一种流媒体播放质量的预测方法与流程
本发明涉及流媒体点播直播技术领域,特别是一种流媒体播放质量的预测方法。
背景技术:
随着中国网络数字电视和视频直播点播产业的飞快发展,基于有线网络的数字电视用户规模在近几年持续增长,网络带宽的增长也促进了高清网络电视的发展,数字高清电视和可交互网络电视等业务的覆盖面也越来越广。由于用户的快速增长和播放媒体的码率的提升,给媒体服务器和传输网络都带来相当大的挑战。
由于互联网流媒体播放技术的复杂性,需要服务器端、传输网络和客户端共同合作完成流媒体的播放功能,任何一方出现问题都会影响播放质量。播放质量最直观的表现就是是否发生卡顿,而卡顿发生对于用户观看体验有极大的影响,容易导致用户的流失。故对于流媒体播放质量的检测和预测,对服务提供商有极大的参考价值,有利于服务提供商及时调整优化服务,提升用户体验。
目前对流媒体播放质量检测的主要方法是在终端中集成软探针软件,一类软探针是集成在播放器中,对播放器的工作状态进行检测从而得出播放质量;另一类软探针是工作于系统底层,通过分析网络数据包来评判网络质量,从而推断播放质量。这两种技术能部分判断播放质量,但缺乏自学习的能力,不能根据终端自身情况进行自适应的改变,同时缺乏对播放质量预测的能力,只能在故障发生后提供数据,不具备故障的前瞻性。
技术实现要素:
本发明的目的在于提供一种工作于系统底层,能实时判断流媒体播放质量并对未来一段时间的播放质量进行预测的方法。
实现本发明目的的技术解决方案为:一种流媒体播放质量的预测方法,包括以下步骤:
步骤1,使用网络监听技术收集和本机系统相关的网络数据包,通过IP地址、端口过滤技术保留流媒体播放相关的数据包;
步骤2,根据相应协议重新构建协议栈,获取该协议栈中传输的媒体数据和网络性能数据,并记录主机的性能数据;
步骤3,解码媒体数据,结合系统时间综合判断当前播放质量,结合上一阶段的网络和主机性能数据训练机器学习模型;
步骤4,使用机器学习模型,通过当前网络和主机性能数据,预测下一阶段时间的流媒体播放质量。
进一步地,步骤1中所述通过IP地址、端口过滤技术保留流媒体播放相关的数据包,具体为:
使用电子节目指南服务器、调度服务器和内容分发网络服务器的IP地址和端口对网络数据包进行过滤,仅保留流媒体播放相关的数据包。
进一步地,步骤2所述根据相应协议重新构建协议栈,获取该协议栈中传输的媒体数据和网络性能数据,并记录主机的性能数据,具体如下:
A)针对传输层是TCP协议的,使用对帧技术,获取TCP中传输的流数据,同时记录时延、乱序率、丢包率、低窗口率;
B)针对应用层是HTTP协议的,对包头进行重新构建,获取请求信息和响应信息,同时记录各阶段时延;
C)针对应用层是HLS协议的,记录媒体码率;
D)针对传输层是UDP组播协议的,记录组播控制信息和媒体数据,同时记录网络时延、抖动;
E)记录播放流媒体时的CPU使用率、内存占用率和IO性能。
进一步地,步骤3中所述的解码媒体数据,结合系统时间综合判断当前播放质量,包括以下步骤:
步骤3.1.1,根据已下载的媒体片段,快速解码获取片段时长;
步骤3.1.2,通过媒体片段下载时间和媒体时长求出目前还可以播放的时长;
步骤3.1.3,通过积累的可播放时长和系统流逝的时间,判断当前流媒体播放质量,并根据缓存时长进行播放质量评级。
进一步地,步骤3中所述的结合上一阶段的网络和主机性能数据训练机器学习模型,步骤如下:
步骤3.2.1,选择网络性能数据中能够体现网络状态的参数,加上反映主机工作状态的性能数据参数,进行预处理和数据融合,最后得到特征向量;
步骤3.2.2,将当前状态10秒前的由步骤3.2.1中得出的特征向量作为输入,将当前流媒体播放质量评级作为输出,训练具有分类功能的机器学习模型。
进一步地,步骤4中所述的使用机器学习模型,通过当前网络和主机性能数据,预测下一阶段时间的流媒体播放质量,具体为:
将当前状态的由步骤3.2.1得出的特征向量作为输入,机器学习模型的输出作为10秒后流媒体播放质量的预测。
本发明与现有技术相比,其显著优点为:(1)通过历史数据预测未来的播放质量,能及时通知服务提供商,特殊情况下能在故障发生之前发现故障、排除故障或采取针对性措施,提升服务质量;(2)由于流媒体播放终端的网络环境和主机环境各不相同,使用机器学习算法能使预测功能在各种工作环境下都能自动适应;(3)具有实时性,能在占用少量CPU时间和内存的前提下,判断当前流媒体的播放质量,并学习分析采集的数据和流媒体播放质量之间的潜在联系,机器学习算法能不断自动调优,使预测准确性不断提升。
附图说明
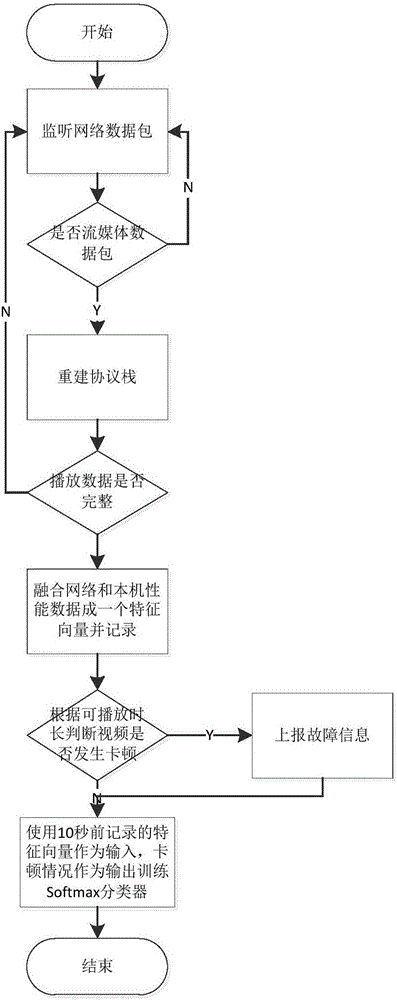
图1是本发明中流媒体播放质量预测的机器学习模型训练流程图。
图2是本发明中机器学习模型预测流媒体播放质量的流程图。
图3是本发明的整体系统数据流图。
具体实施方法
下面对本发明方案进行详细说明。
本发明在对流媒体播放质量进行预测的时候,主要分为两个部分,第一个部分是利用历史数据对预测模型进行训练,第二部分是用当前性能数据输入预测模型并对未来播放质量进行预测。
本发明流媒体播放质量的预测方法,包括以下步骤:
步骤1,使用网络监听技术收集所有和本机系统相关的网络数据包,并通过网络协议(Internet Protocol,IP)地址、端口过滤技术保留流媒体播放相关的数据包。
所述通过IP地址、端口过滤技术保留流媒体播放相关的数据包,具体为:
使用具体的电子节目指南(Electronic Program Guide,EPG)服务器、调度服务器和内容分发网络(Content Delivery Network,CDN)服务器的IP地址和端口对网络数据包进行过滤,仅保留流媒体播放相关的数据包,减少后续流程的数据量,提升了性能。
步骤2,根据相应协议重新构建协议栈,获取该协议栈中传输的媒体数据和网络性能数据,并记录主机的性能数据。
所述根据相应协议重新构建协议栈,获取该协议栈中传输的媒体数据和网络性能数据,并记录主机的性能数据,具体如下:
A)针对传输层是传输控制协议(Transmission Control Protocol,TCP)的,使用TCP对帧技术,将乱序到达的TCP数据包以包序号排序,将排序完成的数据包中的负载数据连接,最后获取TCP中传输的流数据,同时记录包时延、乱序率、丢包率、低窗口率等性能参数。
B)针对应用层是超文本传送协议(HyperText Transfer Protocol,HTTP)的,对请求和响应包头进行重组,获取请求信息和响应信息,同时记录各阶段时延。
C)针对应用层是HTTP流直播(HTTP Live Streaming,HLS)协议的,通过分析请求响应包,获取媒体码率等相关信息。
D)针对传输层是用户数据报协议(User Datagram Protocol,UDP)组播协议的,记录因特网组管理协议(Internet Group Management Protocol,IGMP)控制信息和媒体数据,同时记录网络时延、抖动、包间隔等性能数据。
E)记录播放流媒体时的中央处理器(Central Processing Unit,CPU)使用率、内存占用率和输入输出(Input/Output,IO)性能等主机性能数据。
步骤3,解码媒体数据,结合系统时间综合判断当前播放质量,结合上一阶段的网络和主机性能数据训练机器学习模型。
所述的解码媒体数据,结合系统时间综合判断当前播放质量,包括以下步骤:
步骤3.1.1,根据已下载的媒体片段,快速解码获取片段时长。
步骤3.1.2,通过媒体片段下载时间和媒体时长求出目前还可以播放的时长。
步骤3.1.3,通过积累的可播放时长和系统流逝的时间判断当前播放是否发生卡顿,即当前流媒体播放质量,并根据缓存时长等参数进行播放质量评级。
所述的结合上一阶段的网络和主机性能数据训练机器学习模型,步骤如下:
步骤3.2.1,选择网络性能数据中能够体现网络状态的参数,加上反映主机工作状态的性能数据参数,并对部分参数进行预处理和数据融合,最后得到特征向量;
步骤3.2.2,将当前状态10秒前的由步骤3.2.1中得出的特征向量作为输入,将当前流媒体播放质量评级作为输出,训练具有分类功能的机器学习模型。
步骤4,使用机器学习模型,通过当前网络和主机性能数据,预测下一阶段时间的流媒体播放质量,具体为:
将当前状态的由步骤3.2.1得出的特征向量作为输入,机器学习模型的输出作为10秒后流媒体播放质量的预测。
该方法能够在不更改播放器和系统的情况下,对当前流媒体播放质量进行准确判断,并通过机器学习算法对一段时间后的播放质量进行预测。本方法稳定高效,能通过不断在线学习,针对网络和主机环境不断优化,使预测准确度不断提高,对于服务方提高流媒体播放质量有重要的参考意义。
下面将通过具体的实施例来说明本发明的具体实施方法。
实施例1
本发明中利用历史数据对机器学习模型的训练的流程图如图1所示。具体过程分为以下步骤:
步骤1,创建原始套接字在链路层进行旁路监听。服务提供商的流媒体服务器地址和协议在短时间内不会发生变化,故可以通过下载配置文件的方法,获取所有和流媒体播放相关的服务器地址和端口等信息(包括EPG服务器、调度服务器和CDN服务器的IP地址及其域名规则等),进而选择预编译的BPF过滤器并将其直接载入内核。
步骤2,根据数据包所属的协议类型,对上层协议进行还原,并取得其中的数据内容以供后续分析,同时记录网络性能数据。本发明需要处理的协议主要有以下几种:1)TCP协议数据包,读取包头标志位,获取当前TCP流的状态,当遇到TCP握手包,则初始化一个状态机和缓冲内存用于记录该TCP流的工作状况和传输的数据,同时读取包头的源IP地址、源端口、目标IP地址、目标端口、顺序号(Sequence number)、确认号(Acknowledgement number)和窗口(Window)等协议信息和数据包到达的绝对时间,记录在结构体中,用于后续性能数据计算;当遇到其他TCP包,根据源IP地址、源端口、目标IP地址和目标端口查找已有的TCP流,如果找到则根据包头标志位、顺序号和应答号更新状态机状态,在传输数据时把数据按顺序号进行排序并记录到缓冲中,并根据数据包到达时间、包头信息和传输数据量,计算上行速率、下行速率、各阶段包时延、最大包间隔、最大抖动、丢包率、乱序率、低窗口率等TCP协议相关的性能数据,如果没找到所属的TCP流则丢弃该数据包。2)IGMP协议数据包,直接对包进行解析,获取当前加入或退出的组播组信息,维护一个当前所属组播组的集合。3)UDP数据包,根据所属组播组的集合过滤出有效组播数据包,提取包中的流媒体信息,以供后续分析。4)HTTP协议数据,该数据是在TCP流传输的数据中获取的,通过HTTP协议本身的结束标记判断请求或响应是否完整,根据请求地址或响应信息中的数据类型判断是否为流媒体数据,如果是则在数据传输过程中提取各种中间信息,以供后续分析;如果不是,则删除该TCP流的所有记录,减轻TCP协议分析压力。5)HLS协议数据,该数据是在HTTP协议传输的数据中提取的,主要获取流媒体码率和媒体长度等信息。在统计网络性能数据时,以一定时间间隔调用系统工具计算当前CPU使用率、内存使用率和IO速率,并记录。
步骤3,通过之前协议中获取的媒体数据,快速解码流媒体数据求出当前下载的媒体可播放时长,减去当前时间和下载开始时间的差,即为目前可播放时长,并对可播放时长做求和操作,即为总可播放时长。若时长大于5秒,则认为当前播放质量好;若时长处于2-5秒,则认为当前播放质量中等;若小于2秒,则认为当前播放质量差;若小于0秒,则认为当前播放质量极差(已有卡顿产生)。对于播放质量差及卡顿的情况,上报监控服务器本次故障发生的信息。
步骤4,提取能够主要反映当前环境状况的性能数据,例如,网络层面的最大包延迟、丢包率、乱序率、低窗口率、最大抖动、上行速率和下行速率等;协议层面的RTP序列丢失、HTTP返回错误码、HLS协议不完整、HLS序列丢失等;媒体层面的媒体分辨率、媒体平均码率、媒体类型等;直观反映主机工作情况的主机性能数据,例如,CPU使用率、内存使用率和IO速率等。将这些数据合并为一个一维向量,做归一化处理后,存入循环队列中。
步骤5,取出循环队列中10秒前记录的性能数据向量,和当前的流媒体播放质量作为输入和输出,训练Softmax分类器,使用在线更新的方式更新权重。
本发明中利用现在性能数据对未来一段时间的流媒体播放质量进行预测的流程图如图2所示。
具体过程是:读取循环队列中现在的性能数据向量,输入之前训练的Softmax分类器中,取Softmax分类器的输出作为10秒后的流媒体播放质量预测结果。如果预测未来的播放质量会变差,则触发播放器内部机制,增加缓冲长度或其他主动策略避免卡顿的发生。
综上所述,本发明利用终端设备所在的网络环境和本机性能的历史数据作为训练数据,用现在的性能数据预测一段时间后的流媒体播放质量,整体数据流图如图3所示。本发明不仅仅提供当前播放质量的准确判断,更能对未来进行预测,这对于提升服务质量和用户体验有极大的作用;其次本发明充分考虑每台设备的独特性,方法具有普适性,且能随着工作时间的增长不断自我优化;并且本发明方法简单高效,易于实现。
- 还没有人留言评论。精彩留言会获得点赞!