基于Web页面特征的金融类钓鱼网页检测方法与流程
本发明属于信息安全技术领域,特别是网站安全检测技术领域,涉及一种基于Web页面特征的金融类钓鱼网页检测方法。
背景技术:
随着互联网尤其是移动互联网的快速发展,基于Web的应用深入各行各业,为人们的工作、生活带来了极大的便利。与此同时,人们的个人信息被广泛收集,面临严峻的信息安全问题,如典型地通过网络钓鱼骗取个人敏感信息进而套取钱财。
网络钓鱼主要是模仿合法机构的邮件和网页,诱骗受害者提供个人敏感信息,如银行账户、身份证号、银行卡密码等内容,进一步骗取受害者的钱财。根据2016上半年中国反钓鱼网站联盟(APAC)的统计数据,仿冒工商银行、淘宝网的钓鱼网页数量一直处于前列,钓鱼网站涉及的行业中金融类钓鱼网站一直处于前三位,安全形势十分严峻。考虑到金融类网站用户数量庞大,直接关联着用户的金融资产,具有重要的影响力;且钓鱼网页通常会在文字和图片等方面尽可能仿冒金融类网站的官方网页,因此,可以采用对金融类钓鱼网页进行检测的方法来保护用户的财产。
现有的钓鱼网页检测方法主要有黑名单过滤技术、基于页面的启发式检测技术、基于视觉相似性的检测技术等。黑名单过滤技术依赖域名黑名单的及时更新,对检测新出现的钓鱼网页具有滞后性。基于页面的启发式检测技术利用网页的URL特征、页面内容特征进行检测,对页面内容相似的钓鱼网页具有较高的检测率,但部分钓鱼网页使用嵌入图片或者无用的文字来规避页面内容的检测。基于视觉相似性的检测技术利用网页图片相似度或者网页DOM树结构相似度进行检测,对视觉相似性的钓鱼网页具有较高的检测率,但算法复杂且检测效率较低。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于Web页面特征的金融类钓鱼网页检测方法,该方法针对目前十分猖獗的电信诈骗进行钓鱼网页检测,能够提高对钓鱼网页的检测率和检测效率,降低误判率。
为达到上述目的,本发明提供如下技术方案:
一种基于Web页面特征的金融类钓鱼网页检测方法,该方法的执行基于预先建立的金融类第一Title关键词库、第二Title关键词库、敏感关键词库以及网页Logo图片特征点规则库;该方法具体包括以下步骤:
S1:使用爬虫获取的待测网页的HTML,提取Title标签中的文本信息,计算文本信息与第一Title关键词库、第二Title关键词的匹配度,若匹配度大于阈值,判定待测网页为钓鱼网页,否则,进入步骤S2对待测网页做进一步检测;
S2:提取待测网页特定标签中的文本信息,统计文本信息与敏感关键词库的匹配个数,计算出Web敏感特征值,若特征值大于阈值,判定待测网页为钓鱼网页,否则,进入步骤S3对待测网页做进一步检测;
S3:对待测网页进行定点截图,截图尽可能以最小的面积包含待测网页的Logo图片;
S4:提取出Logo截图的特征点,将其与网页Logo图片特征点规则库进行对比,根据特征点的匹配个数计算出两幅Logo图片的相似度,若相似度大于阈值,判定待测网页为钓鱼网页,否则,判定待测网页为正常网页。
作为优选,在步骤S1中,所述使用爬虫获取的待测网页的HTML,提取Title标签中的文本信息,计算文本信息与第一Title关键词库、第二Title关键词的匹配度具体包括:
S11:通过网页爬虫工具,获取待测URL的Web页面Title文本信息,对Title文本做预处理,去除Title文本中的空格与下划线等干扰内容,对预处理后的Title文本使用分词技术进行分词,得到分词个数N0;
S12:将分词后得到的关键词与第一Title关键词库进行匹配,若两者匹配个数N1不小于1,再与第二Title关键词库匹配,也得到匹配个数N2;
S13:通过两次匹配,得到总的关键词匹配数,定义Title关键词匹配度α的大小表示待测网页与金融类网页Title的相似程度;可以根据与第一Title关键词库的匹配情况确定金融类钓鱼网页的具体仿冒对象。
作为优选,在步骤S2中,所述提取待测网页特定标签中的文本信息,统计文本信息与敏感关键词库的匹配个数,计算出Web敏感特征值具体包括:
S21:获取待测网页HTML特定标签的文本信息,包括a标签、h标签以及span标签中的文本信息,预处理所获取的标签文本,并提取有效的文本信息及其条数i;
S22:将每条文本先与敏感关键词库进行第一次匹配,若匹配,则进行下一条文本的匹配,若不匹配,则将该条文本分词后得到的关键词与敏感关键词库进行第二次匹配,只要有一个关键词匹配成功,则进行下一条文本的匹配;
S23:通过一次或者两次匹配可以得到匹配的文本条数j(j≤i),定义Web敏感特征值β的大小反映待测网页文本特征与金融类网页文本特征的相似程度。
作为优选,在步骤S3中,所述对待测网页进行定点截图,截图尽可能以最小的面积包含待测网页的Logo图标具体包括:
S31:调用自动化测试工具,自动打开浏览器获取待测网页,调整浏览器窗口尺寸大小为800*600,该尺寸足够包含网页的Logo;
S32:调用截图工具自动截取浏览器页面上方600*250的区域,该区域能以最小的面积包含所有待测网页的Logo图标,最小的Logo截图能够减小特征点计算量和降低金融类钓鱼网页检测误判率。
作为优选,在步骤S4中,所述提取出Logo截图的特征点,将其与网页Logo图标特征点规则库进行对比,根据特征点的匹配个数计算出两幅Logo图片的相似度具体包括:
S41:利用图像特征点提取算法提取出Logo截图的特征点数据D0,并得到特征点个数k;
S42:从金融类Logo图片特征点规则库中取出一幅Logo图片特征点数据D,D有m个特征点;
S43:使用图像特征点匹配算法计算D0与D相匹配的特征点个数n(n≤k,m);
S44:定义两幅Logo图片的相似度为根据金融类Logo图片特征点规则库的信息确定金融类钓鱼网页的具体仿冒对象。
本发明的有益效果在于:本发明提供的方法可以克服现有技术中类似方法存在的问题,能够提高对钓鱼网页的检测率和检测效率,降低误判率,能够很好的针对目前十分猖獗的电信诈骗进行钓鱼网页检测。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明一种基于Web页面特征的金融类钓鱼网页检测方法的流程图;
图2为本发明一种基于Web页面特征的金融类钓鱼网页检测方法的详细流程图;
图3为本发明Web页面Logo截图的尺寸及位置示意图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图1为本发明提供的基于Web页面特征的金融类钓鱼网页检测方法的流程图,本发明检测方法的执行基于预先建立的金融类第一Title关键词库、第二Title关键词库、敏感关键词库以及网页Logo图片特征点规则库。
具体地,对建立第一Title关键词库与第二Title关键词库的方法进行详细描述:
对多个金融类网页和钓鱼网页HTML的Title标签文本进行分析,提取Title文本中出现的金融类机构的全称、常用简称,形成第一Title关键词库,如中国工商银行的常用简称有工行、工商银行、工银。提取Title文本中与第一Title关键词库形成搭配的常用词语,形成第一Title关键词库,如登录、首页、主页、业务等。第一Title关键词库与第二Title关键词库可形成常用的网页Title,如中国工商银行主页、工行首页等。在向第一Title关键词库、第二Title关键词库中分别添加关键词时都需要进行去重操作,且第一关键词库与第二关键词库没有重合的关键词。
对建立金融类敏感关键词库的方法进行详细描述:
对多个金融类网页和钓鱼网页HTML中的a标签、h标签以及span标签的关键词进行分析,选择敏感程度较高或者表征金融类机构的关键词,如转账汇款、银行卡号、身份证号、金融理财、电子银行等。
对建立金融类网页Logo图片特征点规则库的方法进行详细描述:
使用截图工具对多个金融类网页和钓鱼网页的Logo进行截图,截图的大小与Logo的大小有关。对Logo截图使用图像特征提取算法进行特征点提取,形成网页Logo图片特征点规则库。
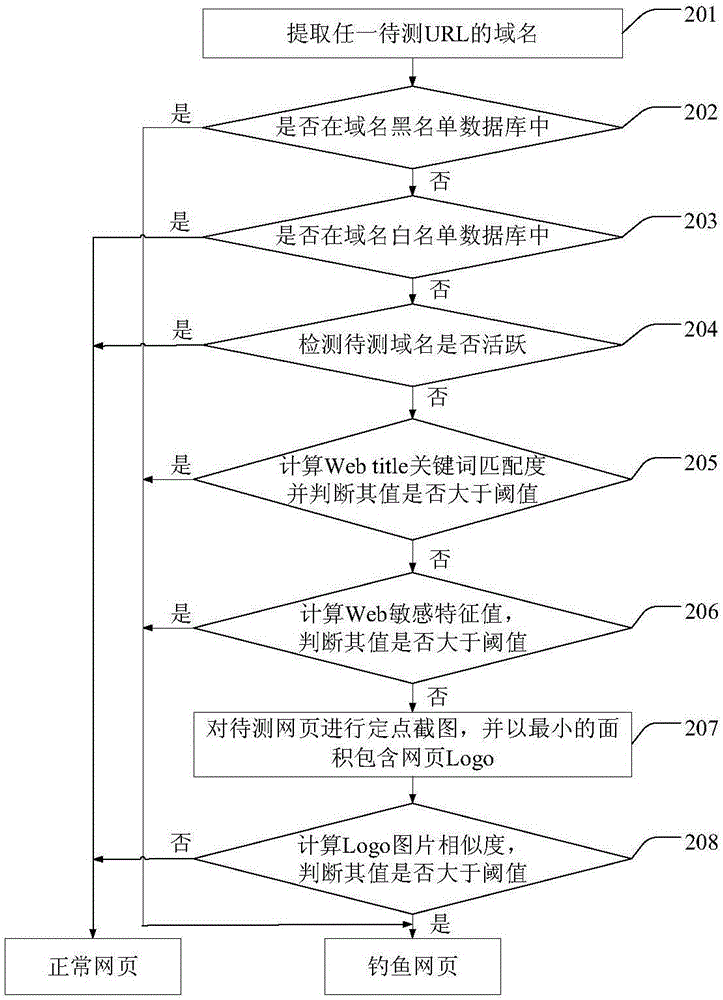
基于上述建立的金融类第一Title关键词库、第二Title关键词库、敏感关键词库以及网页Logo图片特征点规则库,参考图2,图2为本实施例提供的基于Web页面特征的金融类钓鱼网页检测方法流程图,具体包括:
步骤201:从待检测URL中使用正则表达式提取域名,为提高检测的效率,最多提取URL的前三级域名,记为待测域名;
步骤202:将待测域名与域名黑名单数据库进行匹配,域名黑名单由目前已经被中国反钓鱼网站联盟等机构确认的钓鱼网页域名组成,如果黑名单数据库中包含待测域名,则判断待测域名为钓鱼网页使用的域名,否则认为待测域名为可疑的域名,需进行下一步检测;
步骤203:将待测域名与域名白名单数据库进行匹配,域名白名单由常用的网页域名和金融类网页域名组成,如果白名单数据库中包含待测域名,则判断待测域名为正常域名,否则认为待测域名为可疑的域名,需进行下一步检测;
步骤204:基于目前大部分钓鱼网页的存活时间短,可根据域名的活跃度来过滤大部分常用网页,并判断是否需要对待测域名做进一步检测。使用网络爬虫爬取待测域名Alexa访问量排名值,若访问量返回值为空,则认为待测域名为可疑域名,需进行下一步检测。若不为空,计算平均每天的访问量排名,当访问量排名小于某一阈值(意味着访问量排名靠前),则判断待测域名为正常域名,否则认为待测域名为可疑域名,需进行下一步检测;
步骤205:利用爬虫获取待测URL的Web页面,提取待测Web页面的Title标签中的文本,对Title文本进行预处理,如删除文本中的空格、下划线等,并对预处理后的Title文本利用分词技术进行分词,得到分词个数N0。将分词后得到的Title关键词与第一Title关键词库中的关键词进行匹配,得到匹配个数N1。若匹配个数N1为0,则认为待测网页为可疑网页,需进行下一步检测。若匹配个数N1大于等于1,将Title关键词再与第二Title关键词库中的关键词进行匹配,得到匹配个数N2。通过两次匹配得到总的关键词匹配数,计算Title关键词匹配度:
α的大小表示待测网页与金融类网页Title的相似程度。若N0=0或者N1=0,则定义α=0。若匹配度大于某一阈值α*,则判为金融类钓鱼网页,否则认为待测网页为可疑网页,需进行下一步检测。正常金融类网页已经在域名白名单或者域名活跃度检测中进行过滤。α*需要利用金融类钓鱼网页、正常金融类网页以及非金融类正常网页进行训练,使检测率和误判率达到最优。同时可以根据与第一Title关键词库的匹配情况确定金融类钓鱼网页的具体仿冒对象。
步骤206:获取待测网页HTML特定标签的文本信息,包括a标签、h标签以及span标签中的文本信息,预处理所获取的标签文本,并提取有效的文本信息及其条数i。先将每条完整的文本与敏感关键词库进行第一次匹配,若匹配,则进行下一条文本的匹配,若不匹配,则将该条文本分词后得到的关键词与敏感关键词库进行第二次匹配,只要有一个关键词匹配成功,则进行下一条文本的匹配。通过一次或者两次匹配可以得到匹配的文本条数j(j≤i),计算Web敏感特征值:
β的大小反映待测网页文本特征与金融类网页文本特征的相似程度。若i=0,则定义β=0。若特征值大于某一阈值β*,则判为金融类钓鱼网页,否则认为待测网页为可疑网页,需进行下一步检测。正常金融类网页已经在域名白名单或者域名活跃度检测中进行过滤。β*需要利用金融类钓鱼网页、正常金融类网页以及非金融类正常网页进行训练,使检测率和误判率达到最优。
步骤207:调用自动化测试工具,自动打开浏览器获取待测网页,调整浏览器窗口尺寸大小为800*600,该尺寸足够包含网页的Logo图标。调用截图工具自动截取浏览器页面上方600*250的区域,参考图3,该区域能以最小的面积包含所有待测网页的Logo图标,最小的Logo截图能够减小特征点计算量并降低金融类钓鱼网页检测的误判率。
步骤208:利用图像特征点提取算法提取出Logo截图的特征点数据D0,并得到特征点个数k,该图像特征点提取算法与建立网页Logo图片特征点规则库使用的特征点提取算法相同。从金融类Logo图片特征点规则库中取出一幅Logo图片特征点数据D,D有m个特征点。使用图像特征点匹配算法计算D0与D相匹配的特征点个数n(n≤k,m),计算两幅Logo图片的相似度:
γ的大小反映待测网页Logo与金融类网页Logo的相似程度。若特征值大于某一阈值γ*,则判定为金融类钓鱼网页,否则认为待测网页为正常网页。为提高检测效率,当只要出现γ>γ*就停止计算Logo图片的相似度。正常金融类网页已经在域名白名单或者域名活跃度检测中进行过滤。γ*需要利用金融类钓鱼网页、正常金融类网页以及非金融类正常网页进行训练,使检测率和误判率达到最优。同时可以根据金融类Logo图片特征点规则库的信息确定金融类钓鱼网页仿冒的金融机构名称。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其做出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!