数据存储监控方法与流程
本发明涉及数据处理,特别涉及一种数据存储监控方法。
背景技术:
用户在享受网络设施和服务带来的便利的同时,安全问题也逐步升级。由于无线网络的普及,在许多公共场所,用户越来越多的将个人敏感数据存储或传递到网络中和存储在云平台上。而黑客所能利用的信息也随着网络服务和信息量的增加而增多,他们采用扫描端口、暴力破解、等漏洞对目标服务器进行监控。网络安全监控面临着两个亟待解决的问题,一是所要监控的目标系统数据量庞大,以往的非正常事件监控平台很难应对如此庞大的数据量。二是如何利用好大数据以及云平台,从而为安全事件监控提供良好的计算基础。以往技术集中在将网络日志、深度包数据应用在云平台下进行分布式计算,并没有考虑到从数据输入、计算、存储、前台展现等一系列围绕云平台架构的问题。同时,没有考虑实际网络中应对突发数据量,以及通过及时更新学习库对未知非正常进行记录和监控等问题。
技术实现要素:
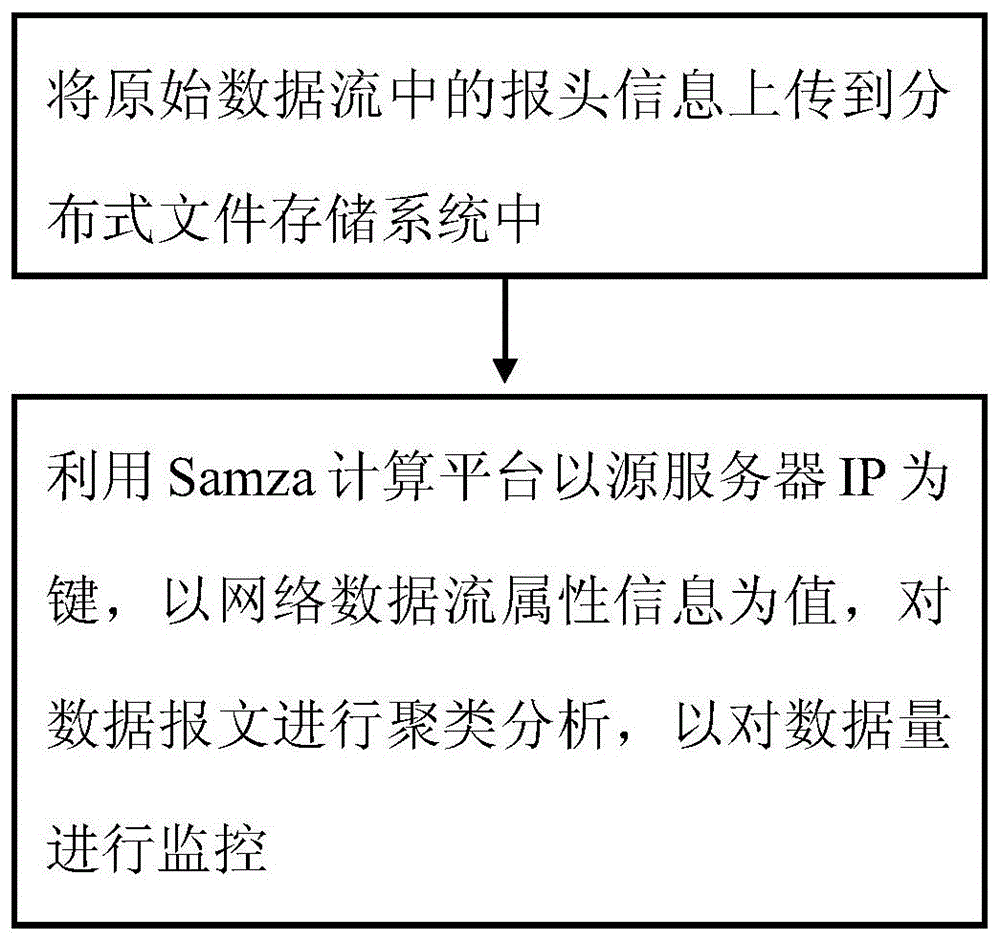
为解决上述现有技术所存在的问题,本发明提出了一种数据存储监控方法,包括:
将原始数据流中的报头信息上传到分布式文件存储系统中,再利用Samza计算平台以源服务器IP为键,以网络数据流属性信息为值,对数据报文进行聚类分析,以对数据量进行监控。
优选地,所述方法进一步包括:
针对网络原始数据流,对数据包进行捕获,然后将数据流报头信息剥离,对于直接能够应用条件过滤对数据流进行过滤的非正常数据流,在进入计算处理过程之前,即上传到分布式文件存储系统之前对数据进行过滤判断,将结果存储在分布式文件存储系统上;将聚类结果存储进入学习库,作为下次分类的依据,将监控结果存入数据库,分别用于阈值分析、非正常监控和数据显示;在数据流监控中,通过聚类算法构建数据流类型集合,对存在于学习库中的集合进行分类划分,从而发现网络中存在的攻击;
其中,在将原始数据流上传到分布式文件存储系统中之前,将部分报头信息正则化并存储后,形成聚类分析的输入数据向量;以源服务器ip和目标端口为关键字,选取流量属性作为聚类分析的输入属性;所述正则化具体包括:
au=(a-amin)/(amax-amin)
其中au为正则化结果,a为每个原始数据,amax-amin分别为原始报头数据的最大值和最小值;
所述聚类过程具体包括:
步骤l:输入属性数据集
步骤2:邻近聚类,对每个x,若|x-mj|<|x-mi|,其中i=1,2,3...c且i≠j,c为聚类数量,则x∈tj
步骤3:计算聚类中心mj=∑x∈tx j=1,2,3...c
步骤4:计算每个类的平均间距δj=∑x∈t|x-mj|
步骤5:计算总体的平均间距δ=∑j=1…cNjδj,其中Nj为第j个类的元素数量;
步骤6;计算各个聚类中心之间的距离:δij=||mi-mj||;
步骤7:把小于预设参数ec的所有距离δij升序排列;
步骤8:判断该类是否合并过,若没有被合并过,则对这些类依次合并,即计算合并中心
本发明相比现有技术,具有以下优点:
本发明提出了一种数据存储监控方法,适应面向不同数据集和响应要求的安全事件监控需求,很好地解决实时性和监控效率之间的平衡问题。
附图说明
图1是根据本发明实施例的数据存储监控方法的流程图。
具体实施方式
下文与图示本发明原理的附图一起提供对本发明一个或者多个实施例的详细描述。结合这样的实施例描述本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求书限定,并且本发明涵盖诸多替代、修改和等同物。在下文描述中阐述诸多具体细节以便提供对本发明的透彻理解。出于示例的目标而提供这些细节,并且无这些具体细节中的一些或者所有细节也可以根据权利要求书实现本发明。
本发明的一方面提供了一种数据存储监控方法。图1是根据本发明实施例的数据存储监控方法流程图。
本发明在数据监控平台下对数据流进行实时监控,加强了对未知类型数据流进行监控的能力。在该架构中对日志、数据流镜像进行采集、存储、计算、和显示。采用数据挖掘聚类分析的方法,监控平台中存在的未知非正常情况。首先对数据流进行聚类,经过统计后得出该类的统计特性,记录进入学习库后生成分类标签,当产生新的数据流时,对网络数据流进行分类,若不满足分类条件,对数据流进行重新聚类,作为下次处理的依据。通过统计的方法对网络中的数据量进行分析、统计,从而发现网络中潜在的安全事件。
针对大规模网络非正常数据流实时监控的要求,系统从数据采集、存储、计算和结果显示结合如下分布式监控平台,包括采集单元、存储单元、计算处理单元和显示单元。其中计算处理单元中应用Samza云平台,实时处理数据流并显示网络运行状况,监控和预警安全事件。
数据采集单元将分散在网络中各个节点和服务器的日志信息、原始数据流信息、数据包镜像信息进行采集,并且保证采集的数据具有内容可靠性、数据集可扩展性,控制节点可管理性。将系统中分散节点产生的日志信息、数据量信息通过数据采集节点传送到分布式文件存储系统中,并对原始数据进行初步处理,产生适合计算处理单元运算的输入数据,最终存储到分布式文件存储系统中。
数据采集单元将分散在网络中的路由节点、防火墙节点、服务器节点等能够产生日志和数据镜像的节点作为数据代理,通过架设多个数据采集节点,然后由主控节点协调工作,将数据推送到分布式文件存储系统中,以便计算处理单元对输入数据进行处理。
存储单元包含数据缓存、数据集中存储、数据持久化模块。数据缓存模块将一部分采集数据直接交付计算处理单元进行数据处理,而不存储在分布式文件存储系统上。所述数据缓存包含消息队列,对数据向计算处理单元进行交付,该模块适用于实时的流处理计算,同时也兼容分布式文件存储系统的存储计算,从而减少了I/O次数,提升了平台计算的效率。
数据集中存储模块应用分布式文件存储系统对采集到的日志和数据流进行存储,对日志采集系统所采集的数据提取出计算处理单元所需要的数据格式。对于存储的数据采用两种数据存储方式:一种是关系数据库,方便计算处理单元采用结构化查询的方式获取数据。另一种是键值对存储方式,适合分布式计算框架的编程模型。
计算处理单元所计算出的结果分为两部分,一部分用于显示,需要存储到关系数据库中,一方面作为网络数据流的历史数据,另一方面用于显示单元的数据源。而另一部分作为处理文件的输入数据集,即对安全数据进行初步统计分析后,再为数据挖掘分析提供输入数据。
计算处理单元包括离线处理、定时处理、实时处理模块。离线处理模块是监控平台利用分布式计算框架的编程模型;采用聚类分析、分类计算、关联规则等数据挖掘的算法对网络中的日志进行离线分析。对攻击行为进行分析还原。例如将入侵监控日志作为关联规则的数据源,对每一条独立的入侵监控数据通过地址溯源,经过报警关联判断,报警决策树生成,对整个攻击流程进行关联分析,还原攻击者对目标机器攻击的整个场景。定时处理模块采用Samza编程模型,实现对网络中存在的攻击进行预警监控。将数据从分布式文件存储系统中读取出来后,在集群中进行数据交换,并且数据交换均发生在内存中,大大缩短了集群在I/O上所耗费的时间。将数据量原始数据上传后进行数据切分,将原始数据切分成数据集,经过流式计算后在集群中传递数据集。最后生成网络数据量统计信息。实时处理模块对于数据量统计信息,包括网络瞬时流量、带宽消耗、关键节点服务器状态,根据属性和规则进行过滤,将日志文件、数据量文件进行初步筛选产生数据流,并将筛选后的结果进行进一步处理。该模块利用分布式计算框架编程模型,对采集到分布式文件存储系统上的文件进行统计分析计算。
Samza集群对于数据量采集到的数据进行统计分析,建立统计分析数据集。云计算集群对网络数据包进行属性提取,数据预处理后对数据进行聚类,将非正常数据流类别从网络数据流中分离出来。
显示单元应用Json传递数据格式至前台界面,向用户提供两种数据接口。其一是安全访问API,向用户以应用单元数据的方式提供数据计算结果,使用套接字数据接口。其二是面向应用的API,针对特定的日志格式,将用户希望监控的数据接入到采集单元,用云监控平台进行安全监控分析。经过客户端和服务器端握手后,可以长时间从服务器端主动向客户端推送数据信息,缩短了数据传输时间,提高了数据传输效率。在显示单元采用从集群主动推送消息的方式来传送数据。
原始数据经过Samza统计处理,对网络非正常状况进行判断,从而在网络历史数据流中判断和筛选出非正常数据流。经过统计之后的网络数据流统计数据进入计算处理单元,对数据进行离线处理计算,通过聚类算法,判断网络中存在的已未知非正常预测。
在数据流采集模块中,实现了数据量和网络数据包相结合的跨单元监控平台数据流的方法。获取数据量描述元组和数据流大小信息。针对数据流,采用一台主机接受数据流,然后对采集的数据流进行解析,将解析后的内容上传到分布式文件存储系统后,再通过Samza集群计算网络数据流统计数据。针对网络原始数据流,对数据包进行捕获,然后将数据流报头信息剥离,将结果存储在分布式文件存储系统上。
本发明对网络数据量监控流程如下。
步骤1:将数据流从服务器经过初步过滤和计算上传到分布式文件存储系统中,以便集群进行计算。
步骤2:通过Samza计算统计数据流。同时对网络原始数据包进行聚类分析。
步骤3:将计算结果写入关系数据库,并将聚类结果存储进入学习库,作为下次分类的依据。
步骤4:将监控结果存入数据库,分别用于阈值分析、非正常监控和数据显示。
数据流中包括源地址、目标地址、源端口、目标端口、协议类型、字节数。这些数据流需要经过统计处理,才能被应用于大规模数据统计。
在Samza平台上将原始数据流经过计算统计后形成网络数据流属性信息,出口报文表示从监控平台中向外部网络发送的数据包,入口报文表示从外部网络向内部网络发送的数据包。对于直接能够应用条件过滤对数据流进行过滤的非正常数据流,在进入计算处理单元之前,即上传到分布式文件存储系统之前对数据进行过滤判断。
在数据流监控中,通过聚类算法构建数据流类型集合,对存在于学习库中的集合进行分类划分,从而发现网络中存在的攻击。
针对网络原始数据流,将部分报头信息正则化并存储后,形成聚类分析的输入数据向量。以源服务器ip和目标端口为关键字,选取流量属性作为聚类分析的输入属性。其中在进入聚类分析之前,所述正则化如下:
au=(a-amin)/(amax-amin)
其中au为正则化结果,a为每个原始数据,amax-amin分别为原始报头数据的最大值和最小值。
聚类过程中,根据已选定好的属性,输入数据,对目标数据流进行聚类,将正常的数据流和非正常的数据流进行区分,具体如下:
步骤l:输入属性数据集
步骤2:邻近聚类,对每个x,若|x-mj|<|x-mi|,其中i=1,2,3...c且i≠j,c为聚类数量,则x∈tj
步骤3:计算聚类中心mj=∑x∈tx j=1,2,3...c
步骤4:计算每个类的平均间距δj=∑x∈t|x-mj|
步骤5:计算总体的平均间距δ=∑j=1…cNjδj,其中Nj为第j个类的元素数量;
步骤6;计算各个聚类中心之间的距离:
δij=||mi-mj||
步骤7:把小于预设参数ec的所有距离δij升序排列
步骤8:判断该类是否合并过,若没有被合并过,则对这些类依次合并,即计算合并中心
在预处理阶段,将网络原始数据流截获并提取包头信息存储到分布式文件存储系统中,再通过映射和规约操作,以源服务器IP和服务器目标端口为关键字进行网络数据流属性统计。截获预定时间内的网络数据包头,并对该时间内的包头信息个数进行汇总。
在不满足改进贝叶斯分类网络的情况下,即存在数据归属于各个类的概率相近,则判断产生的非正常数据流的新类型。将该类型的数据流重新输入聚类过程后,将新产生的类型存储在学习库,作为下次分类的依据。
将聚类算法应用在云平台中,需要考虑将原始数据流中的报头信息先上传到分布式文件存储系统中,再利用计算处理单元中的Samza定时处理,以源服务器IP为键,以网络数据流属性信息为值,对数据报文进行统计分析。最后将统计结果重新存储到分布式文件存储系统的关系数据库中,作为聚类分析的输入数据。当进行聚类时,计算处理单元进行离线处理,执行聚类过程。
综上所述,本发明提出了一种数据存储监控方法,适应面向不同数据集和响应要求的安全事件监控需求,很好地解决实时性和监控效率之间的平衡问题。
显然,本领域的技术人员应该理解,上述的本发明的各模块或各步骤可以用通用的计算系统来实现,它们可以集中在单个的计算系统上,或者分布在多个计算系统所组成的网络上,可选地,它们可以用计算系统可执行的程序代码来实现,从而,可以将它们存储在存储系统中由计算系统来执行。这样,本发明不限制于任何特定的硬件和软件结合。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!