0bit表示窗口中最新添加数据的尾数。当窗口逐行向下滑行时,若窗口中最新添加数据与窗口中其他行数据相同,则压缩字符的个数cnt加1。如附图3所示,为窗口添加的15bit数据不同时,形成非压缩字0x0070的示意图。如附图4所示,为窗口添加的数据相同时时形成压缩字0xc640的示意图。s022:形成压缩字或者非压缩字之后,窗口滑行至该列数据中未处理的行位置,重复步骤s021,直至窗口滑行至该列数据的底部,得到该列数据的压缩数据;m为大于2小于a的正整数。本发明中每一列压缩数据中的压缩字和非压缩字是按照依次形成的顺序进行排列的。s03:如附图5所示,将每一个切片中各列的压缩数据按照列的顺序排列起来,形成压缩数据模块。如附图6所示,在进行压缩数据汇合的时候,将n个压缩数据模块按照切片的顺序进行排列,且相邻的切片对应的压缩数据模块通过插入标记隔开,例如0x8000(正常压缩字不会出现0x8000),从而得到完整的压缩数据流。本发明在上述压缩基础上提供的一种无损解压缩方法,包括如下步骤:如附图7所示,t01:分别接受n个压缩数据模块,并将n个压缩数据模块在n个解压缩单元中分别进行解压缩,得到n个对应的解压缩数据模块。由于在上述完整的压缩数据流中各个压缩数据模块采用插入标记进行隔离,因此,在完整的压缩数据流中区分n个压缩数据模块还是很容易的。对于接受到的每一个压缩数据模块,需要分析依次接收到的压缩字和非压缩字的位数,若依次接收到的压缩字和非压缩字的位数等于a/n时,则接收到的压缩字和非压缩字为该压缩数据模块中的一列数据,其中,非压缩字的位数等于m-1bit,压缩字的位数等于该压缩字中压缩字符的个数cnt+1。对压缩数据模块中每一列的压缩数据进行解压缩的方法如上述所示。对每一列的压缩数据按顺序进行解压缩,具体包括:对于非压缩字,去除第15bit之后,剩下的第14至第0bit数据即为解压缩数据;对于压缩字,将压缩字中的压缩字符扩展到cnt位,加上压缩字中第0bit的尾数,即为解压缩数据;将该列压缩数据按照顺序组合即为解压缩之后的列数据。to2:将n个压缩数据模块解压缩之后的解压缩模块按照对应列进行无缝拼接,即可得到完整数据流中对应的列,从而组合为a行b列的数据流。本实施例中理论最佳压缩率0.2%;(每列数据为全0或全1);理论最差压缩率106.7%;(每列均没有连续的13个以上的0或者1);实际使用中压缩率在2%附近。本发明提供的一种测试向量的无损压缩和解压缩方法,利用ate数据在列方向上具有高继承性的特点,采用数据流列向滑行压缩算法,能够实现无损压缩和解压缩,且压缩和解压缩过程简单快捷,可适用于ate测试领域。以上所述仅为本发明的优选实施例,所述实施例并非用于限制本发明的专利保护范围,因此凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明所附权利要求的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1