基于相机选择的音频处理的制作方法
示例性和非限制性实施例一般涉及音频信号,更具体地涉及音频信号的处理。
背景技术:
具有多个麦克风的设备是已知的。具有多个相机的设备是已知的。处理音频信号以产生经修改的音频信号是已知的。
技术实现要素:
以下发明内容仅仅旨在是示例性的。该发明内容不旨在限制权利要求的范围。
按照一个方面,一种示例方法,包括:从装置的麦克风生成相应的音频信号;确定装置的多个相机中的哪些相机已经被选择以供使用;以及基于所确定的被选择以供使用的相机,为相应的音频信号中要被处理的至少一个相应的音频信号选择音频处理模式,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整至少一个相应的音频信号。
按照另一示例实施例,提供了一种装置,其包括至少一个处理器;以及至少一个非暂态存储器,其包括计算机程序代码,至少一个存储器和计算机程序代码被配置成与至少一个处理器一起使得装置:确定装置的多个相机中的哪些相机已经被选择以供使用;基于所确定的被选择以供使用的相机,为来自装置的麦克风的要被处理的相应的音频信号选择音频处理模式,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整至少一个相应的音频信号。
按照另一示例实施例,提供了一种由机器可读取的非暂态程序存储设备,其有形地体现由机器可执行的用于执行操作的指令程序,该操作包括:确定装置的多个相机中的哪些相机已经被选择以供使用;基于所确定的被选择以供使用的相机,为来自装置的麦克风的要被处理的相应的音频信号选择音频处理模式,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整至少一个相应的音频信号。
附图说明
在以下结合附图进行的描述中对前述各方面以及其他特征进行阐明,其中:
图1是示例实施例的正视图;
图2是图1所示的实施例的后视图;
图3是图示了图1至图2所示的实施例的部件中的一些部件的示意图;
图4是图示了来自图1至图3所示的实施例的麦克风的音频信号的处理的图;
图5是图示了示例方法的图;
图6是图示了来自图1至图3所示的实施例的麦克风的音频信号的处理的图;
图7是图示了来自图1至图3所示的实施例的麦克风的音频信号的处理的图;
图8是图示了来自图1至图3所示的实施例的麦克风的音频信号的处理的图;
图9是图示了相对于图1至图2所示的装置的区域的图,其中可以修改音频源方向;
图10是图示了用于修改音频源方向的示例图形的图。
图11是图示了在图1至图2所示的装置的一侧上使空间图像静止的图;
图12是图示了来自图1至图3所示的实施例的麦克风的音频信号的处理的图;
图13是图示了来自图1至图3所示的实施例的麦克风的音频信号的处理的图;
图14是图示了来自图1至图3所示的实施例的麦克风以及另一麦克风的音频信号的处理的图;
图15是图示了来自麦克风的音频信号的处理的图;
图16是图示了相对于图1至图2所示的装置的音频捕获和回放方向以及视频捕获方向的示例使用的图;以及
图17是图示了相对于图1至图2所示的装置的音频捕获和回放方向以及视频捕获方向的示例使用的另一图。
具体实施方式
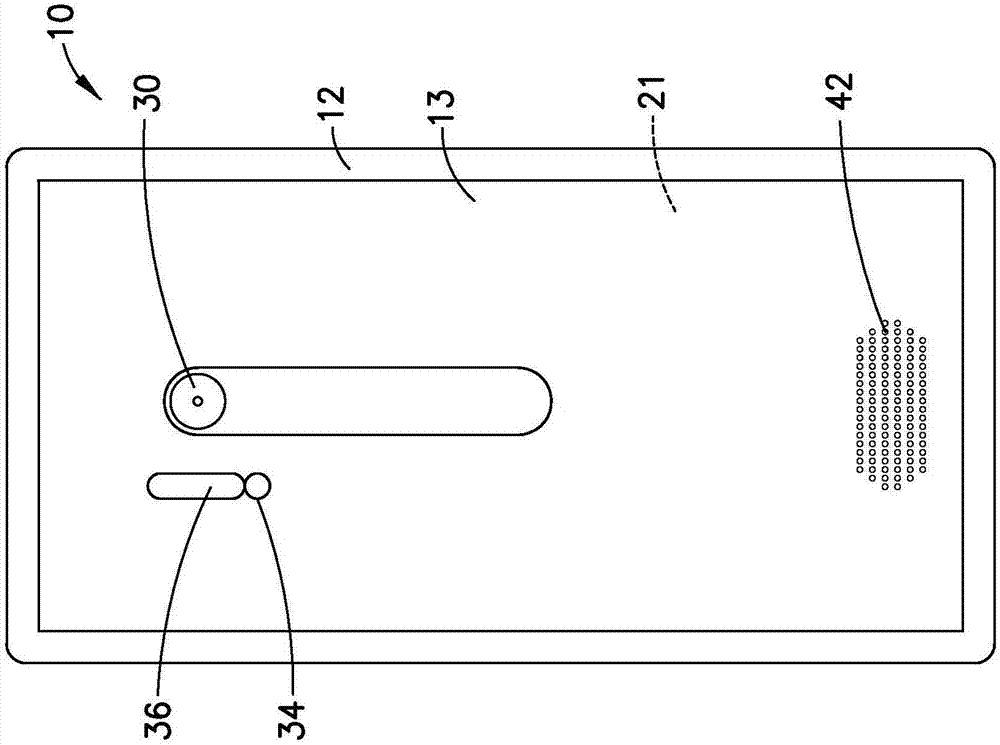
参考图1,示出了结合示例实施例的特征的装置10的正视图。尽管将参照附图中示出的示例实施例对特征进行描述,但是应当理解,可以以许多备选形式的实施例来体现特征。另外,可以使用任何合适的尺寸、形状或类型的元件或材料。
装置10可以是手持便携式装置,诸如包括例如电话应用的通信设备。在所示的示例中,装置10是包括相机和相机应用的智能手机。装置10可以附加地或可替代地包括因特网浏览器应用、视频记录器应用、音乐播放器和记录器应用、电子邮件应用、导航应用、游戏应用和/或任何其他合适的电子设备应用。在备选示例实施例中,该装置可能不是智能电话。
还参考图2至图3,在该示例实施例中,装置10包括壳体12、触摸屏14、接收器16、发送器18、控制器20、可充电电池26和至少两个相机30、32。然而,这些特征对于实现下文所描述的特征是不必要的。控制器20可以包括至少一个处理器22、至少一个存储器24和软件28。壳体12内部的电子电路可以包括至少一个印刷电路板(pwb)21,其具有诸如控制器20之类的部件。接收器16和发送器18形成主通信系统,以允许装置10与无线电话系统(诸如例如移动电话基站)进行通信。
在该示例中,装置10包括位于装置的后侧13的相机30、位于装置的相对前侧的前置相机32、led34和闪光灯系统36。led34和闪光灯系统36在装置的后侧是可见的,并且被提供用于相机30。相机30、32、led34和闪光灯系统36连接至控制器20,使得控制器20可以控制其操作。在备选示例实施例中,后侧可以包括多于一个的相机,和/或前侧可以包括多于一个的相机。
装置10包括作为耳机40而被提供的声音换能器、以及作为扬声器42而被提供的声音换能器。可以提供多于一个或少于一个的扬声器。装置10包括作为麦克风38、39而被提供的声音换能器。在备选示例中,该装置可以包括多于两个的麦克风。麦克风38、39位于壳体12的相应的左侧和右侧,以允许其音频信号表示左声道和右声道。然而,除了只有左声道和右声道之外,可以提供附加的或备选的声道。在该示例中,麦克风38、39位于壳体12的底部,但是它们可以位于壳体上的任何合适位置。
还参考图4,将对包括特征的一种类型的示例进行描述。装置10的电子电路被配置成从两个或更多个麦克风38、39接收信号,并且产生作为左输出声道和右输出声道的音频信号44'、45'。装置10的电子电路形成多模式音频处理器70用于该目的。音频处理器70可以使用不同的模式来处理信号44、45并且产生不同种类的信号44'、45'。多模式音频处理器70使用的模式可以至少部分地基于哪个相机30、32正在被使用来确定或选择。
语音和环境声音通常通过其在视频呼叫或视频记录中的不同角色而具有不同的相对重要性。如何最佳地表示和渲染或捕获这些音频信号可能取决于视频观点。在一类示例中,本文中所描述的特征可以用于基于所使用的相机视图来提供默认音频表示和渲染模式。通过利用多麦克风空间捕获,可以获得语音和环境音频信号之间的改进的分离。因此,可以以更好的质量和更自然的方式来渲染音频,其与正在使用的相机视图更好地相对应并且适应于该相机视图。该渲染可以进一步实现讲话者是场景的一部分的模式,或者讲话者与总体场景分离并且用作叙述者的新颖的视频呼叫模式。
由麦克风拾取(诸如例如,在例如视频呼叫期间)的声音可以被分成音频语音信号和音频环境信号。应当理解,这些信号类型被认为是在视频电话和视频记录的范围内。因此,本文中所描述的特征不限于视频电话。
当进行视频呼叫(或视频记录)时,可以利用设备(或作为记录系统的一部分)上的多于一个的相机。具体地,对于图1至图3所示的示例,前置相机32通常捕获用户的脸部,并且主相机30可以用于捕获用户前面的内容。
一个方面是通过利用空间多麦克风捕获来在该框架中更好地分离语音信号和环境信号,并且因此允许集中于在每个“使用”情况下被认为更重要的声音。例如,当使用前置相机32时,从相机的直视图发出的信号可以被视为被保存的主信号,而其他信号(环境)的增益可以被降低。因为预期当用户选择示出他/她的脸(如通过使用相机32的选择所指示的)时,语音信号是最重要的信号,所以这可以做到。另一方面,当使用主相机30时,可以预期所有声源(包括现在最可能在设备10后方的讲话者)是感兴趣的。
使用本文中所描述的特征,在视频呼叫中利用前置相机32或主相机30可以用于基于正在被使用的相机来触发优选的捕获模式。利用特定相机可以附加地触发捕获模式的默认设置。在一种示例实施例中,捕获模式的默认设置然后还可以由用户调整。
返回参考图4,音频处理器70被配置成基于所使用的相机来控制输出信号中的环境信号的水平。这还可能是基于话音活动检测(vad)或面部检测。因此,本文中所描述的特征可以用于当用户使用或切换到主相机30时,自动允许改进语音信号编码的保真度(当使用前置相机32时)以及适应不同的编码语音和环境信号,诸如例如,在相同的水平下。
还参考图5,一种示例方法,可以包括:如框60所指示的,从装置的麦克风生成音频信号;如框62所指示的,确定装置的多个相机的哪些相机已经被选择以供使用;以及如框64所指示的,基于所确定的被选择以供使用的相机,为要被处理的音频信号选择音频处理模式,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整音频信号。在麦克风的电性输出信号被处理的情况下,生成音频信号是指音频捕获/记录。
如上文所指出的,可以利用面部跟踪方法来进一步增强捕获对现实情景的适应性。例如,面部检测信息可以由图4所示的信号58提供。在一个示例中,当在前置相机32的视图中找不到讲话者的面部时,设备前面(但不在视图中)的声源的环境增益可能不会降低。事实上,这样的声源可能是讲话者。可以通过使用如上文所指出的话音活动检测(vad)或类似技术来附加地或可替代地检测语音信号的存在。
还参考图6,将对另一示例实施例进行描述,其可以用于讲话者(主语音信号)和环境信号的更具体的分离。这种方法的用例可以被描述为整个场景中的“抬出讲话者”,并且用他/她作为叙述者。在这种情况下,当在前置相机32和设备主相机30之间进行切换时,讲话者的方位遵循视频镜头的方位。实际上,当讲话者被认为是环境的一部分时,这是被认为是自然而优选的渲染方式,并且听众想体验身临其境的场景。然而,我们也习惯于将其自身适用于视频电话的另一种类型的渲染。典型示例可能是电视新闻演示(或诸如自然文件之类的程序),其涉及显示人讲话的头部(讲话的头部)和其他视频镜头,其中讲话者只呈现为叙述者,而非完整场景的元素。这种情景对于视频电话本身很自然,并且单声道音频渲染(其当前是视频呼叫中的典型音频技术)还可以被认为遵循这一原则:当视频镜头中的视图改变时,讲话者的位置或多或少保持固定。
相机中的一个相机通常主要用于捕获扬声器(前置相机32),并且其他相机用于捕获风景(后置相机30)。因此,来自扬声器的话音被链接至前置相机32,并且环境声音被链接到后置相机30。因此,如果当使用前置相机时,扬声器的话音的空间图像可能与视频相对应,并且当使用后置相机时,环境的空间图像可能与视频相对应,那么这是好事。
在该示例实施例中,空间多麦克风捕获用于分离设备的每一侧上的信号。至少,与前置相机侧和设备主相机侧有关的声音和声源被分离。进一步地,主语音信号与前置相机侧环境信号相分离。可以利用音频和视频处理方法,诸如vad、噪声抑制、人脸跟踪、波束成形、音频对象分离等。
左麦克风38和右麦克风39被放置在设备上以分别正确地捕获一个相机的音频,即,相机的左侧和右侧上。在一种示例中,产生聚焦于(多个)扬声器上的单声道信号。在备选示例中,产生聚焦于(多个)扬声器上的立体声信号。在该示例中,来自麦克风的信号44、45用于通过电路50来产生单声道信号(或立体声信号)48。这可以包括例如使用在国际申请号pct/ib2013/052690(国际公开号wo2014/162171a1)中描述的装置和方法,其全部内容通过引用并入本文,其产生聚焦于如由相机捕获的讲话者的单声道信号。然而,可以提供用于将语音与环境声音分离的任何合适系统。
由电路52延迟的音频信号44、45然后被电路54衰减。控制器20被配置成确定在产生信号44、45期间哪个相机30或32正在被使用,并且向电路54发送相机指示信号56。电路54被配置成提供用于信号44、45的两个或更多个音频处理模式。音频处理模式的选择至少部分地基于相机指示信号56。因此,电路54被配置成基于哪个相机30、32正在被使用来变化信号44、45的衰减。然后,输出信号44'、45'与(多个)单声道信号48组合以产生输出信号46、47。
离开电路54的环境信号的电平根据所使用的相机而变化,并且环境信号与所聚焦的语音信号混合。当使用面向(多个)扬声器的相机(通常为前置相机32)时,语音信号空间图像保持恒定,语音空间图像与视频(由前置相机32拍摄的)一致,并且环境信号空间图像可能被衰减。当使用背对扬声器的相机(通常为后置相机30)时,环境信号空间图像保持恒定,环境空间图像与视频一致,并且语音信号空间图像保持恒定(或可以比上述模式中的环境信号衰减更少)。
在一些另外的示例实施例中,当视图在至少两个相机视图之间切换时,可以进行信号的立体声声道或方向反转。例如,可以进行这样的反转(参见图16和图17),诸如通过缩小声道之间的间隔(一直到单声道信号),然后将该间隔扩展回到全立体声(其中左声道和右声道现在被反转)。
还参考图7,还可以将实现方式范围扩展到两个以上的声道。例如,无论所使用的相机如何,都可以使用聚焦于他/她的话音的多麦克风技术来捕获扬声器的声音,并且可以使用产生5.1声音的多麦克风技术来捕获环境。该5.1捕获可以对准固定至相机中的其中一个相机(通常是移动设备背面的主相机30)的方向。通常,当扬声器想要示出风景或用户前面的视图等等时,使用该相机30。然后,可以以取决于所使用的相机的方式以及当扬声器的头部在相机30或32中可见时将两个信号(环境和声音)混合在一起。通常,当扬声器在相机30或32中可见时,环境信号被衰减。
在一些实施例中,视频镜头可以利用画中画(pip)渲染。在这种情况下,语音和环境音频的分离以及为讲话者维持静态方位通常提供愉快的渲染。因此,pip用例的工作模式可能与上文所讨论的“叙述者”模式相同。在一些另外的实施例中,音频模式可以适应画中画视频的改变。特别地,当主相机提供主画面并且辅助(pip)画面来自前置相机时,该用例类似于使用仅具有主相机视图的“叙述者”模式。另一方面,当主画面和pip被反转时,默认操作可以至少轻微地衰减空间环境声音。在另外的实施例中,当画中画视频被示出时,语音信号的立体声或多声道渲染可以被下混频到单声道。当pip视频来自前置相机时,尤其如此。
在各种示例实施例中,设备取向(纵向、横向)可以导致对于左信号和右信号相对应的麦克风的选择。由此可见,根据设备方位,不同的麦克风集合或麦克风配对与左和右相对应。
还参考图8至图9,还可以修改音频信号,使得音频源方向(空间图像)和视频总是一致。只要在相机30、32可以看到的区域之间存在间隙72、74以及当音频源方向移动到这些间隙时,就可以这样工作;方向可以被改变。当然,当源在相机中可见时,还可以改变音频源方向,但这会导致空间图像和视频之间的不一致性。在典型情景下,环境音频源的方向将被修改;扬声器通常移动较少,并且仅保留在一个相机的视图中。
如本文中所描述的特征可以使用诸如在美国专利公开号us2013/0044884a1中描述的移动设备中仅使用3个麦克风来捕获5.1信号,其全部内容通过引用并入本文。还可以将不同的摇摄功能用于不同的输出。在该实施例中(参考图8),使用立体声音频。因为当相机被切换(从前置相机到主相机,或反之亦然)时,音频对象的回放方向可能需要从后向前切换,所以该实施例(参考图8)将不适用于5.1音频。由3个麦克风捕获的信号首先被转换成中间信号和侧信号以及侧信息α。alphaαb描述了每个频带b的主要声音方向。为了产生音频信号,在即使当用户在前置相机和后置相机之间切换时声音图像保持静止的情况下,还可以以下列方式修改α(为了简单起见,省略了带索引b):
这导致落在图9中的区域72、74中的音频源方向被修改。
直接向左和向右的对象可以从左和右两者回放;因此它们被赋予方向
这之后,去相关的侧信号被添加到左声道和右声道,其被传输并且被回放。
利用上文所描述的示例,直接向设备的左侧或右侧的音频对象需要从左侧和右侧两者回放;否则,当相机切换时,那些音频对象的回放方向将切换位置。这不是个大问题,因为那些对象在任一相机中都不可见。还参考图1,可替代地,当相机被切换时,可以聚焦于使空间音频图像在相机的一侧(前面或后面)上静止,同时让另外三个侧上的音频对象的回放方向从左向右切换,反之亦然。这可以通过将音频对象回放位置压缩到相机一侧上的一个点,同时在另一侧上保持位置“原样”来实现。
在实践中,这通常是这样做的,使得在前置相机侧上,在前置相机中可见的所有音频对象将总是从中心回放其音频。通常,仅在前置相机侧上存在人,因此将他的话音的方向压缩至中心是自然的。然后将从与后置相机上看到的方向相对应的方向回放设备的另一侧上的音频对象。这可以通过使用图10所图示的函数而修改α来代替公式1来完成;同时保持其他处理如同图8一样。图10是描绘了α的修改的曲线。
还参考图12,备选示例是在相机之间或相机之中切换相机使用时,缓慢转动听觉空间图像。例如,用户首先使用第一相机来拍摄视频,并且音频空间图像与第一相机一致。然后,用户切换到第二相机。在切换之后,音频空间图像被(缓慢地)转动,直到它变得与第二相机一致为止。
上文所描述的示例已经聚焦于具有两个相机的设备上。然而,如本文中所描述的特征可以容易地扩展到具有两个以上的相机的装置。相机不需要处于单个平面中。如这里呈现的相同原理可以用于不在单个平面上的相机。这里的备选实施例不限于移动电话。可以使用具有两个或更多个相机的任何设备。可以添加用于音频对象分离的器件、或用于分离语音和环境对象的定向麦克风。例如,类似于上文关于图6所描述的实施例,可以以以下关于图13和图14的两种方式来实现特征。图13示出了使用音频对象分离。如框76所指示的,音频被分成来自前置相机和后置相机的对象;如框78所指示的,根据哪个相机正在被使用来衰减来自后置相机30的一侧的对象,并且可以组合80用于输出音频82的信号。图14示出了使用定向麦克风。如框84所指示的,可以基于哪个相机正在被使用来衰减来自指向后置相机的左侧和右侧的麦克风的信号44、45,并且指向与前置相机32相同的方向的来自麦克风的信号85可以与从84输出的信号进行组合86、87以生成输出左声道46和输出右声道47。
音频对象分离还可以用于实现类似于上文关于图8至图11所描述的实施例的实施例。一种方法可以用于将多麦克风信号转换为音频对象及其轨迹。轨迹是每个对象的时间相依方向。该方向通常指示为相对于设备的角度(或者在完整3d轨迹的情况下,为两个角度,方位角和仰角)。然后可以使用公式1或图10来修改每个对象的角度。参见图15,其是该实现方式的示例框图。来自麦克风的信号可以被分成如框88所指示的对象及其时间相依方向,诸如例如,使用如在国际专利公开号wo2014/147442a1中所描述的特征,其全部内容通过引用并入本文。如框90所指示的,可以修改从88输出的信号中的一些信号的方向。如框92所指示的,合成可以用于通过将对象摇摄到修改后的方向来产生多声道信号,诸如例如,r.sadek,c.kyriakakis在美国加利福尼亚州旧金山于2004年10月28日至31日的aes第117界会议上的“anovelmultichannelpanningmethodforstandardandarbitraryloudspeakerconfigurations”中所描述的。
如本文中所描述的特征可以用于基于相机选择来自动适应编码模式以提高质量并且聚焦于相关信号。可以提供用于视频电话的新用例,其中讲话者/扬声器/用户作为叙述者而非整个场景的一部分。如本文中所描述的特征可以用于视频电话、空间音频捕获、音频处理、编码和渲染。
在常规电影中,当相机角度或视点改变时,仅屏幕上可见的音频源的位置改变。当相机视点改变时,屏幕上不可见的音频源不会改变它们的方向。如本文中所描述的特征可以改变在屏幕/显示器上不可见的音频源的方向/位置。在常规电影制作中,许多不同的方法用于保持音频源的位置恒定,并且当相机视点被改变时,仍然与视频匹配。然而,这些方法纯粹是手动的,并且在后期处理期间分开进行。
传统上,低比特率语音编码集中于将可理解语音信号从讲话者传递到听众。该目标的一个实际含义是除活动语音之外的所有信号都被认为是可以被抑制或去除的噪声。然而,在高质量的服务中,这个想法是越来越经常把大多数其他信号认为想要为听众复制的环境信息(尽管维持语音信号的可理解性的想法确实与低比特率应用相关)。因此,最高优先级是语音,但环境信号也是感兴趣的。事实上,在一些情况下,它们的重要性可能至少暂时会超过语音信号的重要性。
当使用具有多于一个的相机的移动设备来记录视频(并且可能在视频呼叫中传输)时,用户可以在记录期间改变相机。常规上讲,这改变相机的视点,但是它不改变麦克风的位置。因此,对于常规设备,在音频源位置和视点中的至少一个视点中的视频之间存在差异。第一简单解决方案可能保持音频源位置(即,音频空间图像)固定在一个相机上,但是这可能意味着空间图像对于所有其他相机可能是错误的。第二简单解决方案可能为每个相机不同地重新指派所使用的麦克风,但是每当所使用的相机被改变时,这可能导致音频信号的烦人改变。如本文中所描述的特征提出了几种改善情形的方法。
还参考图16,示出了帮助可视化如本文中所描述的特征中的一些特征的图。如上文所指出的,在视频呼叫或视频记录期间的音频声音可以被分成语音信号和环境信号。当进行视频呼叫或记录时,经常利用设备10上的多于一个的相机(或作为记录系统的一部分)。前置相机32可以捕获用户100的脸部,并且主相机30可以例如在(移动)呼叫期间用于捕获用户在使用设备的同时看到的大部分内容。图16以概念和简化水平图示了来自讲话者100的讲话者/扬声器信号和环境信号如何可以由图1所示的两个麦克风38、39捕获,然后在这样的系统(其中优于单声道记录和渲染并且假设耳机聆听)中被渲染(回放)给用户100'(其可以是诸如在视频呼叫期间或许使用不同的设备10'的同一个人100或不同的人)。更简单的系统根本不会适应相机视图的改变。
如从图16中可以看出,讲话者100总是被认为是整个场景/环境的一部分,而不管如图区域102所指示的正在使用前置相机还是如图区域104所指示的使用设备主相机。因此,对于由麦克风捕获的所有声音(讲话者和环境),左是左,右是右,只有在讲话者和环境信号回放期间的位置似乎相对于听众100'而改变(以自然方式)。
一方面是通过利用空间多麦克风捕获来实现在该框架中更好地分离语音信号和环境信号,并且因此允许集中于在每个用例中被认为是更重要的声音。因此,当如102所指示的使用前置相机时,从相机的直视图发出的信号可以被视为所保留的主信号,同时可以降低其他信号(环境)的增益。这可以做到,因为预期当用户选择示出他/她的脸时,语音信号是最重要的信号。另一方面,当如104所指示的主相机用于示出整个场景时,所有声源(包括现在最可能在设备背后的讲话者)可以被期望是感兴趣的。
例如,在pct公开号wo2013/093187a2中描述的技术可以用于实现上述分离,其通过引用整体并入本文。然而,如本文中所描述的,在视频呼叫中利用前置相机或主相机可以用于触发来自多个模式的优选音频捕获模式。在更一般的术语中,利用具体相机可以触发捕获模式的默认设置,其可以随后可选地由用户进行调整。另外,面部跟踪方法可以用于进一步增强捕获对现实世界情景的适应性。特别地,当在前置相机的视图中找不到讲话者的脸部时,设备前面(而非视图中)的声源的环境增益可能不会降低。这样的声源实际上可能是讲话者。还可以例如通过使用话音活动检测(vad)或类似技术来检测语音信号的存在。
因此,实施例可以自动地允许改进语音信号编码(当使用前置相机时)的保真度,并且适应相同水平下的编码语音和环境信号(当用户切换到主相机时)。
如上文关于权利要求6所指出的,一种实施例允许讲话者(主语音信号)和环境信号的更具体的分离。如图16所看到的,当在由如102所图示的前置相机和如104所图示的设备主相机之间进行切换时,讲话者的方位遵循视频镜头的方位。实际上,当谈话者被认为是环境的一部分并且听众想体验如身临其境的场景时,这可以被认为是自然和优选的渲染方式。
在该实施例中,空间多麦克风捕获可以用于分离设备的每一侧上的信号。至少,声音和与前置相机侧和设备主相机侧有关的声音源可以分开。进一步地,主语音信号可以与前置相机侧环境信号分离。
示例实施例可以将语音信号的左声道和右声道(或任何数目个声道)相对于设备维持静态,而不管有源相机的切换。另一方面,环境信号可能如由相机视图的切换触发来切换。当利用前置相机时,讲话者因此被维持,并且环境可以被抑制(至少稍微)。当视图切换到主相机时,讲话者可以维持在先前方位,但环境信号遵循新的相机视图,并且抑制变为零(或其他默认值)。图17图示了高水平下的捕获和渲染。
在一些实施例中,当设备捕获多声道音频时,语音信号可以是单声道的(例如,所讲出的单词由单声道耳机或麦克风来捕获)。在这些实施例中,可以使用相同的分离原理和环境信号的抑制。语音信号可以被感知为单声源(使用预先定义的摇摄),或者当来自其他麦克风信号的可听见的提示被用于提供语音信号的定向多声道渲染时,语音信号变成定向。在各种实施例中,设备方位(纵向、横向)可以导致与例如左和右信号相对应的麦克风的选择。由此可见,根据设备方位,不同的麦克风集合或麦克风配对与左和右相对应。
一种示例方法,可以包括:从装置的麦克风生成相应的音频信号;确定装置的多个相机中的哪些相机已经被选择以供使用;以及基于所确定的被选择以供使用的相机,为要被处理的音频信号选择音频处理模式,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整音频信号。
该方法还可以包括:从音频信号产生单独的语音信号。该方法可以包括:基于所确定的被选择以供使用的相机来衰减音频信号,然后将单独的语音信号与衰减的音频信号进行组合。在比承载衰减的音频信号的所有声道更少的声道上,单独的语音信号可以与衰减的音频信号进行组合。仅在一个承载衰减的音频信号的声道上,单独的语音信号可以与衰减的音频信号进行组合。该方法可以包括:基于所确定的被选择以供使用的相机来衰减音频信号,并且在单独的声道上提供单独的语音信号,而非衰减的音频信号。从音频信号产生单独的语音信号可以包括:使用面部检测。该方法可以包括:当被选择以供使用的相机包括第一相机时,将来自麦克风中的第一麦克风的音频信号指派为左声道信号、并且将来自麦克风中的第二麦克风的音频信号指派为右声道信号;以及当被选择以供使用的相机包括第二相机时,将来自第一麦克风的音频信号指派为右声道信号、并且将来自第二麦克风的音频信号指派为左声道信号。该方法还可以包括:从音频信号产生单独的语音信号,并且当第一相机或第二相机被选择时,保持与单独的语音信号相对应的空间方向基本上不变。
当被选择以供使用的相机从第一相机切换到第二相机时,在第一麦克风和第二麦克风之间缓慢转动由第一麦克风和第二麦克风接收的声音的听觉图像。该方法可以包括:当被选择以供使用的相机包括第一相机时,为要被处理的音频信号选择音频处理模式中的第一音频处理模式;以及当被选择以供使用的相机包括第二相机时,为要被处理的音频信号选择音频处理模式中的不同的第二音频处理模式,其中第一相机和第二相机面对不同的方向,并且还包括:从用于第一模式的音频信号产生单独的语音信号,而不从用于第二模式的音频信号产生单独的语音信号。
可以在一种装置中提供实施例,该装置包括至少一个处理器;以及至少一个非暂态存储器,其包括计算机程序代码,至少一个存储器和计算机程序代码被配置成与至少一个处理器一起使得装置:确定装置的多个相机中的哪些相机已经被选择以供使用;以及基于所确定的被选择以供使用的相机,为来自装置的麦克风的要被处理的音频信号选择音频处理模式,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整音频信号。
至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:从音频信号产生单独的语音信号。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:基于所确定的被选择以供使用的相机来衰减音频信号,然后将单独的语音信号与衰减的音频信号进行组合。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:在比承载衰减的音频信号的所有声道更少的声道上,将单独的语音信号与衰减的音频信号进行组合。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:仅在一个承载衰减的音频信号的声道上,将单独的语音信号与衰减的音频信号进行组合。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:基于所确定的被选择以供使用的相机来衰减音频信号,并且在单独的声道上提供单独的语音信号,而非衰减的音频信号。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:使用面部检测从音频信号中产生单独的语音信号。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:当被选择以供使用的相机包括第一相机时,将来自麦克风中的第一麦克风的音频信号指派为左声道信号、并且将来自麦克风中的第二麦克风的音频信号指派为右声道信号;以及当被选择以供使用的相机包括第二相机时,将来自第一麦克风的音频信号指派为右声道信号、并且将来自第二麦克风的音频信号指派为左声道信号。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:从音频信号产生单独的语音信号,并且当第一相机或第二相机被选择时,维持与单独的语音信号相对应的方向信息基本上不变。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:在选择以供使用的相机从第一相机切换到第二相机时,在左声道和右声道之间缓慢转动由第一麦克风和第二麦克风接收的声音的听觉图像。至少一个存储器和计算机程序代码可以被配置成与至少一个处理器一起使得装置:当被选择以供使用的相机包括第一相机时,为要被处理的音频信号选择音频处理模式中的第一音频处理模式;以及当被选择以供使用的相机包括第二相机时,为要被处理的音频信号选择音频处理模式中的不同的第二音频处理模式,其中第一相机和第二相机面向不同的方向,并且还包括:从用于第一模式的音频信号产生单独的语音信号,而不从用于第二模式的音频信号产生单独的语音声音信号。
可以在可由机器读取的非暂态程序存储设备中提供示例实施例,诸如例如,图3中的存储器24,其有形地体现可由机器执行的用于执行操作的指令程序,这些操作包括:确定装置的多个相机中的哪些相机已经被选择以供使用;以及基于所确定的被选择以供使用的相机,为来自装置的麦克风的要被处理的音频信号选择音频处理模式,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整音频信号。
一个或多个计算机可读介质的任何组合可以用作存储器。计算机可读介质可以是计算机可读信号介质或非暂态计算机可读存储介质。非暂态计算机可读存储介质不包括传播信号,并且可以是例如但不限于电子、磁性、光学、电磁、红外或半导体系统、装置或设备、或前述的任何合适组合。计算机可读存储介质的更具体的示例(非详尽列表)将包括以下各项:具有一条或多条电线的电连接、便携式计算机软盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或闪存)、光纤、便携式光盘只读存储器(cd-rom)、光存储设备、磁存储设备、或前述的任何合适组合。
一种示例实施例,可以包括:用于从装置的麦克风生成音频信号的器件;用于确定装置的多个相机中的哪些相机已经被选择以供使用的器件;以及用于基于所确定的被选择以供使用的相机,为要被处理的音频信号选择音频处理模式的器件,其中音频处理模式基于所确定的被选择以供使用的相机来至少部分地自动调整音频信号。
应当理解,先前描述仅仅是说明性的。本领域技术人员可以设计出各种备选方案和修改。例如,各种从属权利要求中记载的特征可以以任何合适的组合彼此组合。另外,来自上文所描述的不同实施例的特征可以被选择性地组合成新的实施例。因而,该描述旨在涵盖落在所附权利要求的范围内的所有这样的备选方案、修改和变型。
- 还没有人留言评论。精彩留言会获得点赞!