一种从黑名单号码库中自动识别可释放号码的方法与流程
本发明涉及一种从黑名单号码库中自动识别可释放号码的方法,属于网络通信技术领域。
背景技术:
目前,黑名单号码库中的所有黑号码都是经过长时间的积累而形成的,越来越多的黑号码给网络存储带来压力。经过长期现网观察,当号码进入黑名单号码中被拦截之后,有很多骚扰诈骗分子会放弃使用这个号码,而更换其他号码进行非法活动。因此,黑号码在入黑后,如果在很长一段时间内这个号码的活跃度很低,那么就可以从黑名单号码库中释放这个黑号码,使之成为正常号码供用户使用。如何计算黑名单号码库中每个黑号码的活跃度,并识别活跃度低的黑号码以释放成为用户使用的正常号码,已成为技术人员急需解决的技术问题,目前还未发现相关技术解决方案。
技术实现要素:
有鉴于此,本发明的目的是提供一种从黑名单号码库中自动识别可释放号码的方法,能准确计算黑名单号码库中每个黑号码的活跃度,并识别活跃度低的黑号码以释放成为用户使用的正常号码。
为了达到上述目的,本发明提供了一种从黑名单号码库中自动识别可释放号码的方法,包括有:
步骤一、构建多个在不同时间周期下的分类模型,其中,每个分类模型的输入是一个号码在对应时间周期下的若干通信指标,输出是该号码在对应时间周期下的活跃度;
步骤二、从黑名单号码库中逐一提取每个黑号码,并将所述黑号码在不同时间周期下的若干通信指标分别输入到在对应时间周期下的分类模型中,当所述黑号码在所有时间周期下的分类模型中输出的活跃度均小于低活跃度阈值时,则所述黑号码是可释放号码。
与现有技术相比,本发明的有益效果是:本发明通过黑名单号码库中所有黑号码入库后的多个通信指标,以及多个不同时间周期下的分类模型的层层筛选,能对每个黑号码的活跃度进行准确评估,从黑名单号码库所存储的大量黑号码中准确识别活跃度低的号码,并据此来释放其成为用户使用的正常号码,减轻系统存储压力,并且加载新的黑号码来提高系统的拦截效率,技术方案简单易行,并对现网无需任何改变,从而具有较高的实用性和高效性;当黑号码持续被重置时,说明该黑号码持续保持有较高的活跃度,本发明还可以进一步将所述黑号码加入高活跃度号码库,结合号码模式分析,挖掘此类高活跃度号码的号码模式,在今后出现符合该号码模式的新的黑号码时,由系统自动拦截处理。
附图说明
图1是本发明一种从黑名单号码库中自动识别可释放号码的方法流程图。
图2是对于从黑名单号码库中提取的每个黑号码,步骤二的具体操作流程图。
图3是本发明结合号码模式分析,挖掘高活跃度号码的号码模式的具体操作流程图。
图4是图3步骤B的具体操作流程图。
图5是图4步骤B5的具体操作流程图。
图6是计算两个号码之间的相似度的具体操作流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步的详细描述。
如图1所示,本发明一种从黑名单号码库中自动识别可释放号码的方法,包括有:
步骤一、构建多个在不同时间周期下的分类模型,其中,每个分类模型的输入是一个号码在对应时间周期下的若干通信指标,输出是该号码在对应时间周期下的活跃度;
步骤二、从黑名单号码库中逐一提取每个黑号码,并将所述黑号码在不同时间周期下的若干通信指标分别输入到在对应时间周期下的分类模型中,当所述黑号码在所有时间周期下的分类模型中输出的活跃度均小于低活跃度阈值时,则说明骚扰诈骗份子已弃用所述黑号码,所述黑号码是可释放号码。
黑号码可以是诈骗、骚扰等非法号码,黑号码的活跃度是指号码在进入黑名单号码库之后,依然进行呼叫并且被系统拦截的概率,活跃度越高,表示号码呼叫的概率越大;而活跃度越低,表示该号码呼叫的概率越低,本发明可以通过从黑名单号码库中释放活跃度低的号码来减轻系统的存储压力,并且加载新的黑号码,以提高系统的拦截效率。
步骤一中,本发明中的时间周期可以包括但不限于:日、周、月、季度或半年。分类模型可以采用但不限于:决策树、逻辑回归、随机森林、支持向量机或神经网络模型。不同时间周期下的分类模型的输入可以选取不同的通信指标,例如:日分类模型(即以日为时间周期的分类模型)所输入的通信指标可以包括有呼叫频次、平均呼叫时间间隔等;周分类模型所输入的通信指标可以包括有呼叫频次、被叫离散度、忙时呼叫率、最大呼叫日间隔、最小呼叫日间隔等;月分类模型所输入的通信指标可以包括有呼叫频次、被叫离散度、忙时呼叫率、最大呼叫日间隔、最小呼叫日间隔、呼叫间隔日离散度等;季度分类模型所输入的通信指标可以包括有呼叫频次、被叫离散度、忙时呼叫率、最大呼叫日间隔、最小呼叫日间隔、呼叫间隔日离散度等;半年分类模型所输入的通信指标可以包括有呼叫频次、被叫离散度、忙时呼叫率、最大呼叫日间隔、最小呼叫日间隔、呼叫间隔日离散度等。
举例加以说明,当月分类模型采用决策树时,每个黑号码的活跃度的计算公式可以是:P=-1.17*日呼叫频次-0.114*周呼叫频次+2.69*月呼叫频次+2.31*被叫离散度-8,当P值越小,则说明活跃度越低;P值越大,则说明活跃度越高。该月分类模型中,输入的通信指标包括有:日、周、月呼叫频次、以及被叫离散度,可以用于快速识别短时间的黑号码。
本发明还可以在同一时间周期下设置多个分类模型,然后从黑名单号码库中抽取进入黑名单号码库已达到一定时间的若干黑号码,将其中一部分的黑号码作为训练数据,用于对同一时间周期下的多个分类模型分别进行训练,再将剩余部分的黑号码作为测试数据,用于从同一时间周期下的多个分类模型中挑选测试数据准确率最高的分类模型,最终所述时间周期下的分类模型即选取测试数据准确率最高的分类模型。
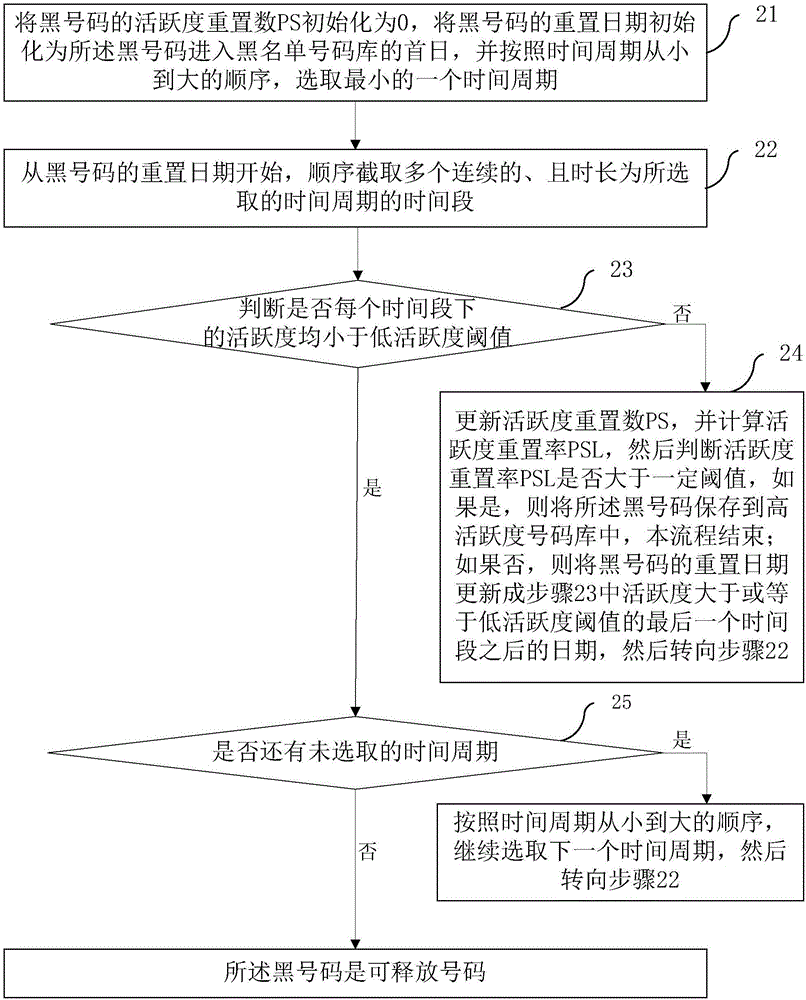
如图2所示,对于从黑名单号码库中提取的每个黑号码,步骤二还可以进一步包括有:
步骤21、将黑号码的活跃度重置数PS初始化为0,将黑号码的重置日期初始化为所述黑号码进入黑名单号码库的首日,并按照时间周期从小到大的顺序,选取最小的一个时间周期;
步骤22、从黑号码的重置日期开始,顺序截取多个连续的、且时长为所选取的时间周期的时间段;
步骤23、计算所述黑号码在多个连续的时间段内的若干通信指标,然后将每个时间段内的若干通信指标分别输入到在所述时间周期下的分类模型中,从而得到所述黑号码分别在每个时间段下的活跃度,并判断是否每个时间段下的活跃度均小于低活跃度阈值?如果否,则转向步骤24;如果是,则转向步骤25;
步骤24、更新活跃度重置数PS:PS=PS+1,并计算活跃度重置率PSL:PSL=PS/T_D,其中,T_D是所述黑号码进入黑名单号码库的总天数,然后判断活跃度重置率PSL是否大于一定阈值?如果是,则将所述黑号码保存到高活跃度号码库中,本流程结束;如果否,则将黑号码的重置日期更新成步骤23中活跃度大于或等于低活跃度阈值的最后一个时间段之后的日期,然后转向步骤22;
步骤25、判断是否还有未选取的时间周期?如果是,则按照时间周期从小到大的顺序,继续选取下一个时间周期,然后转向步骤22;如果否,则所述黑号码是可释放号码,本流程结束。
例如,先计算连续7天的天通信指标,当连续7天的日分类模型所输出的活跃度均小于低活跃度阈值时,再计算连续4周的周通信指标;当连续4周的周分类模型所输出的活跃度也均小于低活跃度阈值时,再继续计算连续2月的月通信指标……直至所有时间周期下的分类模型所持续输出的活跃度均小于低活跃度阈值时,则说明该黑号码是可释放号码。
本发明还可以对识别出的可释放号码按一定顺序从黑名单号码库中进行释放,包括有:
按照可释放号码在最大时间周期下的分类模型中输出的活跃度从小到大的次序,对所有可释放号码进行排序,然后从黑名单号码库中删除若干排序在前的可释放号码。
如果黑号码持续被重置(可按照实际情况设定,如将活跃度重置率设置为25%),则说明该黑号码持续保持有较高的活跃度,本发明停止分析,并将所述黑名单加入高活跃度号码库。同时,还可以结合号码模式分析,挖掘此类高活跃度号码的号码模式,在今后出现符合该号码模式的新的黑号码时,由系统自动拦截处理。如图3所示,本发明还可以包括有:
步骤A、将高活跃度号码库中位数相同的所有黑号码按一定顺序写入黑号码模式表中;
步骤B、从黑号码模式表中逐一提取每两条相邻号码,并计算相邻号码之间的相似度,当其相似度值超过阈值时,则表明两条相邻号码符合同一黑号码模式,提取两条相邻号码在对应位序上的相同号码符来构成一条黑号码模式,并写入到黑号码模式表中;
步骤C、将待识别号码和黑号码模式表中的所有黑号码模式逐一进行匹配,如果待识别号码和黑号码模式表中的一条黑号码模式匹配一致,则待识别号码是黑号码。
步骤A中,可以根据手机、座机等号码位数的不同,将黑号码模式表进一步细分为:手机号码模式表、座机号码模式表、和其他号码模式表等。
如图4所示,图3步骤B还可以进一步包括有:
步骤B1、初始化迭代序号t为1;
步骤B2、初始化号码模式标识符flag为0、号码序号i为1,并初始化第t次迭代的新增号码数Am(t)为0;
步骤B3、从黑号码模式表中提取第i、i+1条号码;
在多次迭代后,黑号码模式表中的第i或i+1条号码可能是黑号码、或者带有号码模式符的黑号码模式;
步骤B4、计算第i、i+1条号码之间的相似度,并判断第i、i+1条号码之间的相似度值是否超过一定阈值?如果是,则继续下一步;如果否,则转向步骤B7;
步骤B5、逐一从第i、i+1条号码中提取每一位号码符,并判断处于相同位序上的两个号码符是否相同,然后将相同的号码符写入到黑号码模式p的对应位序上,将不同的号码符替换成统一的号码模式符写入到黑号码模式p的对应位序上;
步骤B6、将p作为一条新增号码保存到黑号码模式表中,更新flag为1,更新第t次迭代的新增号码数Am(t):Am(t)=Am(t)+1,然后转向步骤B8;
步骤B7、判断flag是否为0?如果是,则将第i条号码作为一条新增号码保存到黑号码模式表中,更新flag为0,更新第t次迭代的新增号码数Am(t):Am(t)=Am(t)+1,然后继续下一步;如果否,则更新flag为0,然后继续下一步;
步骤B8、更新i:i=i+1,然后判断是否已提取完黑号码模式表中的所有号码?如果是,则继续下一步;如果否,则转向步骤B3;
步骤B9、判断第t次迭代的新增号码数Am(t)和第t-1次迭代的新增号码数Am(t-1)是否相同?如果是,则说明多次迭代后黑号码模式表中的所有结果处于收敛状态,删除黑号码模式表中不包含有号码模式符的黑号码,本流程结束;如果否,则更新t:t=t+1,然后转向步骤B2。
步骤B9中,删除黑号码模式表中不包含有号码模式符的黑号码后,黑号码模式表中所剩下的都是带有号码模式符的黑号码模式,将所有黑号码模式按正则表达式进行描述,将待识别号码和其一一匹配,并根据匹配结果判断待识别号码是否是黑号码。
如图5所示,图4步骤B5还可以进一步包括有:
步骤B51、设置号码位序n为1;
步骤B52、判断第i、i+1条号码在第n位序上的号码符是否相同?如果是,则将相同的号码符写入到黑号码模式p的第n位序上,然后继续下一步;如果否,则将一个号码模式符(例如*)写入到黑号码模式p的第n位序上,然后继续下一步;
步骤B53、更新n:n=n+1,并判断n是否大于第i条号码的号码位数?如果是,则本流程结束;如果否,则转向步骤B52。
如图6所示,计算两条号码之间的相似度,还可以进一步包括有:
步骤D1、计算两条号码之间的海明距离:逐一比较两条号码在每一位上的号码符是否相同,并统计不同号码符的个数,所述不同号码符的个数即是两条号码之间的海明距离;
例如,两条黑号码13511223344、13521456874之间的海明距离为6,黑号码13511223344和黑号码模式135*1*53*74之间的海明距离为5,两条黑号码模式135*1*53*74、136*1**3*74之间的海明距离为2;
步骤D2、计算两条号码之间的相似度:其中Sim(Ni,Nj)是号码Ni、Nj之间的相似度,hm(Ni,Nj)是号码Ni、Nj之间的海明距离,L是号码Ni或Nj的号码位数。
例如,两条号码:13512134560和13512475670,分别在第6、7、8、9、10位上的号码符不同,不同号码符的个数为5,则它们之间的海明距离是5,相似度为
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!