混淆数据的方法与流程
本发明涉及数据共享应用中的数据混淆,且更具体地说,涉及混淆数据的方法,所述方法提供模糊数据中的抗碰撞性、不可改变性、计算有效性、抗共谋性和伪随机性。
背景技术:
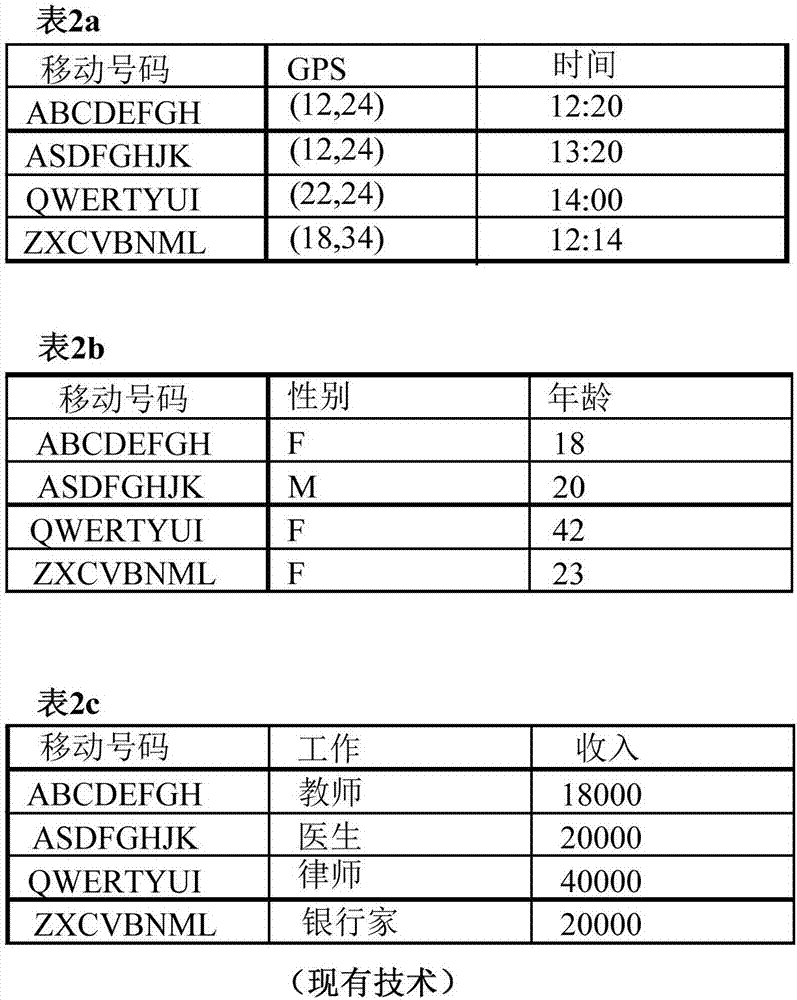
数据共享常见于科学研究以及企业中。电信业务提供商(telecommunicationserviceprovider,tsp)可以获得如图1的表1a到1b所陈列的用户或订户信息。
电信业务提供商可能希望与他们的业务合作伙伴共享此信息,他们的业务伙伴可能希望评估某一位置(12,24)是否适用于建立美容商店。因此,电信业务提供商可以向合作伙伴提供表1a和1b,所述合作伙伴接着检查所述位置周围的人流量模型,特别是他们的目标客户(例如,年轻女性)。然而,按照根据美国国家标准与技术研究所的us标准,移动号码被认为是个人可识别信息(personallyidentifiableinformation,pii)。pii是指能够就其本身而言或与其它信息一起用于识别、联系或定位单个的人或在情境中识别个体的信息。pii可以被看作是关于由代理机构维护的个体的任何信息,包含(1)可以用来辨别或追踪个体的身份的任何信息,例如姓名、社会保障号、出生日期和地点、母亲的婚前姓,或生物标识记录;以及(2)关联到或可关联到个体的任何其它信息,例如医疗、教育、财政和就业信息。
因此,直接共享来自表1a和1b的数据会危及所列用户的隐私,从而可能导致犯罪。从表1a和1b中删除移动号码将解决隐私问题,但是不能提供有用的数据,因为移动号码是用作关联这两个表中的数据的主(关联)密钥。因此,需要数据的混淆。
如果与不同合作伙伴共享的混淆数据相同,那么存在共谋攻击的风险。图2示出了分别与不同合作伙伴共享的表2a到2c。由于提供给不同合作伙伴的已加密移动号码相同,因此合作伙伴可能共谋重建对于每个订户的几乎完整的档案袋,这将侵犯用户隐私。
与数据混淆相关的现有方法在第us2008/0181396a1号美国专利申请公开案(巴拉克里希南(balakrishnan)等人)“使用实体检测和替换的文本数据的数据混淆(dataobfuscationoftextdatausingentitydetectionandreplacement)”和第us2012/0303616a1号美国专利申请公开案(阿布尔萨德(abuelsaad)等人)“使用单向哈希的数据微扰和匿名化(dataperturbationandanonymizationusingonewayhash)”中进行了描述。虽然现有方案对于单次使用可以有效,但是当存在数百万或甚至数十亿行待混淆的数据的情况下现有方案将不会有效。在当今时代,在高速下产生高容量数据,因此需要更有效的混淆方法。
技术实现要素:
本发明的实施例提供一种混淆数据的有效方法和系统,其符合模糊数据中的其它安全需求,包含抗碰撞性、不可改变性、计算有效性、抗共谋性和伪随机性。
根据本发明的一个实施例,提供一种混淆数据的方法。所述方法包括:
通过将单向压缩函数应用于多个辅助输入来产生多个随机数;以及
针对待混淆的每一行数据,反复地:
根据待混淆的每一行数据构建多个数据块,其中预先确定数据块的数目;
产生点积,所述点积通过以下步骤获得:通过将多个数据块中的每一个数据块乘以多个随机数中的专属的一个来产生多个乘积,并对所述多个乘积求和;以及
通过确定取模运算的余数来产生待混淆的每一行数据的混淆形式,使用点积作为被除数以及预先确定的整数作为除数来执行确定取模运算的余数。
所述方法可以进一步包含:
在反复之前,确定整数值和待混淆的多行数据;
使用1-e-l(l-1)/2q确定碰撞的概率,其中q是所确定的整数,l是所确定的待混淆的数据的总行数,且e是自然对数的已知底数(大约等于2.718281828);并且
如果所确定的碰撞概率超过第一预定阈值,调整整数值。
所述方法可以进一步包含:
确定不大于调整后的整数值的数据块长;
基于针对大域的goldreich-levin定理,确定以任何随机数辨别混淆形式的概率;以及
如果所确定的以任何随机数辨别混淆形式的概率超过第二预定阈值,调整调整后的整数值和数据块长。
根据本发明的一个实施例,提供一种混淆数据的系统。所述系统包括:
混淆模块,其可通信地耦合到数据源和随机化模块,
其中所述随机化模块用于通过将单向压缩函数应用于多个辅助输入来产生多个随机数,
其中所述混淆模块用于:
针对待混淆的每一行数据,反复地:
根据待混淆的每一行数据构建多个数据块,其中预先确定数据块的数目;
产生点积,所述点积通过以下步骤获得:通过将多个数据块中的每一个数据块乘以多个随机数中的专属的一个来产生多个乘积,并对所述多个乘积求和;以及
通过确定取模运算的余数来产生待混淆的每一行数据的混淆形式,使用点积作为被除数以及预先确定的整数值作为除数来执行确定取模运算的余数。
在以上实施例中,对单向压缩函数的多个辅助输入可以包含以下中的至少一个:对混淆形式提供不可改变性的秘密密钥、提供抗共谋性的数据合作伙伴标识符、提供灵活性的批次标识符以及对待混淆的每一行数据的随后混淆提供不可关联性的计数器。在以上实施例中,单向压缩函数可以是密码哈希函数和块密码中的一个。
附图说明
下文参考图式公开本发明的实施例,在图式中:
图1示出了表1a和1b,表1a和1b含有其中主(关联)密钥是未混淆的移动号码的订户数据;
图2示出了表2a到2c,表2a到2c待与不同合作伙伴共享并且含有其中主(关联)密钥是混淆移动号码的订户数据;
图3示出了用于执行根据本发明的一个实施例的数据混淆的流程次序;
图4a示出了对一行原始数据的混淆程序的示意性图示;
图4b示出了对多行原始数据的混淆程序的示意性图示;
图5是根据本发明的一个实施例的用于数据混淆的系统的示意性图示。
具体实施方式
下文描述中陈述许多具体细节,以对本发明各实施例进行通彻理解。然而,本领域熟练技术人员将理解,可以在不具有这些具体细节中的一些或全部的情况下实践本发明的实施例。在其它情况下,为了不多余地混淆所描述的实施例的相关方面,并未详细地描述熟知的处理操作。在图式中,所有的几张图以相同参考标号指代相同或相似的功能或特征。
参考图3的流程次序300以及图4a和4b中的示意性图示描述一种混淆数据的方法。
在方块302中,如下通过数据责任人确定或选择用于混淆所需的各种参数:
选择单向压缩函数f。例如,可以选择以密码方式安全哈希函数,例如安全哈希算法sha-256、sha-1、md5。替代地,可以选择块密码,例如高级加密标准(advancedencryptionstandard,aes)。
选择大整数q。大整数q可以是具有64比特的素数。应基于待混淆的数据的总行数l和所需抗碰撞级别选择q的值。可以通过下式计算出碰撞的概率,即寻找映射到一个混淆数据的任何两个原始数据的概率:
1-e-l(l-1)/2q
其中e是自然对数的已知底数(e=2.718281828…)。此界定被称为一般化生日问题。整数q应足够大以确保足够小的计算得出的概率或确保计算得出的碰撞概率小于预定阈值。
选择随机或秘密密钥k。所选密钥应至少是128比特。选择数目n,其对应于待混淆的一行数据被分成的数据块的总数目。高的n值将使安全级提高,但是也将增加计算时间。因此,存在计算有效性与安全性之间的权衡。因此,不同用户应基于用户的实际系统来选择n的值。
在方块304中,通过将单向压缩函数应用于多个辅助输入来产生多个随机数。多个辅助输入可以至少包含对混淆数据提供不可改变性的秘密密钥k(如在方块302中所确定),以及提供抗共谋性的合作伙伴标识符pid(即,识别将接收混淆数据的合作伙伴)。基于辅助输入,将f(辅助输入)计算为多个随机数r1、r2、…、rn。图4a示出了多个随机数r1、r2、…、rn。
在图3的方块306中,对于一行原始或未混淆数据m(具有c比特),根据所述行数据m构建各自具有比特串长h的多个较小的数据块s1、s2、…、sn。将所述行数据分成n块,其中n是在方块302中所确定。图4a示出了多个数据块s1、s2、…、sn。
构建较小数据块的一种可能方式是将m的第一h比特设置为s1,将m的第二h比特设置为s2,…,将m的第(n-1)h比特设置为sn-1,并且使m的剩余比特以零填补以形成h比特的串sn。
随后,基于
在方块308中,产生点积,所述点积通过以下步骤获得:通过将多个数据块中的每一个数据块乘以多个随机数中的专属的一个来产生多个乘积,并对所述多个乘积求和。例如,将第i位置处的数据块乘以第i位置的随机数。在将数据块和随机数的对相乘之后,对自其所得的多个乘积求和或相加。
在方块310中,通过确定取模运算的余数来产生所述行数据m的混淆形式,使用在方块308中所产生的点积作为被除数以及预先确定的整数值q作为除数来执行确定取模运算的余数。接着可将混淆形式存储在另一表或数据库中。
在方块312中,流程次序检查是否有待混淆的另一行数据。如果没有待混淆的另一行数据,流程次序前进到方块314中的结束。如果存在待混淆的另一行数据,对下一行数据重复方块306到310。
执行方块306到312的反复直到混淆了所有指定行数据。应了解,同一批次内的每一行数据的混淆包括重复使用在方块304中确定的多个随机数。
图4b是对于多行数据m1、m2、…、ml的混淆程序的示意性图示。如图4b中所示以及上文所示,基于所选压缩函数和接收到的辅助输入产生多个随机数。对于待混淆的每一行数据,在每次产生点积时应用相同多个随机数,并且根据其结果执行取模运算。因此,反复地,个别地产生每一行数据的混淆形式,并且可以将所述混淆形式输出到混淆数据的表或数据库。
在上述流程次序中,对单向压缩函数的辅助输入可以至少包含秘密密钥k和合作伙伴标识符pid。在某些其它实施例中,辅助输入可以另外包含批次标识符bid和计数器中的至少一个。
参考图3的流程次序300描述的以上程序可以作为程序指令提供。因此,在本发明的一个实施例中,提供一种计算机程序产品,其包括非暂时性计算机可读介质,所述非暂时性计算机可读介质包括计算机可读程序,其中所述计算机可读程序当由计算机上的微处理器执行时致使计算机执行参考图3的流程次序300描述的程序。
图5是用于数据混淆的系统的示意性图示,所述系统可以并入计算系统中。所述用于数据混淆的系统包括可通信地耦合到数据源和随机化模块的混淆模块,其中数据源和/或随机化模块可以位于混淆模块本地或远程。
随机化模块用于通过将单向压缩函数应用于多个辅助输入来产生多个随机数r1…rn,所述多个辅助输入可以至少包含秘密密钥k和数据合作伙伴标识符pid。混淆模块用于:针对待混淆的每一行数据m,反复地:根据待混淆的每一行数据构建多个数据块s1…sn,其中预先确定数据块的数目n;产生点积,所述点积通过以下步骤获得:通过将多个数据块中的每一个数据块乘以多个随机数中的专属的一个来产生多个乘积,并对所述多个乘积求和;以及通过确定取模运算的余数来产生待混淆的每一行数据的混淆形式,使用点积作为被除数以及预先确定的整数值作为除数来执行确定取模运算的余数。
混淆模块进一步用于:在反复之前,确定整数值和待混淆的多行数据;使用1-e-l(l-1)/2q确定碰撞的概率,其中q是所确定的整数,l是所确定的待混淆的数据的总行数,且e是自然对数的已知底数(大约等于2.718281828);并且如果所确定的碰撞概率超过第一预定阈值,调整整数值。
混淆模块进一步用于:确定不大于调整后整数值的数据块长h;基于针对大域的goldreich-levin定理,确定以任何随机数辨别混淆形式的概率;以及如果所确定以任何随机数辨别混淆形式的概率超过第二预定阈值,进一步调整调整后的整数值和数据块长h。
应用1:原始数据m是128比特的密文
使用与图2的表2a到2c相关的上述实例,电信业务提供商(数据责任人)想要与合作伙伴共享其订户的gps位置,因此,采用本公开内容的发明来混淆表2a到2c的已加密移动号码(其是主密钥)。
在本申请中,适用可能的最有效的实施方案。参数确定如下:c=128,n=2,h=64,q=264。数据责任人选择128比特秘密密钥k和压缩函数f作为sha256哈希函数。
可以如下所示执行混淆程序:
(1)将随机数计算为两个64比特数(r1,r2)=f(k,pid,bid)。
(2)对于每一行数据:
a.将已加密移动号码mi的第i行分成两个64比特数(ai,bi)。
b.输出hi=r1*ai+r2*bimodq。
应注意在本申请中,原始数据是密文。对于有效实施方案,应基本上均匀地分布原始数据。安全密文的分布符合安全需求。
应用2:原始数据m具有至少148比特熵。
在本申请中,原始数据m是任意(已加密或未加密)消息。为了确保混淆输出的不可预测,原始数据m应具有至少148比特的熵。
例如,在电子邮件业务提供商的用户姓名的数据库中,电子邮件地址具有用户名@域名(username@domain)的格式,其中用户名m可以长达64个字符。允许的用户名至少包含52个大写和小写英文字母、10个数字和20个特殊字符(对于英文电子邮件地址)。因此,可能的用户名数目将为(52+10+20)64=2406。如果用户名的平均长度超过23,用户名将具有超过148比特的熵。如果电子邮件业务提供商想要共享存储于数据库中的若干表中的信息,其中表的主密钥是电子邮件地址,电子邮件业务提供商可以执行混淆程序如下所示:
(1)如在方块302中计算素数q的最小可接受值。此处,假设如从块302所确定的q=128。
(2)选择小于或等于q的值h。如在方块306中将原始数据m分成具有如(s1,…,sn)的长h的比特串的n块。在此实例中每个字符通常以8比特存储,这意味着m具有512比特。此处,假设h=16,并且n=512/16=32。
(3)根据针对大域的以下goldreich-levin定理(叶夫根尼·多迪(yevgeniydodis)、沙菲·戈德瓦塞尔(shafigoldwasser)、雅艾尔·莱(yaelkalai)、克里斯·佩克特(chrispeikert)和维诺德·瓦伊昆塔南森(vinodvaikuntanathan),具有辅助输入的公开密钥加密方案(public-keyencryptionschemeswithauxiliaryinputs),tcc网页361-381,2010年)计算概率ε。
定理1:假设q是质数并且假设h是gf(q)的任意子集。假设f:hn{0,1}*是任何(可能随机的)函数。如果存在在时间t运行的标识d使得
|pr[s←hn,y←f(s),r←gf(q)n:d(y,r,<r,s>)=1]
-pr[s←hn,y←f(s),r←gf(q)n,u←gf(q)n:d(y,r,u)=1]|=ε
将存在在以下时间运行的逆变器a
t'=t·poly(n,|h|,1/ε)
因此
根据此定理应用上述参数,将确定
(4)如果以随机数辨别混淆输出的此概率ε太大,那么可以选择更大的h(对应于更小的n)并且可以重新考虑q的值。(更大的q允许更小的n,但是其使ε更大)。基于h和q的调整后的值,根据针对大域的goldreich-levin定理重复以上概率分析。
(5)一旦设置了参数,就可以如方块306到312中所描述的执行混淆程序。
在本发明的实施例中,用于混淆l行数据的计算开销,即用于混淆m1、…、ml的计算开销包括用以产生随机数的压缩函数的计算(例如,哈希计算)、n倍乘法和(n-1)倍加法模数q。因此,本发明提供一种有效的混淆方法,其允许将计算得出的压缩函数(随机数)重复用于数据混淆的每一次反复。
本发明还符合其它安全需求,尤其是:
·正确性/抗碰撞性:一个原始数据应始终对应于一个混淆数据,具有绝对概率。在安全压缩函数(例如,密码哈希函数)和整数q较大的情况下,这在本发明中是可能的。此外,当选择参数时可以确定碰撞的概率的可接受性。
·不可改变性:给定混淆数据,在使用密码哈希函数和秘密密钥的情况下在计算上将很难恢复原始数据。例如,如果待混淆的数据是移动电话号码并且未使用秘密密钥作为辅助输入,攻击者将更容易根据混淆数据推断原始数据。然而,如果使用通常为大数目并且仅数据责任人知道的秘密密钥,攻击者将不得不推断秘密密钥来对混淆数据执行任何攻击。因此,秘密密钥用作辅助输入将提供并促进对混淆形式/数据的不可改变性。
·有效性:混淆方法应是有效的。由于随机数可以重复用于相同批次中的其它行数据,因此这在本发明中是可能的。因此,计算开销包括压缩函数的计算(例如,哈希计算)、n倍乘法和(n-1)倍加法模数q。
·抗共谋性:如果数据共享到不同合作伙伴,不同合作伙伴获得的混淆数据应不相同。在安全压缩函数(例如,密码哈希函数)和攻击者获得的h值的数<(l+p)n-1的情况下,其中p是不同合作伙伴的数目,这在本发明中是可能的。这些h值表示使用与p个合作伙伴共享的相同组原始数据m1、m2、...ml计算得出的输出h1、h2、...hl的总数目。此外,如果数据合作伙伴标识符指定为用于产生随机数的输入中的一个,混淆数据将是抗共谋性的。
灵活性:如果针对相同合作伙伴分批地共享数据,取决于应用,以不同批次获得的混淆数据可以相同或不同。参考图2的表2a,例如,数据合作伙伴可能希望对某一时间某一位置处的人数进行计数,或追踪所述区域中人的移动。在前一应用中,第二批次的混淆数据应含有以与第一批次不同的方式混淆的移动号码以确保更高用户隐私。在后一应用中,第二批次的混淆数据应含有以与第一批次相同的方式混淆的移动号码。在本发明中,如果批次标识符指定为用于产生随机数的辅助输入中的一个,以不同批次获得的混淆数据可以不同,由此提供在需要时改变混淆数据的灵活性。此外,在将至少两次或更多次地对相同组原始数据m执行混淆的某些应用中,辅助输入可以包含在相同组原始数据的每次随后的混淆之后递增的计数器。因此,一组原始数据m的第一混淆数据将随着相同组原始数据m的每次随后的混淆而不同。通过简单地检查不同混淆数据,攻击者将不能够确定对相同组原始数据的关联性。因此,使用计数器作为辅助输入提供了对相同原始数据的随后混淆的不可关联性。本领域的技术人员根据对本说明书的考量和对实施例的实践将清楚其它实施例。此外,出于描述明确性的目的使用了某些术语且这些术语不会限制本发明的所公开实施例。上文描述的实施例和特征应视为示例性的。
- 还没有人留言评论。精彩留言会获得点赞!