热点区域自动识别方法和装置与流程
本发明涉及通信技术领域,尤其涉及一种热点区域自动识别方法和装置。
背景技术:
当前移动无线网络处于快速发展阶段,网络负荷开始面临大业务量考验,在局部热点区域已呈现出高用户密度、高并发、大流量的特征。及时掌握并确保热点区域的业务质量与客户感知,是网络运营工作的重点。现有的热点区域监控能力主要通过事先划定好可能发生业务热点的范围,人工梳理出需要重点关注的网元,在保障期间进行持续关注。该方法能够将网络监控范围精准到热点区域,解决对日常可预见性的热点区域业务负荷及网络质量的监控能效。但是人工干预设定热点区域具有一定的局限性,人工梳理及手工配置的人力成本消耗高,立足于该方案的信令大数据分析热点区域自动捕获能力更加凸显高效。根据当前信令数据采集能力,要实现热点区域自动捕获及业务质量监控,存在的问题与缺陷,有以下几点:1、信令大数据实时采集能力目前有待进一步提升,特别针对指标数据的时延控制能力存在缺口,该缺口伴随着采集范围的扩大存在加大恶化的表现。数据时延将直接影响到对热点区域突然并发问题的捕获能力。2、底层数据来源多样性,涉及信令、网管、拨测、路测,将对上层数据汇聚提高难度,将不同数据源、不同时间维度、不同时延、进行汇聚复合运算,对数据处理层的逻辑运算能力有很高的要求。3、热点识别采用动态基线,横向比对算法,生成动态基线的历史数据都是基于5分钟采集、全网小区粒度,同时因热点区域的突发性,无法提前约定需要横向比对的数据范围,故全部动态基线都将是实时触发计算,这种计算方法的效率较低。
技术实现要素:
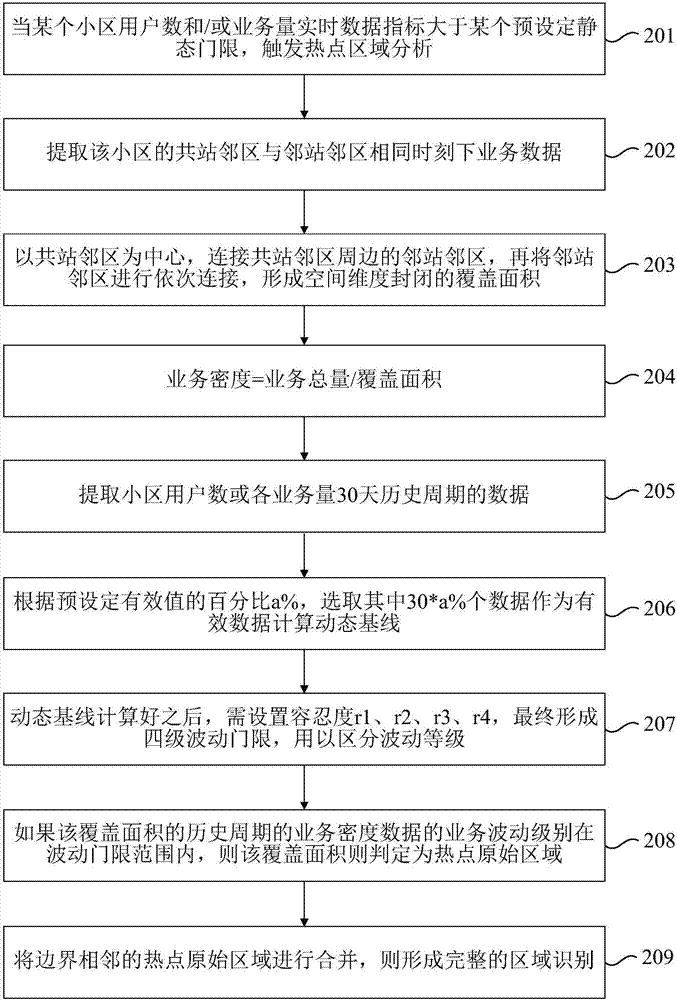
技术问题有鉴于此,本发明要解决的技术问题是,如何自动识别热点区域。解决方案本发明提供一种热点区域自动识别方法,包括:在出现用户数大于第一门限和/或业务量大于第二门限的待识别小区的情况下,触发针对所述待识别小区的热点区域识别步骤;所述热点区域识别步骤包括:获取所述待识别小区的共站邻区和各邻站邻区在相同时刻下的相关业务数据;以所述共站邻区为中心原点,连接到所述共站邻区周边的各所述邻站邻区,以确定覆盖面积;根据所述共站邻区的业务数据、各所述邻站邻区的业务数据和所述覆盖面积,计算出所述覆盖面积对应的业务密度数据;从所述覆盖面积内的全部所述共站邻区和各所述邻站邻区的历史周期的业务密度数据中,提取出有效数据,并计算出对应的动态基线;根据所述动态基线和预先设置的容忍度,确定所述覆盖面积是否属于热点原始区域;基于所述热点原始区域构成热点区域。对于上述方法,在一种可能的实现方式中,基于所述热点原始区域构成热点区域包括:在存在多个热点原始区域的情况下,将边界相邻的热点原始区域进行合并以构成热点区域。对于上述方法,在一种可能的实现方式中,从所述覆盖面积内的全部所述共站邻区和各所述邻站邻区的历史周期的业务密度数据中,提取出有效数据,并计算出对应的动态基线,包括:从所述覆盖面积内的所述共站邻区和各所述邻站邻区中提取用户数和/或业务量在d天内的历史周期的业务密度数据;根据预先设定的有效值的百分比a%,从所提取的历史周期的业务密度数据中选取d*a%个有效数据,其中,所述有效数据为所提取的历史周期的业务密度数据中方差最小的d*a%个数据;计算所选取的d*a%个有效数据的平均值E和方差sigma,并采用式M=E+sigma计算所述动态基线M。对于上述方法,在一种可能的实现方式中,根据所述动态基线和预先设置的容忍度确定所述覆盖面积是否属于热点原始区域,包括:采用式M*(1+rn)来计算第n级的业务波动门限,其中,rn为业务波动级别为n级的容忍度,n为正整数;将所述覆盖面积的历史周期的业务密度数据的波动情况和业务波动门限进行比较,确定所述覆盖面积是否属于热点原始区域。对于上述方法,在一种可能的实现方式中,还包括:根据所述覆盖面积所属的业务波动级别,在GIS地图上采用相应颜色进行渲染。本发明还提供一种热点区域自动识别方法,包括:根据预先设定的小区业务质量指标劣化门限,触发针对待识别小区的热点区域识别步骤;所述热点区域识别步骤包括:根据所述待识别小区的共站邻区与在所述共站邻区周边的各邻站邻区的相同业务质量指标劣化的情况,查找各同质劣化小区;根据所查找到的同质劣化小区的数量相对于本次热点识别过程中所分析的关联邻区的占比,触发热点区域确定过程,所述触发热点区域确定过程包括将本次热点识别过程中的所分析的关联邻区进行封闭连接以形成热点区域。对于上述方法,在一种可能的实现方式中,根据所述待识别小区的共站邻区与在所述共站邻区周边的各邻站邻区的相同业务质量指标劣化的情况,查找各同质劣化小区,包括:在所述待识别小区的共站邻区与各邻站邻区存在相同业务质量指标劣化的情况下,查找是否存在所述待识别小区的同质劣化小区;如果存在,则根据当前查找到的同质劣化小区执行查找步骤,所述查找步骤包括:查找所述当前查找到的同质劣化小区的共站邻区与邻站邻区中是否存在当前查找到的同质劣化小区的同质劣化小区;如果存在,则根据当前查找到的同质劣化小区继续执行所述查找步骤,直至查找不到当前查找到的同质劣化小区的同质劣化小区为止。对于上述方法,在一种可能的实现方式中,还包括:根据所述热点区域内各小区的业务质量劣化级别,在GIS地图上采用相应颜色进行渲染。本发明还提供一种热点区域自动识别装置,包括:触发模块,用于在出现用户数大于第一门限和/或业务量大于第二门限的待识别小区的情况下,触发热点区域识别模块对所述待识别小区进行热点区域识别;所述热点区域识别模块包括:业务数据获取单元,用于获取所述待识别小区的共站邻区和各邻站邻区在相同时刻下的业务数据;覆盖面积确定单元,用于以所述共站邻区为中心原点,连接到所述共站邻区周边的各所述邻站邻区,以确定覆盖面积;业务密度计算单元,用于根据所述共站邻区的业务数据、各所述邻站邻区的业务数据和所述覆盖面积,计算出所述覆盖面积对应的业务密度数据;动态基线计算单元,用于从所述覆盖面积内的全部所述共站邻区和各所述邻站邻区的历史周期的业务密度数据中,提取出有效数据,并计算出对应的动态基线;热点区域确定单元,用于根据所述动态基线和预先设置的容忍度,确定所述覆盖面积是否属于热点原始区域;基于所述热点原始区域构成热点区域。对于上述装置,在一种可能的实现方式中,所述热点区域确定单元还用于在存在多个热点原始区域的情况下,将边界相邻的热点原始区域进行合并以构成热点区域。对于上述装置,在一种可能的实现方式中,所述动态基线计算单元还用于:从所述覆盖面积内的所述共站邻区和各所述邻站邻区中提取用户数和/或业务量在d天内的历史周期的业务密度数据;根据预先设定的有效值的百分比a%,从所提取的历史周期的业务密度数据中选取d*a%个有效数据,其中,所述有效数据为所提取的历史周期的业务密度数据中方差最小的d*a%个数据;计算所选取的d*a%个有效数据的平均值E和方差sigma,并采用式M=E+sigma计算所述动态基线M。对于上述装置,在一种可能的实现方式中,所述热点区域确定单元还用于:采用式M*(1+rn)来计算第n级的业务波动门限,其中,rn为业务波动级别为n级的容忍度,n为正整数;将所述覆盖面积的历史周期的业务密度数据的波动情况和业务波动门限进行比较,确定所述覆盖面积是否属于热点原始区域。对于上述装置,在一种可能的实现方式中,还包括:渲染模块,用于根据所述覆盖面积所属的业务波动级别,在GIS地图上采用相应颜色进行渲染。本发明还提供一种热点区域自动识别装置,包括:触发模块,用于根据预先设定的小区业务质量指标劣化门限,触发热点区域识别模块对待识别小区的热点区域进行识别;所述热点区域识别模块包括:查找单元,用于根据所述待识别小区的共站邻区与在所述共站邻区周边的各邻站邻区的相同业务质量指标劣化的情况,查找各同质劣化小区;热点区域确定单元,用于根据所查找到的同质劣化小区的数量相对于本次热点识别过程中所分析的关联邻区的占比,触发热点区域确定过程,所述触发热点区域确定过程包括将本次热点识别过程中的所分析的关联邻区进行封闭连接以形成热点区域。对于上述装置,在一种可能的实现方式中,所述查找单元还用于:在所述待识别小区的共站邻区与各邻站邻区存在相同业务质量指标劣化的情况下,查找是否存在所述待识别小区的同质劣化小区;如果存在,则根据当前查找到的同质劣化小区执行查找步骤,所述查找步骤包括:查找所述当前查找到的同质劣化小区的共站邻区与邻站邻区中是否存在当前查找到的同质劣化小区的同质劣化小区;如果存在,则根据当前查找到的同质劣化小区继续执行所述查找步骤,直至查找不到当前查找到的同质劣化小区的同质劣化小区为止。对于上述装置,在一种可能的实现方式中,还包括:渲染模块,用于根据所述热点区域内各小区的业务质量劣化级别,在GIS地图上采用相应颜色进行渲染。有益效果本发明可以自动进行热点区域识别,相对现有的人工判断方法,通过设置好热点自动捕获门限,完成热点区域自动捕获,能够节省人力成本,具备准确性高,效率高的优点。进一步地,本发明可以参考待识别小区的共站邻区与各邻站邻区相关历史数据协同分析,能通过周期性数据对热点区域突发问题做出有效的分析和评估,规避了实时数据采集时延的延时性。进一步地,本发明将底层数据逐级汇总,形成不同级别的关联分析数据,降低了输出最终结果所需的运算能力和需求,并且还可以按不同数据层次给出对比情况。进一步地,本发明通过分析待识别小区的共站邻区与各邻站邻区相关历史数据,提取有效数据,并计算对应的动态基线,不需实时采集和实时出发计算,提升了识别效率和运算需求。根据下面参考附图对示例性实施例的详细说明,本发明的其它特征及方面将变得清楚。附图说明包含在说明书中并且构成说明书的一部分的附图与说明书一起示出了本发明的示例性实施例、特征和方面,并且用于解释本发明的原理。图1示出根据本发明一实施例的热点区域自动识别方法的流程图;图2示出根据本发明另一实施例的热点区域自动识别方法的流程图;图3示出根据本发明另一实施例的热点区域自动识别方法的流程图;图4示出根据本发明另一实施例的热点区域自动识别方法的流程图;图5示出根据本发明另一实施例的热点区域自动识别方法中的覆盖面积计算方式的示意图;图6示出根据本发明另一实施例的热点区域自动识别方法中的渲染效果的示意图;图7示出根据本发明一实施例的热点区域自动识别装置的结构示意图;图8示出根据本发明另一实施例的热点区域自动识别装置的结构示意图。具体实施方式以下将参考附图详细说明本发明的各种示例性实施例、特征和方面。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。另外,为了更好的说明本发明,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本发明同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路未作详细描述,以便于凸显本发明的主旨。本发明实施例主要从重要区域质量保障效果、和网络性能管理过程两个层面分别明确衡量标准,通过小区业务面指标(例如流量、用户数等)波动情况监测,结合信令控制面各指标值(例如质量劣化),运用大数据分析合理设置省、地市、区县、重要保障热点触发规则,实现重要区域质量监测分析,及时掌握并确保重点区域的业务质量与客户感知。首先,在地域上可以将例如省、地市、区县3个固定场景,以及重点保障场景区域中所属全量小区等视为重要区域。然后,基于基础数据进行热点识别。举例而言,基于信令的指标集可以包括:用户数、业务量、控制面指标、信令面指标等4类。涉及网页浏览、视频业务、即时通信、应用下载四个业务和网络附着、承载建立、TAU更新、域名查询、连接建立等环节。指标集可以全都采用无线小区空间维度,5分钟为时间统计粒度。各指标的类型以及对应的含义等,可以参见例如表1的相关内容,但是表1也仅是一种示例,即可以采用表1中的部分或全部指标作为热点识别的基础数据,也可以采用与表1类似的其他指标作为热点识别的基础数据。表1热点识别(或热点业务识别)是指按照某种计算规则,主要采用阈值和波动门限、横向对比法,找出区域内使用量最高、增长量最高或业务模型发生明显变化的业务,及时掌握区域内用户访问业务的情况。以下通过几个具体实施例来介绍热点区域自动识别的过程。实施例1图1示出根据本发明一实施例的热点区域自动识别方法的流程图。如图1所示,该热点区域自动识别方法主要可以包括:步骤101、在出现用户数大于第一门限和/或业务量大于第二门限的待识别小区的情况下,触发步骤102。举例而言,可以对重要区域的各小区进行监控,发现重要区域的某个小区的用户密度和/或业务密度发生突变,可以将该小区认为是待识别小区。步骤102、对所述待识别小区进行热点区域识别,具体可以包括:步骤1021、获取所述待识别小区的共站邻区和各邻站邻区在相同时刻下的相关业务数据;其中,一个小区的共站邻区为该小区所归属基站覆盖范围内的其他小区;一个小区的邻站邻区为与该小区归属基站直接相邻的基站覆盖范围内的所有小区。步骤...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1