一种大规模MIMO下基于深度学习的码本选择方法与流程
本发明属于无线通信技术领域,涉及一种大规模MIMO(Multiple-Input Multiple-Output,多输入多输出)下基于深度学习的码本选择方法。
背景技术:
任何一个通信系统,信道是必不可少的组成部分。无线信道为典型的“变参信道”,无线信道的特性与传播环境,如:地形、地物、气候特征、电磁干扰情况、通信体移动速度及使用的频段等密切相关。无线通信系统的通信能力、服务质量(Quality of Service,QoS)等都与无线信道性能的好坏密切相关。因此,要想在有限的频谱资源上尽可能高质量、大容量传输有用的信息,必须很好地掌握无线信道的特性,尤其在大数据时代,同时还要尽可能保证获取的无线信道的差错率较小。
无线信道模型是对无线传播环境及传播特性有了充分了解后,对无线信道的一个抽象描述,能很好地反映无线传播环境的一些重要性质。无线信道模型的建立主要依赖于信道探测。目前,现有的建立无线信道传播模型的方法有:统计性模型、确定性模型和半确定性模型。
但上述现有建立无线信道传播模型的方法存在一些缺点,如这些方法是依据电磁波传播理论,在一些简化条件下分析得出无线信道模型的建立方法。而实际移动传播环境是千变万化的,很大程度的限制了这些理论结果的应用范围,只能针对某个特定环境、单一链路进行,对高速移动场景下的信道特性、方向性信道特性描述的不够全面准确。另一方面,现有的信道模型的建立方法需要充分挖掘收发端的因果关系。其通过采集收发端的信号,分析接发信号建立收发两端的因果关系。因采集的样本有限,且基于假设条件,使得到的结果会受影响。在小数据时代,计算机能力不足,大部分分析仅限于寻求简单的线性关系。
大规模MIMO系统中,因天线数目庞大使得信道阵H维数迅速变大,基于非码本的预编码技术不再适用,而基于码本的线性预编码技术成了关注的焦点。目前常用的产生码本的方法有:基于Grassmannian subspace packing、DFT等。但前者在一般用穷尽搜索找寻最优码字,如随机搜索,交替预测,劳埃德迭代算法,这些算法的计算负担将随着发射天线数的增多急剧增大。而DFT在预编码矢量之间用系统的方式提供了高弦距离,但平均误码率却极易在发射天线遭受高空间相关性时收到影响。针对以上问题,提出一种低计算量、抗空间相关性的预编码方法已成为迫切需求。
技术实现要素:
有鉴于此,本发明的目的在于提供一种大规模MIMO(Multiple-Input Multiple-Output,多输入多输出)下基于深度学习的码本选择方法,该方法能够有效地建立无线信道传播模型及码本查询。
为达到上述目的,本发明提供如下技术方案:
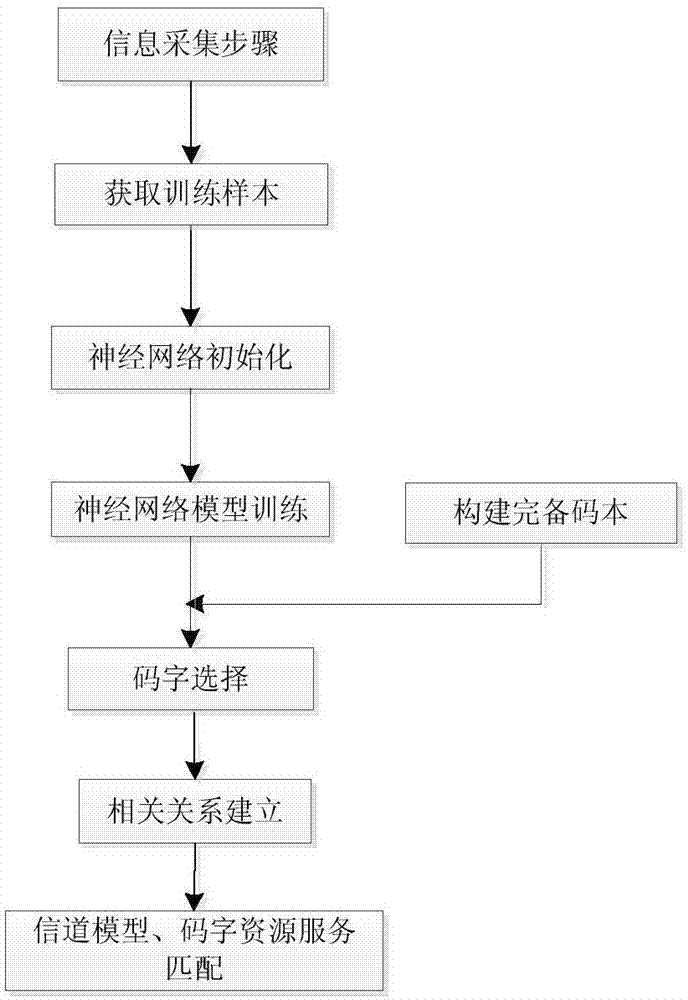
一种大规模MIMO下基于深度学习的码本选择方法,该方法包括以下步骤:
S1:信息采集步骤:由信息采集系统采集测试区内用户端的导频信息;
S2:获取训练样本:根据导频信息构建导频训练序列,进而得到导频训练样本;
S3:初始化神经网络:初始化神经网络模型参数;
S4:神经网络学习:由导频训练样本进行神经网络深度学习,得到最终的网络权重值;
S5:构造完备码本:用改进的DFT(Discrete Fourier Transform,离散傅里叶变换)方法构造适合所有信道状态的码本;
S6:码字选择:根据学习后的神经网络输出的信道,从完备码本中进行码字选择;
S7:相关关系的建立:构建所述测试区的导频信息与无线信道特性信息间的相关关系;
S8:信道匹配步骤:将未知区的信道与已有的无线信道匹配,进而选出未知区的信道对应的码字。
进一步,在步骤S1中,在进行信息采集时将测试区分为四类:郊区宏小区(suburban macro)、市区宏小区(urban macro,UM-a)、市区微小区(urban micro,UM-i)和高速场景(high rise scenario)。
进一步,在步骤S3中,所述初始化神经网络模型参数具体包括:学习率η,偏置值δ,输入层i节点与隐含层j节点的权值系数ωij∈(0,1),隐含层j与输出层节点l的权值系数ωjl∈(0,1),其中i,j,k∈N+且∑|ω|=M(M是常数),最大迭代次数lmax,误差初值e=0,神经元激活函数f(.)采用阈值函数、线性函数或Sigmoid函数。
进一步,在步骤S4中,所述神经网络深度学习具体包括:
S41:导频训练样本P作为神经网络的输入,H=[H0,H1,...,HN]为神经网络的估计目标值,为神经网络的估计输出值;
S42:由模型输出与目标值间的误差、最大迭代次数及权重值约束条件进行参数的深度训练,直到得到满足精度要求;
S43:每进行一次,迭代次数加1即l=l+1;当迭代次数l≤lmax或e(l)≤τmax时结束训练,否则返回步骤S42;
S44:经步骤S41、S42、S43后获得目标更新的权值系数;学习阶段完成后,神经网络利用测试区的导频P来估计并将储存到基于Spark集群的Shark数据库中,Shark数据库为用户提供信道信息的查询服务。
进一步,在步骤S5中,所述用改进的DFT方法构造适合所有信道状态的码本如下:
F=WFDFT
其中,W(∈Mt×Mt)是酉矩阵,满足U=W∑VH(U∈(Mt×Mt),其元素服从CN(0,1))。
进一步,在步骤S6中,所述码字选择包括:神经网络学习完成后,神经网络的输出值即为利用导频训练样本估计出的信道;根据选码准则进行码字选择,并把选出的最优码字放在Shark数据库中,为用户提供码字信息的查询服务。
进一步,在步骤S7中,由信道信息,构建测试区的导频信息与无线信道特性信息间的相关关系,具体包括:根据测试区的导频相关性特征,将测试区内的导频分为多个具有代表性的参考导频图案;由测试区的无线信道模型获取该测试区内参考导频图案的信道信息,得到每个参考图案对应的信道特征,并将参考图案对应的信道特征存储在参考信道信息数据库中。
进一步,在步骤S8中,所述将未知区的信道与已有的无线信道匹配,进而选出未知区的信道对应的码字具体包括:
S81:根据所述未知区域的导频信息与测试区中的参考导频图案进行特征匹配;
S82:判断未知区域的导频信息与测试区的参考导频图案特征间的相似度是否小于设定的阈值,若小于则匹配成功;否则,重新选取参考导频图案,直到满足小于设定的阈值;
S83:当未知区中的导频信息和测试区中的导频图案特征匹配成功后,将参考信道信息数据库中该图案对应的信道特征确定为未知区的信道特征,将信道特征进行综合,得到该未知区中的无线信道;
S84:根据该无线信道,在储存最优码字信息的Shark数据库中,获取最优码字,并将其反馈给该未知区中的基站(BS)。
本发明的有益效果在于:本发明能有效、准确、快速地建立无线信道模型与码本查询,避免了未知区的信道估计且大大降低了未知区信道选择码本的复杂度。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明所述方法的流程示意图;
图2为测试区的无线信道建立流程图;
图3为神经网络深度学习的步骤流程图;
图4为大规模MIMO下码本预编码方法流程图;
图5为未知区导频信息与无线信道特性信息间的匹配模型流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图1为本发明所述方法的流程示意图,如图所示,本方法具体包括以下步骤:
S1:信息采集步骤:由信息采集系统采集测试区内用户端的导频信息;
S2:获取训练样本:根据导频信息构建导频训练序列,进而得到导频训练样本;
S3:初始化神经网络:初始化神经网络模型参数;
S4:神经网络学习:由导频训练样本进行神经网络深度学习,得到最终的网络权重值;
S5:构造完备码本:用改进的DFT(Discrete Fourier Transform,离散傅里叶变换)方法构造适合所有信道状态的码本;
S6:码字选择:根据学习后的神经网络输出的信道,从完备码本中进行码字选择;
S7:相关关系的建立:构建所述测试区的导频信息与无线信道特性信息间的相关关系;
S8:信道匹配步骤:将未知区的信道与已有的无线信道匹配,进而选出未知区的信道对应的码字。
图2为测试区的无线信道建立流程图,包括:
将测试区分为四类:郊区宏小区、市区宏小区、市区微小区、高速场景,以UM-i为例进行信息采集,其余的类同;
将测试区分为四类:郊区宏小区(suburban macro)、市区宏小区(urban macro,UM-a)、市区微小区(urban micro,UM-i)、高速场景(high rise scenario),这里以UM-i为例进行分析,其余的类同;
信息采集系统采集测试区内用户端的导频信息;
由导频信息构建导频训练序列,进而获得导频训练样本;
导频训练样本作为神经网络的输入,进行神经网络深度学习,学习结束后得到神经网络输出值,即为估计出的信道。
图3为神经网络深度学习的步骤流程图,所述神经网络深度学习具体包括:
S41:导频训练样本P作为神经网络的输入,H=[H0,H1,...,HN]为神经网络的估计目标值,为神经网络的估计输出值;
S42:由模型输出与目标值间的误差、最大迭代次数及权重值约束条件进行参数的深度训练,直到得到满足精度要求;
S43:每进行一次,迭代次数加1即l=l+1;当迭代次数l≤lmax或e(l)≤τmax时结束训练,否则返回步骤S42;
S44:经步骤S41、S42、S43后获得目标更新的权值系数;学习阶段完成后,神经网络利用测试区的导频P来估计并将储存到基于Spark集群的Shark数据库中,Shark数据库为用户提供信道信息的查询服务。
图4为大规模MIMO下码本预编码方法流程图,由改进的DFT方法构造码本,并将码本放在收发两端:
F=WFDFT
其中,W(∈Mt×Mt)是酉矩阵,满足U=WΣVH(U∈(Mt×Mt),其元素服从CN(0,1))。
用户端将神经网络输出的最优码字在码本中的索引反馈给基站端(BS),并将最优码字的信息存储到Shark数据库中,该Shark数据库为用户提供最优码字的查询服务。
图5为未知区导频信息与无线信道特性信息间的匹配模型流程图,在本实施例中,具体流程如下:
根据UM-i测试区的导频相关性特征,将测试区内的导频分为多个具有代表性的参考导频图案;
由UM-i测试区的无线信道获取该测试区内参考导频图案的信道信息,得到每个参考图案对应的信道特征,并将参考图案对应的信道特征存储在参考信道信息数据库中。
根据所述未知区的导频信息与UM-i测试区中的参考导频图案进行特征匹配;
判断未知区域的导频信息与测试区的参考导频图案特征间的相似度是否小于设定的阈值,若小于则匹配成功;否则,重新选取参考导频图案,直到满足小于设定的阈值;
当未知区中的导频信息和测试区中的导频图案特征匹配成功后,将参考信道信息数据库中该图案对应的信道特征确定为未知区的信道特征,将信道特征进行综合,得到该未知区中的无线信道;
根据该无线信道,在储存最优码字信息的Shark数据库中,获取最优码字,并将其反馈给该未知区中的BS。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!