基于线性变换的F-LDPC码校验矩阵重量压缩方法
本发明属于智能通信,具体提供一种基于线性变换的f-ldpc码校验矩阵重量压缩方法,该方法用于降低f-ldpc码校验矩阵盲识别的复杂度。
背景技术:
1、f-ldpc码是一种串行级联校验系统码,其编码器由外部编码模块、交织器以及内部校验编码器三个模块级联构成,f-ldpc码具有极高的码率灵活度以及便于简单高速硬件译码器实现的优点,在民用通信系统和军用通信系统中都有着较好的应用前景,文献“thef-ldpc family: high-performance flexible modern codes for flexible radio”中详细阐述了f-ldpc码编码原理和校验矩阵生成机制。信道编码盲识别是第三方在非合作通信场景下获取通信双方所传信息的一种技术手段,在军事情报分析、智能通信等领域中有着广泛应用。对于截获传输信号的第三方,信号的编码参数等信息通常是未知的,需要通过对码字数据的分析识别出信道编码参数进而实现译码,完成从信号层到信息层的突破。
2、f-ldpc码的盲识别工作主要包括校验矩阵搜索(校验矩阵盲识别)和参数识别两部分,校验矩阵搜索是参数识别的基础,也是盲识别工作中的关键问题。目前,在大码长和较高误码率条件下,f-ldpc码校验矩阵搜索算法的搜索进程将严重受阻甚至完全停止;因此,有必要提出一种新的方法来优化f-ldpc码校验矩阵搜索进程以提高搜索效率,进而提高f-ldpc码盲识别的效率和抗误码性能。
技术实现思路
1、本发明的目的在于提供一种基于线性变换的f-ldpc码校验矩阵重量压缩方法,用以在大码长、较高误码率条件下优化f-ldpc码校验矩阵搜索进程以提高搜索效率,进而提高f-ldpc码盲识别的效率和抗误码性能。本发明提出基于线性变换的重量压缩方法,通过线性变换将f-ldpc码校验矩阵的汉明重量压缩至原先重量的1/2,并生成一组新的码字,新码字与重量压缩后的校验矩阵存在校验关系,在此基础上,结合校验矩阵搜索算法能够极大地降低搜索难度、提高搜索效率;同时,随着重量压缩方法的引入,f-ldpc码校验矩阵盲识别的抗误码能力也得到显著提升。
2、为实现上述目的,本发明采用的技术方案为:
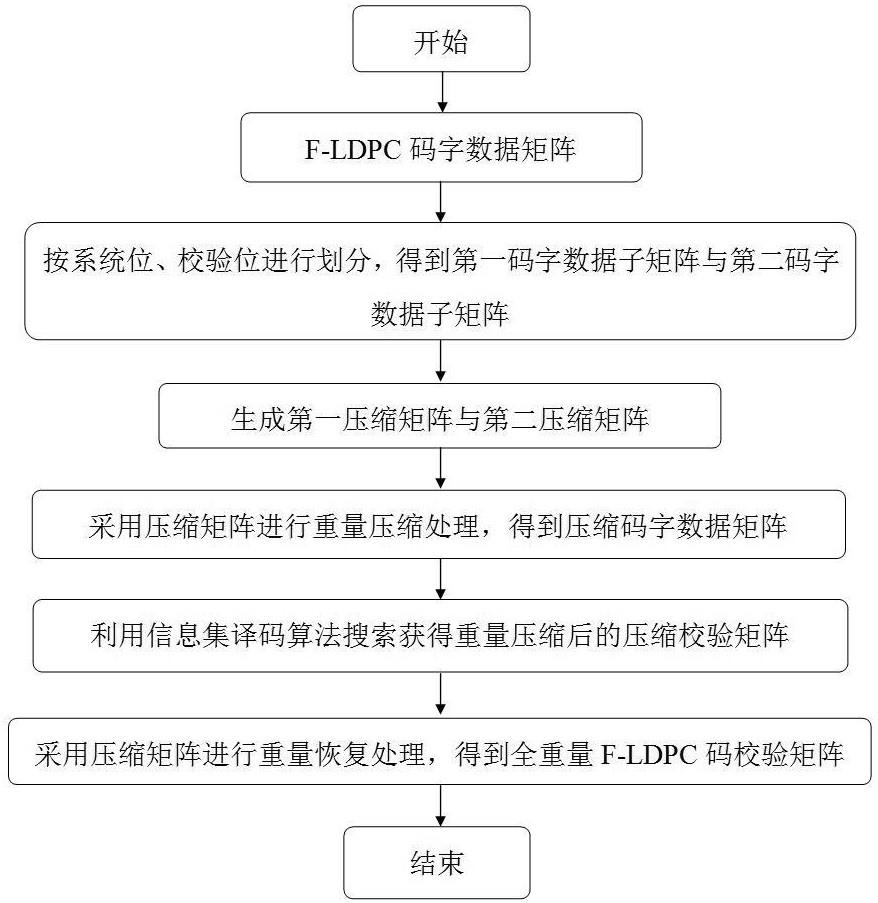
3、基于线性变换的f-ldpc码校验矩阵重量压缩方法,包括以下步骤:
4、步骤1. 重量压缩;
5、根据f-ldpc码的信息位长 k,将码字数据矩阵 c按系统位、校验位进行划分,得到第一码字数据子矩阵 b与第二码字数据子矩阵 p;
6、根据f-ldpc码的码长 n与信息位长 k生成第一压缩矩阵 g与第二压缩矩阵 ge;
7、采用第一压缩矩阵 g与第二压缩矩阵 ge分别对第一码字数据子矩阵 b与第二码字数据子矩阵 p进行重量压缩处理,得到第一压缩码字数据子矩阵 b new与第二压缩码字数据子矩阵 p new;
8、将第一压缩码字数据子矩阵 b new与第二压缩码字数据子矩阵 p new拼接得到压缩码字数据矩阵 c new;
9、步骤2. 校验矩阵搜索;
10、基于压缩码字数据矩阵 c new,利用信息集译码算法搜索获得重量压缩后的压缩校验矩阵 h new;
11、步骤3. 重量恢复;
12、根据f-ldpc码的信息位长 k,将压缩校验矩阵 h new进行划分,得到第一压缩子校验矩阵 d与第二压缩子校验矩阵 q;
13、采用第一压缩矩阵 g与第二压缩矩阵 ge分别对第一压缩子校验矩阵 d与第二压缩子校验矩阵 q进行重量恢复处理,得到第一全重量码字数据子矩阵 d t与第二全重量码字数据子矩阵 q t,
14、将第一全重量码字数据子矩阵 d t与第二全重量码字数据子矩阵 q t拼接得到全重量f-ldpc码校验矩阵 h。
15、进一步的,步骤1中,码字数据矩阵 c的划分过程为:
16、 c m× n=[ b m× k| p m×( n- k)],
17、其中, m× n表示码字数据矩阵 c的维度, m× k表示第一码字数据子矩阵 b的维度, m×( n- k)表示第二码字数据子矩阵 p的维度, m为码字数量。
18、进一步的,步骤1中,第一压缩矩阵 g与第二压缩矩阵 ge采用双对角结构方阵,具体为:
19、,,
20、其中, k× k表示第一压缩矩阵 g的维度,( n- k)×( n- k)表示第二压缩矩阵 ge的维度。
21、进一步的,步骤1中,重量压缩处理具体为: b new= bg t, p new= pge t, g t表示第一压缩矩阵 g的转置, ge t表示第二压缩矩阵 ge的转置。
22、进一步的,步骤1中,压缩码字数据矩阵 c new表示为: c new=[ b new| p new]。
23、进一步的,步骤2中,信息集译码算法具体采用dumer算法。
24、进一步的,步骤3中,压缩校验矩阵 h new划分过程为:
25、 h new=[ d( n- k)× k| q( n- k)×( n- k)],
26、其中,( n- k)× k表示第一压缩子校验矩阵 d的维度,( n- k)×( n- k)表示第二压缩子校验矩阵 q的维度。
27、进一步的,步骤3中,重量恢复处理具体为: d t= dg, q t= qge。
28、进一步的,步骤3中,全重量f-ldpc码校验矩阵 h表示为: h=[ d t| q t]。
29、基于上述技术方案,本发明的有益效果在于:
30、本发明基于f-ldpc码编码机制及其校验矩阵的结构特性,首先,通过可逆线性变换的方法在不损坏f-ldpc码校验矩阵结构的前提下将校验矩阵的汉明重量压缩为原先重量的1/2,同时,对f-ldpc码字做相应线性变换获得与重量压缩后校验矩阵满足校验关系的新码字;然后,利用基于信息集译码的dumer算法对新码字进行校验关系恢复,获得重量压缩的校验矩阵 h new;最后,通过线性变换将校验矩阵 h new还原为全重量的f-ldpc码校验矩阵 h。本发明提出的校验矩阵重量压缩方法将f-ldpc码的全重量校验矩阵 h的盲识别(搜索)问题转化为重量减半的校验矩阵 h new的盲识别问题,极大降低了f-ldpc码校验矩阵盲识别的复杂度。
31、综上所述,本发明提供了一种基于线性变换的f-ldpc码校验矩阵重量压缩方法,该方法能够显著降低f-ldpc码校验矩阵搜索的复杂度,同等条件下对搜索时间成本的优化程度在90%以上;同时,该方法大幅提高了f-ldpc码校验矩阵搜索的抗误码能力,对于码长较大的f-ldpc码,能够在10-3量级误比特率条件下实现校验矩阵的完整识别;对于码长较小的f-ldpc码,能够在10-2量级误码率条件下实现校验矩阵的完整识别。
- 还没有人留言评论。精彩留言会获得点赞!