一种面向大流量环境的文件还原系统以及方法与流程
本发明涉及通信技术领域,尤其涉及一种面向大流量环境的文件还原系统。
背景技术:
部署在运营商网络中的DPI设备有对用户下载文件进行还原的功能要求,目前通常的方法是DPI设备中协议识别功能和文件还原功能是紧耦合在一起,在一个DPI设备中实现,这样会影响DPI设备的主要功能,导致效率低,但是简单的将协议识别和文件还原分不在不同的设备上运行,来实现高效的性能是不可能的。因为,目前针对文件还原技术,都是针对完整的数据流才能实现对流的文件还原,如果数据流不完整,则无法实现。例如:缺少三次握手数据包、只有一个方向的数据包等情况,现有技术是无法进行还原的。如果在还原方法不变且DPI硬件结构不变的基础上,要实现将协议识别功能和文件还原部分分离开来,那么就需要协议识别处理部分就必须具备以下条件:1)处理的数据必须是双向数据路;2)转发给文件还原服务器的数据流必须是双向数据流,并且是包含三次握手数据包。
在运营上的实际环境中,多数都是采用链路负载均衡的方式进行部署的,不可能确保每条链路的数据都是完整的双向数据流;即使是完整的双向数据流,在将协议识别数来的时候,三次握手数据已经处理过了,无法将完整的数据流转发给文件还原设备。所以,实际上若要将协议识别和文件还原服务独立开来,那么就需要实现以下功能:1)、将运营商的所有链路在流经协议识别服务器前,需要进行数据汇聚处理,安装完整流在分发到不同的协议识别服务器;2)、在协议被识别出来之前,需要对数据包进行缓存,等到协议识别成功后,再将缓存的数据按照接收的顺序转发给文件还原设备。显然,为了满足协议设备与文件还原的分离,需要增加额外的流量汇聚设备,同时协议识别服务器要增加数据包缓存的功能,不仅对内存容量要求提高,还将增加数据的拷贝动作,占用CPU的使用资源。
所以,如果简单的将协议识别和文件还原功能分开部署到两台设备上而又没有改进文件还原技术,会大大增加额外的成本,同时增加了对部署环境的要求。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的上述DPI设备效率低的缺陷,提供一种面向大流量环境的文件还原系统。
本发明解决其技术问题所采用的技术方案是:构造一种面向大流量环境的文件还原系统,包括:
至少一个协议识别服务器,所述协议识别服务器用于数据流识别并将识别出的需要进行文件还原的数据流的原始报文写入识别出的协议类型后转发至文件还原服务器;
文件还原服务器,用于接收所述至少一个协议识别服务器的原始报文,判定数据流的方向,并结合原始报文中写入的协议类型进行文件还原。
在本发明所述的面向大流量环境的文件还原系统中,所述的写入识别出的协议包括:将五元组信息相同的报文作为一个数据流,并将数据流中的第一个原始报文的TOS字段改写为该数据流对应的协议类型。
在本发明所述的面向大流量环境的文件还原系统中,所述的进行文件还原包括:从当前数据流中的第一个原始报文的TOS字段提取协议类型,如果提取出的协议类型的取值符在系统定义的范围之内,则根据判定的数据流的方向建立一个TCP数据流连接以处理该数据流中的所有原始报文,针对每个原始报文按照协议中关于当前数据流的方向的规定,对原始报文进行解析和提取信息进而完成文件还原。
在本发明所述的面向大流量环境的文件还原系统中,判定数据流的方向包括:根据数据流中原始报文的端口数值判定该原始报文来自服务器端口或者客户端端口。
在本发明所述的面向大流量环境的文件还原系统中,所述系统还包括信息存储服务器,用于存储协议识别服务器发送的文件基础信息;
所述文件还原服务器还用于:在文件还原后,判断日志需要的信息是否完整,如果完整则记录日志,否则基于五元组信息从信息存储服务器查询基本信息。
本发明还公开了一种面向大流量环境的文件还原方法,方法包括:
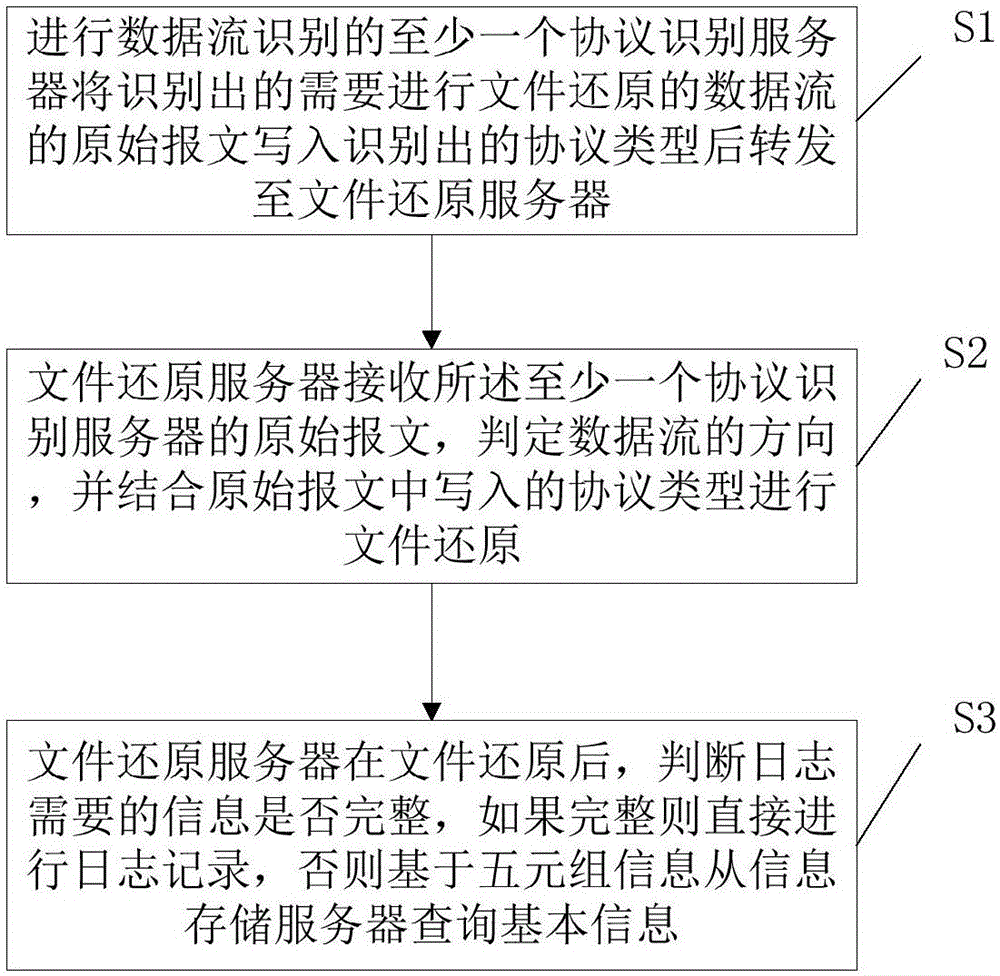
S1、进行数据流识别的至少一个协议识别服务器将识别出的需要进行文件还原的数据流的原始报文写入识别出的协议类型后转发至文件还原服务器;
S2、文件还原服务器接收所述至少一个协议识别服务器的原始报文,判定数据流的方向,并结合原始报文中写入的协议类型进行文件还原。
在本发明所述的面向大流量环境的文件还原方法中,步骤S2中所述的写入识别出的协议包括:将五元组信息相同的报文作为一个数据流,并将数据流中的第一个原始报文的TOS字段改写为该数据流对应的协议类型。
在本发明所述的面向大流量环境的文件还原方法中,步骤S2中所述的进行文件还原包括:
S21、从当前数据流中的第一个原始报文的TOS字段提取协议类型,如果提取出的协议类型的取值符在系统定义的范围之内,则进入步骤S22,否则结束;
S22、根据判定的数据流的方向建立一个TCP数据流连接以处理该数据流中的所有原始报文;
S23、针对每个原始报文按照协议中关于当前数据流的方向的规定,对原始报文进行解析和提取信息进而完成文件还原。
在本发明所述的面向大流量环境的文件还原方法中,步骤S2中所述的判定数据流的方向包括:根据数据流中原始报文的端口数值判定该原始报文来自服务器端口或者客户端端口。
在本发明所述的面向大流量环境的文件还原方法中,方法还包括:
S3、所述文件还原服务器在文件还原后,判断日志需要的信息是否完整,如果完整则记录日志,否则基于五元组信息从信息存储服务器查询基本信息。
实施本发明的面向大流量环境的文件还原系统,具有以下有益效果:
1)、DPI的流识别和文件还原松耦合,文件还原服务器与DPI设备分离,DPI设备作为协议识别服务器专注进行流识别,同样配置的DPI硬件设备,拥有高效的DPI处理能力,可以处理更大的数据流量;
2)、文件还原服务器通过判定数据流的方向,结合原始报文中写入的协议类型进行文件还原,因此支持单向数据流还原、支持没有三次握手报文的TCP流还原;
3)、支持一台文件还原服务器对接多台进行协议识别的DPI设备,部署、扩容都比较灵活。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明的面向大流量环境的文件还原系统的结构示意图;
图2是本发明的面向大流量环境的文件还原方法的程序流程图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
本发明中,DPI设备仅仅执行数据流识别,将识别出的需要进行文件还原的数据流的原始报文写入识别出的协议类型后转发至文件还原服务器;文件还原服务器接收所述至少一个DPI设备的原始报文后,判定数据流的方向,并结合原始报文中写入的协议类型进行文件还原。本发明的还原可以针对非完整的数据或只有单向数据的流还原,在不增加额外成本的情况下,完成协议识别和文件还原的分离,实现设备专用的目的,达到高效的处理性能。
下面以较佳实施例详细说明本发明。
参考图1是本发明的面向大流量环境的文件还原系统的结构示意图。
较佳实施例中,系统包括:至少一个协议识别服务器、文件还原服务器、信息存储服务器。其中:
协议识别服务器:
本发明中协议识别服务器即为原有的DPI设备,DPI设备专注进行数据流识别,并将识别出的需要进行文件还原的数据流的原始报文写入识别出的协议类型后转发至文件还原服务器。如图中,多个DPI设备1-N均将数据转发至同一台文件还原服务器。
具体的,所述的写入识别出的协议包括:将五元组信息(4层协议、源IP、源端口、目的IP、目的端口)相同的报文作为一个数据流,并将数据流中的第一个原始报文的TOS字段改写为该数据流对应的协议类型。
TOS字段作为一个8位的整数使用,其改写不影响还原功能。改写的协议类型是根据具体的场景系统定义的,例如1代表HTTP协议。具体数值对应关系并不做限制。
由于协议识别服务器完成协议识别后,发现需要将该数据流转发到文件还原设备时,会将该流转发的第一个报文的TOS字段改写为该流对应的协议类型,由此,便于文件还原服务器识别,减少文件还原服务器识别的过程,来提高效率。
文件还原服务器:
文件还原服务器用于接收所述至少一个协议识别服务器的原始报文,判定数据流的方向,并结合原始报文中写入的协议类型进行文件还原。
文件还原服务器在进行文件还原时,是根据不同协议的特征,进行对数据包的处理,从而实现数据的还原。每种协议都规定了在客户端发给服务端的数据报文中获取那些信息、在服务器端发给客户端的数据报文中获取哪些数据。所以,要进行还原就必须确定当前数据报文的方向是客户端发给服务器的数据报文还是服务器端发给客户端的报文,在确定数据报文的方向后,才能按照协议规定的还原方法,对数据报文进行解析、提出,最终完成数据报文的还原。
例如,客户端发起一个http下载的网络活动。对该数据流的文件还原应该是从客户端发给服务端的数据报文中提取下载的地址、下载的文件名等信息,从服务端发给客户端的数据报文中提取文件类型、文件大小、文件内容等信息。假如当前文件还原服务器接收到一个客户端发给服务器端的数报文,需要对该报文进行还原处理,如果无法正确的判断当前数据报文的方向,从而导致无法确定是从该数据报文中提取什么信息。如果将数据报文的方向错误判断为服务端发给客户端的数据报文,那么将会按照服务端发给客户端的数据报文处理方式进行处理,比如提取文件类型、文件大小、文件内容等信息,显然这样是无法提取到正确的文件的,这也将导致最终对该数据流的还原失败。
为此,必须判定数据流的方向,较佳实施例中具体为:根据数据流中原始报文的端口数值判定该原始报文来自服务器端口或者客户端端口。因为互联网上公开的服务端口都比较小(例如:http端口80;ftp端口22、21;SMTP端口25;POP3端口110;),而客户发起请求端的端口都比较大,大部分都在10000以上。因此,可以根据端口数值确定报文的方向,无需受限于三次握手的要求。
具体的还原过程为:从当前数据流中的第一个原始报文的TOS字段提取协议类型,如果提取出的协议类型的取值符在系统定义的范围之内,则根据判定的数据流的方向建立一个TCP数据流连接以处理该数据流中的所有原始报文,针对每个原始报文按照协议中关于当前数据流的方向的规定,对原始报文进行解析和提取信息进而完成文件还原。
现有协议栈的TCP数据包的乱序、重组维护,是在接收到SYN数据报文时才创建一个TCP数据流连接,来处理后续的数据包。而单向数据流没有SYN数据包,由于本发明确定当前流的数据方向,来建立一个TCP数据流连接来处理后续的数据包,可以实现对单向数据的乱序重组。
信息存储服务器:
信息存储服务器用于存储协议识别服务器发送的文件基础信息,以五元组信息作为KEY值、基本信息作为VALUE,建立对应关系,并提供查询接口以供文件还原服务器查询。
优选的,文件还原服务器在文件还原后,判断日志需要的信息是否完整,如果完整则记录日志,否则基于五元组信息从信息存储服务器查询基本信息。
例如,针对HTTP协议GET方式下载文件时,协议识别服务器只会将GET的应答转发给文件还原服务器进行文件还原。但是,文件还原服务器在对文件进行还原完成后,记录日志信息时无法知道该文件对应的URL、文件名等基本信息。所以,协议识别服务器需要将这些基本信息存储到信息存储服务器,文件还原服务器通过提供五元组信息即可查询获取相应的基本信息。
相应的,本发明还公开了一种面向大流量环境的文件还原方法。参考图2是本发明的面向大流量环境的文件还原方法的程序流程图。方法包括:
S1、进行数据流识别的至少一个协议识别服务器将识别出的需要进行文件还原的数据流的原始报文写入识别出的协议类型后转发至文件还原服务器;
S2、文件还原服务器接收所述至少一个协议识别服务器的原始报文,判定数据流的方向,并结合原始报文中写入的协议类型进行文件还原。
其中,步骤S2中所述的写入识别出的协议包括:将五元组信息相同的报文作为一个数据流,并将数据流中的第一个原始报文的TOS字段改写为该数据流对应的协议类型。
其中,步骤S2中所述的进行文件还原包括:
S21、从当前数据流中的第一个原始报文的TOS字段提取协议类型,如果提取出的协议类型的取值符在系统定义的范围之内,则进入步骤S22,否则结束;
S22、根据判定的数据流的方向建立一个TCP数据流连接以处理该数据流中的所有原始报文;
S23、针对每个原始报文按照协议中关于当前数据流的方向的规定,对原始报文进行解析和提取信息进而完成文件还原。
其中,步骤S2中所述的判定数据流的方向包括:根据数据流中原始报文的端口数值判定该原始报文来自服务器端口或者客户端端口。
优选的,方法还包括S3:所述文件还原服务器在文件还原后,判断日志需要的信息是否完整,如果完整则记录日志,否则基于五元组信息从信息存储服务器查询基本信息。
综上所述,本发明流识别和文件还原松耦合,文件还原服务器与DPI设备分离,DPI设备作为协议识别服务器专注进行流识别,同样配置的DPI硬件设备,拥有高效的DPI处理能力,可以处理更大的数据流量;文件还原服务器通过判定数据流的方向,结合原始报文中写入的协议类型进行文件还原,因此支持单向数据流还原、支持没有三次握手报文的TCP流还原;支持一台文件还原服务器对接多台进行协议识别的DPI设备,部署、扩容都比较灵活。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!