三维内容生成装置及其三维内容生成方法与流程
与示例性实施例一致的装置和方法涉及一种三维(3d)内容生成装置及其三维内容生成方法,更具体地,涉及一种被配置为基于对象的特征点的检测来生成三维内容的三维内容生成装置及其三维内容生成方法。
背景技术:
近来,在检测和识别视频图像中对象的脸部方面已经进行了许多研究。从二维(2d)图像中识别具有三维(3d)形状的脸部在诸如脸部识别、脸部表情识别、图像建模等各种技术领域中是非常重要的。然而,由于二维图像不包括对象的深度信息,因此从二维图像识别三维脸部形状是非常困难的。
各种方法来可以被用来执行3d脸部建模。例如,可以使用3d相机来获得红色、绿色和蓝色(rgb)图像和深度图。然而,由于3d相机非常昂贵,所以使用2d相机的立体匹配方法被广泛使用。尽管如此,立体匹配方法的局限在于需要至少两台2d相机。
另外,恢复脸部比恢复对象的其他区域要困难得多。这是因为脸部的颜色分布基本上是均匀的,没有足够的特征点,并且当获得对象的图像时,对象的脸部表情可能会发生改变。
因此,期望一种不需要多台2d相机或者不需要3d相机就能够稳定地恢复3d脸部图像的技术。
技术实现要素:
一个或更多个示例性实施例提供了一种基于检测对象的特征点来生成三维(3d)内容的三维内容生成装置及其三维内容生成方法。
根据示例性实施例的一个方面,提供了一种三维(3d)内容生成装置,包括:输入器,被配置为接收对象的多幅图像,所述多幅图像被采集自不同位置;检测器,被配置为从所述多幅图像中的每幅图像中识别所述对象并且检测所述对象的特征点;图形成器,被配置为提取检测到的特征点的3d位置信息,并且被配置为基于提取出的所述特征点的所述3d位置信息来形成针对所述对象的表面的至少一个深度图;以及内容生成器,被配置为基于所述至少一个深度图和所述多幅图像来生成所述对象的3d内容。
所述装置还可以包括位置确定器,所述位置确定器被配置为基于所述对象的提取出的所述特征点的所述3d位置信息来确定采集所述多幅图像中的每幅图像的采集位置,其中,所述内容生成器被配置为基于所确定的采集位置来生成所述对象的所述3d内容。
所述检测器可以将所学习的所述对象的模型应用于所述多幅图像并且检测所述对象的所述特征点。
所述检测器可以通过使用所述多幅图像、所确定的采集位置和检测到的所述特征点中的至少一个来更新所述对象的所述模型,并且可以通过将更新后的所述模型应用于随后输入的图像来检测所述特征点。
所述内容生成器可以基于检测到的特征点的排列形状和所确定的采集位置中的至少一个来从所述多幅图像中选择图像,并且可以通过使用所选择的图像来恢复所述对象的至少一个预先确定的部分的纹理,从而生成所述3d内容。
所述内容生成器可以基于检测到的特征点的所述排列形状和所确定的采集位置中的至少一个从所述多幅图像中选择至少两幅图像,并且可以通过使用所选择的至少两幅图像来恢复除了所述预先确定的部分之外的部分的纹理,从而生成所述3d内容。
所述对象可以包括人的头部,并且所述检测器可以将所学习的人脸模型应用于所述多幅图像并且检测脸部的所述特征点。
所述检测器可以通过使用所述多幅图像、所确定的采集位置和检测到的脸部的所述特征点中的至少一个来更新脸部模型,并且可以通过将更新后的所述脸部模型应用于随后输入的图像来检测脸部的所述特征点。
所述内容生成器可以基于检测到的脸部的所述特征点的排列形状和所确定的采集位置中的至少一个来从所述多幅图像中选择图像,并且可以通过使用所选择的图像来恢复与眉毛对应的区域、与眼睛对应的区域、与鼻子对应的区域以及与嘴巴对应的区域中的至少一个区域的纹理,从而生成所述3d内容。
所述内容生成器可以基于检测到的脸部的所述特征点的所述排列形状和所确定的采集位置中的至少一个来从多幅图像中选择至少两幅图像,并且通过使用所选择的至少两幅图像来恢复除了与所述眉毛对应的所述区域、与所述眼睛对应的所述区域、与所述鼻子对应的所述区域以及与所述嘴巴对应的所述区域之外的区域的纹理,从而生成所述3d内容。
所述图形成器可以基于检测到的特征点的分布和所确定的采集位置中的至少一个来从所述多幅图像中选择图像,以及基于从所选择的图像中提取出的深度信息来形成所述深度图;所述内容生成器可以确定体素立方体的体积(所述体素的体积等于或大于所述对象的体积),基于所学习的所述对象的模型来旋转所述体素立方体,以及向所述对象的至少一个预先确定的部分应用相比于除了所述预先确定的部分更高的分辨率。
所述图形成器可以通过在所述多幅图像中的至少两幅图像之间进行立体处理来形成所述深度图;以及基于从所述至少两幅图像中检测到的所述特征点的所述3d位置信息和采集所述至少两幅图像的采集位置中的至少一个,来确定用于所述立体处理的块的尺寸。
所述图形成器基于所述特征点的所述3d位置信息来确定针对所述对象的表面的深度范围,并且基于所确定的深度范围形成所述深度图。
所述内容生成器可以基于所述特征点的所述3d位置信息确定所述对象的体积,并且基于所确定的体积来生成所述3d内容。
所述多幅图像是通过使用单目相机在所述不同位置对所述对象进行采集而获得的。
根据另一实施例的一个方面,提供了一种3d内容生成方法,包括:接收对象的多幅图像的输入,所述多幅图像被采集自不同位置;从所述多幅图像中的每幅图像中识别所述对象并且检测所述对象的特征点;提取检测到的特征点的3d位置信息,并且基于提取出的所述特征点的所述3d位置信息来形成针对于所述对象的表面的至少一个深度图;以及基于所述至少一个深度图和所述多幅图像来生成所述对象的3d内容。
所述方法还可以包括基于所述特征点的所述3d位置信息,确定采集所述多幅图像中的每幅图像的采集位置,其中所述生成包括基于所确定的采集位置来生成所述对象的所述3d内容。
所述检测可以包括将所学习的所述对象的模型应用于所述多幅图像,从而检测所述对象的所述特征点。
所述检测可以包括通过使用所述多幅图像、所确定的采集位置和检测到的所述特征点中的至少一个来更新所述对象的所述模型,以及通过将更新后的所述模型应用于随后输入的图像来检测所述特征点。
所述生成可以包括基于检测到的特征点的排列形状和所确定的采集位置中的至少一个来从所述多幅图像中选择图像,并且可以通过使用所选择的图像来恢复所述对象的至少一个预先确定的部分的纹理。
所述生成可以包括基于检测到的特征点的排列形状和所确定的采集位置中的至少一个来从所述多幅图像中选择至少两幅图像,并且通过使用所选择的至少两幅图像来恢复除了所述预先确定的部分之外的部分的纹理。
所述对象可以包括人的头部,所述检测可以包括将所学习的人脸模型应用于所述多幅图像从而检测脸部的所述特征点。
所述检测可以包括通过使用所述多幅图像、所确定的采集位置和检测到的脸部的所述特征点中的至少一个来更新所述脸部模型,并且可以通过将更新后的所述脸部模型应用于随后输入的图像来检测脸部的所述特征点。
所述生成可以包括基于检测到的脸部的特征点的排列形状和所确定的采集位置中的至少一个来从所述多幅图像中选择图像,并且可以通过使用所选择的图像来恢复与眉毛对应的区域、与眼睛对应的区域、与鼻子对应的区域以及与嘴巴对应的区域中的至少一个区域的纹理,从而生成所述3d内容。
所述生成可以包括基于检测到的脸部的特征点的排列形状和所确定的采集位置中的至少一个来从所述多幅图像中选择至少两幅图像,并且通过使用所选择的至少两幅图像来恢复除了与所述眉毛对应的区域、与所述眼睛对应的区域、与所述鼻子对应的区域以及与所述嘴巴对应的区域之外的区域的纹理,从而生成所述3d内容。
所述形成所述深度图可以包括基于检测到的特征点的分布和所确定的采集位置中的至少一个来从所述多幅图像中选择图像;以及基于从所选择的图像中提取出的深度信息形成所述深度图;确定体素立方体的体积,所述体积等于或大于所述对象;基于所学习的所述对象的模型旋转所述体素立方体;以及向所述对象的至少一个预先确定的部分应用相比于除了所述预先确定的部分之外的部分更高的分辨率。
所述形成所述深度图可以包括通过在所述多幅图像中的至少两幅图像之间进行立体处理来形成所述深度图;以及基于从所述至少两幅图像中检测到的所述特征点的所述3d位置信息和采集所述至少两幅图像的采集位置中的至少一个,来确定用于所述立体处理的块的尺寸。
根据又一实施例的一方面,提供了存储程序的非暂时性记录介质,所述程序在由计算机执行时使所述计算机执行3d内容生成方法,所述3d内容生成方法包括:接收对象的多幅图像的输入,所述多幅图像被采集自不同位置;从所述多幅图像中的每幅图像中识别所述对象并且检测所述对象的特征点;提取检测到的特征点的3d位置信息,并且基于提取出的所述特征点的所述3d位置信息形成针对所述对象的表面的至少一个深度图;以及基于所述至少一个深度图和所述多幅图像生成所述对象的3d内容。
附图说明
通过参照附图描述特定示例性实施例,上述方面和/或其他方面将变得更加明显,其中:
图1是示出了根据示例性实施例的三维内容生成装置的框图;
图2是用于说明根据示例性实施例配置的脸部网格的视图;
图3是用于说明根据示例性实施例的其形状已被恢复的模型的视图;
图4、图5、图6a、图6b、图6c、图6d和图6e是用于说明根据各种示例性实施例的纹理恢复方法的视图;
图7是用于说明根据示例性实施例的三维生成装置的3d建模的数据处理流水线的视图;
图8是用于说明根据示例性实施例的三维内容生成方法的流程图。
具体实施方式
在下文中,参照附图更详细地描述了示例性实施例。
在下面的描述中,除非另外说明,否则在不同的附图中描述时,相同的附图标记用于表示相同的元件。提供了描述中限定的事物,诸如详细的构造和元件,以帮助全面理解示例性实施例。因此,可以理解的是,可以在没有那些具体限定的事物的情况下实施示例性实施例。此外,将不会对相关技术中已知的功能或元件进行详细描述,因为它们会以不必要的细节模糊示例性实施例。
术语“第一”、“第二”.…..可以用于描述不同的组件,但是组件不应当受术语的限制。术语仅用于将一个组件与其他组件进行区分。
本文所使用的术语仅用于描述示例性实施例,而不旨在限制本公开的范围。只要在上下文中不是不同的含义,单数表述还包括复数含义。在说明书中,术语“包括”和“由......组成”指定写入说明书中的特征、数目、步骤、操作、组件、元件或其组合的存在,但不排除存在或者可以添加一个或更多个其他特征、数目、步骤、操作、组件、元素或其组合。
在示例性实施例中,“模块”或“单元”执行至少一个功能或操作,并且可以以硬件、软件或硬件和软件的组合来实现。另外,除了必须用特定硬件实现的“模块”或“单元”之外,可以将多个“模块”或多个“单元”集成到至少一个模块中,并且可以用至少一个处理器(未示出)来实现。
图1是用于说明根据示例性实施例的三维(3d)内容生成装置的配置的框图。
参照图1,三维内容生成装置100包括输入器110、检测器120、图形成器130和内容生成器140。三维内容生成装置100可以被实现为各种装置,诸如智能电话、电视机(tv)、笔记本式个人电脑(pc)、平板电脑、电子书、电子相框、自助服务终端等。
输入器110接收从不同位置采集到的对象的多幅图像。在本文中,多幅图像可以包括对象的静止图像(或帧),并且可以构成视频。
输入器110可以被实现为相机或接收从外部相机采集到的图像的通信接口。
在输入器110被实现为通信接口的情况下,输入器110可以包括各种通信芯片,诸如无线保真(wi-fi)芯片、蓝牙(bluetooth)芯片、近场通信(nfc)芯片、无线通信芯片等。wi-fi芯片、蓝牙芯片、nfc芯片可以分别用于使用wi-fi方法、蓝牙方法和nfc方法进行通信。nfc芯片是指通过使用在射频识别(rfid)的诸如135khz、13.56mhz、433mhz、860-960mhz和2.45ghz的各种频带中的13.56mhz频带来进行nfc通信的芯片。在使用wi-fi芯片或蓝牙芯片的情况下,可以首先发送和/或接收诸如服务集标识符(ssid)、会话密钥等各种连接信息,然后可以通过使用该连接信息来发送和/或接收各种信息。无线通信芯片是指根据以下各种通信标准进行通信的芯片,诸如电气和电子工程师协会(ieee)、紫蜂协议(zigbee)、第三代(3g)、第三代合作伙伴计划(3gpp)、长期演进(lte)等。
在输入器110被实现为相机的情况下,输入器110可以包括透镜和图像传感器。透镜的类型可以包括通用透镜、光学角度透镜、变焦透镜等。相机的镜头的类型可以根据3d内容生成装置100的类型、特点、使用环境等来确定。相机的图像传感器的示例可以包括互补金属氧化物半导体(cmos)、电荷耦合器件(ccd)等。
在示例性实施例中,可以通过由单目相机获得的二维(2d)图像来生成3d内容。也就是说,根据示例性实施例,避免了对多个相机的需求。因此,3d内容生成装置100可以被实现为在其中嵌入单目相机的装置(例如,智能电话)。
检测器120可以基于拍摄对象的多幅图像中的至少一幅来识别对象。例如,检测器120可以通过从多幅图像中的至少一幅图像中提取对应于对象的区域且将所提取的区域与预先存储的有关对象的信息进行比较来识别对象。例如,检测器可以通过将与从图像中提取出的对象对应的区域和预先存储的有关人的脸部的信息进行比较,来识别包括在图像中的对象是人的脸部。为了识别图像中的对象,可以使用各种常规方法。因此,将省略详细说明。检测器120可以从通过输入器110输入的多幅图像中的每幅图像检测对象的预先确定的特征点。
具体而言,检测器120可以根据所识别的对象提取对于对象来说是特别的特征点。
例如,即使对象的形状、尺寸、位置发生了变化,但是仍然能够很容易地被识别出的点,以及即使相机的视角和光线发生了变化,但是仍然能够很容易地从图像中找到的点,可以被判定为特征点。
检测器120可以将所学习的对象的模型应用于多幅图像并检测特征点。所学习的对象的模型指示重复进行以下操作的结果:输入关于对象的多幅图像(例如,当对象是人的手部时,为拍摄了各种人的手部的图像);从每幅图像手动地或者自动地选择预设的特征点;以及参照多幅图像,输入关于所选择的特征点的信息。
当假定多幅图像对应于人的头部的图像时,检测器120可以检测每幅图像的脸部特征点。
检测器120可以将针对人的脸部学习的脸部模型应用于通过输入器110输入的多幅图像,并且检测脸部特征点。脸部特征点是指脸部的特征点,诸如,例如眼睛、眉毛、鼻子、上唇、下唇、下颌轮廓等。可以将以下操作的结果获得为针对人的脸部学习的脸部模型:输入通过采集人的脸部而获得的图像;手动或自动地从每幅图像确定关于眼睛、眉毛、鼻子、上唇、下唇、下颌轮廓等的特征点;以及输入针对多幅图像中的每幅图像的关于脸部区域的表示所确定的特征点的相应信息。可以通过使用相关领域技术人员熟知的机器学习技术来执行上述过程,因此将省略对该过程的详细说明。
所学习的脸部模型可以包括可以从在学习中使用的脸部的图像中提取出的信息,即,基于脸部特征点的位置的脸部特征的3d信息和颜色信息、关于所采集的图像的颜色的信息、关于所采集的图像的纹理的信息、关于所采集对象的位置的信息(或者关于相机的位置的信息)等。
检测器120可以通过所学习的脸部模型的各种算法从图像中自动检测脸部特征点。例如,可以使用诸如主动外观模型(aam)或主动形状模型(asm)的算法。
asm是这样一种模型:该模型检测眼睛的位置,并且基于检测到的眼睛的位置,通过使用形状信息来确定其他区域(例如,鼻子、嘴巴、眉毛等)的位置。而aam是不仅基于形状信息还基于纹理信息来检测能够有效地解释脸部特征的脸部特征点的模型。
aam通过对脸部模型向量和脸部表面纹理应用主成分分析(pca),来对基于各种人的脸部统计提供的标准脸部模型进行变形,以使标准化的脸部数据和归一化的2d脸部数据的误差平方最小。使用标准化的脸部数据和归一化的2d脸部数据,在aam中找到脸部特征点。aam具有的优点在于aam可以提供快速的计算速度和跟踪特征。
在使用aam的情况下,检测器120可以执行检测关于包括在输入图像中的脸部的眼睛、眉毛、鼻子、上唇、下唇和/或下颌轮廓的特征点的拟合操作。
在这种情况下,可以执行拟合从而最小化或减少由下面的等式1表示的成本函数。
【等式1】
ef=e2d(p,q)+α·etx(p,q)+β·e3d(p,q,k,p,x).
在本文中,ef是成本函数,e2d是所采集的脸部图像的2d平均模型与该2d平均模型的变形的外观之间的差值。使用形状参数p和q。etx是所采集的图像的纹理与所选择的图像的变形的模板脸部纹理之间的差值,所选择的图像被称为关键帧。关键帧的详细讨论将在下文提供。α是etx的加权值。另外,e3d是2d形状与投影在2d平面上的参考3d脸部模型的形状x之间的几何差值,其中使用了关于采集脸部图像的相机的固有参数k和外部参数p。β是e3d的加权值。
检测器120可以基于脸部特征点并且也可以基于与特征点对应的一个或更多个图像的采集位置来更新脸部模型,并且可以将更新后的脸部模型应用于随后输入的图像。因此,由于可以通过机器学习将当前正在采集的对象的特征反映在将要应用于随后的图像的脸部模型上,所以可以提高检测特征点的精度。
在本文中,更新后的脸部信息不仅可以包括所学习的脸部模型的2d或3d点的位置和颜色信息,而且更新后的脸部信息还可以包括关于基于以下信息生成的有关3d点、网格位置、尺寸和颜色的信息:先前所获得的多幅采集到的图像的位置信息;先前所获得的多幅采集到的图像的颜色信息;先前所获得的多幅图像的纹理信息。
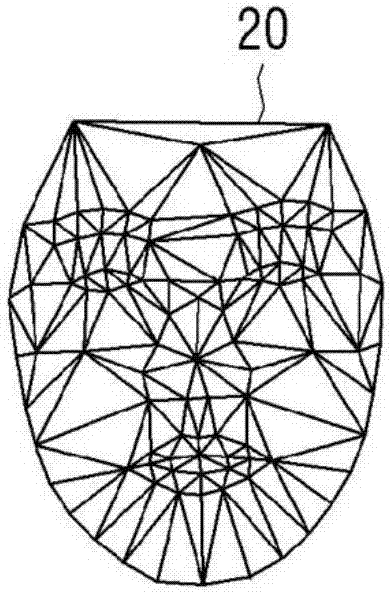
图2是用于说明根据示例性实施例配置的脸部网格的视图。参照图2,检测器120可以配置脸部网格20,该脸部网格20包括如图2所示连接的检测到的特征点的网格三角形。基于脸部网格20,检测器120可以识别采集到的图像内的脸部的角度和尺寸。
更具体地,等式1中的外部参数p可以包括关于脸部的角度的信息,脸部网格三角形的尺寸或者外部参数p的值包括关于脸部的尺寸的信息。
更具体地,检测器120可以使用特征点的位置来获得脸部左侧的面积大小和脸部右侧的面积大小。在本文中,检测器120使用位于前额中间的特征点的位置、表示脸部轮廓的特征的位置、与鼻尖部分对应的特征点的位置以及诸如唇部周围特征点的位置的有代表性的特征点的位置,来获得脸部右侧的面积大小和脸部右侧的面积大小。
更具体地,检测器120可以基于有代表性的特征点的位置来确定网格三角形,并且计算网格三角形的面积大小的总和,从而获得脸部左侧的面积大小和脸部右侧的面积大小。然后,检测器120可以根据脸部左侧的面积大小与脸部右侧的面积大小的比率来检测脸部的角度信息。
以这种方式,检测器120可以沿偏航、俯仰和滚动方向检测关于脸部角度的信息。沿滚动、俯仰和偏航方向的关于脸部角度的信息可以对应于相对于x、y和z轴的旋转角度。
此外,3d内容生成装置100还可以包括确定采集每幅图像的相机的位置(即,相机位姿)的位置确定器(未示出)。
位置确定器可以基于通过采集到图像中的脸部网格、3d特征点的分布以及2d位置计算出的脸部的角度和尺寸,来确定采集图像的相机的位置。
在另一示例性实施例中,3d内容生成装置100可以以使用单目相机的立体视觉方法来形成3d点云,并确定相机的位置。
更具体地,位置确定器可以使用立体匹配处理方法,该立体匹配处理方法使用两幅图像来检测这两幅图像之间的对应部分,由此确定相机针对每幅图像的相对位置,从而确定相机的位置。
更具体地,位置确定器可以通过比较和分析所采集的图像的特征点的2d位置和已注册的特征点的3d位置来确定每个相机的绝对位置,由此确定相机的位置。
在本文中,特征点是指可以与图像的特征对应的点。不仅可以使用以前学习过的脸部特征点,而且可以使用通过立体处理添加的任何点来作为特征点。
然而,针对具有均匀颜色分布的对象(诸如脸部),当使用基于检测到的特征点的比较来确定相机位置的方法时,由于对象的颜色相似度,可能出现将不同特征点感知为相同特征点的误差。例如,在从第一图像中仅能看到脸部右侧而看不到脸部左侧的情况下,在从第二图像中仅能看到脸部左侧而看不到脸部右侧的情况下,根据两幅图像的颜色相似度,可能出现在图像之间确定共同特征点的误差。
因此,在示例性实施例中,为了减小该误差,来自不同图像中的被预测为不是共同特征点的特征点被排除掉,而仅提取有效特征点。
更具体地,在被注册在3d点云中的特征点中,仅提取如上所述的由检测器120生成的未被脸部网格覆盖的有效特征点。有效特征点是已经去除异常值的特征点,因此通过使用该特征点,可以以更高的精度以及基本上没有误差地确定相机的位置。
因此,根据示例性实施例,通过使用将提取特征点的2d技术与3d跟踪技术组合的脸部模型,可以以更高的精度确定相机的位置。
根据示例性实施例,相机的位置p*可以由下面的等式2最终确定。
【等式2】
此处,p*是最终的相机位置,而re(i,p)是使用相机位置p的点i的重投影误差。此外,re(j,p)是使用相机位置p的点j的重投影误差。此外,根据示例性实施例,在下面的2处的重投影误差。关键点x是脸部外侧的关键点或脸部内的关键点,但是关键点x'是通过立体处理生成的,而不是通过学习生成的。x和x'都通过光束平差(bundleadjustment)进行更新。此外,当关键点被稀疏网格(m)覆盖时,在确定采集图像的相机的位置的过程中,将任何关键点x或x'作为异常值临时去除。
如上所述,位置确定器可以基于使用已经去除异常值的有效特征点的3d跟踪技术而以更高的精度来确定相机的位置。如前所述,内容生成器140可以基于所确定的相机的位置来生成关于对象的3d内容。
由于重投影误差较大,可以去除可靠性低的特征点,并且通过高精度匹配算来法校正误差大的特征点的位置,从而确定3d点云信息。
可以重复确定有效特征点的过程从而反映如上所述更新的3d点云信息,也可以更新机器学习中使用的脸部模型的信息。因此,由于所采集对象的特征被反映在模型中,所以可以提高机器学习的精度。
换句话说,检测器120可以使用多幅输入图像、采集图像的位置以及从图像中检测到的特征点中的至少一个来更新脸部模型,然后在更新之后,检测器120可以将更新后的脸部模型应用于通过输入器110输入的图像,从而重复检测脸部特征点。
以这种方式更新的脸部模型不仅反映了关于最初提供的脸部模型的信息,还反映了关于当前被采集的对象的信息。换句话说,更新后的脸部模型不仅可以包括关于所学习的脸部模型的2d点或3d点的位置信息和颜色信息,而且还可以包括关于基于以下信息另外生成的3d点的位置信息和颜色信息:关于先前获得的多幅所采集图像的信息、关于先前获得的多幅所采集图像的颜色的信息以及关于先前获得的多幅所采集到图像的纹理的信息。
因此,更新后的脸部模型可以实时反映出当前正在被采集的对象的特征,因此检测当前正在被采集的对象的脸部特征点的精度可以得到提高。
图形成器130形成对象表面的深度图。深度图是指表示图像中的对象与背景的3d距离信息的深度信息的集合。
图形成器130可以基于脸部模型的3d位置信息来提取通过应用所学习的脸部模型而检测到的脸部特征点的3d位置信息。此外,图形成器130可以基于所提取的特征点的3d位置信息来形成对象表面的深度图。由图形成器130提取的特征点的3d位置信息是基于人的脸部,因此3d位置信息可能不能反映正在被采集的实际对象的确切信息。然而,基于鼻尖比脸部的其他部分更突出的事实,图形成器130可以基于脸部模型提取正在被采集的对象的粗略3d位置信息。因此,基于3d位置信息,可以限定形成存在于3d空间中的对象表面的实际点的位置的范围,因此可以形成精确的深度图,且形成的速度要比不使用所限定的区域而是一个接一个地确定每个点的位置更快。
此外,图形成器130可以在通过输入器110输入的多幅图像之中选择图像来提取深度信息,并且通过使用所选择的图像和从所选择的图像中提取的深度信息来形成深度图。所选择的图像被称为关键帧,未被选择的图像被称为参考帧。
在另一示例性实施例中,图形成器130可以基于在检测器120中检测到的脸部特征点的分布、图像与从图像中检测到的脸部特征点之间的关系以及图像之间的相对采集位置来选择关键帧。
更具体地,根据在检测器120中检测到的脸部特征点,可以识别图像中包括了头部的哪个部分,并且图形成器130可以以每个预定的第一间隔选择与脸部的正面对应的图像作为关键帧,并且以大于预定的第一间隔的每个第二间隔来选择与其他部分对应的图像作为关键帧。以这种方式,针对需要更精确地表达的脸部区域,可以获得更大数目的关键帧,而针对不需要精确表达的脸部区域(诸如,头的后部),可以获得更小数目的关键帧。因此,针对重要的脸部区域,可以在降低形成深度图的速度的同时,提高恢复形状的精度。
在另一示例性实施例中,图形成器130可以在形成图信息时确定所形成的图信息的质量,并且当确定质量低于预定标准时,可以在对应的区域中选择更多的关键帧,从而再次基于这些关键帧来形成图信息。
此外,图形成器130可以基于所选择的关键帧与参考帧的比较和分析,通过立体处理形成深度图。
立体处理是指对从不同位置获得的图像之间的距离信息进行处理,类似于人类的视觉系统。立体处理(或立体组合)是计算机可视区域之一,其模拟了人类视觉系统中的提取图像之间的距离的能力。更具体地,可以使用诸如模板匹配和基于体素的多视点方法等各种方法,这些方法对于相关领域的技术人员是公知的,因此将省略其详细说明。
在这种情况下,在示例性实施例中,图形成器130可以基于所提取的特征点的3d位置信息和通过连接特征点(或点)配置的脸部网格(或体积模型)中的至少一个来确定对象表面的深度范围,并且在所确定的深度范围内形成深度图。更具体地说,图形成器130可以在当前关键帧的相机位置中反映脸部模型,并且预测关键帧内的每个像素的初始深度范围。因此,可以提高提取每个像素的深度信息的精度。
此外,图形成器130可以基于所提取的特征点的3d位置信息来确定用于立体处理的块的尺寸(或块尺寸)。在使用模板匹配方法的情况下,可以确定用于模板匹配的块尺寸。
在这种情况下,图形成器130可以基于从至少两幅或多幅图像中提取的特征点的3d位置信息、至少两幅或多幅图像之间的相对采集位置以及在至少两幅或多幅图像中特征点的分布来确定块尺寸。
更具体地说,图形成器130可以在当前关键帧的相机的位置中反映脸部模型,基于所反映的信息来确定关键帧的像素之间的在地理上的相似度以及基于关键帧像素与参考像素之间的颜色相似度来确定块尺寸。例如,针对像素之间具有较高颜色相似度的诸如脸颊的部分,可以使用大的块尺寸。块尺寸越大,形成图的准确度越高,但速度可能会变得更慢。在本实施例中,可以根据对象区域的特点来确定适当的块尺寸。
此外,图形成器130可以比较关键帧与参考帧,并且基于比较结果来提取深度信息。在这种情况下,可以仅使用一个参考帧,或者可以使用多个累积的参考帧。
可以通过测量关键帧像素x与参考帧测试像素x'之间的颜色相似度来提取关键帧的深度信息。例如,使用基于多视点的逼近方法来提取深度信息,并且靠近关键帧的所有帧都被用作参考帧ir。所有体素的成本e可以使用下面的等式3来计算。
【等式3】
在本文中,e是所有体素的成本,ed是测量关键帧与参考帧之间的光测误差的数据项,更具体地是颜色的差异。es是测量体素与x所属的m内的三角形之间的距离的形状误差。此外,γ是关于es的常数。此外,ec是测量参考图像中参考帧测试像素x'的方差的项。此外,δ是ec的常数。
内容生成器140可以使用在图形成器130中生成的深度图和多幅图像来生成对象的3d内容。在这种情况下,可以针对所有输入图像或针对一些输入图像生成深度图。当针对两幅或多幅图像形成深度图时,内容生成器140可以通过累积两幅或多幅图像的深度图来生成3d内容。
具体地,内容生成器140可以基于所提取的特征点的3d位置信息来确定对象的体积,并且确定分辨率。更具体地,可以使用更新后的脸部模型的尺寸和关于关键帧的深度图的平均深度信息来预测对象的近似体积。
此外,内容生成器140可以基于所测量的体积生成3d内容。因此,由于可以防止在对象以外的区域中的资源被浪费,所以可以提高恢复形状的精度和速度。
例如,内容生成器140可以确定体素立方体的体积,该体积等于或大于对象。
然后,内容生成器140可以基于所学习的对象的模型来旋转体素立方体,并且内容生成器140可以根据对象的部分应用不同的分辨率。
具体而言,内容生成器140可以向对象的预先确定的部分应用相比于除了对象的预先确定的部分之外的部分更高的分辨率。例如,当对象是人的脸部时,内容生成器140可以将第一分辨率应用于例如与眼睛、鼻子和嘴巴对应的部分,并且可以将比第一分辨率低的第二分辨率应用于其余部分。
内容生成器140可以通过累积为每个关键帧生成的深度图来恢复对象的表面。例如,可以使用作为公知技术的截断符号距离函数(tsdf)。此外,内容生成器140可以使用移动立方体算法(marchingcubealgorithm)从累积的体积中提取表面,并且通过泊松(poisson)网格优化来生成水密模型,由此恢复对象的形状。图3示出了根据示例性实施例所恢复的形状30。
然后,内容生成器140可以通过执行纹理重构来生成对象的3d内容。纹理恢复是指对所恢复的形状着色。
在纹理恢复的情况下,由于外部元素和内部元素可能出现纹理错位,或者可能出现纹理颜色的差异。例如,如果对象是人的头部,则在拍摄期间可能出现诸如瞳孔移动、眨眼、嘴唇移动等,并且因此当基于多幅图像执行针对诸如眼睛和嘴唇等的特征点的纹理恢复时,诸如眼睛和嘴唇等的特征点可能显得不自然。
因此,为了避免上述问题,在示例性实施例中,内容生成器140基于检测到的脸部的特征点的排列形状和图像的采集位置中的至少一个来选择多幅图像中的一幅图像,并且通过使用所选择的图像来恢复眉毛区域、眼睛区域、鼻子区域和嘴巴区域中的至少一个区域的纹理,以生成对象的3d内容。
因此,在诸如眉毛区域、眼睛区域、鼻子区域或嘴巴区域的容易发生移动的脸部的区域中,使用多幅图像中特征点最可区别的图像进行纹理恢复,可以防止不自然的脸部表情出现在完成的3d内容中。
在这种情况下,可以基于如上所述选择的一幅图像来恢复被限定为眉毛区域、眼睛区域、鼻子区域或嘴巴区域的区域的纹理,并且为了提供更自然的纹理表情,可以基于两幅或多幅图像来恢复纹理。例如,可以将靠近眉毛区域、眼睛区域、鼻子区域或嘴巴区域的边缘的区域和如上所述选择的一幅图像与另一幅图像组合,而后执行纹理恢复。
针对除了诸如眼睛区域、鼻子区域或嘴巴区域之外的其余区域,内容生成器140可以通过选择多幅输入图像中的至少两幅图像和基于排列形状以及所确定的检测到的脸部特征点的采集位置中的至少一个对所选择的图像进行组合来恢复纹理。
更具体地,内容生成器140可以通过对从脸部的图像获得的颜色应用加权平均来恢复除了眼睛区域、鼻子区域或嘴巴区域等之外的其余区域的纹理。
图4是用于说明根据示例性实施例的恢复纹理的方法的视图。通过相机采集对象,该对象是人的头部40。图4示出了当相机围绕对象转动时由相机拍摄的图像。在图4中,位置c1、c2和c3对应于相机面向头部40的脸部并因此其对人来说是可见的位置。此外,位置c4和c5对应于相机面向头部40的后部并因此其对人来说是不可见的位置。
由相机在位置c1处拍摄的图像可以是最好地表现脸部的图像,因此内容生成器140可以选择在位置c1处所拍摄的图像,并且使用所选择的图像来恢复眉毛区域、眼睛区域、鼻子区域和嘴巴区域的纹理。在位置c1处采集到的图像在下文中可以被称为“最佳图像”。
在这种情况下,内容生成器140可以基于通过由检测器120应用脸部模型检测到的脸部特征点,通过使用以下方法来选择最佳图像。
内容生成器140指定如图5所示的脸部的眉毛区域、眼睛区域、鼻子区域和嘴巴区域作为要通过使用一幅图像的纹理恢复的未混合区域φ。
此外,内容生成器140选择由下面的等式4定义的成本函数f成为最大值的图像。
【等式4】
f=a·ffrontal+b·feyeopen+c·feyecenter+d·fmouthopen+e·ffacialexpression
f是成本函数,参照图6a,ffrontal是关于正脸方向的元素,参照图6b,feyeopen是关于眼睛睁开程度的元素61,参照图6c,feyecenter是关于瞳孔位置的元素62,即注视的位置,参照图6d,fmouthopen是关于嘴巴张开程度的元素63,参照图6e,ffacialexpression是关于脸部表情的元素64。脸部表情越少,元素64的得分越高。在图6e中,元素66的得分可以在多个元素64中具有最高得分。此外,a、b、c、d和e中的每一个都可以是加权值元素。
当图像中的对象朝向前方时,眼睛睁开的程度越大(即,眼睛睁地越大)、瞳孔在中间的越多、嘴巴张开地越小(即,嘴巴闭地越紧)、脸部表情越少。基于上述特点,可以选择该图像作为最佳图像。
在未混合区域朝向前方的情况下,对被选择为最佳图像的图像的纹理进行恢复。在不是未混合区域φ的区域的情况下,通过对从所采集的图像中获得的颜色应用加权平均来恢复纹理。
此外,内容生成器140还可以执行用于补洞的算法,并且恢复纹理图中未被分配颜色的区域中的颜色。
上述各种示例性实施例可以实现在记录介质中,该记录介质可以由计算机或计算机相关装置使用软件、硬件或其组合来读取。通过使用硬件,示例性实施例可以使用以下项中的至少一个功能来实现:专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理设备(dspd)、可编程逻辑设备(pld)、现场可编程门阵列(fpga)、处理器、控制器、微控制器、微处理器以及用于执行其他功能的电子单元。例如,由上述检测器120、图形成器130、内容生成器140和位置确定器执行的功能可以由3d原始内容生成装置100的中央处理单元(cpu)和/或图形处理单元(gpu)来实现。通过使用软件,示例性实施例可以通过单独的软件模块来实现。每个软件模块可以执行上述示例性实施例的一个或更多个功能和操作。
根据各种示例性实施例的3d内容生成装置的功能主要可以分为如图7中示出的两个模块。
图7是用于说明在根据示例性实施例的内容生成装置100中执行的数据处理的每个流水线的视图。
参照图7,流水线包括两部分:现场模块和后期模块。现场模块在所采集的图像被输入的同时实时执行数据处理,并且对输入的所采集的图像并行地执行任务a和任务b。任务a包括检测脸部的特征点的操作,任务b包括基于检测到的特征点形成深度图的操作。此外,后期模块包括在拍摄完成之后执行的形状恢复c和纹理恢复d。
同时,已经描述了所恢复的主体是脸部的示例,但是本申请的公开不限于脸部恢复,而是可以针对任何对象执行恢复。此处,对象表示具有形状的任何事物。
图8是用于说明根据示例性实施例的3d内容生成方法的流程图。
参照图8,3d内容生成装置100接收在不同位置采集到的对象的多幅图像(s810)。在这种情况下,多幅图像中的每幅图像可以是以视频格式采集到的对象的帧或依次采集到的静止图像。此外,可以同时输入多幅图像,或者在先前图像的处理完成之后一次输入一幅图像。3d内容生成装置100可以是被配置为从外部相机或具有相机的装置接收图像的装置。在这种情况下,相机可以是单目相机。
此外,3d内容生成装置100从多幅图像中的每幅图像中检测预先确定的特征点(s820)。具体而言,3d内容生成装置100可以将所学习的对象的模型应用于多幅图像中的每幅图像,并检测对象的特征点。所学习的对象的模型指示重复进行以下操作的结果:输入关于对象的多幅图像(例如,当对象是人的脸部时,为拍摄了人的各种脸部的图像);从每幅图像手动或自动地选择预设的特征点;以及参照多幅图像,输入关于所选择的特征点的信息。
在对象是人的头部的情况下,3d内容生成装置100可以将所学习的脸部模型应用于输入的多幅图像中的每幅图像,并且检测脸部的特征点。在这种情况下,可以使用应用aam或asm的算法。作为又一示例,当恢复的对象是手时,内容生成装置100可以使用所学习的手部模型从多幅输入图像中检测手部的特征点。
3d内容生成装置100可以基于所提取的特征点的3d位置信息来确定多幅图像中的每幅图像的采集位置(即,相机的位姿)。
3d内容生成装置100可以使用检测到的对象的特征点、多幅图像以及所确定的采集位置中的至少一个来更新对象的模型。也就是说,模型学习可以被实时更新。
在这种情况下,更新后的对象的模型还可以包括基于多幅输入图像中的每幅图像的位置信息、颜色信息和纹理信息另外生成的3d点的位置信息和颜色信息。
此外,3d内容生成装置100可以在更新模型之后将更新后的模型应用于输入的图像,并检测对象的特征点。
此外,3d内容生成装置100可以提取所提取的特征点的3d位置信息,并且基于所提取的特征点的3d位置信息来形成对象的表面的深度图(s830)。
在这种情况下,3d内容生成装置100可以基于所提取的特征点来选择图像从而提取深度信息,并且基于从所选择的图像中提取出的深度信息来形成深度图。在本文中,提取深度信息的图像可以被称为关键帧。
更具体地,在对象是人的头部的情况下,基于检测到的特征点将被确定与具有许多弯曲区域的脸部对应的较大数目的图像选为关键帧,并且基于检测到的特征点将被确定与几乎没有弯曲区域的头的后部对应的较小数目的图像选为关键帧。例如,根据示例性实施例,在把要被选为关键帧的图像的数目预先确定为特定数目的情况下,通过根据脸部的区域来分配关键帧的数目可以更有效地恢复形状。
3d内容生成装置100可以通过在多幅图像中的至少两幅图像之间进行模板匹配来形成深度图,并且可以基于从至少两幅图像中提取的特征点的3d位置信息来确定用于模板匹配的块尺寸。
此外,3d内容生成装置100可以基于所提取的特征点的3d位置信息来确定对象的表面的深度范围,并且在所确定的深度范围内形成深度图。
然后,3d内容生成装置100使用所形成的深度图和多幅图像来生成3d内容(s840)。更具体地说,可以执行表面重构和纹理映射。
在表面重构操作中,可以基于所提取的特征点的3d位置信息来预测对象的体积,并且可以基于所预测的体积来恢复形状。更具体地,可以使用关键帧的深度图的平均深度信息和更新后的对象的模型的尺寸来预测对象的近似体积,并且可以基于所预测的对象的体积来确定分辨率。因此,通过防止在对象以外的区域中的资源被浪费,可以提高恢复形状的速度和精度。
此外,可以累积相应关键帧的深度图,通过使用累积后的深度图来恢复表面,而后从累积后的体积中提取表面(例如,移动立方体算法)并且生成水密模型(泊松网格优化),从而提取最终的形状。
此外,在纹理恢复操作中,3d内容生成装置100可以基于所提取的对象的特征点的排列形状来将多幅图像中的一幅图像选为最佳图像。最佳图像是指被确定为能最好地表现对象的图像。
在对象是人的头部的情况下,最佳图像是指被确定为能最好的表现脸部的图像。当图像朝向前方时,眼睛睁开的程度越大、瞳孔在中间的越多、嘴巴张开的越小、脸部表情越少。基于上述特点,可以将该图像选为最佳图像。
此外,3d内容生成装置100可以通过使用所选择的最佳图像来恢复对象的至少一个预先确定的区域的纹理。
另外,对于其余区域,3d内容生成装置100可以基于检测到的特征点的排列形状和所确定的采集位置中的至少一个来从多幅图像中选择至少两幅图像,并且对于除了通过使用所选择的最佳图像恢复其纹理的区域之外的区域,可以通过使用至少两幅所选择的图像来恢复该区域的纹理。
例如,在对象是人的头部的情况下,3d内容生成装置100可以通过使用所选择的最佳图像来恢复眉毛区域、眼睛区域、鼻子区域和嘴巴区域中的至少一个区域的纹理。
另外,对于其余区域,将加权平均值应用于所采集的对象的图像(或由对象可见的相机获得的图像)的颜色,然后再应用于恢复后的形状。
上述3d内容生成方法仅是示例,可能存在各种其他示例性实施例。
根据各种示例性实施例的3d内容生成方法可以被实现为程序,该程序包括可由计算机实现的算法,并且该程序可以被存储在非暂时性计算机可读介质中。
非暂时性计算机可读介质可以安装到各种装置上。
非暂时性计算机可读介质是指半永久性地而不是在短时间段内存储数据的计算机可读介质,诸如寄存器、高速缓冲存储器和存储器等。更具体地说,用于执行各种上述方法的程序可以被存储在诸如光盘(cd)、数字多功能盘(dvd)、硬盘、蓝光盘、通用串行总线(usb)、存储卡、只读存储器(rom)等的非暂时性计算机可读介质中。因此,根据示例性实施例,程序可以被安装在相关技术装置中以实现执行3d内容生成操作的3d内容生成装置。
根据各种示例性实施例,可以使用单目相机以非常快的速度生成可以从移动设备打印的3d脸部模型。此外,可以在缺乏足够数目的特征点的脸部中稳定地执行3d建模。
此外,由于在没有移动相机的繁琐操作的情况下就可以完成slam初始化,因此可以提高用户便利性。在相关的基于slam的建模技术中,通过仅基于使用图像之间的光测误差的算法改进基本框架来指定脸部模型存在困难。然而,示例性实施例中提供的算法可以通过将3d技术与2d识别结合以及通过机器学习来解决脸部建模的难题。
尽管已经示出和描述了一些实施例,但是本领域技术人员将会理解,在不脱离本公开的原理和精神以及由权利要求及其等同物所限定的范围的前提下,可以对示例性实施例进行改变。
- 还没有人留言评论。精彩留言会获得点赞!