增量双中继系统中基于误符号率的功率优化分配的方法与流程
本发明涉及到通信技术领域,特别是涉及到协作通信的技术领域。在此邻域中,本发明提出了增量双中继系统中以误符号率最小为目标的发射功率在源节点和两个中继节点之间的优化分配的方法。
背景技术:
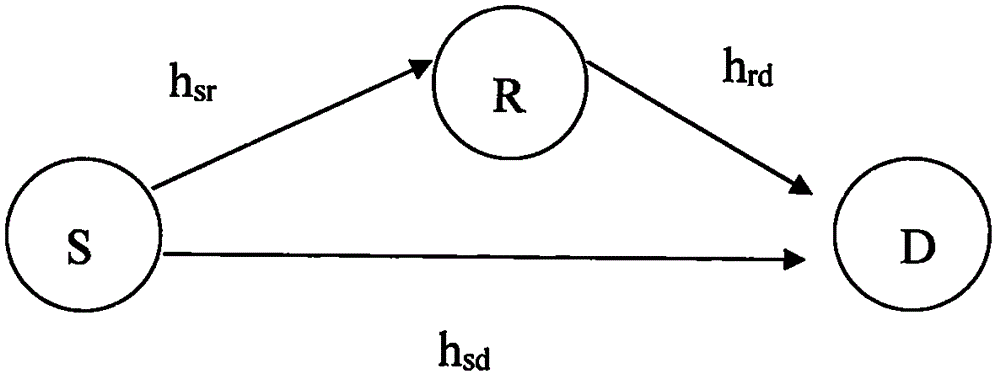
在传统的协作通信中,其系统模型如附图1所示。此时,有一个源节点,一个目的节点,和一个中继节点参与到协同通信中来。在第一个时隙中,源节点发射信息给目的节点和中继节点。在第二个时隙中,中继节点发射信息给目的节点,目的节点根据其第一个时隙和第二个时隙收到的信号进行最大比合并,产生解码信号。根据中继节点的转发信息方式的不同,其协作可分为译码转发(DF)协议和放大转发协议(AF)和编码协作。
其中,在译码转发协议下,中继节点先解码信息再重新编码信息传输;在放大转发协议下,中继节点仅仅放大所接收到的信号。在编码协作下,中继节点产生纠错能力更强的编码发送给目的节点。
但是,这样的中继协议和系统存在如下问题:1.当源节点到中继节点的信道质量差时,中继节点的误符号率很高。这样的信号传输给目的节点时,往往起不到有益的作用,反而会提高目的节点的误符号率,而不是降低目的节点的误符号率。2.当源节点到目的节点的信道质量较好时,往往不需要中继节点的协作,就已经能产生符合误符号率要求的目的节点收到的信号。这种情况下,依然采用协作方式,会降低系统传输信息的速率。
为此,本发明提出并分析了增量双中继系统的误符号率性能。给出了这个系统和协议下的误符号率的容易计算的近似表达式,并通过此表达式来优化系统的性能。利用了所提出的进化方法,来优化地分配源节点的发射功率和两个中继节点的发射功率,以使在总功率一定的情况下,尽量降低系统的误符号率,更大地提高所提出系统的性能。在所提出的降低误符号率的进化方法中,首先把两个自变量转化为二进制数,在二进制下先固定一个变量,进化另外一个变量,然后根据进化的结果缩小这个变量的取值范围。然后,当两个变量的每一个允许的取值区间足够小时,采取联合进化的方式,对两个变量进行二进制下的交叉、变异、和淘汰,以优化地寻找最优解。最后,利用最优解来分配系统的总功率。
技术实现要素:
为了克服上述现有技术的不足,本发明提供了一种协同通信的协议,并分析了此协议下的系统的误符号率。为了进一步地提高此协议的性能,本发明推导出了此误符号率近似的计算量很小的表达式。基于此表达式,本发明提供了一种优化分配系统发射功率的方法,并使用进化的方法来淘汰搜索区间和进行种群进化,并避免陷入局部最小。所得到的方法可以优化地并高精度地分配系统的功率,即,在系统总功率一定的情况下,通过协议中的功率分配来尽量减少系统的误符号率。
本发明所采用的技术方案是:1.提供协同通信的新协议,在此协议下,只在系统目的节点的解码端发生解码错误时才启用中继节点,以加快信息的传输速率。同时,在解码端需要协作时,一次使用两个中继节点来保证传输的可靠性。(传统的增量中继系统只有一个中继节点)2.提供了此协议下误符号率的精确的表达式,并对此表达式进行了近似,以利于误符号率的计算。3.提供了此协议下的功率分配的方法,以在系统总功率一定的情况下,通过功率分配来减少系统的误符号率。4.利用二进制下的进化方法来提高求解问题的精度和性能。
与现有技术相比,本发明的有益效果是:1.在各种信道模型下,实验结果已说明所提出的协议的性能优于已有的协同通信的协议。2.实验结果同时说明新协议下通过基于误符号率的功率分配方法,可进一步地在很大的程度上继续提高系统的性能。
本发明所提出的系统模型如附图2所示,增量双中继系统由一个源节点S,两个中继节点R1,R2和一个目的节点D组成(传统的增量中继系统只有一个中继节点,选择两个中继节点是为了在可靠性和传输速率之间进行很好的平衡,选择的中继节点太多会大大降低系统的传输速率,而只选择一个中继节点在误符号率上会增加)。源节点到目的节点,源节点到中继节点R1,源节点到中继节点R2,中继节点R1到目的节点D,中继节点R2到目的节点D的信道增益分别为hsd、hsr1、hsr2、hrd1、hrd2,它们均服从均值为零,方差分别为的瑞利分布。假设每一个节点配置一根天线,并且每个节点处的噪声均为加性高斯白噪声,且均服从均值为零,方差为N0的高斯分布。在此系统下,只有从源节点到目的节点的传输出错时,目的节点才同时请求两个中继节点进行协作。因为这里有两个中继节点,且当真正需要他们进行协作时才启用它们,本发明命名这个系统为增量双中继系统。
对所提出的增量双中继系统下的通信协议具体描述如下:在第一个系统时隙内,源节点发射信号给目的节点,同时,中继节点R1,R2也可以接收到源节点发射的信号,然后分两种情况:1)在情况1下,目的节点D判断在第一个系统时隙内接收到的信号译码正确(此时收到的码字通过了信道编码的验证),目的节点D把译码结果直接输出,同时目的节点D通过发送比特“1”来通知两个中继节点R1和R2此时不需要进行协作传输,这样,源节点S在下一个系统时隙可以继续发送信号以提高传输速率。2)在情况2下,目的节点D接收到的信号在译码中发生错误(纠错码的验证发生错误),目的节点D通过发送比特“0”来通知两个中继节点R1和R2此时都需要进行协作传输以提高系统的传输的可靠性,两个中继节点R1和R2通过接收到目的节点发送的比特“0”就得知此时需要参与协作,在系统的第二个时隙,中继节点R1在这个时隙采用DF(译码转发)的方式将自己译码并再编码后的信号转发给目的节点D,在第三时隙,另一个中继节点R2在这个时隙采用同样的译码转发的方式将自己译码并再编码后的信号转发给目的节点D,此情况下,目的节点将三个时隙中接收到的信号采用最大比合并的方法进行解码后再输出。同时,和传统的增量中继系统不同,传统的增量中继系统以目的节点的信噪比判断是否让中继节点协作,而这里采用纠错码进行校验来决定是否需要让两个中继节点都协作,所提出的方法在操作上更简便。
进一步地,第一时隙,对源节点的广播信息,目的节点和中继节点R1,R2接收到的信号ysd,ysr1和ysr2分别为
其中,P1为源节点S的发射功率,x为发射的信号,nsd、nsr1、nsr2分别为目的节点、和中继节点R1、中继节点R2处的加性高斯白噪声。如果第一时隙目的节点收到的信号质量不够好(信噪比较小),那么在第二和第三时隙,中继节点R1,R2分别将接收到的信号译码后采用与源节点相同的编码方式编码,再转发给目的节点。目的节点在第二,第三时隙接收到的信号yrd1,yrd2为:
其中,P2,P3分别为中继节点R1,R2的发射功率,x′为两个中继节点转发的信号,nrd1和nrd2为目的节点处的加性高斯白噪声。
以下将分析此增量双中继系统的误符号率(SER)的性能。首先给出了一个信号经过n条独立路径衰减后再通过最大比合并方式合并后目的节点处的平均SER表达式,然后运用此表达式,推导了此增量双中继系统平均SER的精确表达式。
对采用M-PSK调制方式发射信号时,单接收节点的SER可精确地表示为
其中,r为单节点处的瞬时信噪比,r=P|h|2/N0,h为瑞利分布的信道增益系数且其方差为δ2,P为发射节点的发射功率,b=sin2(π/M),M为调制系数。瞬时信噪比r为服从指数分布的随机变量,根据指数函数的矩生成函数(Moment Generating Function,MGF),此时单接收节点的平均SER可表示为
当目的节点采用最大比合并方式合并n条经过独立的信道衰弱而到达的信号时,其输出信噪比为n路独立信道的信噪比之和,定义各节点的发射功率均为P,则其瞬时SER可表示为
其中,r1、r2、...、rn分别为n条独立信道上的信噪比,h1、h2、...、hn分别为n条独立路径的信道衰落系数,他们服从均值为零,方差分别为δ12、δ22、...、δn2的瑞利分布。因为各信道之间相互独立,根据指数函数的MGF,采用最大比合并方式合并n路经过独立衰减的的信号后,其输出的平均SER为
在增量双中继系统中,目的节点处的解码错误的情况可以归为以下四种:
(1)协议的第一个时隙中的直传链路下目的节点发生解码错误,且两个中继节点R1,R2都发生解码错误。
(2)直传链路中目的节点发生解码错误,中继节点R1解码正确,而中继节点R2解码错误,目的节点采用最大比合并(MRC)方式合并源节点和中继节点R1发射的信号后,输出时发生解码错误。
(3)直传链路中目的节点发生解码错误,中继节点R1发生解码错误,中继节点R2解码正确,目的节点采用MRC方式合并源节点和中继节点R2发射的信号后,输出时发生解码错误。
(4)直传链路中目的节点发生解码错误,中继节点都解码正确,目的节点采用MRC方式合并源节点和中继节点发射的信号后,输出时发生解码错误。
所以,采用M-PSK调制时,系统平均误符号率可以表示为
其中,分别为对应于情况(1)、(2)、(3)、(4)下所提出协议中目的节点处的平均误符号率。由于,源节点到目的节点,源节点到中继节点R1,源节点到中继节点R2,中继节点R1到目的节点D,中继节点R2到目的节点D的信道增益分别为hsd、hsr1、hsr2、hrd1、hrd2,它们均服从均值为零,方差分别为的瑞利分布,进一步地,可以推导出
将式(11)~(14)代入式(10),即可得到系统平均SER的精确值。
以上给出了增量双中继系统的误符号率表达式,由于其表达式很复杂,为了在源节点,以及两个中继节点之间优化地进行功率分配,必须对其表达式进行简化。本发明在高信噪比下对式(10)进行了近似。即
当P1/N0→∞时,
同理
则式(11)可以写为如下形式
同理,式(12)、(13)、(14)可以分别化简为
其中b=sin2(π/M),将式(15)、(16)、(17)、(18)相加即为增量双中继系统在高信噪比下的近似误符号率,即
附图3为增量双中继系统在高信噪比下误符号率近似值与精确值的对比图,由图3可知,当系统的总功率高于15db时,其近似曲线与精确值曲线几乎重合,因此在高信噪比情况下可以用近似值替代精确值进行功率分配。而在协作通信系统中,其一般是工作在高信噪比下的,因此所提出系统的误符号率的计算可以利用所得到的近似表达式的计算来完成。
这样,就可以把所提出的系统下的基于误符号率的优化的功率分配方法转化为如下带约束条件的优化问题:即,在条件(1)P=P1+P2+P3,(2)P1≥0 (3)P2≥0 (4)P3≥0下最小化函数φtotal(P1,P2,P3)=φtotal(e)。把条件(1)带入式(19),可把以上问题转化为只含有两个自变量的优化问题,即,在约束条件:(1)P≥P1≥0,(2)0≤P2≤P-P1下最小化函数
这里,由于有两个自变量需要优化,首先用给定的系统的总功率P对这两个自变量进行归一化,原问题可以转化为:在条件(1)和条件(2)下最小化函数
为此,本发明提出了一种最小化以上函数的方法。由于自变量β1、β2都在0和1之间,它们可用D个比特的二进制的定点小数来表示。本发明采用以下两个策略来优化地确定自变量的优化的取值:(1)对一个自变量的保留的取值范围进行等区间分割,并在每个区间内随机取S个值,(2)通过二进制下的随机的进化的方法来确定在这个自变量不变的情况下,另一个自变量的优化的取值,使目标函数减少。接着,仅保留使目标函数小的那些区间,淘汰掉其他区间。(3)对变量β1和β2分别反复轮替地执行以上步骤(1)和(2),直到它们的每个保留的区间足够小。(4)对合理的两个自变量都保留下来的联合取值区间,通过联合进化的方法使目标函数减少。对所有这样的联合区间遍历处理后,仅保留使目标函数最小的联合区间,以及这个区间上进化的最优的解。
所提出的功率分配的优化的方法可以描述为:
1.把第一个自变量可能的取值区间分割为N个大小相等的子区间对每个子区间It,随机均匀分布地产生这个区间内的S个值st,i。对每个st,i,寻找和其优化匹配的第二个自变量的值pn,使φtotal(st,i,pn)变小。
1.1)在这里,先把pn二进制化,即用二进制的数来表示pn。对于二进制数(0.pn1,pn2,...,pnk,...,pnD)2,D为其最低的二进制的小数位,有(0.pn1,pn2,...,pnk,...,pnD)2=pn1*2-1+pn2*2-2+...+pnk*2-k+...+pnD*2-D。然后,用随机的方法产生第一代的关于(0.pn1,pn2,...,pnk,...,pnD)2的初始种群n表示种群中的第m个个体,0表示第0代,在其可能的取值区间内均匀地随机取值,M为种群规模。这样,就产生了g=0代的种群。
1.2)然后,利用为适应度函数,从第g代中选择使小的M/2个的个体,淘汰M/2个使大的M/2个的个体。这所选择的M/2个个体构成了下一代的初始群体可选群体设置为这个初始的g+1代的群体。
1.3)接着,第k(1≤k≤M/4)次地随机地从可选群体中选择两个父代个体,第m1个个体和第m2个个体随机地从1到D的整数中,确定交叉位置c(m1,m2)=cm,cm为从1到D均匀分布的随机整数。产生下一代中的两个交叉后的子个体
和
完成交叉操作。设置变异概率为pm,以上个体和中的每个二进制位以pm的概率由原来的1变为0,或者由原来的0变为1。变异完成的两个子代个体分别记为和并把它们放入第g+1代群体中。并把第m1个个体和第m2个个体从可选群体中删除。重复这一步骤,直到可选群体为空(即已进行了M/4次的选择操作)。
1.4)重复执行以上第1.2步和第1.3步,直到产生了g=gmax代数的种群为止。计算第gmax代种群中使值最小的个体从每个子区间所产生的所有st,i中选择NS个使最小的st,i,并求这些st,i上所对应的的均值,这个均值记为
然后,保留值小的N/Nr个子区间,淘汰掉其余的子区间,这样就缩小了后续操作中第一个变量β1的取值范围。
2.把第二个自变量可能的取值区间分割为N个大小相等的子区间对每个子区间Ju,随机均匀地产生这个区间内的R个值对每个寻找和其优化匹配的第一个自变量中未淘汰的区间内的的值si,使变小。
2.1)在这里,把si二进制化,即用二进制的数来表示si。对于二进制数(0.si1,si2,...,sik,...,siD)2,D为其最低的二进制的小数位,有(0.si1,si2,...,sik,...,siD)2=si1*2-1+si2*2-2+...+sik*2-k+...+siD*2-D。同时,si的取值应在其保留的区间范围内。然后,用随机的方法产生第一代的关于(0.si1,si2,...,snk,...,snD)2的初始种群m表示种群中的第m个个体,0表示第0代,在其可能的取值区间内均匀地随机取值,M为种群规模。同时在其初始群体中,每个大小相等的保留区间应包含同样多的个体。这样,就产生了g=0代的种群。
2.2)然后,利用为适应度函数,从第g代中选择使小的M/2个的个体,淘汰M/2个使大的M/2个的个体。这所选择的M/2个个体构成了下一代的初始群体可选群体设置为这个初始的g+1代的群体。
2.3)接着,第k(1≤k≤M/4)次地随机地从可选群体中选择两个父代个体,第m1个个体和第m2个个体随机地从1到D的整数中,确定交叉位置c(m1,m2)=cm,cm为从1到D均匀分布的随机整数。产生下一代中的两个交叉后的子个体
和
完成交叉操作。设置变异概率为pm,以上个体和中的每个二进制位以pm的概率由原来的1变为0,或者由原来的0变为1。变异完成的两个子代个体分别记为和并把它们放入第g+1代群体中。并把第m1个个体和第m2个个体从可选群体中删除。重复这一步骤,直到可选群体为空(即已进行了M/4次的选择操作)。
2.4)重复执行以上第2.2步和第2.3步,直到产生了g=gmax代数的种群为止。计算第gmax代种群中使值最小的个体从每个子区间所产生的所有中选择NS个使最小的并求这些上所对应的的均值,这个均值记为
然后,保留值小的N/Nr个子区间,淘汰掉其余的子区间,这样就缩小了后续操作中第二个变量β2的取值范围。
对第一个自变量的保留的取值区间,每一个区间划分为更小的Nr个区间,然后利用以上第1步,继续缩小第一个自变量的保留的取值区间的大小。然后,对第二个自变量的保留的取值区间,每一个区间划分为更小的Nr个区间,淘汰使第一个自变量和第二个自变量相加大于1的子区间,然后利用以上第2步,继续缩小第二个自变量的保留的取值区间的大小。反复执行此步骤,直到两个自变量的每个保留的子区间的大小都小于ls为止。
3.对每个由两个自变量保留的区间所组成的联合区间,进行种群的联合进化,找到优化的解。
对由两个自变量保留的区间所组成的联合区间产生进化的种群,其中区间为对第一个变量采用以上的方法优化后得到的估计其优化值所在的区间,t*为这些区间的索引号,为对第二个变量采用以上的方法优化后得到的估计其优化值所在的区间,u*为这些区间的索引号。
3.1)产生初始的群体{(si(g),pi(g))|1≤i≤Ng},其中g=0,i表示种群中的第i个个体,Ng为种群的规模,同时且为在区间内均匀分布的随机数,且为在区间内均匀分布的随机数。
3.2)利用适应度函数φtotal(si(g),pi(g))淘汰掉φtotal(si(g),pi(g))值大的Ng/2个个体,仅保留适应度函数小的Ng/2个个体。剩下的个体组成联合区间下的第g+1代的可选种群,设置g=g+1。
3.3)接着,第k(1≤k≤M/4)次地随机地从可选群体中选择两个父代个体,第m1个个体和第m2个个体随机地从1到D的整数中,确定交叉位置c(m1,m2)=cm,cm为从1到D间均匀分布的随机整数。然后产生下一代中的交叉后的子个体和
其中
完成交叉操作。设置变异概率为pm,以上二进制数和中的每个二进制位以pm的概率由原来的1变为0,或者由原来的0变为1。变异完成的两个子代个体分别记的子个体和并把它们放入第g+1代群体中。并把第m1个个体和第m2个个体从可选群体中删除。重复这一步骤,直到可选群体为空(即已进行了M/4次的选择操作)。设置g=g+1。
3.4)重复执行以上第4.2步和第4.3步,直到产生了g=gmax代数的种群为止。
使步骤4.1-4.4遍历所有的由两个自变量保留的区间所组成的联合区间,找到所有这些区间的gmax代的个体所组成的大的种群中使值最小的个体
4.最优的功率分配方案为源节点使用的发射功率,中继节点1采用的发射功率,中继节点2采用的发射功率。其中,P为给定的发射总功率。
这样,通过以上的操作,可以有效地避免寻找优化的功率分配的方式时,陷入局部最小的问题。并提高问题求解的精度,并对系统做有效的优化。
在说明书附图4中,显示了所提出的协同通信的方案的优越性。图中给出了所提出的系统和协议在等功率分配下的误符号率曲线,此图和图5-6中的SNR的定义是SNR=10*log10(P/N0),其中P是系统发射的总功率,N0是加性高斯白噪声的功率谱密度。SER是系统的误符号率,在使用Golay映射的调制方式时,它的值近似为系统的误比特率BER(bit error rate)。此图中的另一个曲线是现在性能最好的协同通信的系统和协议在做过功率分配优化后的性能。可以看出,虽然所提出的系统和协议还没有进行功率分配的优化,其性能已经优于现有的协同通信中最好的方法了。在相同的15dB的SNR下,所提出的系统与协议已经把误符号率降低为原来的以下了。且可以看出,随着信噪比SNR的增大,所提出的系统与协议能在更大的程度上降低误符号率。
图5和图6显示了采用所提出的功率优化的方法能够带来的系统的增益。图5为在的信道条件下所提出的最优功率分配方法与等功率分配方法的误符号率曲线对比图,由图5可以看出,在该种信道条件下,利用所提出的最优功率分配系统的误符号率性能相对与等功率分配有显著的提高。而且,随着系统总功率的增加,所提出的最优功率分配方法的性能优势相对于等功率分配越来越明显。当系统总功率大于20db时,在相同的误符号率要求下,最优功率分配比等功率分配大约可以节省3db以上的系统总功率。
图6为在信道下得最优功率分配与等功率分配的误符号率曲线对比图,由图6可以看出,在该种信道条件下,最优功率分配的误符号率性能优势相对等功率分配很明显,与图5情况信道下的趋势相同,随着系统总功率的增加,最优功率分配的性能优势越来越明显。当系统总功率大于20db时,在相同的误符号率要求下,最优功率分配比等功率分配大约可以节省5db以上的系统总功率。
附图说明
1.图1为传统的协同通信系统的示意图;
2.图2为本发明所提出的增量双中继系统的模型的示意图;
3.图3为增量双中继系统误符号率的近似值与精确值的对比图;
4.图4为本发明所提出的系统和协议(系统与协议1)与目前最好的协同通信协议(系统与协议2)的误符号率对比图;
5.图5为等功率分配与本发明所提出的最优功率分配方法的误符号率的比较图;
6.图6为等功率分配与与本发明所提出的最优功率分配方法的误符号率的比较图。
具体实施方式
下面结合附图对本发明做进一步的说明。附图2为所提出的系统和协议的示意图,在所提出的协议中,只有当源节点到目的节点的译码发生错误时,两个中继节点才同时参与协作,转发信号;否则源节点继续发送信号。因此,图中从中继节点到目的节点的线条为虚线。对所提出的增量双中继系统下的通信协议具体描述如下:第一个时隙,源节点发射信号给目的节点,同时,R1,R2也可以接收到源节点发射的信号,目的节点根据接收到的信号质量判断是否需要中继节点的协作。如果目的节点接收到的信号译码正确,那么不需要请求中继节点参与协作。如果目的节点接收到的信号在译码中发生错误(纠错码的验证发生错误),那么两个中继节点就需要同时参与协作。此时,目的节点通过发送一个比特的信号来通知两个中继节点是否要进行协作传输。即,如果第一时隙中,目的节点接收到的信号正确,那么在第二时隙,源节点再发下一个新的信号;如果目的节点接收到的信号不正确,那么在第二时隙和第三时隙,中继节点R1,和R2分别采用DF(译码转发)协议将信号转发给目的节点,最后目的节点将三个时隙中接收到的信号采用最大比合并的方法进行解码后再输出。
此协议下的误符号率的近似解可表示为:
其中,源节点到目的节点,源节点到中继节点R1,源节点到中继节点R2,中继节点R1到目的节点D,中继节点R2到目的节点D的信道增益分别为hsd、hsr1、hsr2、hrd1、hrd2,它们均服从均值为零,方差分别为的瑞利分布,N0为加性高斯白噪声的功率谱的大小,P1为发射节点的发送功率,P2为第一个中继节点的发送功率,P3为第二个中继节点的发送功率,b=sin2(π/M),M为信号调制系数。
由此,此协议下的功率分配的优化问题可转化为如下问题:在条件(1)和条件(2)下最小化函数
其中P为系统给定的总的发射功率,β1P为源节点的发射功率,β2P为中继节点R1的发射功率,(1-β1-β2)P为中继节点R2的发射功率。
通过大量的实验,确定了所提出的功率优化方法中的优化的参数的取值如下:第一次对第一个变量的取值区间划分为N=20个子区间,对自变量取D=32位的小数来表示,对每个子区间产生S=50个随机点。在种群进化中,种群规模M=400,变异概率pm=0.05。NS=3,即在子区间淘汰时,每个子区间取3个最小值进行平均来代表子区间的最小值。Nr=4,即每次保留N/Nr=5个子区间供下一次继续划分。进化时的进化的最多代数为gmax=50。第一次对第二个变量的取值区间划分为R=20个子区间。对两个变量的每个保留的子区间的大小都小于ls=0.025时,停止对保留的子区间的进一步的缩小。两个变量联合进化时的种群规模Ng=200。
功率分配的优化的步骤如下所述:
1.把第一个自变量可能的取值区间分割为N个大小相等的子区间对每个子区间It,随机均匀分布地产生这个区间内的S个值st,i。对每个st,i,寻找和其优化匹配的第二个自变量的值pn,使φtotal(st,i,pn)变小。
1.1)在这里,先把pn二进制化,即用二进制的数来表示pn。对于二进制数(0.pn1,pn2,...,pnk,...,pnD)2,D为其最低的二进制的小数位,有(0.pn1,pn2,...,pnk,...,pnD)2=pn1*2-1+pn2*2-2+...+pnk*2-k+...+pnD*2-D。然后,用随机的方法产生第一代的关于(0.pn1,pn2,...,pnk,...,pnD)2的初始种群m表示种群中的第m个个体,0表示第0代,在其可能的取值区间内均匀地随机取值,M为种群规模。这样,就产生了g=0代的种群。
1.2)然后,利用为适应度函数,从第g代中选择使小的M/2个的个体,淘汰M/2个使大的M/2个的个体。这所选择的M/2个个体构成了下一代的初始群体可选群体设置为这个初始的g+1代的群体。
1.3)接着,第k(1≤k≤M/4)次地随机地从可选群体中选择两个父代个体,第m1个个体和第m2个个体随机地从1到D的整数中,确定交叉位置c(m1,m2)=cm,cm为从1到D均匀分布的随机整数。产生下一代中的两个交叉后的子个体
和
完成交叉操作。设置变异概率为pm,以上个体和中的每个二进制位以pm的概率由原来的1变为0,或者由原来的0变为1。变异完成的两个子代个体分别记为和并把它们放入第g+1代群体中。并把第m1个个体和第m2个个体从可选群体中删除。重复这一步骤,直到可选群体为空(即已进行了M/4次的选择操作)。
1.4)重复执行以上第1.2步和第1.3步,直到产生了g=gmax代数的种群为止。计算第gmax代种群中使值最小的个体从每个子区间所产生的所有st,i中选择NS个使最小的st,i,并求这些st,i上所对应的的均值,这个均值记为
然后,保留值小的N/Nr个子区间,淘汰掉其余的子区间,这样就缩小了后续操作中第一个变量β1的取值范围。
2.把第二个自变量可能的取值区间分割为N个大小相等的子区间对每个子区间Ju,随机均匀地产生这个区间内的R个值对每个寻找和其优化匹配的第一个自变量中未淘汰的区间内的的值si,使变小。
2.1)在这里,把si二进制化,即用二进制的数来表示si。对于二进制数(0.si1,si2,...,sik,...,siD)2,D为其最低的二进制的小数位,有(0.si1,si2,...,sik,...,siD)2=si1*2-1+si2*2-2+...+sik*2-k+...+siD*2-D。同时,si的取值应在其保留的区间范围内。然后,用随机的方法产生第一代的关于(0.si1,si2,...,snk,...,snD)2的初始种群m表示种群中的第m个个体,0表示第0代,在其可能的取值区间内均匀地随机取值,M为种群规模。同时在其初始群体中,每个大小相等的保留区间应包含同样多的个体。这样,就产生了g=0代的种群。
2.2)然后,利用为适应度函数,从第g代中选择使小的M/2个的个体,淘汰M/2个使大的M/2个的个体。这所选择的M/2个个体构成了下一代的初始群体可选群体设置为这个初始的g+1代的群体。
2.3)接着,第k(1≤k≤M/4)次地随机地从可选群体中选择两个父代个体,第m1个个体和第m2个个体随机地从1到D的整数中,确定交叉位置c(m1,m2)=cm,cm为从1到D均匀分布的随机整数。产生下一代中的两个交叉后的子个体
和
完成交叉操作。设置变异概率为pm,以上个体和中的每个二进制位以pm的概率由原来的1变为0,或者由原来的0变为1。变异完成的两个子代个体分别记为和并把它们放入第g+1代群体中。并把第m1个个体和第m2个个体从可选群体中删除。重复这一步骤,直到可选群体为空(即已进行了M/4次的选择操作)。
2.4)重复执行以上第2.2步和第2.3步,直到产生了g=gmax代数的种群为止。计算第gmax代种群中使值最小的个体从每个子区间所产生的所有中选择NS个使最小的并求这些上所对应的的均值,这个均值记为
然后,保留值小的N/Nr个子区间,淘汰掉其余的子区间,这样就缩小了后续操作中第二个变量β2的取值范围。
3.对第一个自变量的保留的取值区间,每一个区间划分为更小的Nr个区间,然后利用以上第1步,继续缩小第一个自变量的保留的取值区间的大小。然后,对第二个自变量的保留的取值区间,每一个区间划分为更小的Nr个区间,淘汰使第一个自变量和第二个自变量相加大于1的子区间,然后利用以上第2步,继续缩小第二个自变量的保留的取值区间的大小。反复执行此步骤,直到两个自变量的每个保留的子区间的大小都小于ls为止。
4.对每个由两个自变量保留的区间所组成的联合区间,进行种群的联合进化,找到优化的解。
对由两个自变量保留的区间所组成的联合区间产生进化的种群,其中区间为对第一个变量采用以上的方法优化后得到的估计其优化值所在的区间,t*为这些区间的索引号,为对第二个变量采用以上的方法优化后得到的估计其优化值所在的区间,u*为这些区间的索引号。
4.1)产生初始的群体{(si(g),pi(g))|1≤i≤Ng},其中g=0,i表示种群中的第i个个体,Ng为种群的规模,同时且为在区间内均匀分布的随机数,且为在区间内均匀分布的随机数。
4.2)利用适应度函数φtotal(si(g),pi(g))淘汰掉φtotal(si(g),pi(g))值大的Ng/2个个体,仅保留适应度函数小的Ng/2个个体。剩下的个体组成联合区间It×Ju下的第g+1代的可选种群,设置g=g+1。
4.3)接着,第k(1≤k≤M/4)次地随机地从可选群体中选择两个父代个体,第m1个个体和第m2个个体随机地从1到D的整数中,确定交叉位置c(m1,m2)=cm,cm为从1到D间均匀分布的随机整数。然后产生下一代中的交叉后的子个体和
其中
完成交叉操作。设置变异概率为pm,以上二进制数和中的每个二进制位以pm的概率由原来的1变为0,或者由原来的0变为1。变异完成的两个子代个体分别记的子个体和并把它们放入第g+1代群体中。并把第m1个个体和第m2个个体从可选群体中删除。重复这一步骤,直到可选群体为空(即已进行了M/4次的选择操作)。设置g=g+1。
4.4)重复执行以上第4.2步和第4.3步,直到产生了g=gmax代数的种群为止。
使步骤4.1-4.4遍历所有的由两个自变量保留的区间所组成的联合区间,找到所有这些区间的gmax代的个体所组成的大的种群中使值最小的个体
5.最优的功率分配方案为源节点使用的发射功率,中继节点1采用的发射功率,中继节点2采用的发射功率。其中,P为给定的发射总功率。
- 还没有人留言评论。精彩留言会获得点赞!